一主题网络爬虫设计方案
1.主题式网络爬虫名称:爬取前程无忧职位信息
2.主题式网络爬虫爬取的内容
本爬虫就要爬取公司名称,工作地点,薪资,学历,工作经验,招聘人数,公司规模,公司类型,公司福利和发布时间。
3.主题式网络爬虫设计方案概述
实验思路:爬取数据,数据清洗,数据可视化。
二.主题页面结构的结构特征分析
打开前程无忧,找到职位搜索,点右键检查元素。
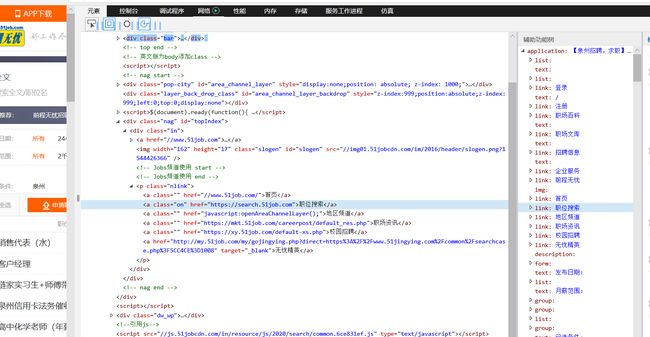
爬取信息,储存在Excel中
import urllib.request
import xlwt
import re
import urllib.parse
#import time
header={
'Host':'search.51job.com',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'MOzilla/5.0(Windows NT 10.0;Win64; x64) AppleWebkit/537.36(KHTML,like Gecko) chrome/78.0.3904.108 safari/537.36'
}
def getfront(page,item): #page是页数,item是输入的字符串,见后文
result = urllib.parse.quote(item) #先把字符串转成十六进制编码
ur1 = result+',2,'+str(page)+'.html'
ur2 = 'https://search.51job.com/list/000000,000000,0000,00,9,99,'
res = ur2+ur1
a = urllib.request.urlopen(res)
html = a.read().decode('gbk') #读取源代码并转为unicode
return html
def getInformation(html):
reg = re.compile(r'class="t1 ">.*? (.*?).*?(.*?).*?(.*?).*?',re.S)#匹配换行符
items=re.findall(reg,html)
return items
#新建表格空间
excel1 = xlwt.Workbook()
# 设置单元格格式
sheet1 = excel1.add_sheet('Job', cell_overwrite_ok=True)
sheet1.write(0, 0, '序号')
sheet1.write(0, 1, '职位')
sheet1.write(0, 2, '公司名称')
sheet1.write(0, 3, '公司地点')
sheet1.write(0, 4, '公司性质')
sheet1.write(0, 5, '薪资')
sheet1.write(0, 6, '学历要求')
sheet1.write(0, 7, '工作经验')
sheet1.write(0, 8, '公司规模')
sheet1.write(0, 9, '公司类型')
sheet1.write(0, 10,'公司福利')
sheet1.write(0, 11,'发布时间')
number = 1
item = input()
for j in range(1,10000): #页数自己随便改
try:
print("正在爬取第"+str(j)+"页数据...")
html = getfront(j,item) #调用获取网页原码
for i in getInformation(html):
try:
url1 = i[1] #职位网址
res1 = urllib.request.urlopen(url1).read().decode('gbk')
company = re.findall(re.compile(r'.*?.*?.*?
.*?',re.S),res1)
job_need = re.findall(re.compile(r'
.*? | (.*?) | (.*?) | .*?
