简单全面学习java8新特性Stream-API中的Reduce&Collect(三)
简单全面学习java8新特性Stream-API中的Reduce&Collect(三)
- 涉及知识(参数函数接口)
- 1. BiFunction
- 2. BinaryOperator
- 3. BiConsumer
- 4. Optional
- 5. Consumer & Function & Predicate
- 6.Supplier
- 1. reduce 归约汇聚
- 一个参数的Optional reduce(BinaryOperator accumulator)
- 两个参数的 T reduce(T identity, BinaryOperator accumulator)
- 三个参数的 U reduce(U identity, BiFunction
涉及知识(参数函数接口)
1. BiFunction
它是一个函数式接口,包含的函数式方法定义如下:
@FunctionalInterface
public interface BiFunction<T, U, R> {
R apply(T t, U u);
与Function接口的不同点在于它接收两个输入,返回一个输出;
而Function接口 接收一个输入,返回一个输出。
注意它的两个输入,一个输出的类型可以是不一样的。
其他方法
default <V> BiFunction<T, U, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t, U u) -> after.apply(apply(t, u));
}
2. BinaryOperator
实际上就是继承自BiFunction的一个接口
@FunctionalInterface
public interface BinaryOperator<T> extends BiFunction<T,T,T> {
上面已经分析了,BiFunction 的三个参数可以是一样的也可以不一样;
而BinaryOperator就直接限定了其三个参数必须是一样的;
因此BinaryOperator与BiFunction的区别就在这。
它表示的就是两个相同类型的输入经过计算后产生一个同类型的输出。
默认实现的两个方法(根据传入的默认比较器)
minBy --返回两个元素中较小的那个
public static <T> BinaryOperator<T> minBy(Comparator<? super T> comparator) {
Objects.requireNonNull(comparator);
return (a, b) -> comparator.compare(a, b) <= 0 ? a : b;
}
maxBy - 返回两个元素中较大的那个
public static <T> BinaryOperator<T> maxBy(Comparator<? super T> comparator) {
Objects.requireNonNull(comparator);
return (a, b) -> comparator.compare(a, b) >= 0 ? a : b;
}
这里需要特殊说明一下,这个传入的比较器如果是顺序的
compare(a, b){
return a-b
}
这样子的,结果的大于0 小于0 是以 a-b的结果算出来的,这样子那两个方法minBy,maxBy就是正确的
如果 结果正负是以 b-a 为依据的,那么他们的结果相反
3. BiConsumer
也是一个函数式接口,它的定义如下:
@FunctionalInterface
public interface BiConsumer<T, U> {
/**
* Performs this operation on the given arguments.
*
* @param t the first input argument
* @param u the second input argument
*/
void accept(T t, U u);
/**
* Returns a composed {@code BiConsumer} that performs, in sequence, this
* operation followed by the {@code after} operation. If performing either
* operation throws an exception, it is relayed to the caller of the
* composed operation. If performing this operation throws an exception,
* the {@code after} operation will not be performed.
*
* @param after the operation to perform after this operation
* @return a composed {@code BiConsumer} that performs in sequence this
* operation followed by the {@code after} operation
* @throws NullPointerException if {@code after} is null
*/
default BiConsumer<T, U> andThen(BiConsumer<? super T, ? super U> after) {
Objects.requireNonNull(after);
return (l, r) -> {
accept(l, r);
after.accept(l, r);
};
}
可见它就是一个有两个输入参数的Consumer的变种。计算没有返回值。
4. Optional
链接: 简单全面学习JDK1.8新特性之流式编程-SreamAPI(二).
中的Optional
5. Consumer & Function & Predicate
链接: JDK1.8新特性lambda表达式&函数式接口(一).
中的常见函数式接口
6.Supplier
/**
* Represents a supplier of results.
*
* There is no requirement that a new or distinct result be returned each
* time the supplier is invoked.
*
*
This is a functional interface
* whose functional method is {@link #get()}.
*
* @param the type of results supplied by this supplier
*
* @since 1.8
*/
@FunctionalInterface
public interface Supplier<T> {
/**
* Gets a result.
