MySQL架构(视频链接:https://pan.baidu.com/s/1_aGwTIs3hfmhC71e-zkhFg 提取码:j8dr)
文章目录
- 1.淘宝为鉴
- 2.硬盘读写原理
- 3.总体架构
- 4.并发控制
- 4.1.订单问题
- 4.2.锁
- 4.2.1.表级锁
- 4.2.2.行级锁
- 4.2.2.1.读锁(共享锁)
- 4.2.2.2.写锁(排他锁)
- 4.2.2.3.死锁
- 4.2.3.解决并发问题
- 5.事务
- 5.1.语法
- 5.2.优化订单问题
- 5.2.1.增加事务
- 5.2.2.行级排他锁实现悲观锁
- 5.2.3.存储过程实现乐观锁
- 5.3.死锁
- 5.4.事务日志
- 5.5.自动提交
- 5.6.隐式和显式锁定
- 6.多版本并发控制MVCC
- 7.存储引擎
- 7.1.InnoDB
- 7.2.MyISAM
- 7.3.其他
- 7.4.插件引擎
1.淘宝为鉴

LAMP:Linux+Apache+MySQL+PHP
垂直拆分:表拆分,将一个表拆成多个表,策略:按照时间,按照区域,用户ID等规则
水平拆分:多个数据库做复制,主从,集群等等。
QPS:Query Per Second
2.硬盘读写原理
硬盘
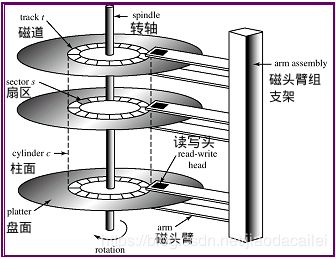
逻辑地址 -> 物理地址:盘面号 + 柱面号 + 扇区号
扇区大小512k,其标识符包含:盘面号 + 柱面号 + 扇区号
数据读取时间:寻道时间 + 旋转延迟 + 数据传输(磁盘到内存)
数据读取:cpu给出逻辑地址和内存地址,硬盘控制器翻译为物理地址并读取数据写入内存地址。
数据存储顺序:
系统将文件存储到磁盘上时,按柱面、磁头、扇区的方式进行,即最先是第1磁道的第一磁头下(也就是第1盘面的第一磁道)的所有扇区,然后,是同一柱面的下一磁头,……,一个柱面存储满后就推进到下一个柱面,直到把文件内容全部写入磁盘。系统将文件存储到磁盘上时,按柱面、磁头、扇区的方式进行,即最先是第1磁道的第一磁头下(也就是第1盘面的第一磁道)的所有扇区,然后,是同一柱面的下一磁头,……,一个柱面存储满后就推进到下一个柱面,直到把文件内容全部写入磁盘。
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
数据库读数据过程:找到行数据的逻辑地址,CPU将该逻辑地址发给磁盘控制器,磁盘控制器将其翻译为物理地址后,在磁盘中找到相应的扇区进行读取,读取后的数据,写入内存。
数据库写数据过程:找到需要修改的行数据的逻辑地址,CPU将该逻辑地址发给磁盘控制器,磁盘控制器将其翻译为物理地址后,在磁盘中找到相应的扇区进行读取,读取后的数据,写入内存;在内存中修改数据,然后将数据写入磁盘。
3.总体架构
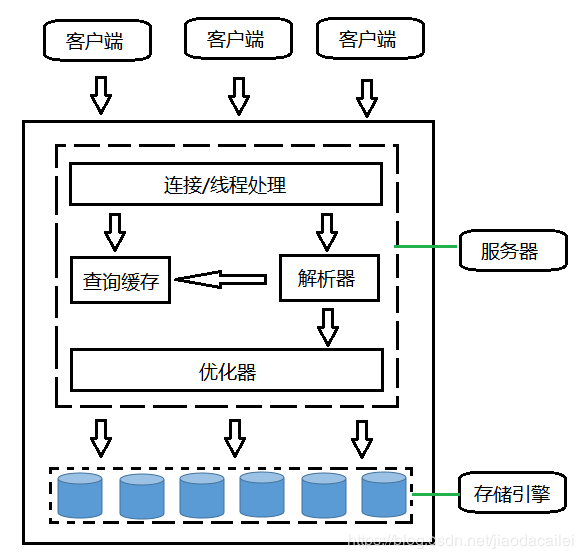
客户端发出sql查询;
服务器层的连接和线程处理模块,就会为其启动一个线程,并且做认证和权限控制;
如果查询缓存中有数据,直接返回,否则,进入解析器;
解析器将sql解析为MySQL内部存储结构(解析树);
优化器对执行的方案进行成本评估(该查询需要读取的行数),决定一个方案后,调用存储引擎;
存储引擎负责实际执行查询任务,和文件系统及硬件存储打交道。
每个客户端连接会在服务器进程中拥有有一个线程,服务器会缓存线程,实现线程池管理。
认证:用户名、原始主机信息和密码。如果使用SSL方式连接,还可以进行X.509证书认证。
权限:对某个表执行select/insert等权限。
4.并发控制
4.1.订单问题
并发创建订单时,修改库存数据。
DROP TABLE IF EXISTS `t_goods`;
CREATE TABLE `t_goods` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL COMMENT '名称',
`amount` int(11) NOT NULL COMMENT '商品库存数量',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of t_goods
-- ----------------------------
INSERT INTO `t_goods` VALUES ('1', '商品A', '15');
-- ----------------------------
-- Table structure for `t_order`
-- ----------------------------
DROP TABLE IF EXISTS `t_order`;
CREATE TABLE `t_order` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`goods_id` int(11) NOT NULL COMMENT '商品ID',
`amount` int(10) NOT NULL DEFAULT '0' COMMENT '商品数量',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
模拟并发时的问题脚本
select '创建订单...' as log;
insert into t_order (goods_id, amount) values (1, 1);
select '获取商品库存数量...' as log;
set @goods_amount = (select amount from t_goods where id = 1);
select '休眠10秒...' as log;
select sleep(10);
select '更新商品库存数量...' as log;
update t_goods set amount = (@goods_amount - 1) where id = 1;
模拟两个客户端访问数据过程:
| SQL | Session1 | Session2 | 说明 | |
|---|---|---|---|---|
| 1 | insert into t_order (goods_id, amount) values (1, 1); | 执行1 | 执行1 | |
| 2 | set @goods_amount = (select amount from t_goods where id = 1); | 执行2 | 执行2 | |
| 3 | select sleep(10); | 执行3 | 执行3 | |
| 4 | update t_goods set amount = (@goods_amount - 1) where id = 1; | 执行4 | 执行4 | |
4.2.锁
读锁:共享锁
写锁:排他锁
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。MyISAM/InnoDB
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。InnoDB
表级锁的写锁一旦加上后,表无法再加其他锁;
行级锁的读锁加了之后,可以再加其他锁;
行级锁的写锁加了之后,不能再加其他锁。
4.2.1.表级锁
表写锁,假设先执行Session1
| Session1 | Session2 | Session3 |
|---|---|---|
| LOCK TABLE t_goods write; | ||
| select * from t_goods; | update t_goods set amount = 10 where id = 1; | |
| select * from t_goods; | 等待 | 等待 |
| select * from t_order;[Err] 1100 - Table ‘t_order’ was not locked with LOCK TABLES | ||
| update t_goods set amount = 10 where id = 1; | 等待 | 等待 |
| UNLOCK TABLES; | 等待 | 等待 |
| 返回查询结果 | 更新成功 | |
表读锁,假设先执行Session1
| Session1 | Session2/3/4/5 |
|---|---|
| LOCK TABLE t_goods read; | |
| select * from t_goods;update t_goods set amount = 10 where id = 1;LOCK TABLE t_goods write;LOCK TABLE t_goods read; | |
| select * from t_goods; | 等待 |
| select * from t_order;--------[Err] 1100 - Table ‘t_order’ was not locked with LOCK TABLES | |
| update t_goods set amount = 10 where id = 1;--------[Err] 1099 - Table ‘t_goods’ was locked with a READ lock and can’t be updated | 等待 |
| UNLOCK TABLES; | 等待 |
| 结果2/3/4/5: | |
如果锁没有生效,是查询缓存的问题,执行
| 清除查询缓存 |
|---|
| reset query cache; |
| 通过表锁实现并发控制 |
|---|
| insert into t_order (goods_id, amount) values (1, 1);Lock table t_goods write;set @goods_amount = (select amount from t_goods where id = 1);update t_goods set amount = (@goods_amount - 1) where id = 1;Unlock tables; |
4.2.2.行级锁
存储引擎层实现,服务器层没有实现
InnoDB行锁是通过给索引上的索引项加锁来实现的,这一点MySQL与Oracle不同,后者是通过在数据块中对相应数据行加锁来实现的。
InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
如果要给行加锁的步骤:
启动事务;
加锁及其他sql操作;
提交事务/回滚;
4.2.2.1.读锁(共享锁)
| Session1 | Session2/3/4/5 |
|---|---|
| set autocommit = 0;# start transaction;# beginselect * from t_goods where id = 1 lock in SHARE MODE;update t_goods set name = ‘商品A’ where id = 1;commit; | select * from t_goods where id = 1;select * from t_goods where id = 1 lock in SHARE MODE;select * from t_goods where id = 1 for update;update t_goods set name = ‘商品A’ where id = 1; |
4.2.2.2.写锁(排他锁)
| Session1 | Session2 | Session3/4/5 |
|---|---|---|
