转自:http://blog.csdn.net/yujimoyouran/article/details/59104131
简单描述一下这个例子:将项目日志实时采集到elasticsearch,便于统一管理。
1. 收集日志格式为:
log4j.properties : org.apache.log4j.Logger: %d{ISO8601} [%l-%M]-[%p] %t %m%n
logback.xml :org.slf4j.Logger: %date [%logger:%L]-[%level] %thread %msg%n
2. flume 1.7.0 (flume搭建只需解压配置jdk即可,官网教程都有案例,http://flume.apache.org/FlumeUserGuide.html)
source:Taildir Source
channel: File Channel
sinks:ElasticSearchSink
3. elasticsearch1.7.5
Flume搭建:
1. 下载flume安装包并解压apache-flume-1.7.0-bin.tar.gz, http://flume.apache.org/download.html
2. 创建软连接 ln -s apache-flume-1.7.0-bin flume
3. 进入conf目录,cp flume-env.sh.template flume-env.sh
4. 修改jdk,vi flume-env.sh

5. 将elasticsearch lib中的elasticsearch-1.7.5.jar和lucene相关jar包拷贝到flume lib中
6. 创建一些下面需要的目录(不同的source,channel,sink需要的目录不一样,用时看官网即可)
mkdir flume/conf/es (用来存放flume配置文件,并新建文件data-es.conf )
mkdir flume/tmp (Taildir Source生成的positionFile文件目录)
mkdir -p flume/file-channel/checkpoint (File Channel检查点写入间隔)
mkdir -p flume/file-channel/data (File Channel数据存放目录)
mkdir flume/test (存放测试数据)
Taildir Source配置,直接上data-es.conf截图:
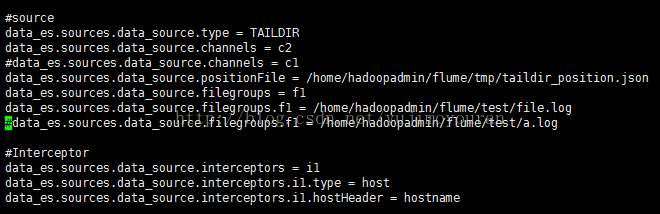
File Channel配置:

ElasticSearchSink 配置:
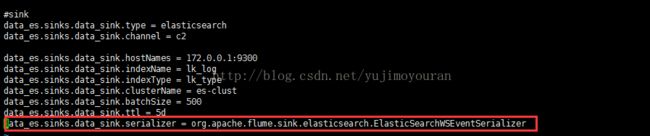
接下来主要讲解一下上图标红的地方,就是flume自定义Serializer
首先大体说一下为什么需要自定义Seralizer,一是也许项目中的log4j日志我们只关心程序员自己输出的日志信息,而不需要log4j其他信息;二是项目日志一般都会统一格式,自定义的格式也许flume不能很精准的拆分。
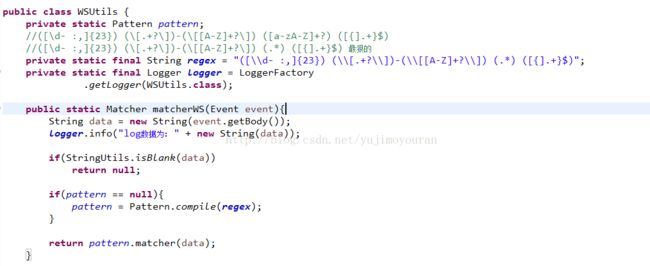
这里定义日志格式为:
2017-02-27 13:57:19,218 [com.data.test]-[INFO] main {sysName###测试项目@@@status###正在初始化@@@info###开始执行了}
使用正则拆分日志:([\d- :,]{23}) (\[.+?\])-(\[[A-Z]+?\]) (.*) ([{].+}$)
拆分结构:
![]()
下载源码,只需导入flume-ng-elasticsearch-sink模块即可:
源码不做详细讲解 (因为我还没来的及仔细研究,只是了解大概照猫画虎)
一. 修改的地方是:通过ElasticSearchSink 传入的数据会按照 “prefix-yyyy-MM-dd” 每天创建index,如果数据量不大的话有点浪费,现在只想按照“prefix-yyyy-MM”每月创建index,修改org.apache.flume.sink.elasticsearch.TimeBasedIndexNameBuilder

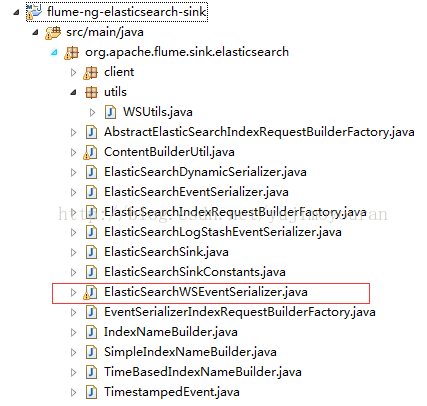
二. 仿照org.elasticsearch.common.xcontent.XContentFactory.jsonBuilder.ElasticSearchDynamicSerializer创建自己的Search,其中flume也是封装了es的api操作, Event对象就是你获取到的每条日志,然后按照你自己的逻辑将日志拆分即可,简单的几个截图吧:
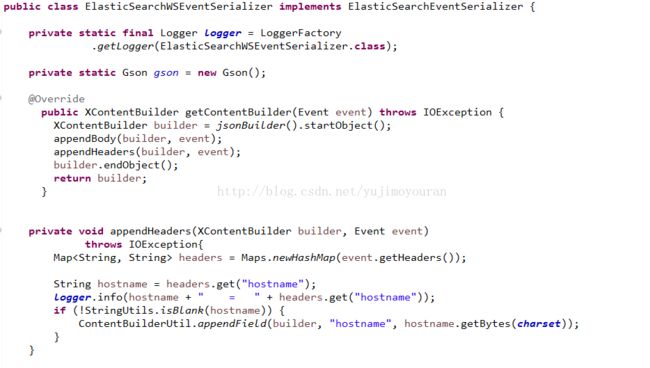
三. 因为只要程序员自己输出日志,所以要将正则不匹配的日志过滤掉。修改org.apache.flume.sink.elasticsearch.ElasticSearchSink, 标红为自己修改的地方
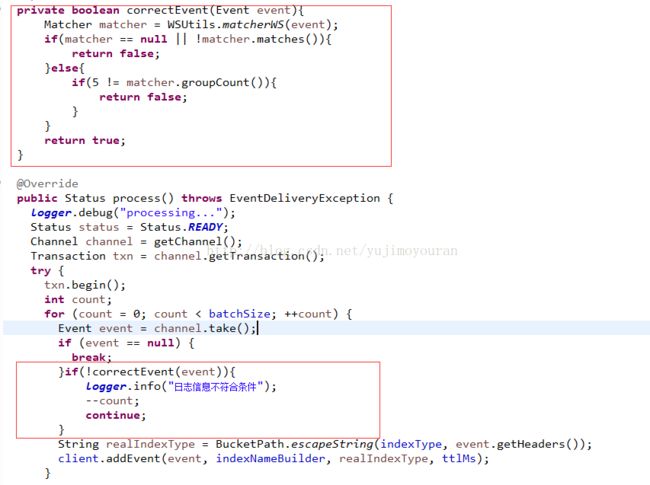
最后maven打包替换到flume lib下面相应jar包即可
![]()
算是写完了吧。。。