深度学习实战(一) 在MNIST上训练DNN,比较学习曲线并保存最优模型
-
Build a DNN with five hidden layers of 100 neurons each, He initialization, and the ELU activation function.
-
Using Adam optimization and early stopping, try training it on MNIST but only on digits 0 to 4, as we will use transfer learning for digits 5 to 9 in the next exercise. You will need a softmax output layer with five neurons, and as always make sure to save checkpoints at regular intervals and save the final model so you can reuse it later.
-
Tune the hyperparameters using cross-validation and see what precision you can achieve.
import tensorflow as tf
import numpy as np
from datetime import datetime
import os
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
X_train = X_train.astype(np.float32).reshape(-1, 28*28) / 255.0
X_test = X_test.astype(np.float32).reshape(-1, 28*28) / 255.0
y_train = y_train.astype(np.int32)
y_test = y_test.astype(np.int32)
X_valid, X_train = X_train[:5000], X_train[5000:]
y_valid, y_train = y_train[:5000], y_train[5000:]
X_train = X_train[y_train < 5]
y_train = y_train[y_train < 5]
X_valid = X_valid[y_valid < 5]
y_valid = y_valid[y_valid < 5]
X_test = X_test[y_test < 5]
y_test = y_test[y_test < 5]
he_init = tf.variance_scaling_initializer()
def log_dir(prefix=""):
now = datetime.utcnow().strftime("%Y%m%d%H%M%S")
root_logdir = "tf_logs"
if prefix:
prefix += "-"
name = prefix + "run-" + now
return "{}/{}/".format(root_logdir, name)
def shuffle_batch(X, y, batch_size):
rnd_idx = np.random.permutation(len(X))
n_batches = len(X) // batch_size
for batch_idx in np.array_split(rnd_idx, n_batches):
X_batch, y_batch = X[batch_idx], y[batch_idx]
yield X_batch, y_batch
def dnn(inputs,layers=5,n_neural=100,init_type=he_init,activation=tf.nn.elu,name=""):
with tf.variable_scope("dnn"):
for layrnum in range(layers):
head = "hidden"
tname = "{}{}".format(head, layrnum+1)
inputs = tf.layers.dense(inputs, n_neural,kernel_initializer=init_type, activation=activation, name=tname )
return inputs
logdir = log_dir("mnist_dnn")
n_inputs = 28*28
n_outputs = 5
learning_rate = 0.01
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int32, shape=(None), name="y")
with tf.name_scope("dnn"):
outputs = dnn(X)
logits = tf.layers.dense(outputs, n_outputs, name="logits")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
loss_summary = tf.summary.scalar('loss', loss)
with tf.name_scope("train"):
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
accuracy_summary = tf.summary.scalar('accuracy', accuracy)
n_epochs = 10000
batch_size = 50
m = X_train.shape[0]
n_batches = int(np.ceil(m / batch_size))
best_loss_val = np.infty
checks_since_last_progress = 0
max_checks_without_progress = 20
checkpoint_path = "/tmp/my_logreg_model.ckpt"
checkpoint_epoch_path = checkpoint_path + ".epoch"
final_model_path = "./my_logreg_model"
init = tf.global_variables_initializer()
saver = tf.train.Saver()
file_writer = tf.summary.FileWriter(logdir, tf.get_default_graph())
with tf.Session() as sess:
if os.path.isfile(checkpoint_epoch_path):
# if the checkpoint file exists, restore the model and load the epoch number
with open(checkpoint_epoch_path, "rb") as f:
start_epoch = int(f.read())
print("Training was interrupted. Continuing at epoch", start_epoch)
saver.restore(sess, checkpoint_path)
else:
start_epoch = 0
sess.run(init)
for epoch in range(start_epoch, n_epochs):
batch_index = 0
for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size):
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
if batch_index % 10 == 0:
summary_str = loss_summary.eval(feed_dict={X: X_batch, y: y_batch})
step = epoch * n_batches + batch_index
file_writer.add_summary(summary_str, step)
batch_index = batch_index+1
acc_batch = accuracy.eval(feed_dict={X: X_batch, y: y_batch})
acc_val, loss_val = sess.run([accuracy, loss], feed_dict={X: X_valid, y: y_valid})
#acc_val, loss_val, accuracy_summary_str, loss_summary_str = sess.run([accuracy, loss, accuracy_summary, loss_summary], feed_dict={X: X_valid, y: y_valid})
#file_writer.add_summary(accuracy_summary_str, epoch)
#file_writer.add_summary(loss_summary_str, epoch)
if loss_val < best_loss_val:
#save_path = saver.save(sess,checkpoint_path)
best_loss_val = loss_val
checks_without_progress = 0
else:
checks_without_progress += 1
if checks_without_progress > max_checks_without_progress:
print("Early stopping!")
