Zookeepr分布式协调服务之基础铺垫(大数据工程师工作笔记)
01 Zookeeper 架构原理
1. 定义
ZooKeeper 在很多大企业里,已经证明了非常的稳定。
ZooKeeper 是一种分布式应用所设计的高可用、高性能且一致的开源协调服务。它首先提供了分布式锁服务。
它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
由于 ZooKeeper 是开源的,后来者在分布式锁的基础上又提供了配置维护、组服务、分布式消息队列、分布式通知/协调等。
2.特点
-
1)最终一致性
- 客户端无论连接到哪个 Server,展示给它的都是同一个视图,这是 Zookeeper 最重要的性能;
- 可以理解为每个节点上都有一个内存数据库,数据都是一模一样的;
-
2)可靠性
- 具有简单、健壮、良好的性能,如果消息 message 被一台服务器接收,那么它将被所有的服务器接收;
- 也就是说我们将数据写到我们的集群里面,只要有一台机器接收了某一条消息,那么其他机器也能接收到,并同步过去;
-
3)实时性
- Zookeeper 保证客户端将在一个时间间隔范围内,获得服务器的更新信息或者服务器失效的信息。但由于网络延时等原因,Zookeeper 不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用 sync() 接口;
-
4)等待无关(wait-free)
- 慢的或者失效的客户端不得干预快速的客户端的请求,这就使得每个客户端都能有效的等待;
-
5)原子性
- 更新操作要么成功,要么失败,没有中间状态。
-
6)顺序性
- 对于所有 Server,同一消息发布顺序一致。它包括全局有序和偏序两种。
- i)全局有序是指如果在一台服务器上消息 a 在消息 b 前发布,则在所有 Server 上消息 a 都将在消息 b 前发布。
- ii)偏序是指如果一个消息 b 在消息 a 后被同一个发送者发布,a 必将排在 b 前面。
- 对于所有 Server,同一消息发布顺序一致。它包括全局有序和偏序两种。
3.基本架构
Zookeeper (ZK)是一个由多个 Server 组成的集群,该集群有一个 Leader,多个 Follower。客户端可以连接任意 ZK 服务节点来读写数据。
ZK 内容有选举机制,会选举出谁是 leader,所以不一定哪个 Server 是 Leader;

ZK 集群中每个 Server 都保存一份数据副本。
ZK 使用简单的同步策略,通过以下两条基本保证来实现数据的一致性:
- 1)全局串行化所有的写操作。(读可以并行化操作)
- 2)保证同一客户端的指令被 FIFO(先进先出:谁先来谁先处理) 执行以及消息通知的 FIFO。所有的读请求由 ZK Server 本地响应,所有的更新请求将转发给 Leader,由 Leader实施。
ZK 通过复制来实现高可用性,只要 ZK 集群中半数以上的机器处于可用状态,它就能提供服务。比如,在一个有 5 个节点的 ZK 集群中,每个 Follower 节点的数据都是 Leader 节点数据的副本,每个节点的数据视图都一样,这样就有 5个节点提供 ZK 服务。并且 ZK 集群中任意2台机器出现故障,都可以保证 ZK 仍然对外提供服务,因为剩下的 3 台机器超过了半数。
ZK 会确保对 Znode 树(ZK 存储数据的数据结构)的每一个修改都会被复制到超过半数的机器上。如果少于半数的机器出现故障,则最少有一台机器会保存最新的状态,那么这台机器就是我们的 Leader,其余的副本最终也会更新到这个状态。如果 Leader 挂了,由于其他机器保存了 Leader 的副本,那就可以从中选出一台机器作为新的 Leader 继续提供服务。
4.状态角色

在实际工作中,如果我们负载特别高,我们使用观察者角色,如果不需要,我们也不需要搭建;
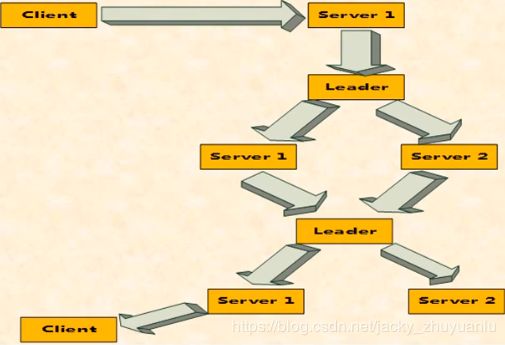
5. 读写流程
6. 服务
Zookeeper 提供很多服务,比如分布式锁、分布式队列、分布式通知与协调等服务。那么具体是通过什么方式实现的呢?
