Kubernetes简介
Kubernetes是谷歌严格保密十几年的秘密武器—Borg的一个开源版本,是Docker分布式系统解决方案.2014年由Google公司启动.
Kubernetes提供了面向应用的容器集群部署和管理系统。Kubernetes的目标旨在消除编排物理/虚拟计算,网络和存储基础设施的负担,并使应用程序运营商和开发人员完全将重点放在以容器为中心的原语上进行自助运营。Kubernetes 也提供稳定、兼容的基础(平台),用于构建定制化的workflows 和更高级的自动化任务。 Kubernetes 具备完善的集群管理能力,包括多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和服务发现机制、内建负载均衡器、故障发现和自我修复能力、服务滚动升级和在线扩容、可扩展的资源自动调度机制、多粒度的资源配额管理能力。 Kubernetes 还提供完善的管理工具,涵盖开发、部署测试、运维监控等各个环节。
Kubernetes作为云原生应用的基石,相当于一个云操作系统,其重要性不言而喻。
容器编排
容器编排引擎三足鼎立:
Mesos
Docker Swarm+compose
Kubernetes
早在 2015 年 5 月,Kubernetes 在 Google 上的搜索热度就已经超过了 Mesos 和 Docker Swarm,从那儿之后更是一路飙升,将对手甩开了十几条街,容器编排引擎领域的三足鼎立时代结束。
目前,AWS、Azure、Google、阿里云、腾讯云等主流公有云提供的是基于 Kubernetes 的容器服务;Rancher、CoreOS、IBM、Mirantis、Oracle、Red Hat、VMWare 等无数厂商也在大力研发和推广基于 Kubernetes 的容器 CaaS 或 PaaS 产品。可以说,Kubernetes 是当前容器行业最炙手可热的明星。
Google 的数据中心里运行着超过 20 亿个容器,而且 Google 十年前就开始使用容器技术。
最初,Google 开发了一个叫 Borg 的系统(现在命名为 Omega)来调度如此庞大数量的容器和工作负载。在积累了这么多年的经验后,Google 决定重写这个容器管理系统,并将其贡献到开源社区,让全世界都能受益。这个项目就是 Kubernetes。简单的讲,Kubernetes 是 Google Omega 的开源版本。
跟很多基础设施领域先有工程实践、后有方法论的发展路线不同,Kubernetes 项目的理论基础则要比工程实践走得靠前得多,这当然要归功于 Google 公司在 2015 年 4 月发布的 Borg 论文了。
Borg 系统,一直以来都被誉为 Google 公司内部最强大的"秘密武器"。虽然略显夸张,但这个说法倒不算是吹牛。
因为,相比于 Spanner、BigTable 等相对上层的项目,Borg 要承担的责任,是承载 Google 公司整个基础设施的核心依赖。在 Google 公司已经公开发表的基础设施体系论文中,Borg 项目当仁不让地位居整个基础设施技术栈的最底层。
由于这样的定位,Borg 可以说是 Google 最不可能开源的一个项目。而幸运地是,得益于 Docker 项目和容器技术的风靡,它却终于得以以另一种方式与开源社区见面,这个方式就是 Kubernetes 项目。
所以,相比于"小打小闹"的 Docker 公司、"旧瓶装新酒"的 Mesos 社区,Kubernetes 项目从一开始就比较幸运地站上了一个他人难以企及的高度:在它的成长阶段,这个项目每一个核心特性的提出,几乎都脱胎于 Borg/Omega 系统的设计与经验。更重要的是,这些特性在开源社区落地的过程中,又在整个社区的合力之下得到了极大的改进,修复了很多当年遗留在 Borg 体系中的缺陷和问题。
所以,尽管在发布之初被批评是"曲高和寡",但是在逐渐觉察到 Docker 技术栈的"稚嫩"和 Mesos 社区的"老迈"之后,这个社区很快就明白了:k8s 项目在 Borg 体系的指导下,体现出了一种独有的"先进性"与"完备性",而这些特质才是一个基础设施领域开源项目赖以生存的核心价值。
什么是编排
一个正在运行的 Linux 容器,可以分成两部分看待
1 . 容器的静态视图
一组联合挂载在 /var/lib/docker/aufs/mnt 上的 rootfs,这一部分称为"容器镜像"(Container Image)
2 . 容器的动态视图
一个由 Namespace+Cgroups 构成的隔离环境,这一部分称为"容器运行时"(Container Runtime)
作为一名开发者,其实并不关心容器运行时的差异。在整个"开发 - 测试 - 发布"的流程中,真正承载着容器信息进行传递的,是容器镜像,而不是容器运行时。
这正是容器技术圈在 Docker 项目成功后不久,就迅速走向了"容器编排"这个"上层建筑"的主要原因:作为一家云服务商或者基础设施提供商,我只要能够将用户提交的 Docker 镜像以容器的方式运行起来,就能成为这个非常热闹的容器生态图上的一个承载点,从而将整个容器技术栈上的价值,沉淀在我的这个节点上。