*
* @return a result
*/
T get();
}
1. reduce 归约汇聚
reduce中文含义是 减少 缩小 ,在这我称之为汇聚,也有人称之为归约
而 stream中的 reduce方法根据一定的规则将Stream中的元素进行计算后返回一个唯一的值。
主要作用是把 Stream 元素组合起来。它提供一个起始值(种子),然后依照运算规则(BinaryOperator),和前面 Stream 的第一个、第二个、第 n 个元素组合。从这个意义上说,字符串拼接、数值的 sum、min、max、average 都是特殊的 reduce;
在Stream中reduce共有三种重载,分别是一个参数的,两个参数的,和三个参数的
一个参数的Optional reduce(BinaryOperator accumulator)
源码:
/**
* Performs a reduction on the
* elements of this stream, using an
* associative accumulation
* function, and returns an {@code Optional} describing the reduced value,
* if any. This is equivalent to:
* {@code
* boolean foundAny = false;
* T result = null;
* for (T element : this stream) {
* if (!foundAny) {
* foundAny = true;
* result = element;
* }
* else
* result = accumulator.apply(result, element);
* }
* return foundAny ? Optional.of(result) : Optional.empty();
* }
*
* but is not constrained to execute sequentially.
*
* The {@code accumulator} function must be an
* associative function.
*
*
This is a terminal
* operation.
*
* @param accumulator an associative,
* non-interfering,
* stateless
* function for combining two values
* @return an {@link Optional} describing the result of the reduction
* @throws NullPointerException if the result of the reduction is null
* @see #reduce(Object, BinaryOperator)
* @see #min(Comparator)
* @see #max(Comparator)
*/
Optional<T> reduce(BinaryOperator<T> accumulator);
注释里面有讲这个方法的原理
内部执行原理:
boolean foundAny = false;
T result = null;
for (T element : this stream) {
if (!foundAny) {
foundAny = true;
result = element;
}
else
result = accumulator.apply(result, element);
}
return foundAny ? Optional.of(result) : Optional.empty();
还有一句比较重要
遍历流的时候 but is not constrained to execute sequentially.
但不限于按顺序执行
还有要注意的是他返回的是 Optional 类型
再看 参数 accumulator ,他是一个 BinaryOperator,前面讲过
这里用的是他的 apply 方法(传入的两个参数跟返回值都是一个类型的,即是流中元素的类型)
举例:
IntStream ints = IntStream.of(1,2,3,8,2,9,4,5,6);
System.out.println(ints.reduce((x, y) -> x + y).getAsInt());
结果
40
两个参数的 T reduce(T identity, BinaryOperator accumulator)
源码
/**
* Performs a reduction on the
* elements of this stream, using the provided identity value and an
* associative
* accumulation function, and returns the reduced value. This is equivalent
* to:
* {@code
* T result = identity;
* for (T element : this stream)
* result = accumulator.apply(result, element)
* return result;
* }
*
* but is not constrained to execute sequentially.
*
* The {@code identity} value must be an identity for the accumulator
* function. This means that for all {@code t},
* {@code accumulator.apply(identity, t)} is equal to {@code t}.
* The {@code accumulator} function must be an
* associative function.
*
*
This is a terminal
* operation.
*
* @apiNote Sum, min, max, average, and string concatenation are all special
* cases of reduction. Summing a stream of numbers can be expressed as:
*
*
{@code
* Integer sum = integers.reduce(0, (a, b) -> a+b);
* }
*
* or:
*
* {@code
* Integer sum = integers.reduce(0, Integer::sum);
* }
*
* While this may seem a more roundabout way to perform an aggregation
* compared to simply mutating a running total in a loop, reduction
* operations parallelize more gracefully, without needing additional
* synchronization and with greatly reduced risk of data races.
*
* @param identity the identity value for the accumulating function
* @param accumulator an associative,
* non-interfering,
* stateless
* function for combining two values
* @return the result of the reduction
*/
T reduce(T identity, BinaryOperator<T> accumulator);
其执行原理
T result = identity;
for (T element : this stream)
result = accumulator.apply(result, element)
return result;
同样有 but is not constrained to execute sequentially.
但不限于按顺序执行
但是他的返回类型就是流的类型 T
只不过这次初始值不在是null 而是第一个参数 identity
IntStream ints = IntStream.of(1,2,3,8,2,9,4,5,6);
//System.out.println("reduce1:"+ints.reduce((x, y) -> x + y).getAsInt());
System.out.println("reduce2:"+ints.reduce(2,(x,y)->x+y));
Stream sSt = Stream.of("1","2","3","8","2","9","4","5","6");
BinaryOperator<String> operator = (x,y)->x.concat(y);
//System.out.println("reduce2:"+sSt.reduce("2",(x,y)->{return x.toString().concat(y.toString());}));
System.out.println("reduce21:"+sSt.reduce("2",operator));
reduce2:42
reduce21:2123829456
三个参数的 U reduce(U identity, BiFunction accumulator, BinaryOperator combiner)
源码:
/**
* Performs a reduction on the
* elements of this stream, using the provided identity, accumulation and
* combining functions. This is equivalent to:
* {@code
* U result = identity;
* for (T element : this stream)
* result = accumulator.apply(result, element)
* return result;
* }
*
* but is not constrained to execute sequentially.