Zookeeper 的相关服务主要通过以下几个部分实现:
- 1.数据结构:Znode
- 2.原语:在数据结构的基础上定义的一些原语,也就是该数据结构的一些操作。(Znode 的增删改查)
- 3.通知机制-watcher:可以通过通知机制,将消息以网络形式发送给分布式应用程序。
Zookeeper 主要通过数据结构+原语+watcher机制这3部分共同来实现相关服务。
02 Zookeeper 集群安装部署
1. 安装模式
Zookeeper 安装模式有三种:
- 单机模式:Zookeeper 只运行在一台服务器上,适合测试环境;
- 伪集群模式:一台物理机上运行多个 Zookeeper 实例,适合测试环境(基本不用);
- 分布式集群模式:Zookeeper 运行于一个集群中,适合生产环境。
2. 版本选择
目前 Hadoop 发行版非常多,有华为发行版、Intel 发行版、Cloudera 发行版(CDH)等,所有这些发行版均是基于 Apache Hadoop 衍生出来的,之所以有这么多的版本,完全是由 Apache Hadoop 的开源协议决定的:任何人可以对其进行修改,并作为开源或商业产品发布或销售。
国内绝大多数公司发行版是收费的,比如 Intel 发行版、华为发行版等,尽管这些发行版增加了很多开源版本没有的新 feature,但绝大多数公司选择 Hadoop版本时会将把是否收费作为重要指标,不收费的 Hadoop 版本主要有三个(均是国外厂商),分别是:
- Cloudera 版本(Cloudera’s Distribution Including Apache Hadoop,简称“CDH”)- 用的最多,最稳定
- Apache 基金会 hadoop
- Hortonworks 版本(Hortonworks Data Platform,简称 “HDP”)。
按照上面的先后顺序代表了在国内的使用率,CDH 和 HDP虽然是收费版本,但是他们是开源的,只是收取服务费用。
对于国内而言,绝大多数选择 CDH 版本,主要理由如下:
- 1.CDH 对 Hadoop 版本的划分非常清晰
- 2.CDH文档清晰,很多采用 Apache 版本的用户都会阅读 cdh 提供的文档,包括安装文档、升级文档等。
- 3.HDP 版本时比较新的版本,目前与 apache 基本同步,因为 Hortonworks 内部大部分员工都是 apache 代码贡献者,尤其是 Hadoop 2.x 的贡献者。
版本选择(很重要)
当我们决定是否采用某个软件用于开发环境时,通常需要考虑以下几个因素:
- 是否为开源软件,即是否免费。
- 是否有稳定版,这个一般软件官方网站会给出说明。
- 是否经实践验证,这个可通过检查是否有一些大公司已经在生产环境中使用
- 是否有强大的社区支持,当出现一个问题时,能够通过社区、论坛等网络资源快速获取解决方法。
3. 集群规划
1.主机规划
Zookeeper 最小集群是3节点集群,学习使用足够,生产环境可以根据实际资源情况使用5或7或9节点 Zookeeper 集群。(公司中根据情况一般用5或7个节点)
| Hadoop01 | Hadoop02 | Hadoop03 | |
|---|---|---|---|
| Zookeep | 是 | 是 | 是 |
2.软件规划
JDK 使用工作中常用的版本 jdk1.8 ,选择 CDH 版本的 Zookeeper 与 Hadoop 兼容即可。
| 软件 | 版本 | 位数 |
|---|---|---|
| JDK | 1.8 | 64 |
| Centos | 6.5 | 64 |
| Zookeeper | zookeeper-3.4.4-cdh5.10.0.tar.gz | |