更重要的是,只要从这个承载点向 Docker 镜像制作者和使用者方向回溯,整条路径上的各个服务节点,比如 CI/CD、监控、安全、网络、存储等等,都有可以发挥和盈利的余地。这个逻辑,正是所有云计算提供商如此热衷于容器技术的重要原因:通过容器镜像,它们可以和潜在用户(即,开发者)直接关联起来。
从一个开发者和单一的容器镜像,到无数开发者和庞大的容器集群,容器技术实现了从"容器"到"容器云"的飞跃,标志着它真正得到了市场和生态的认可。
这样,容器就从一个开发者手里的小工具,一跃成为了云计算领域的绝对主角;而能够定义容器组织和管理规范的"容器编排"技术,则当仁不让地坐上了容器技术领域的"头把交椅"。
最具代表性的容器编排工具
# 1. Docker 公司的 Compose+Swarm 组合
# 2. Google 与 RedHat 公司共同主导的 Kubernetes 项目
编排工具
Swarm与CoreOS
Docker 公司发布 Swarm 项目
Docker 公司在 2014 年发布 Swarm 项目. 一个有意思的事实:虽然通过"容器"这个概念完成了对经典 PaaS 项目的"降维打击",但是 Docker 项目和 Docker 公司,兜兜转转了一年多,却还是回到了 PaaS 项目原本深耕多年的那个战场:如何让开发者把应用部署在我的项目上
Docker 项目从发布之初就全面发力,从技术、社区、商业、市场全方位争取到的开发者群体,实际上是为此后吸引整个生态到自家"PaaS"上的一个铺垫。只不过这时,"PaaS"的定义已经全然不是 Cloud Foundry 描述的那个样子,而是变成了一套以 Docker 容器为技术核心,以 Docker 镜像为打包标准的、全新的"容器化"思路。
这正是 Docker 项目从一开始悉心运作"容器化"理念和经营整个 Docker 生态的主要目的。
Docker 公司在 Docker 项目已经取得巨大成功后,执意要重新走回 PaaS 之路的原因:
虽然 Docker 项目备受追捧,但用户们最终要部署的,还是他们的网站、服务、数据库,甚至是云计算业务。只有那些能够为用户提供平台层能力的工具,才会真正成为开发者们关心和愿意付费的产品。而 Docker 项目这样一个只能用来创建和启停容器的小工具,最终只能充当这些平台项目的"幕后英雄"。
Docker 公司的老朋友和老对手 CoreOS:
CoreOS 是一个基础设施领域创业公司。 核心产品是一个定制化的操作系统,用户可以按照分布式集群的方式,管理所有安装了这个操作系统的节点。从而,用户在集群里部署和管理应用就像使用单机一样方便了。
Docker 项目发布后,CoreOS 公司很快就认识到可以把"容器"的概念无缝集成到自己的这套方案中,从而为用户提供更高层次的 PaaS 能力。所以,CoreOS 很早就成了 Docker 项目的贡献者,并在短时间内成为了 Docker 项目中第二重要的力量。
2014 年底,CoreOS 公司与 Docker 公司停止合作,并推出自己研制的 Rocket(后来叫 rkt)容器。
原因是 Docker 公司对 Docker 项目定位的不满足。Docker 公司的解决方法是让 Docker 项目提供更多的平台层能力,即向 PaaS 项目进化。这与 CoreOS 公司的核心产品和战略发生了严重冲突。
Docker 公司在 2014 年就已经定好了平台化的发展方向,并且绝对不会跟 CoreOS 在平台层面开展任何合作。这样看来,Docker 公司在 2014 年 12 月的 DockerCon 上发布 Swarm 的举动,也就一点都不突然了。
CoreOS 项目
依托于一系列开源项目(比如 Container Linux 操作系统、Fleet 作业调度工具、systemd 进程管理和 rkt 容器),一层层搭建起来的平台产品
Swarm 项目:
以一个完整的整体来对外提供集群管理功能。Swarm 的最大亮点是它完全使用 Docker 项目原本的容器管理 API 来完成集群管理,比如:
单机 Docker 项目
docker run 我的容器
多机 Docker 项目
``docker run -H " 我的 Swarm 集群 API 地址 " " 我的容器 "`
在部署了 Swarm 的多机环境下,用户只需使用原先的 Docker 指令创建一个容器,这个请求就会被 Swarm 拦截下来处理,然后通过具体的调度算法找到一个合适的 Docker Daemon 运行起来。
这个操作方式简洁明了,对于已经了解过 Docker 命令行的开发者们也很容易掌握。所以,这样一个"原生"的 Docker 容器集群管理项目一经发布,就受到了已有 Docker 用户群的热捧。相比之下,CoreOS 的解决方案就显得非常另类,更不用说用户还要去接受完全让人摸不着头脑、新造的容器项目 rkt 了。
Swarm 项目只是 Docker 公司重新定义"PaaS"的关键一环。2014 年到 2015 年这段时间里,Docker 项目的迅速走红催生出了一个非常繁荣的"Docker 生态"。在这个生态里,围绕着 Docker 在各个层次进行集成和创新的项目层出不穷.