*
* The {@code identity} value must be an identity for the combiner
* function. This means that for all {@code u}, {@code combiner(identity, u)}
* is equal to {@code u}. Additionally, the {@code combiner} function
* must be compatible with the {@code accumulator} function; for all
* {@code u} and {@code t}, the following must hold:
*
{@code
* combiner.apply(u, accumulator.apply(identity, t)) == accumulator.apply(u, t)
* }
*
* This is a terminal
* operation.
*
* @apiNote Many reductions using this form can be represented more simply
* by an explicit combination of {@code map} and {@code reduce} operations.
* The {@code accumulator} function acts as a fused mapper and accumulator,
* which can sometimes be more efficient than separate mapping and reduction,
* such as when knowing the previously reduced value allows you to avoid
* some computation.
*
* @param The type of the result
* @param identity the identity value for the combiner function
* @param accumulator an associative,
* non-interfering,
* stateless
* function for incorporating an additional element into a result
* @param combiner an associative,
* non-interfering,
* stateless
* function for combining two values, which must be
* compatible with the accumulator function
* @return the result of the reduction
* @see #reduce(BinaryOperator)
* @see #reduce(Object, BinaryOperator)
*/
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
它的基本的处理原理
U result = identity;
for (T element : this stream)
result = accumulator.apply(result, element)
return result;
与两个参数的reduce的区别
双参数的返回类型为 T Stream元素的类型也是 T
三参数的返回类型为 U Stream元素的类型时T,有了更大的发展空间
U可以是T,也可以不是T
与双参数的并无太大区别,主要体现在第三参数的,
其实第三个参数用于在并行计算下 合并各个线程的计算结果
并行流运行时:内部使用了fork-join框架
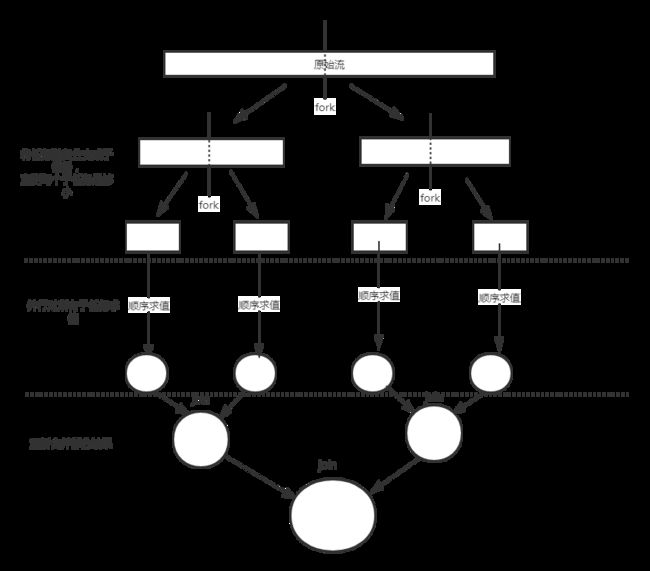
多线程时,多个线程同时参与运算
多个线程执行任务,必然会产生多个结果
那么如何将他们进行正确的合并
这就是第三个参数的作用
通过分析原理代码我们可以知道 result是一直参与运算的
result = accumulator.apply(result, element)
先来测试一把
//以下这种结果不同--原因是没有熟读方法规范(可以说以下这种写法是错误的)
System.out.println("串行reduceTest:"+Arrays.asList(1, 2, 3, 4).stream().reduce(5, (x, y) -> x + y, (x, y) -> x + y));
System.out.println("并行reduceTest:"+Arrays.asList(1, 2, 3, 4).stream().parallel().reduce(5, (x, y) -> x + y, (x, y) -> x + y));
串行reduceTest:15
并行reduceTest:30
原因是
((((5+1)+2)+3)+4) = 15
(5+1)+(5+2)+(5+3)+(5+4) = 30
这就是原因
以上的写法有问题
源码中这一段有详细描述
The {@code identity} value must be an identity for the combiner function. This means that for all {@code u}, {@code combiner(identity, u)} is equal to {@code u}. Additionally, the {@code combiner} function must be compatible with the {@code accumulator} function; for all {@code u} and {@code t}, the following must hold:
{@code combiner.apply(u, accumulator.apply(identity, t)) == accumulator.apply(u, t) }
不懂可以上百度翻译
首先他告诉我们
combiner函数的{@code identity}参数值必须是一个标识
也即是identity值 对与 合并预算combiner 来说是一个恒等式
这意味着对于所有的 u, combiner(identity, u)和u都是相等的
这段话是不是感觉很别扭,但是要记住这是并发场景下使用的
这个result 的初始identity 对于每一个分支都是参与运算的!