| Hadoop | hadoop-2.6.0-cdh5.10.0.tar.gz |
3.用户规划
大数据平台集群软件统一在 hadoop 用户下安装
| 节点名称 | 用户组 | 用户 |
|---|---|---|
| Hadoop01 | Hadoop | Hadoop |
| Hadoop02 | Hadoop | Hadoop |
| Hadoop03 | Hadoop | Hadoop |
4.目录规划
为了方便统一管理,提前规划好软件目录、脚本目录和数据目录。
| 名称 | 路径 |
|---|---|
| 所有软件目录 | /home/hadoop/app |
| 脚本目录 | /home/hadoop/tools |
| 数据目录 | /home/hadoop/data |
4. 环境准备
1.时钟同步
因为 Hadoop 对集群中各个机器的时间同步要求比较高,要求各个机器的系统时间不能相差太多,不然会造成很多问题。比如,最常见的连接超时问题。所以需要配置集群中各个机器和互联网的时间服务器进行时间同步,但是在实际生产环境中,集群中大部分服务器是不能连接外网的,这时候可以在内网搭建一个自己的时间服务器(NTP服务器),然后让集群的各个机器与这个时间服务器定时的进行时间同步。
如何搭建时间服务器呢?
以主机名为 hadoop01 的机器为例。
1)首先查看一下该机器的时间
输入命令: date 查看当前节点时间。从结果可以看到当前时间为 EST(东部标准时间,即纽约时间),我们处在中国,所以可以把时间改为 CST (中部标准时间,即上海时间)。
2)如何修改时间标准?
只需要在所有节点执行命令:
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
实际上就是把 Shanghai 时间的文件复制到 localtime 中。
注意:上面操作在3个节点都要执行,保证系统当前时间标准为上海时间。OK,接下来进行时钟同步的配置。
3)配置 NTP 服务器
我们选择第一台机器(hadoop01)为 NTP 服务器,其他机器和这台机器进行定时的时间同步。
- (a)检查 NTP服务是否已经安装
- 输入命令:rpm-qa | grep ntp 即可
- 如果没有安装就输入命令 yum install -y ntp 进行安装。
- (b)修改配置文件 ntp.conf
- 输入命令:vi /etc/ntp.conf 然后进行如下修改:
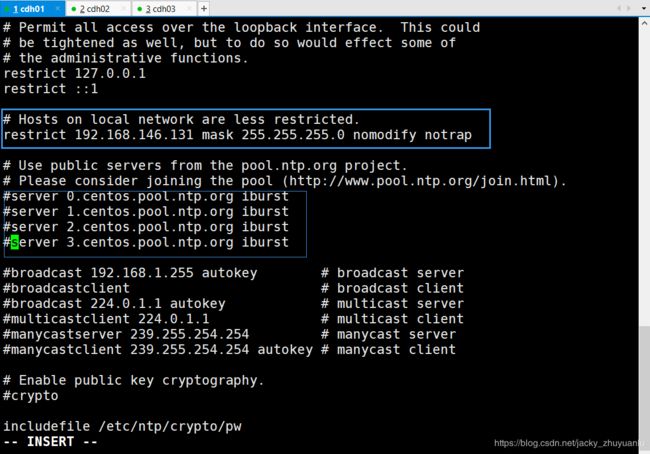
- i)启用 restrict,限定该机器网段,具体操作如下:将restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap 行的注释去掉,并且将网段改为自己本机的网段,我们这里是146网段。当然也可以直接输入本机的 IP 地址。
- ii)注释掉 server 域名配置:以上4个 server 是时间服务器的域名,这里不需要连接互联网,所以将他们注释掉。
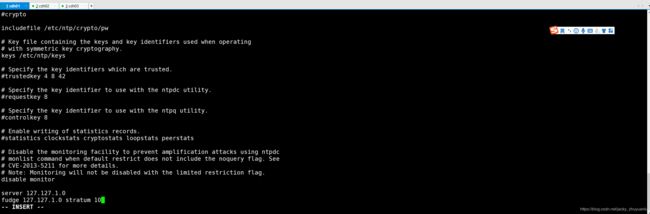
- iii)在该文件中添加下边两行,让本机和本地硬件时间同步。server 127.127.1.0 ||||||||||||||| fudge 127.127.1.0 stratum 10
- 默认的配置文件里这两个是被注释掉的。NTP 服务器会根据这里的配置,把自己的时间作为 NTP 服务器的时间,即和自己同步。考虑到有的局域网里不可以访问外网,所以这里需要配置该配置项。