cncf(Fig/Compose)
Fig 项目
被docker收购后改名为 Compose
Fig 项目基本上只是靠两个人全职开发和维护的,可它却是当时 GitHub 上热度堪比 Docker 项目的明星。
Fig 项目受欢迎的原因
是它在开发者面前第一次提出"容器编排"(Container Orchestration)的概念。
"编排"(Orchestration)在云计算行业里不算是新词汇,主要是指用户如何通过某些工具或者配置来完成一组虚拟机以及关联资源的定义、配置、创建、删除等工作,然后由云计算平台按照这些指定的逻辑来完成的过程。
容器时代,"编排"就是对 Docker 容器的一系列定义、配置和创建动作的管理。而 Fig 的工作实际上非常简单:假如现在用户需要部署的是应用容器 A、数据库容器 B、负载均衡容器 C,那么 Fig 就允许用户把 A、B、C 三个容器定义在一个配置文件中,并且可以指定它们之间的关联关系,比如容器 A 需要访问数据库容器 B。
接下来,只需执行一条非常简单的指令:# fig up
Fig 就会把这些容器的定义和配置交给 Docker API 按照访问逻辑依次创建,一系列容器就都启动了;而容器 A 与 B 之间的关联关系,也会交给 Docker 的 Link 功能通过写入 hosts 文件的方式进行配置。更重要的是,你还可以在 Fig 的配置文件里定义各种容器的副本个数等编排参数,再加上 Swarm 的集群管理能力,一个活脱脱的 PaaS 呼之欲出。
它成了 Docker 公司到目前为止第二大受欢迎的项目,一直到今也依然被很多人使用。
当时的这个容器生态里,还有很多开源项目或公司。比如:
专门负责处理容器网络的 SocketPlane 项目(后来被 Docker 公司收购)
专门负责处理容器存储的 Flocker 项目(后来被 EMC 公司收购)
专门给 Docker 集群做图形化管理界面和对外提供云服务的 Tutum 项目(后来被 Docker 公司收购)等等。
Mesosphere与Mesos
老牌集群管理项目 Mesos 和它背后的创业公司 Mesosphere:Mesos 社区独特的竞争力:
超大规模集群的管理经验
Mesos 早已通过了万台节点的验证,2014 年之后又被广泛使用在 eBay 等大型互联网公司的生产环境中。
Mesos 是 Berkeley 主导的大数据套件之一,是大数据火热时最受欢迎的资源管理项目,也是跟 Yarn 项目杀得难舍难分的实力派选手。
大数据所关注的计算密集型离线业务,其实并不像常规的 Web 服务那样适合用容器进行托管和扩容,也没有对应用打包的强烈需求,所以 Hadoop、Spark 等项目到现在也没在容器技术上投下更大的赌注;
但对于 Mesos 来说,天生的两层调度机制让它非常容易从大数据领域抽身,转而去支持受众更加广泛的 PaaS 业务。
在这种思路指导下,Mesosphere 公司发布了一个名为 Marathon 的项目,这个项目很快就成为 Docker Swarm 的一个有力竞争对手。
通过 Marathon 实现了诸如应用托管和负载均衡的 PaaS 功能之后,Mesos+Marathon 的组合实际上进化成了一个高度成熟的 PaaS 项目,同时还能很好地支持大数据业务。
Mesosphere 公司提出"DC/OS"(数据中心操作系统)的口号和产品:
旨在使用户能够像管理一台机器那样管理一个万级别的物理机集群,并且使用 Docker 容器在这个集群里自由地部署应用。这对很多大型企业来说具有着非同寻常的吸引力。
这时的容器技术生态, CoreOS 的 rkt 容器完全打不开局面,Fleet 集群管理项目更是少有人问津,CoreOS 完全被 Docker 公司压制了。
RedHat 也是因为对 Docker 公司平台化战略不满而愤愤退出。但此时,它竟只剩下 OpenShift 这个跟 Cloud Foundry 同时代的经典 PaaS 一张牌可以打,跟 Docker Swarm 和转型后的 Mesos 完全不在同一个"竞技水平"之上。
google与k8s
2014 年 6 月,基础设施领域的翘楚 Google 公司突然发力,正宣告了一个名叫 Kubernetes 项目的诞生。这个项目,不仅挽救了当时的 CoreOS 和 RedHat,还如同当年 Docker 项目的横空出世一样,再一次改变了整个容器市场的格局。
这段时间,也正是 Docker 生态创业公司们的春天,大量围绕着 Docker 项目的网络、存储、监控、CI/CD,甚至 UI 项目纷纷出台,也涌现出了很多 Rancher、Tutum 这样在开源与商业上均取得了巨大成功的创业公司。