| set autocommit = 0;# start transaction;# begin;select * from t_goods where id = 1 for update;update t_goods set name = ‘商品A’ where id = 1;commit; | select * from t_goods where id = 1; | select * from t_goods where id = 1 lock in SHARE MODE;select * from t_goods where id = 1 lock for update;update t_goods set name = ‘商品A’ where id = 1; |
4.2.2.3.死锁
| Session1 | Session2 |
|---|---|
| set autocommit = 0;# begin transaction;select * from t_goods where id = 1 lock in SHARE MODE; | |
| set autocommit = 0;# begin transaction;select * from t_goods where id = 1 lock in SHARE MODE; | |
| update t_goods set name = ‘商品A’ where id = 1;--------阻塞 | |
| update t_goods set name = ‘商品A’ where id = 1;--------死锁退出 | |
| commit; | |
| 上面阻塞的sql执行成功 | |
| commit; | |
4.2.3.解决并发问题
| Begin;insert into t_order (goods_id, amount) values (1, 1);set @goods_amount = (select amount from t_goods where id = 1 for update);update t_goods set amount = (@goods_amount - 1) where id = 1;commit; |
5.事务
ACID
隔离级别
5.1.语法
BEGIN;
START TRANSACTION;
SET AUTOCOMMIT = 0;
COMMIT;
ROLLBACK;
5.2.优化订单问题
5.2.1.增加事务
| SQL语句 | 说明 |
|---|---|
| begin; | |
| insert into t_order (goods_id, amount) values (1, 1); | |
| set @goods_amount = (select amount from t_goods where id = 1); | |
| select sleep(10); | 此处停止应用,对数据库没有影响 |
| update t_goods set amount = (@goods_amount + 1) where id = 1; | |
| commit; | |
上述方案,解决了所有sql语句要么同时成功,要么同时失败,但并发时的数据不一致问题仍然存在。需要使用行级排他锁,也可以使用表级排他锁。
5.2.2.行级排他锁实现悲观锁
| Session1 | Session2 |
|---|---|
| begin; | |
| insert into t_order (goods_id, amount) values (1, 1); | |
| select @goods_amount := amount from t_goods where id = 1 for update; | |
| begin; | |
| insert into t_order (goods_id, amount) values (1, 1); | |
| select @goods_amount := amount from t_goods where id = 1 for update;----等待… | |
| select sleep(10); | |
| update t_goods set amount = (@goods_amount + 1) where id = 1; | |
| commit; | |
| ----等待session1的排他锁释放才能继续执行:select sleep(10); | |
| update t_goods set amount = (@goods_amount + 1) where id = 1; | |
| commit; | |
上述方案为悲观锁
5.2.3.存储过程实现乐观锁
在t_goods上增加version字段,默认值为0;每次修改记录时,version加1;
修改数据时,如果version值被改变,则回滚,否则提交。
创建存储过程createOrder
DELIMITER //
CREATE PROCEDURE createOrder()
BEGIN
START TRANSACTION;
insert into t_order (goods_id, amount) values (1, 1);
select @goods_amount := amount,@goods_version := version from t_goods where id = 1;
select sleep(10);
update t_goods set amount = (@goods_amount + 1), version = (@goods_version + 1) where id = 1 and version = @goods_version;
SELECT ROW_COUNT() into @goods_updated;
if @goods_updated = 1 THEN
COMMIT;
ELSE
ROLLBACK;
end IF;
END;
//
DELIMITER;
如果需要修改,则要先删除再创建,删除的语句如下:
| 删除存储过程 |
|---|