所以要要求
任意的u, combiner(identity,u) 和u是相同的
上述结果不对是因为没有达到要求
combiner为 (a,b)->a+b;
那么如果分为两个分支进行运算,我们的初始值identity就参与了两次运算 也就是说多加了一个identity的值!!
如果要满足 u = combiner(identity,u)
只能是 identity = 0,才能够使得u = combiner(identity,u)恒等成立
否则,你就不要用(a,b)->a+b 实现这个combiner
然后
combiner 必须和accumulator要兼容
对于任意的u 和 t
combiner.apply(u, accumulator.apply(identity, t)) == accumulator.apply(u, t)
这是为什么呢?
假设说4个元素 1,2,3,4 需要运算
此时假设已经 1,2,3 三组数据已经运算结束,马上要同第四组运算
如果是并行,我们假定1,2,3 在一个分支 4单独在另一分支
并行时
U为已经计算好的1,2,3后的结果 接下来要与另一组的4 合并
T4则是identity与T参与运算
上面的图就是
combiner.apply(u, accumulator.apply(identity, t))

非并行运算
u 直接与下一个元素进行结合运算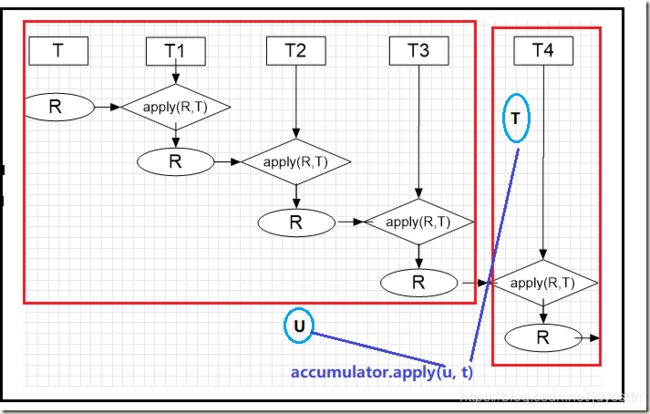
以上两个图片来自 noteless 感谢
显然这只是并行和非并行两种不同的处理运算方式,他们应该是相同的
也就是
combiner.apply(u, accumulator.apply(identity, t)) == accumulator.apply(u, t)
感觉这里的意思好像有种 u与t 同类型的感觉
最后我们把测试用例初始值改成0,再试一下
System.out.println("串行reduceTest:"+Arrays.asList(1, 2, 3, 4).stream().reduce(0, (x, y) -> x + y, (x, y) -> x + y));
System.out.println("并行reduceTest:"+Arrays.asList(1, 2, 3, 4).stream().parallel().reduce(0, (x, y) -> x + y, (x, y) -> x + y));
串行reduceTest:10
并行reduceTest:10
OK 完美,齐活
例外
Stream<String> s1 = Stream.of("aa", "ab", "c", "ad");
//模拟Filter查找其中含有字母a的所有元素,由于使用了r1.addAll(r2),其打印结果将不会是预期的aa ab ad
Predicate<String> predicate = t -> t.contains("a");
s1.parallel().reduce(new ArrayList<String>(), (r, t) -> {if (predicate.test(t)) r.add(t); return r; },
(r1, r2) -> {r1.addAll(r2); return r1; }).stream().forEach(System.out::println);
ad
ad
ab
aa
ad
ad
ab
aa
ad
ad
ab
aa
ad
ad
ab
aa
原因是 在进行合并流的时候 BinaryOperator combiner.apply(r1,r2) 中的两个参数都是同一个对象 new ArrayList(), 只要对同一个对象进行合并就必然会出现 数据重复错误
只要第一个参数的类型
是ArrayList等对象
而非基本数据类型的包装类或者String,
第三个函数的处理上可能容易引起失误
2. collect 收集
R collect(Supplier supplier, BiConsumer accumulator,BiConsumer combiner)
源代码
/**
* Performs a mutable
* reduction operation on the elements of this stream. A mutable
* reduction is one in which the reduced value is a mutable result container,
* such as an {@code ArrayList}, and elements are incorporated by updating
* the state of the result rather than by replacing the result. This
* produces a result equivalent to:
* {@code
* R result = supplier.get();
* for (T element : this stream)
* accumulator.accept(result, element);
* return result;
* }
*
* Like {@link #reduce(Object, BinaryOperator)}, {@code collect} operations
* can be parallelized without requiring additional synchronization.