在 2014~2015 年间,整个容器社区可谓热闹非凡。
这令人兴奋的繁荣背后,却浮现出了更多的担忧。这其中最主要的负面情绪,是对 Docker 公司商业化战略的种种顾虑。
事实上,很多从业者也都看得明白,Docker 项目此时已经成为 Docker 公司一个商业产品。而开源,只是 Docker 公司吸引开发者群体的一个重要手段。不过这么多年来,开源社区的商业化其实都是类似的思路,无非是高不高调、心不心急的问题罢了。
而真正令大多数人不满意的是,Docker 公司在 Docker 开源项目的发展上,始终保持着绝对的权威和发言权,并在多个场合用实际行动挑战到了其他玩家(比如,CoreOS、RedHat,甚至谷歌和微软)的切身利益。
那么,这个时候,大家的不满也就不再是在 GitHub 上发发牢骚这么简单了。
相信很多容器领域的老玩家们都听说过,Docker 项目刚刚兴起时,Google 也开源了一个在内部使用多年、经历过生产环境验证的 Linux 容器:lmctfy(Let Me Container That For You)。
然而,面对 Docker 项目的强势崛起,这个对用户没那么友好的 Google 容器项目根本没有招架之力。所以,知难而退的 Google 公司,向 Docker 公司表示了合作的愿望:关停这个项目,和 Docker 公司共同推进一个中立的容器运行时(container runtime)库作为 Docker 项目的核心依赖。
不过,Docker 公司并没有认同这个明显会削弱自己地位的提议,还在不久后,自己发布了一个容器运行时库 Libcontainer。这次匆忙的、由一家主导的、并带有战略性考量的重构,成了 Libcontainer 被社区长期诟病代码可读性差、可维护性不强的一个重要原因。
至此,Docker 公司在容器运行时层面上的强硬态度,以及 Docker 项目在高速迭代中表现出来的不稳定和频繁变更的问题,开始让社区叫苦不迭。
这种情绪在 2015 年达到了一个高潮,容器领域的其他几位玩家开始商议"切割"Docker 项目的话语权。而"切割"的手段也非常经典,那就是成立一个中立的基金会。
于是,2015 年 6 月 22 日,由 Docker 公司牵头,CoreOS、Google、RedHat 等公司共同宣布,Docker 公司将 Libcontainer 捐出,并改名为 RunC 项目,交由一个完全中立的基金会管理,然后以 RunC 为依据,大家共同制定一套容器和镜像的标准和规范。
这套标准和规范,就是 OCI( Open Container Initiative )。OCI 的提出,意在将容器运行时和镜像的实现从 Docker 项目中完全剥离出来。这样做,一方面可以改善 Docker 公司在容器技术上一家独大的现状,另一方面也为其他玩家不依赖于 Docker 项目构建各自的平台层能力提供了可能。
不过,OCI 的成立更多的是这些容器玩家出于自身利益进行干涉的一个妥协结果。尽管 Docker 是 OCI 的发起者和创始成员,它却很少在 OCI 的技术推进和标准制定等事务上扮演关键角色,也没有动力去积极地推进这些所谓的标准。
这也是迄今为止 OCI 组织效率持续低下的根本原因。
OCI 并没能改变 Docker 公司在容器领域一家独大的现状,Google 和 RedHat 等公司于是把第二把武器摆上了台面。
Docker 之所以不担心 OCI 的威胁,原因就在于它的 Docker 项目是容器生态的事实标准,而它所维护的 Docker 社区也足够庞大。可是,一旦这场斗争被转移到容器之上的平台层,或者说 PaaS 层,Docker 公司的竞争优势便立刻捉襟见肘了。
在这个领域里,像 Google 和 RedHat 这样的成熟公司,都拥有着深厚的技术积累;而像 CoreOS 这样的创业公司,也拥有像 Etcd 这样被广泛使用的开源基础设施项目。
可是 Docker 公司却只有一个 Swarm。
所以这次,Google、RedHat 等开源基础设施领域玩家们,共同牵头发起了一个名为 CNCF(Cloud Native Computing Foundation)的基金会。这个基金会的目的其实很容易理解:它希望,以 Kubernetes 项目为基础,建立一个由开源基础设施领域厂商主导的、按照独立基金会方式运营的平台级社区,来对抗以 Docker 公司为核心的容器商业生态。
为了打造出一个围绕 Kubernetes 项目的"护城河",CNCF 社区就需要至少确保两件事情:
# 1. Kubernetes 项目必须能够在容器编排领域取得足够大的竞争优势
# 2. CNCF 社区必须以 Kubernetes 项目为核心,覆盖足够多的场景
CNCF 社区如何解决 Kubernetes 项目在编排领域的竞争力的问题:
在容器编排领域,Kubernetes 项目需要面对来自 Docker 公司和 Mesos 社区两个方向的压力。Swarm 和 Mesos 实际上分别从两个不同的方向讲出了自己最擅长的故事:Swarm 擅长的是跟 Docker 生态的无缝集成,而 Mesos 擅长的则是大规模集群的调度与管理。
这两个方向,也是大多数人做容器集群管理项目时最容易想到的两个出发点。也正因为如此,Kubernetes 项目如果继续在这两个方向上做文章恐怕就不太明智了。
Kubernetes 选择的应对方式是:Borg
k8s 项目大多来自于 Borg 和 Omega 系统的内部特性,这些特性落到 k8s 项目上,就是 Pod、Sidecar 等功能和设计模式。
这就解释了,为什么 Kubernetes 发布后,很多人"抱怨"其设计思想过于"超前"的原因:Kubernetes 项目的基础特性,并不是几个工程师突然"拍脑袋"想出来的东西,而是 Google 公司在容器化基础设施领域多年来实践经验的沉淀与升华。这正是 Kubernetes 项目能够从一开始就避免同 Swarm 和 Mesos 社区同质化的重要手段。
CNCF 接下来的任务是如何把这些先进的思想通过技术手段在开源社区落地,并培育出一个认同这些理念的生态?
RedHat 发挥了重要作用。当时,Kubernetes 团队规模很小,能够投入的工程能力十分紧张,这恰恰是 RedHat 的长处。RedHat 更是世界上为数不多、能真正理解开源社区运作和项目研发真谛的合作伙伴。
RedHat 与 Google 联盟的成立,不仅保证了 RedHat 在 Kubernetes 项目上的影响力,也正式开启了容器编排领域"三国鼎立"的局面。
Mesos 社区与容器技术的关系,更像是"借势",而不是这个领域真正的参与者和领导者。这个事实,加上它所属的 Apache 社区固有的封闭性,导致了 Mesos 社区虽然技术最为成熟,却在容器编排领域鲜有创新。
一开始,Docker 公司就把应对 Kubernetes 项目的竞争摆在首要位置:
一方面,不断强调"Docker Native"的"重要性"
一方面,与 k8s 项目在多个场合进行了直接的碰撞。这次竞争的发展态势,很快就超过了 Docker 公司的预期。
Kubernetes 项目并没有跟 Swarm 项目展开同质化的竞争
所以 "Docker Native"的说辞并没有太大的杀伤力
相反 k8s 项目让人耳目一新的设计理念和号召力,很快就构建出了一个与众不同的容器编排与管理的生态。Kubernetes 项目在 GitHub 上的各项指标开始一骑绝尘,将 Swarm 项目远远地甩在了身后.
CNCF 社区如何解决第二个问题:
在已经囊括了容器监控事实标准的 Prometheus 项目后,CNCF 社区迅速在成员项目中添加了 Fluentd、OpenTracing、CNI 等一系列容器生态的知名工具和项目。
而在看到了 CNCF 社区对用户表现出来的巨大吸引力之后,大量的公司和创业团队也开始专门针对 CNCF 社区而非 Docker 公司制定推广策略。
2016 年,Docker 公司宣布了一个震惊所有人的计划:放弃现有的 Swarm 项目,将容器编排和集群管理功能全部内置到 Docker 项目当中。
Docker 公司意识到了 Swarm 项目目前唯一的竞争优势,就是跟 Docker 项目的无缝集成。那么,如何让这种优势最大化呢?那就是把 Swarm 内置到 Docker 项目当中。
从工程角度来看,这种做法的风险很大。内置容器编排、集群管理和负载均衡能力,固然可以使得 Docker 项目的边界直接扩大到一个完整的 PaaS 项目的范畴,但这种变更带来的技术复杂度和维护难度,长远来看对 Docker 项目是不利的。
不过,在当时的大环境下,Docker 公司的选择恐怕也带有一丝孤注一掷的意味。
k8s 的应对策略
是反其道而行之,开始在整个社区推进"民主化"架构,即:从 API 到容器运行时的每一层,Kubernetes 项目都为开发者暴露出了可以扩展的插件机制,鼓励用户通过代码的方式介入到 Kubernetes 项目的每一个阶段。
Kubernetes 项目的这个变革的效果立竿见影,很快在整个容器社区中催生出了大量的、基于 Kubernetes API 和扩展接口的二次创新工作,比如:
目前热度极高的微服务治理项目 Istio;
被广泛采用的有状态应用部署框架 Operator;
还有像 Rook 这样的开源创业项目,它通过 Kubernetes 的可扩展接口,把 Ceph 这样的重量级产品封装成了简单易用的容器存储插件。在鼓励二次创新的整体氛围当中,k8s 社区在 2016 年后得到了空前的发展。更重要的是,不同于之前局限于"打包、发布"这样的 PaaS 化路线,这一次容器社区的繁荣,是一次完全以 Kubernetes 项目为核心的"百花争鸣"。
面对 Kubernetes 社区的崛起和壮大,Docker 公司也不得不面对自己豪赌失败的现实。但在早前拒绝了微软的天价收购之后,Docker 公司实际上已经没有什么回旋余地,只能选择逐步放弃开源社区而专注于自己的商业化转型。
所以,从 2017 年开始,Docker 公司先是将 Docker 项目的容器运行时部分 Containerd 捐赠给 CNCF 社区,标志着 Docker 项目已经全面升级成为一个 PaaS 平台;紧接着,Docker 公司宣布将 Docker 项目改名为 Moby,然后交给社区自行维护,而 Docker 公司的商业产品将占有 Docker 这个注册商标。
Docker 公司这些举措背后的含义非常明确:它将全面放弃在开源社区同 Kubernetes 生态的竞争,转而专注于自己的商业业务,并且通过将 Docker 项目改名为 Moby 的举动,将原本属于 Docker 社区的用户转化成了自己的客户。
2017 年 10 月,Docker 公司出人意料地宣布,将在自己的主打产品 Docker 企业版中内置 Kubernetes 项目,这标志着持续了近两年之久的"编排之争"至此落下帷幕。
2018 年 1 月 30 日,RedHat 宣布斥资 2.5 亿美元收购 CoreOS。
2018 年 3 月 28 日,这一切纷争的始作俑者,Docker 公司的 CTO Solomon Hykes 宣布辞职,曾经纷纷扰扰的容器技术圈子,到此尘埃落定。
容器技术圈子在短短几年里发生了很多变数,但很多事情其实也都在情理之中。就像 Docker 这样一家创业公司,在通过开源社区的运作取得了巨大的成功之后,就不得不面对来自整个云计算产业的竞争和围剿。而这个产业的垄断特性,对于 Docker 这样的技术型创业公司其实天生就不友好。
在这种局势下,接受微软的天价收购,在大多数人看来都是一个非常明智和实际的选择。可是 Solomon Hykes 却多少带有一些理想主义的影子,既然不甘于"寄人篱下",那他就必须带领 Docker 公司去对抗来自整个云计算产业的压力。
只不过,Docker 公司最后选择的对抗方式,是将开源项目与商业产品紧密绑定,打造了一个极端封闭的技术生态。而这,其实违背了 Docker 项目与开发者保持亲密关系的初衷。相比之下,Kubernetes 社区,正是以一种更加温和的方式,承接了 Docker 项目的未尽事业,即:以开发者为核心,构建一个相对民主和开放的容器生态。
这也是为何,Kubernetes 项目的成功其实是必然的。
很难想象如果 Docker 公司最初选择了跟 Kubernetes 社区合作,如今的容器生态又将会是怎样的一番景象。不过我们可以肯定的是,Docker 公司在过去五年里的风云变幻,以及 Solomon Hykes 本人的传奇经历,都已经在云计算的长河中留下了浓墨重彩的一笔。
小结
# 1. 容器技术的兴起源于 PaaS 技术的普及;
# 2. Docker 公司发布的 Docker 项目具有里程碑式的意义;
# 3. Docker 项目通过"容器镜像",解决了应用打包这个根本性难题。
# 容器本身没有价值,有价值的是"容器编排"。
# 也正因为如此,容器技术生态才爆发了一场关于"容器编排"的"战争"。而这次战争,最终以 Kubernetes 项目和 CNCF 社区的胜利而告终。
Kubernetes核心概念
什么是Kubernetes?
Kubernetes是一个完备的分布式系统支撑平台。
Kubernetes具有完备的集群管理能力,包括多层次的安全防护和准入机制/多租户应用支撑能力、透明的服务注册和服务发现机制、内建智能负载均衡器、强大的故障发现和自我修复功能、服务滚动升级和在线扩容能力、可扩展的资源自动调度机制,以及多粒度的资源配额管理能力。同时kubernetes提供了完善的管理工具,这些工具覆盖了包括开发、测试部署、运维监控在内的各个环节;因此kubernetes是一个全新的基于容器技术的分布式架构解决方案,并且是一个一站式的完备的分布式系统开发和支撑平台.