',re.S),res1)
welfare = re.findall(re.compile(r'(.*?)',re.S),res1)
print(i[0],i[2],i[4],i[5],company[0][0],job_need[2][0],job_need[1][0],company[0][1],company[0][2],welfare,i[6])
sheet1.write(number,0,number)
sheet1.write(number,1,i[0])
sheet1.write(number,2,i[2])
sheet1.write(number,3,i[4])
sheet1.write(number,4,company[0][0])
sheet1.write(number,5,i[5])
sheet1.write(number,6,job_need[1][0])
sheet1.write(number,7,job_need[2][0])
sheet1.write(number,8,company[0][1])
sheet1.write(number,9,company[0][2])
sheet1.write(number,10,(" ".join(str(i) for i in welfare)))
sheet1.write(number,11,i[6])
number+=1
excel1.save("51job.xls")
time.sleep(0.3) #休息间隔,避免爬取海量数据时被误判为攻击,IP遭到封禁
except:
pass
except:
pass
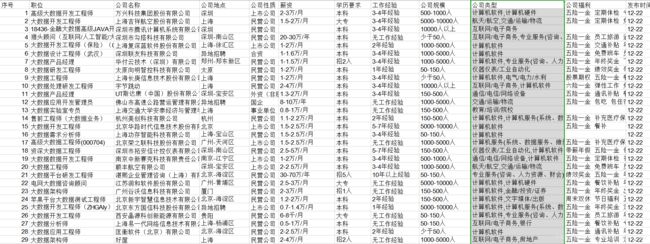
数据清洗:
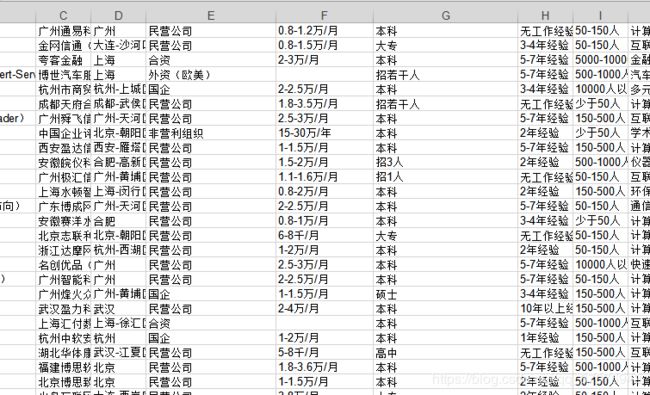
1.首先打开文件,出现有空值(NAN)的信息,直接删除整行,职位出错,及其他地方信息出错,如在学历中“召几人”,薪资单位不一致并保存到另一个文件。

#coding:utf-8
import pandas as pd
import re
#除此之外还要安装xlrd包
data = pd.read_excel(r'51job.xls',sheet_name='Job')
result = pd.DataFrame(data)
a = result.dropna(axis=0,how='any')
pd.set_option('display.max_rows',None) #输出全部行,不省略
b = u'数据'
number = 1
li = a['职位']
for i in range(0,len(li)):
try:
if b in li[i]:
#print(number,li[i])
number+=1
else:
a = a.drop(i,axis=0)
except:
pass
b2= u'人'
li2 = a['学历要求']
for i in range(0,len(li2)):
try:
if b2 in li2[i]:
#print(number,li2[i])
number+=1
a = a.drop(i,axis=0)
except:
pass
b3 =u'万/年'
b4 =u'千/月'
li3 = a['薪资']
#注释部分的print都是为了调试用的
for i in range(0,len(li3)):
try:
if b3 in li3[i]:
x = re.findall(r'\d*\.?\d+',li3[i])
#print(x)
min_ = format(float(x[0])/12,'.2f') #转换成浮点型并保留两位小数
max_ = format(float(x[1])/12,'.2f')
li3[i][1] = min_+'-'+max_+u'万/月'
if b4 in li3[i]:
x = re.findall(r'\d*\.?\d+',li3[i])
#print(x)
#input()
min_ = format(float(x[0])/10,'.2f')
max_ = format(float(x[1])/10,'.2f')
li3[i][1] = str(min_+'-'+max_+'万/月')
print(i,li3[i])
except:
pass
#保存到另一个文件
a.to_excel('51job2.xls', sheet_name='Job', index=False)
数据可视化:
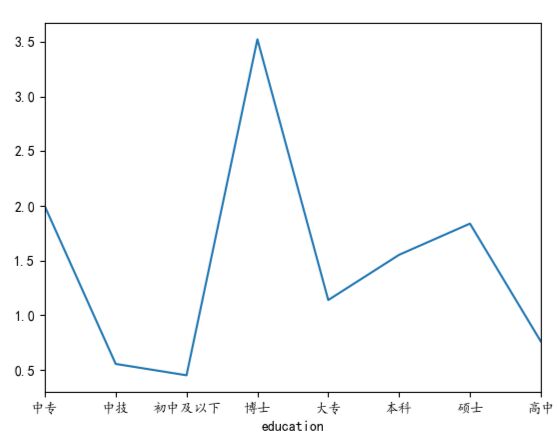
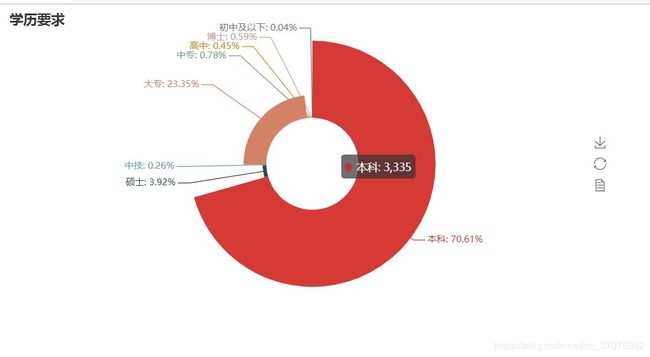
绘制工作经验-薪资图、学历-薪资图、学历圆环图:
先打开文件,创建多个列表单独存放‘薪资’,‘学历要求’等信息。
file = pd.read_excel(r'51job2.xls',sheet_name='Job')
f = pd.DataFrame(file)
pd.set_option('display.max_rows',None)
add = f['公司地点']
sly = f['薪资']
edu = f['学历要求']
exp = f['工作经验']
address =[]
salary = []
education = []
experience = []
for i in range(0,len(f)):
try:
a = add[i].split('-')
address.append(a[0])
#print(address[i])
s = re.findall(r'\d*\.?\d+',sly[i])
s1= float(s[0])
s2 =float(s[1])
salary.append([s1,s2])
#print(salary[i])
education.append(edu[i])
#print(education[i])
experience.append(exp[i])
#print(experience[i])
except:
pass
min_s=[] #定义存放最低薪资的列表
max_s=[] #定义存放最高薪资的列表
for i in range(0,len(experience)):
min_s.append(salary[i][0])
max_s.append(salary[i][0])
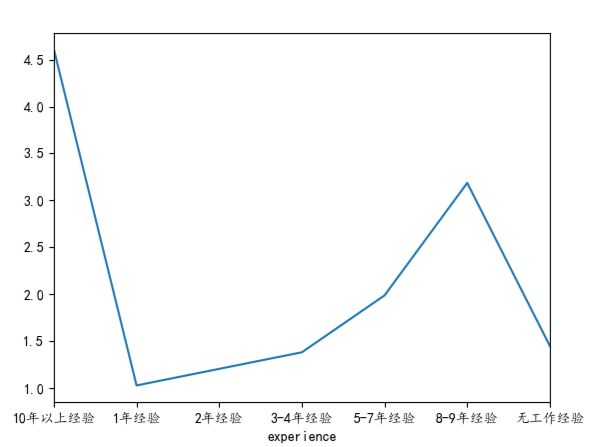
my_df = pd.DataFrame({'experience':experience, 'min_salay' : min_s, 'max_salay' : max_s}) #关联工作经验与薪资
data1 = my_df.groupby('experience').mean()['min_salay'].plot(kind='line')
plt.show()
my_df2 = pd.DataFrame({'education':education, 'min_salay' : min_s, 'max_salay' : max_s}) #关联学历与薪资
data2 = my_df2.groupby('education').mean()['min_salay'].plot(kind='line')
plt.show()
def get_edu(list):
education2 = {}
for i in set(list):
education2[i] = list.count(i)
return education2
dir1 = get_edu(education)
# print(dir1)
attr= dir1.keys()
value = dir1.values()
pie = Pie("学历要求")