*
*
This is a terminal
* operation.
*
* @apiNote There are many existing classes in the JDK whose signatures are
* well-suited for use with method references as arguments to {@code collect()}.
* For example, the following will accumulate strings into an {@code ArrayList}:
*
{@code
* List asList = stringStream.collect(ArrayList::new, ArrayList::add,
* ArrayList::addAll);
* }
*
* The following will take a stream of strings and concatenates them into a
* single string:
*
{@code
* String concat = stringStream.collect(StringBuilder::new, StringBuilder::append,
* StringBuilder::append)
* .toString();
* }
*
* @param type of the result
* @param supplier a function that creates a new result container. For a
* parallel execution, this function may be called
* multiple times and must return a fresh value each time.
* @param accumulator an associative,
* non-interfering,
* stateless
* function for incorporating an additional element into a result
* @param combiner an associative,
* non-interfering,
* stateless
* function for combining two values, which must be
* compatible with the accumulator function
* @return the result of the reduction
*/
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
前面我们说中间操作是将一个流转换成另一个流,这些操作是不消耗流的,但是终端操作会消耗流,产生一个最终结果,collect()就是一个规约操作,将流中的结果汇总。结果是由传入collect()中的Collector或者accumulator定义的
其内部主要原理
R result = supplier.get();
for (T element : this stream)
accumulator.accept(result, element);
return result;
元素通过更新合并
结果的状态,而不是替换结果。
参数分析
注释翻译
supplier:动态的提供初始化的值;创建一个可变的结果容器;对于并行计算,这个方法可能被调用多次,每次返回一个新的对象;
accumulator:类型为BiConsumer,注意这个接口是没有返回值的;它必须将一个元素放入结果容器中。
combiner:类型也是BiConsumer,因此也没有返回值。它与三参数的Reduce类型,只是在并行计算时汇总不同线程计算的结果。它的输入是两个结果容器,必须将第二个结果容器中的值全部放入第一个结果容器中。
Collect与分并行与非并行两种情况
并行
Stream<String> s1 = Stream.of("aa", "ab", "c", "ad");
s1.parallel().collect(()->new ArrayList<String>(), (r, t) -> {if (predicate.test(t)) r.add(t); },
(r1, r2) -> {r1.addAll(r2);}).stream().forEach(System.out::println);
aa
ab
ad
串行
Stream<String> s1 = Stream.of("aa", "ab", "c", "ad");
s1.collect(()->new ArrayList<String>(), (r, t) -> {if (predicate.test(t)) r.add(t); },
(r1, r2) -> {r1.addAll(r2);}).stream().forEach(System.out::println);
aa
ab
ad
之所以 collect 在处理集合类上没有出现像reduce 处理集合类的的失误场景是因为
他的实现的Supplier 会让他在并行是每一步都闯将一个新的对象,而不是像reduce那样每个线程都调用同一个对象引用
注释中也在强调结果容器(result container)这个,那是否除集合类型,其结果R也可以是其它类型呢?
先看基本类型,由于BiConsumer不会有返回值,如果是基本数据类型或者String,在BiConsumer中加工后的结果都无法在这个函数外体现,因此是没有意义的。
那其它非集合类型的Java对象呢?如果对象中包含有集合类型的属性,也是可以处理的;否则,处理上也没有任何意义,
combiner对象使用一个Java对象来更新另外一个对象?至少目前我没有想到这个有哪些应用场景。它不同Reduce,
Reduce在Java对象上是有应用场景的,就因为Reduce即使是并行情况下,也不会创建多个初始化对象,combiner接收的两个参数永远是同一个对象,如假设人有很多条参加会议的记录,这些记录没有在人本身对象里面存储而在另外一个对象中;人本身对象中只有一个属性是最早参加会议时间,那就可以使用reduce来对这个属性进行更新。当然这个示例不够完美,它能使用其它更快的方式实现,但至少通过Reduce是能够实现这一类型的功能的
R collect(Collector collector)
源码
/**
* Performs a mutable
* reduction operation on the elements of this stream using a
* {@code Collector}. A {@code Collector}
* encapsulates the functions used as arguments to
* {@link #collect(Supplier, BiConsumer, BiConsumer)}, allowing for reuse of
* collection strategies and composition of collect operations such as
* multiple-level grouping or partitioning.
