十分钟看懂时序数据库(IV)- 分级存储
物联网领域近期如火如荼,互联网和传统公司争相布局物联网。作为物联网领域数据存储的首选,时序数据库也越来越多进入人们的视野,而早在2016年7月,百度云在其天工物联网平台上发布了国内首个多租户的分布式时序数据库产品TSDB,成为支持其发展制造,交通,能源,智慧城市等产业领域的核心产品,同时也成为百度战略发展产业物联网的标志性事件。
前文提到低成本的存储是时序数据库需要解决的一个主要问题,而上一篇文章介绍了通过针对时序数据的压缩方法,从利用数据本身特征的方面,降低时序数据的存储成本。
本文将介绍通过对数据进行分级存储,从使用不同存储介质,以及减少数据的副本数的方面,介绍如何在保证时序数据的查询性能的前提下,降低时序数据的存储成本。
1.分级存储
分级存储,就是按某一特征,将数据划分为不同的级别,每个级别的数据存储在不同成本的存储介质上。为什么需要对数据进行分级存储?为什么不把所有的数据都存储在最便宜的存储介质上?这是因为在降低存储成本的同时,还需要保证数据访问的性能(我们知道,存储介质的读写性能与成本一般成正比),分级存储是对两者比较好的平衡方法。分级存储的这一思想也体现在计算机的体系结构里(寄存器、L1/L2 Cache、内存、硬盘)。
2.时序数据的分级存储
时序数据应该按什么特征进行分级呢?时序数据的时间戳是一种非常合适的分级依据,越近期的数据查询得越多,是热数据;越久以前的数据查询得越少,是冷数据。例如,用户会经常查询一个设备的最新温度,或者查看这个设备最近1小时或者最近1天的温度曲线;很难想象用户会经常查询一个设备1年前的温度,这些1年前的数据一般会用于大数据分析或者机器学习中,而这些批处理的场景一般对查询的延时不会像交互式场景那么敏感。
如图1所示,一般可以将时序数据分为3级,第一级是最近1天的数据保存在内存缓存Cache中,第二级是最近1年的数据存储在固态硬盘SSD中,第三级是1年以上的数据存储在机械硬盘HDD中。Cache中的数据可以使用写回(write back)或者写通(write through)的策略写入SSD,而SSD中的数据可以通过后台程序定期批量的迁移到HDD。为了保证数据持久性,一般会为数据保存2个或者3个副本,通过EC编码可以将副本数降低到1.5甚至更低,但却不影响数据的持久性。不过EC编码会消耗更多的CPU和网络带宽,进而影响查询性能,因此一般只应用在存储冷数据的HDD上。

图1 时序数据的分级存储
3.内存缓存
时序数据库大部分请求的数据都集中在最近1天,将这些数据保存在内存中,可以保证这些数据能被快速的读取。虽然内存的访问速度快,但是成本很高(价格大约比SSD高一个数量级),并且容量有限。因此需要对数据进行压缩,以减少每个数据的内存占用,压缩相关的内容已经在上一篇文章中进行了介绍,在这里不再赘述。另一方面,由于内存中的数据是易失的、非持久化的,一旦重启进程或者重启机器后就会丢失,如果不恢复数据,所有请求将落到下一级的存储上,对下一级存储造成巨大的压力。因此一般会在写入内存的同时写入本地硬盘,在重启后重新加载到内存中。
Beringei(注1)是Facebook开源的一款内存时序数据库,是Facebook发表的Gorilla论文(注2)的开源实现。Beringei使用一种三级的内存数据结构,如图2所示,其中第一级为分片索引,第二级为时间序列索引,第三级为时序数据,通过该数据结构可以支持快速的数据读写;Beringei实现了一种高效的流式的压缩算法,从而使内存占用最小化;Beringei支持写入内存的同时写入硬盘,并在重启后恢复数据。然而Beringei也有一些限制,譬如只支持浮点型数值、时间精度只到秒、只能按时间戳顺序的写入数据。
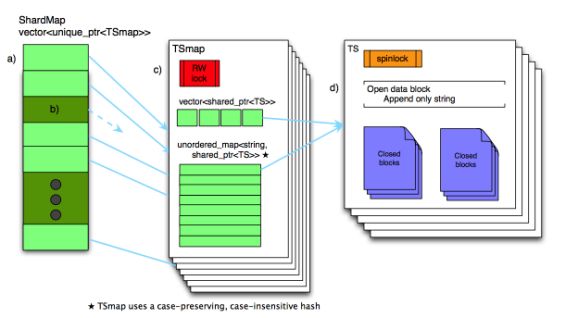
图2 Beringei的内存数据结构(注2)
4.SSD与HDD