| DROP PROCEDURE createOrder; |
先执行session1
| Session1 | Session2 |
|---|---|
| CALL createOrder(); | CALL createOrder(); |
| ----成功更新 | ----未更新,回滚 |
5.3.死锁
| Session1 | Session2 |
|---|---|
| begin; | begin; |
| update t_goods set name = ‘商品AX’ where id = 1; | |
| update t_goods set name = ‘商品BX’ where id = 2; | |
| update t_goods set name = ‘商品BX’ where id = 2;----阻塞 | |
| update t_goods set name = ‘商品AX’ where id = 1;----[Err] 1213 - Deadlock found when trying to get lock; try restarting transaction | |
| 阻塞解除,并执行成功 | |
| commit; | |
5.4.事务日志
修改表数据过程仅仅是写事务日志文件而已,并不是将数据直接写入实际的数据库文件中。
| 设备 | 操作 |
|---|---|
| 内存 | 1.将表数据加载到内存;2.修改内存中的数据拷贝; |
| 事务日志文件 | 3.写入修改行为到日志文件,并记录操作标志为未完成 |
| 数据库文件 | 4.内存中修改的数据会慢慢刷新到磁盘中的数据库文件中,并更新操作标志为完成 |
假设3步之后系统崩溃,则数据库重启后,会重新执行日志的内容,恢复数据。
事务日志采用追加,为顺序IO,比直接写磁盘的随机IO要快,故可以保证快速的写入。
5.5.自动提交
InnoDB引擎默认每个查询一个事务,禁用自动提交:
set autocommit = 0;
禁用之后,会开启一个新事务,commit/rollback之后才提交/回滚该事务。
之后接着又启动一个新事务,直到下一个commit/rollback之后才提交/回滚该事务。
5.6.隐式和显式锁定
InnoDB采用两阶段锁定协议(two-phase locking protocol)。
事务中的update/delete/insert语句会隐式锁定记录(排他锁(X)),直到commit/rollback之后,释放锁。
对于普通SELECT语句,InnoDB不会加任何锁;
事务可以通过以下语句显示给记录集加共享锁或排他锁。
| 共享锁(S) | 排他锁(X) |
|---|---|
| SELECT * FROM table_name WHERE … LOCK IN SHARE MODE | SELECT * FROM table_name WHERE … FOR UPDATE |
MySQL也支持LOCK TABLES / UNLOCK TABLES等命令,由服务器层实现,与存储引擎无关。
6.多版本并发控制MVCC
InnoDB的MVCC实现原理:
在每行数据后面增加两个字段:创建时间和删除时间。
其值并不是具体的时间,而是每一个事务对应的系统版本号。每个新的事务启动时,系统版本号都会递增。
InnoDB的Repeatable Read隔离级别,不仅解决了脏读问题,还解决了幻读问题。按照隔离级别的定义,幻读在串行化隔离级别解决就可以了,但InnoDB在Repeatable Read隔离级别就已经解决了。
Repeatable Read情况下MVCC工作流程:
| SQL | MVCC下操作规则 |
|---|---|
| Select | 增加条件:创建时间 <= 当前系统版本号 and (删除时间为空 or 删除时间 > 当前系统版本号) |
| Insert | 插入行数据的创建时间设置为当前系统版本号 |
| Delete | 删除行的删除时间设置为当前系统版本号 |
| Update | 修改一行时,实际是插入新行,并设置创建时间设置为当前系统版本号;并将旧行的删除时间设置为当前系统版本号 |
解决可重复读问题
| Session1 | Session2 |
|---|---|
| Select * from t_goods where id = 1; | |
| Update t_goods set amount = 10 where id = 1; | |
| Select * from t_goods where id = 1; | |
| Delete from t_goods where id = 1; | |
| Select * from t_goods where id = 1; | |
解决幻读问题
| Session1 | Session2 |
|---|---|
| Select * from t_goods; | |
| insert t_goods (name, amount) values (‘商品C’, 100); | |
| Select * from t_goods; | |
| Delete from t_goods where id = 1; | |
| Select * from t_goods; | |
7.存储引擎
7.1.InnoDB
默认存储引擎
支持事务
支持表级/行级锁
默认事务隔离级别:REPEATABLE READ
主键聚簇索引,全文索引
7.2.MyISAM
不支持事务,支持表级锁,支持全文索引
7.3.其他
Archive
Blackhole
CSV
Federated
Memory
NDB
7.4.插件引擎
XtraDB:OLTP(OnLine Transaction Processing),基于InnoDB的改进版
Infobright:面向列,数据仓库
视频链接:https://pan.baidu.com/s/1_aGwTIs3hfmhC71e-zkhFg 提取码:j8dr