*
* If the stream is parallel, and the {@code Collector}
* is {@link Collector.Characteristics#CONCURRENT concurrent}, and
* either the stream is unordered or the collector is
* {@link Collector.Characteristics#UNORDERED unordered},
* then a concurrent reduction will be performed (see {@link Collector} for
* details on concurrent reduction.)
*
*
This is a terminal
* operation.
*
*
When executed in parallel, multiple intermediate results may be
* instantiated, populated, and merged so as to maintain isolation of
* mutable data structures. Therefore, even when executed in parallel
* with non-thread-safe data structures (such as {@code ArrayList}), no
* additional synchronization is needed for a parallel reduction.
*
* @apiNote
* The following will accumulate strings into an ArrayList:
*
{@code
* List asList = stringStream.collect(Collectors.toList());
* }
*
* The following will classify {@code Person} objects by city:
*
{@code
* Map> peopleByCity
* = personStream.collect(Collectors.groupingBy(Person::getCity));
* }
*
* The following will classify {@code Person} objects by state and city,
* cascading two {@code Collector}s together:
*
{@code
* Map>> peopleByStateAndCity
* = personStream.collect(Collectors.groupingBy(Person::getState,
* Collectors.groupingBy(Person::getCity)));
* }
*
* @param the type of the result
* @param the intermediate accumulation type of the {@code Collector}
* @param collector the {@code Collector} describing the reduction
* @return the result of the reduction
* @see #collect(Supplier, BiConsumer, BiConsumer)
* @see Collectors
*/
<R, A> R collect(Collector<? super T, A, R> collector);
Collector & Collectors
collect方法要求传入一个Collector接口的实例对象,Collector可以看做是用来处理流的工具,在Collectors里面封装了很多Collector工具。
全局变量
// supplier参数用于生成结果容器,容器类型为A。
Supplier<A> supplier();
// accumulator用于归纳元素,泛型T就是元素,它会将流中的元素同结果容器A发生操作。
BiConsumer<A, T> accumulator();
// combiner用于合并两个并行执行的结果,将其合并为最终结果A。
BinaryOperator<A> combiner();
// finisher用于将之前完整的结果R转为A。
Function<A, R> finisher();
// characteristics表示当前Collector的特征值,是一个不可变的Set。
Set<Characteristics> characteristics();
枚举
Characteristics这个特征值是一个枚举:
enum Characteristics {
// 多线程并行。
CONCURRENT,
// 无序。
UNORDERED,
// 无需转换结果。
IDENTITY_FINISH
}
构造方法
Collector拥有两个of方法用于生成Collector实例,其中一个拥有上面所有五个参数,另一个四个参数,不包括finisher参数。
// 四参方法,用于生成一个Collector,T代表流中的元素,R代表最终的结果。因为没有finisher参数,所以需要有IDENTITY_FINISH特征值。
public static<T, R> Collector<T, R, R> of(Supplier<R> supplier,
BiConsumer<R, T> accumulator,
BinaryOperator<R> combiner,
Characteristics... characteristics) {
Objects.requireNonNull(supplier);
Objects.requireNonNull(accumulator);
Objects.requireNonNull(combiner);
Objects.requireNonNull(characteristics);
Set<Characteristics> cs = (characteristics.length == 0)
? Collectors.CH_ID
: Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.IDENTITY_FINISH,
characteristics));
return new Collectors.CollectorImpl<>(supplier, accumulator, combiner, cs);
}
// 五参方法,用于生成一个Collector,T代表流中的元素,A代表中间结果,R代表最终结果,finisher用于将A转换为R。
public static<T, A, R> Collector<T, A, R> of(Supplier<A> supplier,
BiConsumer<A, T> accumulator,
BinaryOperator<A> combiner,
Function<A, R> finisher,
Characteristics... characteristics) {
Objects.requireNonNull(supplier);
Objects.requireNonNull(accumulator);
Objects.requireNonNull(combiner);
Objects.requireNonNull(finisher);
Objects.requireNonNull(characteristics);
Set<Characteristics> cs = Collectors.CH_NOID;
if (characteristics.length > 0) {
cs = EnumSet.noneOf(Characteristics.class);
Collections.addAll(cs, characteristics);
cs = Collections.unmodifiableSet(cs);
}
