利用Lucene实现全文搜索
之前在我的项目【BBS】中做了一个站内搜索功能,旨在实现主题和内容的搜索,并且实现前端高亮显示。
查阅相关资料,发现利用普通的关系型数据库(模糊查询)是无法实现的,于是开始研究Lucene全文搜索,经过不懈努力,
最终将Lucene全文搜索成功的应用到了我的项目中,很开心,这篇文章就给大家分享下Lucene全文搜索的经验。
在这之前还是给大家看看Lucene全文搜索在实际项目中的应用效果吧,下图是我的项目【BBS】的站内搜索功能:
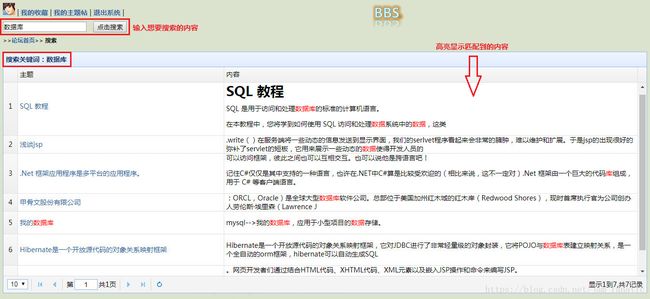
Lucene存储数据不是将数据存储在数据库中,而是通过特定的编码后将数据存储在磁盘上或者是内存中,使用Lucene全文搜索速度非常的快,原因是我们每次存储一个数据对象时,它都会将其创建索引进行存储,这样下次在查找的时候就会很快。
简单说说Lucene的工作原理:
存储过程:
1.利用分词器对将要存储的数据进行分词处理
2.为分词后的数据创建索引
3.将创建好的索引进行存储
查询过程:
1.利用分词器对将要搜索的数据进行分词处理
2.使用分词后的数据到索引库进行查询
3.将查询出的数据进行高亮处理
这就是Lucene存储和查询的基本工作原理,低层很复杂,我也只是简单了解并会简单的使用(如有错误,还请指正)
下面着重说几个点:
分词器
分词器的作用就是将很长的文字内容进行分词(拆分),比如将
【快乐的一只小青蛙】分词后得到【快乐】,【的】,【一只】,【小】,【青蛙】。
当然了,这算是比较好的分词效果了,不同的分词器,效果是不同的,有官方提供的分词器(对中文分词效果差),
也有第三方提供的分词器,都是通过实现Analyzer接口来实现的,我用的分词器是MMSegAnalyzer,
分词后可以通过分词查看器(luke-javafx)进行查看。
索引创建
索引创建是将一个Document对象进行索引,而这个Document对象其实就像是关系型数据库中的一张表,可以向该对象中添加字段,如我用到的例子中Document添加的【title】和【content】两个字段,进行存储时也是将该Document对象进行存储,以后查询的时候就可以将整个Document对象查询出来。
索引存储
索引的存储可以存在磁盘上,也可以存在内存中,磁盘和内存的区别想必大家都知道的,我就不多说了,另外还有要注意存储索引时有三个模式:
CREATE_OR_APPEND:创建或增加(之前没有索引记录就创建,有就增加记录)
APPEND:增加(有索引记录就增加,没有不做任何处理)
CREATE:创建(删除之前的索引记录,新建索引记录)
查询
查询时为了保证正确率,采用的分词器应该和创建索引时是一致的,不然的话会导致查询正确率偏低,也就是匹配不上索引,
查询时应该到创建索引时的索引库中进行查询。
高亮处理
高亮处理就是将查询所匹配到的内容进行特殊处理,以方便观察,根据自己的情况来决定将匹配到的内容做何种处理,我这个例子是将匹配到的内容输出到html页面时显示为红色。
代码部分
这是个简单的案列,我创建的是maven项目,并用到了单元测试,在pom.xml中添加如下依赖:
org.apache.lucene
lucene-core
7.2.1
org.apache.lucene
lucene-highlighter
7.2.1
org.apache.lucene
lucene-queryparser
7.2.1
com.chenlb.mmseg4j
mmseg4j-solr
2.3.0
junit
junit
4.12
pom.lastUpdated
下面是java代码:
package com.yc.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.highlight.Fragmenter;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.InvalidTokenOffsetsException;
import org.apache.lucene.search.highlight.QueryScorer;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
import org.apache.lucene.search.highlight.SimpleSpanFragmenter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
import com.chenlb.mmseg4j.analysis.MMSegAnalyzer;
/**
* 基于MMSegAnalyzer分词器,磁盘存储的搜索引擎
*
* @author Administrator
*
*/
public class LuceneMmseg4jUtil {
// 分词器
Analyzer analyzer = new MMSegAnalyzer();
// 存放索引的路径
String direct = "G:\\index";
/**
* 创建索引并进行存储
*
* @param title
* @param content
* @throws IOException
*/
public void index(String title, String content) throws IOException {
Directory directory = FSDirectory.open(Paths.get(direct));
IndexWriterConfig iwConfig = new IndexWriterConfig(analyzer);
// 设置创建索引模式(在原来的索引的基础上创建或新增)
iwConfig.setOpenMode(OpenMode.CREATE_OR_APPEND);
/*
* 添加索引,在之前的索引基础上追加
* iwConfig.setOpenMode(OpenMode.APPEND);
* 创建索引,删除之前的索引
* iwConfig.setOpenMode(OpenMode.CREATE);
*/
IndexWriter iwriter = new IndexWriter(directory, iwConfig);
// 创建一个存储对象
Document doc = new Document();
// 添加字段
doc.add(new TextField("title", title, Field.Store.YES));
doc.add(new TextField("content", content, Field.Store.YES));
// 新添加一个doc对象
iwriter.addDocument(doc);
// 创建的索引数目
int numDocs = iwriter.numDocs();
System.out.println("共索引了: " + numDocs + " 个对象");
// 提交事务
iwriter.commit();
// 关闭事务
iwriter.close();
}
/**
* 高亮处理
*
* @param query
* @param fieldName
* @param fieldContent
* @return
* @throws IOException
* @throws InvalidTokenOffsetsException
*/
public String displayHtmlHighlight(Query query, String fieldName, String fieldContent)
throws IOException, InvalidTokenOffsetsException {
// 设置高亮标签,可以自定义,这里我用html将其显示为红色
SimpleHTMLFormatter formatter = new SimpleHTMLFormatter("", "");
// 评分
QueryScorer scorer = new QueryScorer(query);
// 创建Fragmenter
Fragmenter fragmenter = new SimpleSpanFragmenter(scorer);
// 高亮分析器
Highlighter highlight = new Highlighter(formatter, scorer);
highlight.setTextFragmenter(fragmenter);
// 调用高亮方法
String str = highlight.getBestFragment(analyzer, fieldName, fieldContent);
return str;
}
/**
* 查询方法
*
* @param text
* @return
* @throws IOException
* @throws ParseException
* @throws InvalidTokenOffsetsException
*/
public List> search(String text)
throws IOException, ParseException, InvalidTokenOffsetsException {
// 得到存放索引的位置
Directory directory = FSDirectory.open(Paths.get(direct));
DirectoryReader ireader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(ireader);
// 在content中进行搜索
QueryParser parser = new QueryParser("content", analyzer);
// 搜索含有text的内容
Query query = parser.parse(text);
// 搜索标题和显示条数(10)
TopDocs tds = searcher.search(query, 10);
List> list = new ArrayList>();
Map map = null;
// 在内容中查获找
for (ScoreDoc sd : tds.scoreDocs) {
// 获取title
String title = searcher.doc(sd.doc).get("title");
// 获取content
String content = searcher.doc(sd.doc).get("content");
// 内容添加高亮
QueryParser qp = new QueryParser("content", analyzer);
// 将匹配到的text添加高亮处理
Query q = qp.parse(text);
String html_content = displayHtmlHighlight(q, "content", content);
map = new HashMap();
map.put("title", title);
map.put("content", html_content);
list.add(map);
}
return list;
}
/**
* 删除索引方法
*
* @param filed
* @param keyWord
* @throws IOException
*/
public void delete(String filed, String keyWord) throws IOException {
Directory directory = FSDirectory.open(Paths.get(direct));
IndexWriterConfig iwConfig = new IndexWriterConfig(analyzer);
// 在原来的索引的基础上创建或新增
iwConfig.setOpenMode(OpenMode.CREATE_OR_APPEND);
IndexWriter iwriter = new IndexWriter(directory, iwConfig);
// 删除filed中含有keyWord的索引
iwriter.deleteDocuments(new Term(filed, keyWord));
// 提交事务
iwriter.commit();
// 关闭事务
iwriter.close();
}
@Test
// 创建索引测试
public void indexTest() throws IOException {
LuceneMmseg4jUtil lucene = new LuceneMmseg4jUtil();
lucene.index("我的简介", "大家好,我叫小铭,我的专业是网络工程");
lucene.index("我的专业", "我的专业是网络工程");
}
@Test
// 查询测试
public void searchTest() throws IOException, ParseException, InvalidTokenOffsetsException {
LuceneMmseg4jUtil lucene = new LuceneMmseg4jUtil();
List> list = lucene.search("网络工程");
for(Map map:list) {
System.out.println(map);
}
}
@Test
// 删除索引测试
public void deleteTest() throws IOException {
LuceneMmseg4jUtil lucene = new LuceneMmseg4jUtil();
lucene.delete("title", "简介");
}
}
创建索引
运行indexTest()这个方法后,控制台输出:

到我们存储索引的磁盘路径看看,可以看到如下的一些文件:

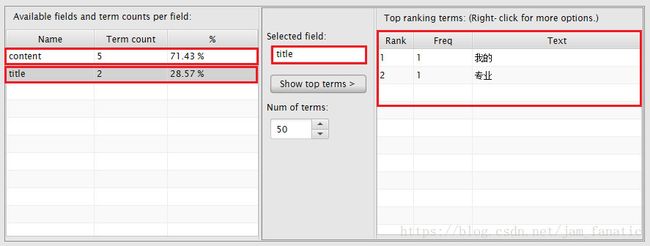
然后我们再利用索引查看工具(luke-javafx)进行查看,有title和content两个字段,先看看title字段分词效果:

再来看看content字段分词效果:

查询
执行查询方法searchTest(),可以在控制台看到如下内容:

很完美的查询出我们想要查询的数据,并且将匹配到的内容进行了高亮处理。
删除索引
下面我们测试下删除索引的方法,执行deleteTest()方法,再利用分词查看器进行查看,可以看到,title字段匹配到"简介"的数据Document对象已经被删除了:

再运行查询方法searchTest(),看看到底有没有被删除:

很明显,数据对象已经被我们删除了,很完美。
这样,我们便利用Lucene实现了全文搜索,想要存储复杂的数据对象,只需要对Document对象的字段进行设计就可以了,这个例子只是简单地入个门,Lucene很强大,想要很好的利用Lucene,还需要进一步的学习。
好了,关于Lucene全文搜索的入门经验分享到此,所有分享内容都是自己学习总结的,如有错误,欢迎指正。
文章属原创,如需引用,请注明出处。