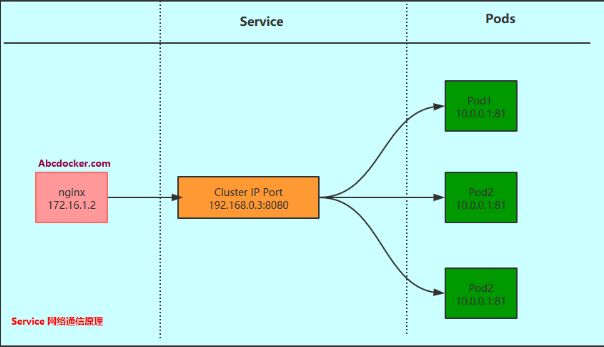
Kubernetes Service介绍
Service是分布式集群结构的核心,一个Server对象有以下关键特征:
# 1. 拥有一个唯一指定的名字(比如mysql-server)
# 2. 拥有一个虚拟IP(Cluster IP,Service IP或VIP和端口号)
# 3. 能够提供某种远程服务能力
# 4. 被映射到了提供这种服务能力的一组容器应用上.
Service的服务进程目前都基于Socker通信方式对外提供服务,比如redis、memcache、MySQL、Web Server,或者是实现了某个具体业务的一个特定的TCP Server进程。虽然一个Service通常由多个相关的服务进程来提供服务,每个服务进程都有一个独立的Endpoint(IP+Port)访问点,但Kubernetes 能够让我们通过Service
虚拟Cluster IP+Service Port连接到指定的Service上。有了Kubernetes内建的透明负载均衡和故障恢复机制,不管后端有多少服务进程,也不管某个服务进程是否会由于发生故障而重新部署到其他机器,都不会影响到我们对服务的正常调用。更重要的是这个Service本身一旦创建就不再变化,这意味着Kubernetes集群中,我们再也不用为了服务的IP地址变来变去的问题而头疼。
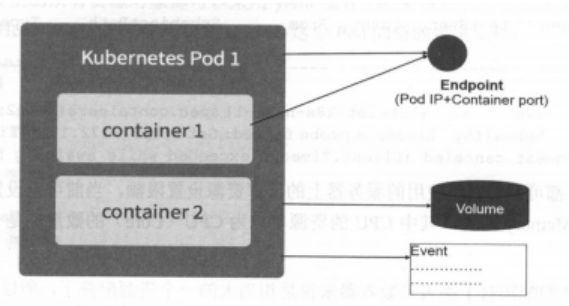
Kubernetes Pod介绍
Pod概念 Pod运行在一个我们称之为Node的环境中,可以是私有云也可以是公有云的虚拟机或者物理机上,通常在一个节点上运行几百个Pod,每个Pod运行着一个特殊的称之为Pause的容器,其他容器则为业务容器,这些业务容器共享着Pause容器的网络栈和Volume挂载卷,因此他们之间的通讯和数据交换更为高效,在设计时我们充分利用这一特征将一组密切相关的服务进程放入同一个Pod中.
并不是每个Pod和它里面的容器都映射到一个Service上,只是那些提供服务(无论是内还是对外)的一组Pod才会被映射成一个服务.
Service和Pod如何关联
容器提供了强大的隔离功能,所以有必要把Service提供服务的这组容器放入到容器中隔离,Kubernetes设计了Pod服务,将每个服务进程包装成相应的Pod中,使其成为Pod中运行的一个容器Container,为了建立Service和Pod间的关联关系,Kubernetes首先给每个Pod贴上了一个标签Label,给运行Mysql的Pod贴上了name=mysql标签,给运行PHP贴上name=php标签,然后给相应的Service定义标签选择器Label Selector,比如Mysql Service的标签选择器选择条件为name=mysql,意为该Service要作用于所有包含name=mysql Label的Pod上,这样就巧妙的解决了Service和Pod关联的问题.
Kubernetes RC介绍
RC介绍在Kubernetes集群中,你只需要为需要扩容的Service关联的Pod创建一个RC(Replication Controller),则该Service的扩容以至于后来的Service升级等头疼问题都可以迎刃而解,定义一个RC文件包含以下3个关键点.
# 1. 目标Pod的定义
# 2. 目标Pod需要运行的副本数量(Replicas)
# 3. 要监控的目标Pod的标签(Label)
在创建好RC系统自动创建号Pod后,Kubernetes会通过RC中定义的Label筛选出对应的Pod实例并监控其状态和数量,如果实例数量少于定义的副本数量Replicas则会用RC中定义的Pod模板来创建一个新的Pod,然后将Pod调度到合适的Node上运行,直到Pod实例的数量达到预定目标,这个过程完全是自动化的,无需人干预,只需要修改RC中的副本数量即可.