return new Collectors.CollectorImpl<>(supplier, accumulator, combiner, finisher, cs);
}
Collectors工具类
Collectors是一个工具类,是JDK预实现Collector的工具类,它内部提供了多种Collector。
ava8中Collectors的方法:
- toCollection
- toList
- toSet
- toMap
- joining
- mapping/flatMapping
- filtering
- collectingAndThen
- counting
- minBy
- maxBy
- summingInt/summingLong/summingDouble
- averagingInt/averagingLong/averagingDouble
- groupingBy
- groupingByConcurrent
- partitioningBy
- BinaryOperator
- summarizingInt
toCollection
此函数返回一个收集器,它将输入元素累积到一个集合中。
List<String> strList = Arrays.asList("a", "b", "c", "b", "a");
// toCollection()
Collection<String> strCollection = strList.parallelStream().collect(Collectors.toCollection(HashSet::new));
System.out.println(strCollection); // [a, b, c]
Set<String> strSet = strList.parallelStream().collect(Collectors.toCollection(HashSet::new));
System.out.println(strSet); // [a, b, c]
List<String> strList1 = strList.parallelStream().sorted(String::compareToIgnoreCase)
.collect(Collectors.toCollection(ArrayList::new));
System.out.println(strList1); // [a, a, b, b, c]
toList()
返回一个收集器,它将输入元素累积到一个新的List中。
List<String> strList = Arrays.asList("a", "b", "c", "b", "a");
List<String> uppercaseList = strList.parallelStream().map(String::toUpperCase).collect(Collectors.toList());
System.out.println(uppercaseList); // [A, B, C, B, A]
List<String> uppercaseUnmodifiableList = strList.parallelStream().map(String::toUpperCase)
.collect(Collectors.toUnmodifiableList());
System.out.println(uppercaseUnmodifiableList); // [A, B, C, B, A]
toSet()
List<String> strList = Arrays.asList("a", "b", "c", "b", "a");
Set<String> uppercaseSet = strList.parallelStream().map(String::toUpperCase).collect(Collectors.toSet());
System.out.println(uppercaseSet); // [A, B, C]
Set<String> uppercaseUnmodifiableSet = strList.parallelStream().map(String::toUpperCase)
.collect(Collectors.toUnmodifiableSet());
System.out.println(uppercaseUnmodifiableSet); // [A, B, C]
toMap
映射生成map
Map<String, String> map = Stream.of("a", "b", "c")
.collect(Collectors.toMap(Function.identity(), String::toUpperCase));
System.out.println(map); // {a=A, b=B, c=C}
// Duplicate Keys will throw: Exception in thread "main"
// java.lang.IllegalStateException: Duplicate key a (attempted merging values A
// and A)
Map<String, String> mapD = Stream.of("a", "b", "c", "b", "a")
.collect(Collectors.toMap(Function.identity(), String::toUpperCase, String::concat));
System.out.println(mapD); // {a=AA, b=BB, c=C}
// above are HashMap, use below to create different types of Map
TreeMap<String, String> mapTree = Stream.of("a", "b", "c", "b")
.collect(Collectors.toMap(Function.identity(), String::toUpperCase, String::concat, TreeMap::new));
System.out.println(mapTree); {a=A, b=BB, c=C}
joining
连接字符串
String concat = Stream.of("a", "b").collect(Collectors.joining());
System.out.println(concat); // ab
String csv = Stream.of("a", "b").collect(Collectors.joining(","));
System.out.println(csv); // a,b
String csv1 = Stream.of("a", "b").collect(Collectors.joining(",", "[", "]"));
System.out.println(csv1); // [a,b]
String csv2 = Stream.of("a", new StringBuilder("b"), new StringBuffer("c")).collect(Collectors.joining(","));
System.out.println(csv2); // a,b
mapping/flatMapping
它将Function应用于输入元素,然后将它们累积到给定的Collector
Set<String> setStr = Stream.of("a", "a", "b")
.collect(Collectors.mapping(String::toUpperCase, Collectors.toSet()));
System.out.println(setStr); // [A, B]
Set<String> setStr1 = Stream.of("a", "a", "b")
.collect(Collectors.flatMapping(s -> Stream.of(s.toUpperCase()), Collectors.toSet()));
System.out.println(setStr1); // [A, B]
