如何构建一个反电信网络诈骗基础模型
如何构建一个反电信网络诈骗基础模型
2017-05-10 11:26 浏览次数:413
文|西角边的MR
网络诈骗,电信诈骗层出不穷,花样翻新,防不胜防,伤害普通百姓利益。本文通过对目前社会上关于网络电信诈骗新闻进行提取,从中分析当前网络诈骗发展趋势和关键因素,进而构建合理的反诈骗模型。
一、对关键词的分析
参考
如何从新闻中识别骗子们的小套路
爬虫获取了网站关于电信诈骗的新闻。

其中keyword是通过jieba对文本进行分词得到的。对于关键词的分析主要从两个方面考虑,一个是关键词之间是否有诈骗逻辑,第二是对具有诈骗逻辑的关键词进一步分析,分为消极词汇(例如你被法院传讯了)和积极词汇(例如你又双叒叕成为幸运观众了),这两种词汇在诈骗中对受害者产生的心理影响是不同的。
1、首先笔者构建一个词语出现的频率表(指标矩阵)。
由于爬虫爬取的时间格式具体到秒,要以天为单位进行的关键词统计,实现方法是以时间为索引构建时间和关键词词典。
时间和关键词的指标矩阵如上图所示,并将它存为csv文件以便后续处理。
通过构建指标矩阵可以大致得知这些关键词出现的日期和频率,为后期构建关键词词组打下基础。
2、对于关键词分析
接下来用pandas读取上述csv文件,获得一个Dataframe类型的变量来处理。
假设对于同一天出现在同一篇文章的关键词具有相关性。
Dataframe里有自定义的函数corr可以求得每个column之间的相关系数,经过index转换后得到一张相关性系数表。
经过计算后,笔者发现这里面的相关性系数有正有负,当相关性系数大于0时,可以认为这个词组存在诈骗逻辑。
对于变量大于0的情况,还要进一步分类,计算它们的情感态度值。通过查阅资料,笔者发现需要许多数据才能构成一张情感态度分值表,所以笔者使用了现成的snowNLP的工具包来获得其态度值,并以0.5为界限进行积极和消极分类,可视化展示如下:
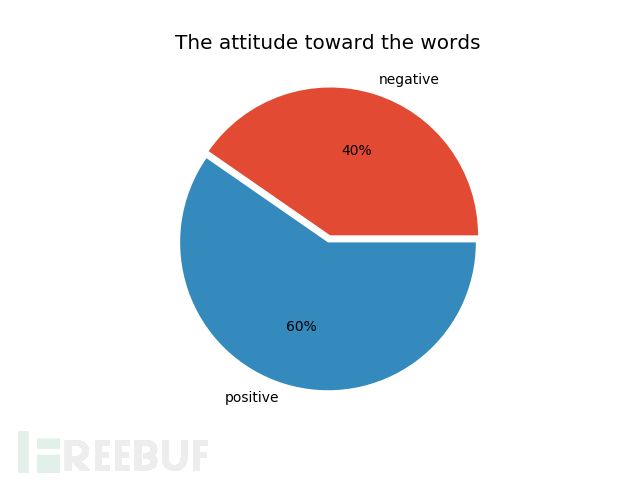
以csv的形式存储获取的数据,这个比例以后会用于计算诈骗概率。
从中我们便获取了具有假设网络诈骗逻辑的词组。
二、对关键词是否具有相关性的判断