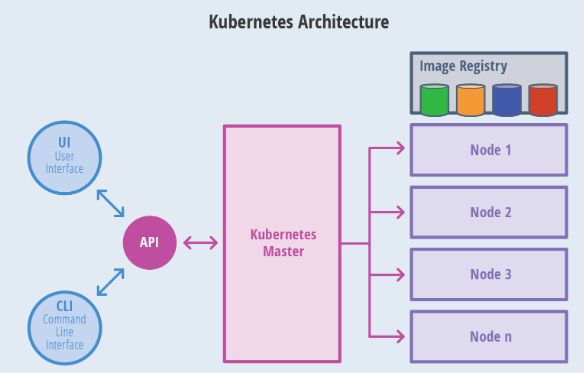
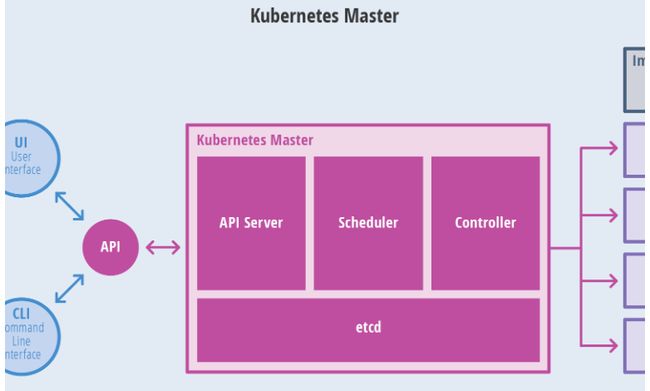
Kubernetes Master介绍
Kubernetes 里的Master指的是集群控制节点,每个Kubernetes集群里需要有一个Master节点来负责整个集群的管理和控制,基本上Kubernetes所有的控制命令都发给它,它负责具体的执行过程,我们后面执行的所有命令基本上都是在Master节点上运行的。如果Master宕机或不可用,那么集群内容器的管理都将失效.
Master节点上运行一下一组关键进程:
- Kubernetes API Server: 提供了HTTP Rest接口的关键服务进程,是Kubernetes里所有资源的增删改查等操作的唯一入口,也是集群控制的入门进程.
- Kubernetes Controller Manager 里所有的资源对象的自动化控制中心.
- Kubernetes Scheduler: 负责资源调度(Pod调度)的进程
另外在Master节点还需要启动一个etcd服务,因为Kubernetes里所有资源对象的数据全部保存在etcd中.
Kubernetes Node介绍
除了Master,集群中其他机器称为Node节点,每个Node都会被分配一些工作负载Docker容器,当某个Node宕机,其上的工作负载都会被Master自动转移到其他节点上去.
每个Node节点上都运行着以下一组关键进程
# 1. kubelet: 负责Pod对应的创建、停止等服务,同时与Master节点密切协作,实现集群管理的基本功能.
# 2. kube-proxy: 实现Kubernetes Service的通信与负载均衡机制的重要组件.
# 3. Docker Engine: Docker引擎,负责本机的容器创建和管理工作
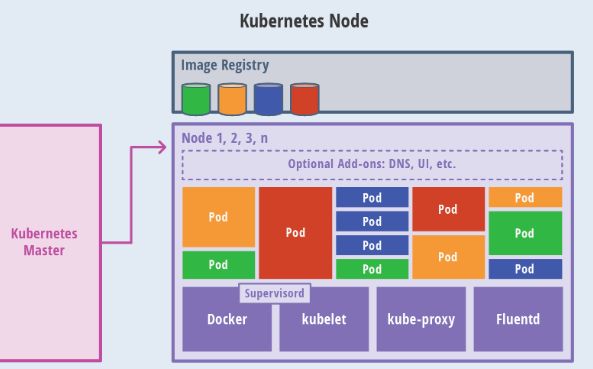
在集群管理方面,Kubernetes将集群中的机器划分为一个Master节点和一群工作节点(Node)中,在Master节点上运行着集群管理相关的一组进程kube-apiserver,kube-controller-manager和kube-scheduler,这些进程实现了整个集群的资源管理,Pod调度,弹性伸缩,安全控制,系统监控和纠错等管理功能,并且都是全自动完成的、Node作为集群中的工作节点,运行真正的应用程序,在Node上Kubernetes最小运行单元是Pod,Node上运行着Kubernetes的Kubelet、kube-proxy服务进程,这些服务进程负责Pod创建、启动、监控、重启、销毁以及软件模式的负载均衡.