pie.add("", attr, value, center=[50, 50], is_random=False, radius=[30, 75], rosetype='radius',
is_legend_show=False, is_label_show=True,legend_orient='vertical')
pie.render('学历要求玫瑰图.html')
所有代码,如下:
import urllib.request
import xlwt
import re
import urllib.parse
#import time
header={
'Host':'search.51job.com',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'MOzilla/5.0(Windows NT 10.0;Win64; x64) AppleWebkit/537.36(KHTML,like Gecko) chrome/78.0.3904.108 safari/537.36'
}
def getfront(page,item): #page是页数,item是输入的字符串,见后文
result = urllib.parse.quote(item) #先把字符串转成十六进制编码
ur1 = result+',2,'+str(page)+'.html'
ur2 = 'https://search.51job.com/list/000000,000000,0000,00,9,99,'
res = ur2+ur1
a = urllib.request.urlopen(res)
html = a.read().decode('gbk') #读取源代码并转为unicode
return html
def getInformation(html):
reg = re.compile(r'class="t1 ">.*? (.*?).*?(.*?).*?(.*?).*?',re.S)#匹配换行符
items=re.findall(reg,html)
return items
#新建表格空间
excel1 = xlwt.Workbook()
# 设置单元格格式
sheet1 = excel1.add_sheet('Job', cell_overwrite_ok=True)
sheet1.write(0, 0, '序号')
sheet1.write(0, 1, '职位')
sheet1.write(0, 2, '公司名称')
sheet1.write(0, 3, '公司地点')
sheet1.write(0, 4, '公司性质')
sheet1.write(0, 5, '薪资')
sheet1.write(0, 6, '学历要求')
sheet1.write(0, 7, '工作经验')
sheet1.write(0, 8, '公司规模')
sheet1.write(0, 9, '公司类型')
sheet1.write(0, 10,'公司福利')
sheet1.write(0, 11,'发布时间')
number = 1
item = input()
for j in range(1,10000): #页数自己随便改
try:
print("正在爬取第"+str(j)+"页数据...")
html = getfront(j,item) #调用获取网页原码
for i in getInformation(html):
try:
url1 = i[1] #职位网址
res1 = urllib.request.urlopen(url1).read().decode('gbk')
company = re.findall(re.compile(r'.*?.*?.*?
.*?',re.S),res1)
job_need = re.findall(re.compile(r'
.*? | (.*?) | (.*?) | .*?