对于用于判断新的文本中提取出来的关键词是否具有电信网络诈骗的相关性,我们可以尝试如下方法
1、概率计算
对关键词的相关性统计如下:
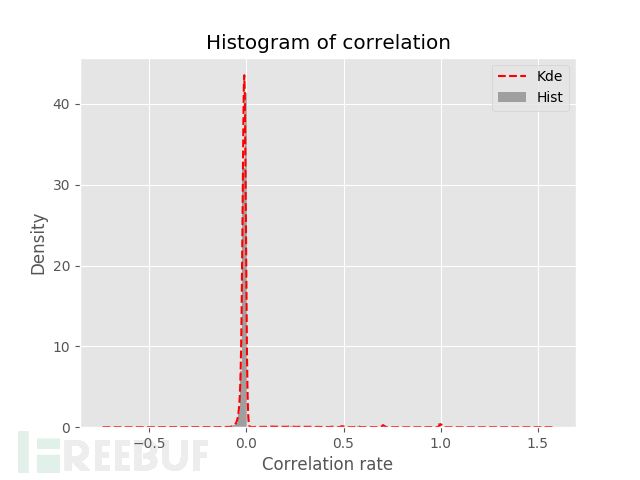
从图中可以知道大部分词语之间都是不能构成诈骗逻辑,在0.5,0.75和1左右只有很少一部分词语。如果数据量够大的话或许可以采用这种方法。所以并不建议使用此类方法。
2、分类方法
对于获取的词组,可以分为有相关性(>0)和没有相关性的(<0)两类,构建为机器学习样本({word1:value,word2:value,word3:value},class:value)。然后将样本分为训练集和测试集。这里笔者分别使用了朴素贝叶斯的方法和决策树的方法并进行了比较。这个分类器可以自己尝试写,也可以使用nltk里的自带函数来处理。

构建的样本代码如上图。
上图是使用bayes和tree进行分类,并计算准确度。
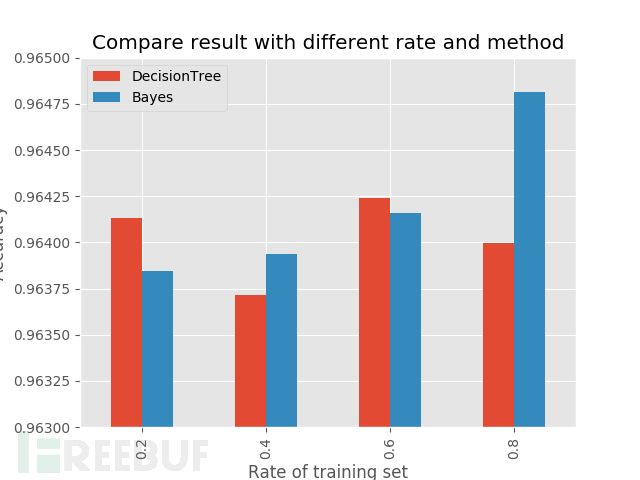
从图中发现训练集和测试集按照4:1进行分类时,使用bayes的精确度最为合适。
从中可以对新提取的关键词来判断是否具有相关性,而这个相关性也就是指符合电信网络诈骗的逻辑思维。对于具有这种相关性的新词组,可以继续对词组的情感态度进行进一步分类。
三、对诈骗出现时间特点的选取
网络电信诈骗中,时间因素也是一个很重要的参量。
一般节假日是案件的高发期,所以计算诈骗概率的时候要结合时间因素。怎样对时间采样可以获得一个比较准确的概率预测?这里笔者采用了以季度为单位和以月份为单位的预测模型。
笔者首先统计出这些新闻出现的大致变化趋势,新闻能从一定程度上反映当前社会对于诈骗案件的关注程度。

橙黄色表示的是当日对网络电信诈骗新闻的报道篇数,红色表示一周左右的一个移动平均数,灰色是移动平均标准差。从中大致可以看出电信网络诈骗的出现频率大致上是随某一热度时间出现。
为了能够更好的分别热度出现的时间阈值,笔者对时间进行按月统计和按季度统计。
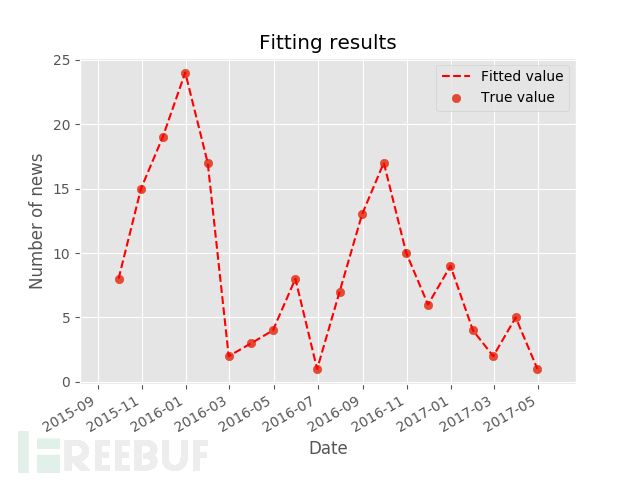