filtering
设置过滤条件
List<String> strList2 = Lists.newArrayList("1", "2", "10", "100", "20", "999");
Set<String> set = strList2.parallelStream()
.collect(Collectors.filtering(s -> s.length() < 2, Collectors.toSet()));
System.out.println(set); // [1, 2]
collectingAndThen
返回一个收集器,该收集器将输入元素累积到给定的收集器中,然后执行其他完成功能
List<String> strList2 = Lists.newArrayList("1", "2", "10", "100", "20", "999");
List<String> unmodifiableList = strList2.parallelStream()
.collect(Collectors.collectingAndThen(Collectors.toList(), Collections::unmodifiableList));
System.out.println(unmodifiableList); // [1, 2, 10, 100, 20, 999]
counting
计数
Long evenCount = Stream.of(1, 2, 3, 4, 5).filter(x -> x % 2 == 0).collect(Collectors.counting());
System.out.println(evenCount); // 2
minBy
根据给定的比较器返回最小元素
Optional<Integer> min = Stream.of(1, 2, 3, 4, 5).collect(Collectors.minBy((x, y) -> x - y));
System.out.println(min); // Optional[1]
maxBy
它根据给定的比较器返回最大元素
Optional<Integer> max = Stream.of(1, 2, 3, 4, 5).collect(Collectors.maxBy((x, y) -> x - y));
System.out.println(max); // Optional[5]
summingInt/summingLong/summingDouble
求总和
List<String> strList3 = Arrays.asList("1", "2", "3", "4", "5");
Integer sum = strList3.parallelStream().collect(Collectors.summingInt(Integer::parseInt));
System.out.println(sum); // 15
Long sumL = Stream.of("12", "23").collect(Collectors.summingLong(Long::parseLong));
System.out.println(sumL); // 35
Double sumD = Stream.of("1e2", "2e3").collect(Collectors.summingDouble(Double::parseDouble));
System.out.println(sumD); // 2100.0
averagingInt/averagingLong/averagingDouble
求平均值
List<String> strList4 = Arrays.asList("1", "2", "3", "4", "5");
Double average = strList4.parallelStream().collect(Collectors.averagingInt(Integer::parseInt));
System.out.println(average); // 3.0
Double averageL = Stream.of("12", "23").collect(Collectors.averagingLong(Long::parseLong));
System.out.println(averageL); // 17.5
Double averageD = Stream.of("1e2", "2e3").collect(Collectors.averagingDouble(Double::parseDouble));
System.out.println(averageD); // 1050.0
groupingBy
分组
Map<Integer, List<Integer>> mapGroupBy = Stream.of(1, 2, 3, 4, 5, 4, 3).collect(Collectors.groupingBy(x -> x * 10));
System.out.println(mapGroupBy); // {50=[5], 20=[2], 40=[4, 4], 10=[1], 30=[3, 3]}
groupingByConcurrent
分组,是并发和无序的
Map<Integer, List<Integer>> mapGroupBy = Stream.of(1, 2, 3, 4, 5, 4, 3).collect(Collectors.groupingByConcurrent(x -> x * 10));
System.out.println(mapGroupBy); // {50=[5], 20=[2], 40=[4, 4], 10=[1], 30=[3, 3]}
partitioningBy
返回一个Collector,它根据Predicate对输入元素进行分区,并将它们组织成Map
Map<Boolean, List<Integer>> mapPartitionBy = Stream.of(1, 2, 3, 4, 5, 4, 3).collect(Collectors.partitioningBy(x -> x % 2 == 0));
System.out.println(mapPartitionBy); // {false=[1, 3, 5, 3], true=[2, 4, 4]}
BinaryOperator
返回一个收集器,它在指定的BinaryOperator下执行其输入元素的减少。这主要用于多级缩减,例如使用groupingBy()和partitioningBy()方法指定下游收集器
Map<Boolean, Optional<Integer>> reducing = Stream.of(1, 2, 3, 4, 5, 4, 3).collect(Collectors.partitioningBy(
x -> x % 2 == 0, Collectors.reducing(BinaryOperator.maxBy(Comparator.comparing(Integer::intValue)))));
System.out.println(reducing); // {false=Optional[5], true=Optional[4]}
summarizingInt
返回统计数据:min, max, average, count, sum
IntSummaryStatistics summarizingInt = Stream.of("12", "23", "35")
.collect(Collectors.summarizingInt(Integer::parseInt));
System.out.println(summarizingInt);
//IntSummaryStatistics{count=3, sum=70, min=12, average=23.333333, max=35}
整理
reduce 在并行情况下 因为引用的使用一个对象,所以 它适用于 所有基本类型或者String,还有不包含 集合类型的 对象
collect 在并行场景下每个线程都用的同一个对象引用, 并且因为操作没有返回值,所以适用于 集合类型 和 含有集合类型的对象