- 默认的配置文件里这两个是被注释掉的。NTP 服务器会根据这里的配置,把自己的时间作为 NTP 服务器的时间,即和自己同步。考虑到有的局域网里不可以访问外网,所以这里需要配置该配置项。
- 输入命令:vi /etc/ntp.conf 然后进行如下修改:
- (c)启动 NTP 服务
- 输入命令 systemctl start ntpd
- 输入命令 systemctl enable ntpd 即可。这样每次机器启动时,NTP 服务都会自动启动。
这里提供方法解决问题:
1.通过命令 systemctl enable ntpd 设置NTP服务开机自启动。
2.重启虚拟机后查看 服务运行状态 systemctl status ntpd ,发现服务并没有成功启动。
3.查看chrony是否被设置为开机自启动。通过指令 systemctl is-enabled chrony 查看,发现这个服务已经被设置为开机自启动所以导致NTP服务的自启动失败。
4.所以要把 chrony 的自启动去掉。执行指令 systemctl disable chrony 。
5.重启虚拟机, 执行 systemctl status ntpd ,问题解决。
4)配置其他机器的定时时间同步
实际上配置其他机器的时间服务器时钟同步并不难,只需要在对应机器输入命令:crontab -e 即可,然后在会话中输入:
0-59/10 * * * * /usr/sbin/ntpdate hadoop01
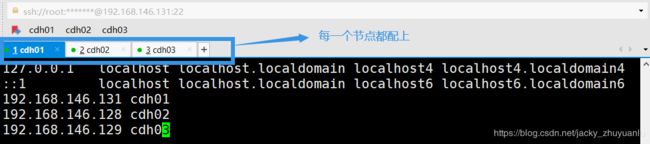
2.Hosts 文件配置
配置集群所有节点 ip 与 hostname 的映射关系
vi /etc/hosts
3. 集群脚本准备
创建 /home/hodoop/tools 脚本存放目录
mkdir /home/hadoop/tools
1)编写脚本配置文件和分发文件
vi deploy.conf

2)开发远程拷贝脚本
vi deploy.sh
#!/bin/bash
if [ $# -lt 3 ]
then
echo "Usage:./deploy.sh srcFile(or Dir) descFile(or Dir) MachineTag"
echo "Usage:./deploy.sh srcFile(or Dir) descFile(or Dir) MachineTag confFile"
exit
fi
scr=$1
dest=$2
tag=$3
if [ 'b'$4'b' == 'bb' ]
then
confFile=/home/hadoop/tools/deploy.conf
else
confFile=$4
fi
if [ -f $confFile ]
then
if [ -f $src ]
then
for server in `cat $confFile | grep -v '^#' |grep ','$tag',' |awk -F',' '{print $1}'`
do
scp $src $server":"$dest
done
elif [ -d $src ]
then
for server in `cat $confFile | grep -v '^#' |grep ','$tag',' |awk -F',' '{print $1}'`
do
scp -r $src $server":"$dest
done
else
echo "Error:NO source file exist"
fi
else
echo "Error:please assign config file"
fi
给脚本添加权限
chmod u+x deploy.sh


测试
./deploy.sh deploy.conf /home/hadoop/ slave