这是以月份为采样的统计,并进行了拟合后的结果。从中分析电信网络案件在1月,9月呈现高发态势。
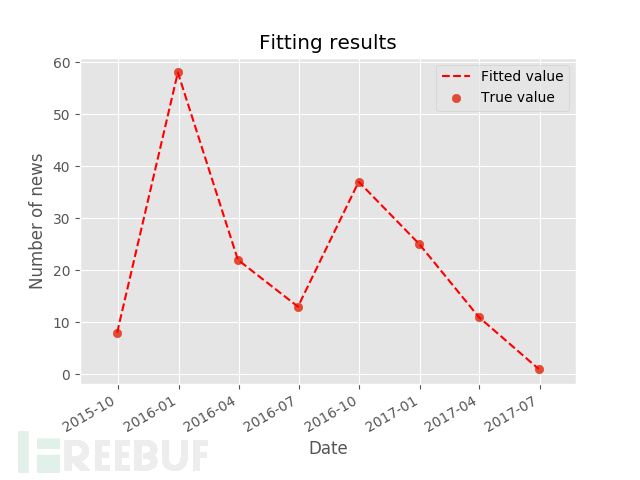
这是以季度为采样的统计,并进行了拟合。从图中大概可以看出一般在每年的四季度到下一年的一季度,每年的暑假到开学这季度,电信网络诈骗案件呈现高发态势。
为了能够准确统计诈骗随时间变化的趋势,笔者使用类似决策树算法的方法来计算两种采样频率的信息熵。
这是两种采样对于不同阶数的拟合误差,如下图所示:

以月份为采样,对于不同阶数的拟合误差。
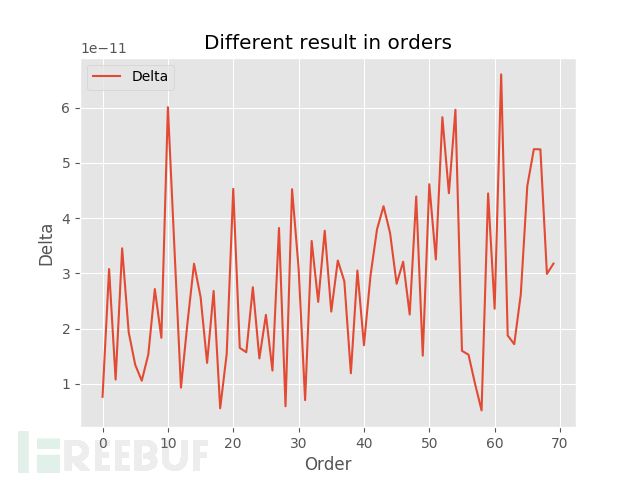
以季度为采样,对于不同阶数的拟合误差。
经过决策计算后,以季度为采样频率的计算反映诈骗随时间变化的趋势更为准确。当然拟合曲线是否具有预测性还等待确定。不过目前一个可行的方法就是以季度为采样,统计各个季度的出现频率并使用回归模型预测(这里也试用过ARIMA模型,但是并没有将这个划归为平稳曲线,所以目前这只能这样做)。
四、结论
1、电信网络诈骗中,更趋向于使用一些积极词汇,例如中奖等信息来对用户实施诈骗。
2、电信网络诈骗的大致发展趋势是上一年的最后季度和年初的第一季度,从中可以大致得出其主要是利用了受害者在过年时放松警惕,易轻信他人的特点。
3、每年的开学季也是电信网络诈骗的一个次要高峰期,这一阶段的主要对象是学生群体,利用家长,学生的求学的心理来针对性的实施诈骗。
五、总结
通过对于关键词和时间序列的分析,在构建网络及电信诈骗模型的时候,我们要综合考虑一下几点:
1、从文章中提取的关键词要进行相关性分类和情感态度分类。相关性分类是为了获取具有诈骗逻辑的关键词组,情感态度分类是为了对具有诈骗逻辑词组的词语进行积极和消极分类。
2、对于新出现的词组判断是否具有相关性可以利用已有的相关性词汇表,构建训练集组成机器学习模型。
3、对于时间因素来说,要选择合适的时间采样频率。实现方法是以不同的时间间隔,计算相应时间间隔内新闻出现的频率,计算不同时间间隔的信息熵并进行比较,最终选择出对应信息熵较低的时间频率。
当然我们同时也要不断提高自己的防范意识,不轻信,不贪占小便宜,对自己的财产安全负责。