用户有时会关注时序数据在过去1周、过去1个月、过去1年的趋势,把最近1年的数据存储在固态硬盘SSD上,可以实现在秒级甚至亚秒级读取过去1年的数据。而1年以上的时序数据则很少用于交互式查询,这些数据往往会用于大数据分析或者机器学习,这些批处理场景对查询的延时不会像交互式场景那么敏感,因此可以把这些1年以上的数据存储在机械硬盘HDD上。
SSD的价格大约是HDD的几倍,但是SSD的性能要远远高于HDD。在前文中我们介绍过,时序数据库会对时序数据进行分片,一个分片的数据会连续的存放在一台机器的硬盘上,因此读取一个分片的数据是顺序读取的。对于顺序读取来说,SSD和HDD的性能是差不多的,因此这种存储方式对于SSD和HDD来说都是合适的。但是,一台机器上会存储大量的分片,当同时读取多个分片时,硬盘的访问就变成了随机读取。对于随机读取来说,HDD由于需要平均10毫秒的寻道时间,因此只能做到百这个量级的IOPS,而SSD能做到万级甚至十万级的IOPS,比HDD高2到3个数量级(注3)。由此可见,HDD只能应付批处理这种并发量较低、顺序读取大量数据的场景,而只有SSD能支持高并发、低延时的交互式查询场景。
5.EC编码
为了保证时序数据在机器宕机、硬盘故障的时候还能正常的访问、不会丢失,也就是为了保证数据的可用性和持久性,会为数据保存多个备份(也称为副本),根据可用性和持久性的需求一般是保存2到3个副本,这样当其中的1个或者2个机器宕机、硬盘故障的时候也能保证数据的正常访问以及不会丢失。但是这也大大增加了存储的成本,3个副本就是3倍的存储成本。通过EC编码,可以将存储成本降到1.5倍,同时不会降低数据的可用性和持久性。
EC编码全称是Erasure Coding纠删码,是一种数据保护技术,最早应用于通信行业的数据传输的数据恢复中,同时也用于RAID-5和RAID-6存储阵列技术中。EC编码主要是利用算法对原始数据块进行编码得到校验块,并将原始数据块和校验块都存储起来。当原始数据块丢失时,通过其他原始数据块以及校验块能重新计算出丢失的数据块;当校验块丢失时,重新计算即可得到校验块。这样就能对丢失的数据进行恢复,从而达到容错的目的。对于k个原始数据块和m个校验块,算法能保证在丢失任意m个块后,都可以通过算法恢复出原来的k个原始数据块。如图3所示,一个生成矩阵GT乘以k个原始数据块组成的向量,可以得到由k个原始数据块和m个校验块组成的向量。
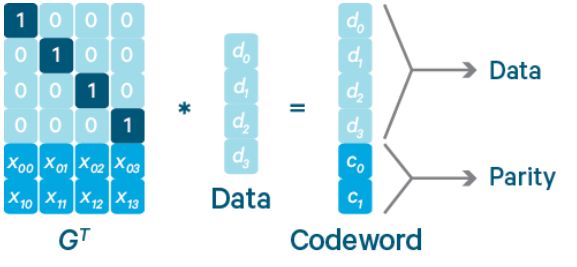
图3 EC编码过程(注4)
将EC编码应用于时序数据,关键问题在于如何定义什么是数据块。一种直观的方法是一个分片作为一个数据块(注意,一个分片是存储在一个机器上的,不同的数据块是存储在不同机器上的,因此不应该把一个分片再划分为多个数据块)。但是由于分片的数据量不一致,需要将数据块都对齐到最大的数据块,而且得到的校验块也是跟最大的数据块一样大,这会导致存储空间和计算资源的浪费。举个极端的例子,譬如1个分片的大小是1M,其他k-1个分片的大小都是1K,那么就需要将这k-1个分片都对齐(可以通过补0)到1M再计算EC编码,得到的m个校验块都是1M的。更好的方法是利用底层存储的数据块作为EC编码的数据块,譬如使用Hbase存储时序数据的话,就可以利用底层HDFS提供的EC编码功能(注4)。
6.总结
根据时序数据天然的时序上的冷热划分,可以对时序数据进行分级存储,将最近的最热的数据保存在内存中,将中期的次热数据存储在SSD上,将远期的冷数据存储在HDD上,能在保证查询性能的前提下,降低存储成本。另外,通过EC编码技术,能减少数据的副本数,从而使存储成本能降至更低的水平。
注1:https://github.com/facebookincubator/beringei
注2:http://www.vldb.org/pvldb/vol8/p1816-teller.pdf
注3:https://blog.acolyer.org/2016/01/22/all-change-please/
注4:https://blog.cloudera.com/blog/2015/09/introduction-to-hdfs-er