',re.S),res1)
welfare = re.findall(re.compile(r'(.*?)',re.S),res1)
print(i[0],i[2],i[4],i[5],company[0][0],job_need[2][0],job_need[1][0],company[0][1],company[0][2],welfare,i[6])
sheet1.write(number,0,number)
sheet1.write(number,1,i[0])
sheet1.write(number,2,i[2])
sheet1.write(number,3,i[4])
sheet1.write(number,4,company[0][0])
sheet1.write(number,5,i[5])
sheet1.write(number,6,job_need[1][0])
sheet1.write(number,7,job_need[2][0])
sheet1.write(number,8,company[0][1])
sheet1.write(number,9,company[0][2])
sheet1.write(number,10,(" ".join(str(i) for i in welfare)))
sheet1.write(number,11,i[6])
number+=1
excel1.save("51job.xls")
time.sleep(0.3) #休息间隔,避免爬取海量数据时被误判为攻击,IP遭到封禁
except:
pass
except:
pass
#coding:utf-8
import pandas as pd
import re
#除此之外还要安装xlrd包
data = pd.read_excel(r'51job.xls',sheet_name='Job')
result = pd.DataFrame(data)
a = result.dropna(axis=0,how='any')
pd.set_option('display.max_rows',None) #输出全部行,不省略
b = u'数据'
number = 1
li = a['职位']
for i in range(0,len(li)):
try:
if b in li[i]:
#print(number,li[i])
number+=1
else:
a = a.drop(i,axis=0)
except:
pass
b2= u'人'
li2 = a['学历要求']
for i in range(0,len(li2)):
try:
if b2 in li2[i]:
#print(number,li2[i])
number+=1
a = a.drop(i,axis=0)
except:
pass
b3 =u'万/年'
b4 =u'千/月'
li3 = a['薪资']
#注释部分的print都是为了调试用的
for i in range(0,len(li3)):
try:
if b3 in li3[i]:
x = re.findall(r'\d*\.?\d+',li3[i])
#print(x)
min_ = format(float(x[0])/12,'.2f') #转换成浮点型并保留两位小数
max_ = format(float(x[1])/12,'.2f')
li3[i][1] = min_+'-'+max_+u'万/月'
if b4 in li3[i]:
x = re.findall(r'\d*\.?\d+',li3[i])
#print(x)
#input()
min_ = format(float(x[0])/10,'.2f')
max_ = format(float(x[1])/10,'.2f')
li3[i][1] = str(min_+'-'+max_+'万/月')
print(i,li3[i])
except:
pass
#保存到另一个文件
a.to_excel('51job2.xls', sheet_name='Job', index=False)
file = pd.read_excel(r'51job2.xls',sheet_name='Job')
f = pd.DataFrame(file)
pd.set_option('display.max_rows',None)
add = f['公司地点']
sly = f['薪资']
edu = f['学历要求']
exp = f['工作经验']
address =[]
salary = []
education = []
experience = []
for i in range(0,len(f)):
try:
a = add[i].split('-')
address.append(a[0])
#print(address[i])
s = re.findall(r'\d*\.?\d+',sly[i])
s1= float(s[0])
s2 =float(s[1])
salary.append([s1,s2])
#print(salary[i])
education.append(edu[i])
#print(education[i])
experience.append(exp[i])
#print(experience[i])
except:
pass
min_s=[] #定义存放最低薪资的列表
max_s=[] #定义存放最高薪资的列表
for i in range(0,len(experience)):
min_s.append(salary[i][0])
max_s.append(salary[i][0])
my_df = pd.DataFrame({'experience':experience, 'min_salay' : min_s, 'max_salay' : max_s}) #关联工作经验与薪资
data1 = my_df.groupby('experience').mean()['min_salay'].plot(kind='line')
plt.show()
my_df2 = pd.DataFrame({'education':education, 'min_salay' : min_s, 'max_salay' : max_s}) #关联学历与薪资
data2 = my_df2.groupby('education').mean()['min_salay'].plot(kind='line')
plt.show()
def get_edu(list):
education2 = {}
for i in set(list):
education2[i] = list.count(i)
return education2
dir1 = get_edu(education)
# print(dir1)
attr= dir1.keys()
value = dir1.values()
pie = Pie("学历要求")
pie.add("", attr, value, center=[50, 50], is_random=False, radius=[30, 75], rosetype='radius',
is_legend_show=False, is_label_show=True,legend_orient='vertical')
pie.render('学历要求玫瑰图.html')
总结:
1.经过对主题数据的分析与可视化,可以得到哪些结论?
数据可视化可以让我们对网页的内容更清晰,更直观。
2.小结
经过这段时间的学习,我认识到学Python太难了,由于英语不扎实,经常要查找英语单词,在find_all上徘徊了很久,运行不了,最后还是没搞懂,今后需要更多时间投入。