break
print(epoch, "Batch accuracy:", acc_batch, "Val accuracy:", acc_val)
saver.save(sess, checkpoint_path)
with open(checkpoint_epoch_path, "wb") as f:
f.write(b"%d" % (epoch + 1))
saver.save(sess, final_model_path)
os.remove(checkpoint_epoch_path)
acc_test = accuracy.eval(feed_dict={X: X_test, y: y_test})
print("Final accuracy on test set:", acc_test)
file_writer.close()log info:
0 Batch accuracy: 1.0 Val accuracy: 0.95191556
1 Batch accuracy: 1.0 Val accuracy: 0.9804535
2 Batch accuracy: 0.98 Val accuracy: 0.9757623
3 Batch accuracy: 1.0 Val accuracy: 0.98279905
4 Batch accuracy: 1.0 Val accuracy: 0.9816263
5 Batch accuracy: 1.0 Val accuracy: 0.98631746
6 Batch accuracy: 0.4 Val accuracy: 0.34284598
7 Batch accuracy: 0.82 Val accuracy: 0.7517592
8 Batch accuracy: 0.98 Val accuracy: 0.97810787
9 Batch accuracy: 1.0 Val accuracy: 0.9820172
10 Batch accuracy: 0.98 Val accuracy: 0.9859265
11 Batch accuracy: 1.0 Val accuracy: 0.98358095
12 Batch accuracy: 0.94 Val accuracy: 0.9644253
13 Batch accuracy: 0.94 Val accuracy: 0.97068024
14 Batch accuracy: 1.0 Val accuracy: 0.98006254
15 Batch accuracy: 1.0 Val accuracy: 0.98319
16 Batch accuracy: 1.0 Val accuracy: 0.98553556
17 Batch accuracy: 0.98 Val accuracy: 0.9769351
18 Batch accuracy: 1.0 Val accuracy: 0.9757623
19 Batch accuracy: 0.88 Val accuracy: 0.9577795
20 Batch accuracy: 0.94 Val accuracy: 0.9577795
21 Batch accuracy: 0.98 Val accuracy: 0.9851446
22 Batch accuracy: 0.98 Val accuracy: 0.97732604
23 Batch accuracy: 1.0 Val accuracy: 0.9757623
Early stopping!
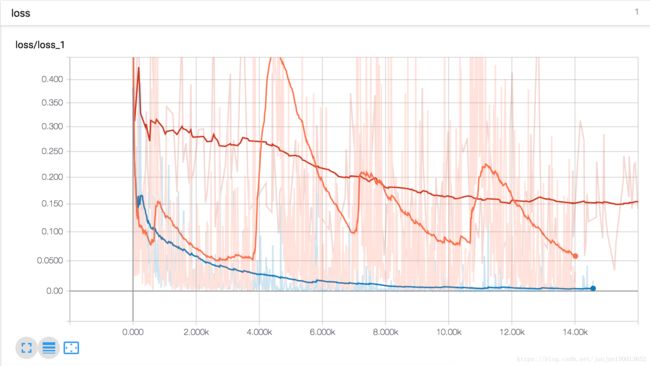
Final accuracy on test set: 0.98890835learning curves:
- Now try adding Batch Normalization and compare the learning curves: is it converging faster than before? Does it produce a better model?
import tensorflow as tf
import numpy as np
from datetime import datetime
import os
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
X_train = X_train.astype(np.float32).reshape(-1, 28*28) / 255.0
X_test = X_test.astype(np.float32).reshape(-1, 28*28) / 255.0
y_train = y_train.astype(np.int32)
y_test = y_test.astype(np.int32)
X_valid, X_train = X_train[:5000], X_train[5000:]
y_valid, y_train = y_train[:5000], y_train[5000:]
X_train = X_train[y_train < 5]
y_train = y_train[y_train < 5]
X_valid = X_valid[y_valid < 5]
y_valid = y_valid[y_valid < 5]
X_test = X_test[y_test < 5]
y_test = y_test[y_test < 5]
he_init = tf.variance_scaling_initializer()
training = tf.placeholder_with_default(False, shape=(), name='training') # extra ops for batch normalization
def log_dir(prefix=""):
now = datetime.utcnow().strftime("%Y%m%d%H%M%S")
root_logdir = "tf_logs"
if prefix:
prefix += "-"
name = prefix + "run-" + now
return "{}/{}/".format(root_logdir, name)
def shuffle_batch(X, y, batch_size):
rnd_idx = np.random.permutation(len(X))
n_batches = len(X) // batch_size
for batch_idx in np.array_split(rnd_idx, n_batches):
X_batch, y_batch = X[batch_idx], y[batch_idx]
yield X_batch, y_batch
def dnn(inputs,layers=5,n_neural=100,init_type=he_init,batch_norm_momentum = 0.9,activation=tf.nn.elu,name=""):
with tf.variable_scope("dnn"):
for layrnum in range(layers):
head = "hidden"
tname = "{}{}".format(head, layrnum+1)
inputs = tf.layers.dense(inputs, n_neural,kernel_initializer=init_type, name=tname )
inputs = tf.layers.batch_normalization(inputs, training=training, momentum=batch_norm_momentum) # extra ops for batch normalization
inputs = activation(inputs)
return inputs
logdir = log_dir("mnist_dnn")
n_inputs = 28*28
n_outputs = 5
learning_rate = 0.01
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int32, shape=(None), name="y")
with tf.name_scope("dnn"):
outputs = dnn(X)
logits = tf.layers.dense(outputs, n_outputs, name="logits")
Y_proba = tf.nn.softmax(logits, name="Y_proba")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
loss_summary = tf.summary.scalar('loss', loss)
with tf.name_scope("train"):
optimizer = tf.train.AdamOptimizer(learning_rate)
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) # extra ops for batch normalization
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32),name="accuracy")
accuracy_summary = tf.summary.scalar('accuracy', accuracy)
n_epochs = 10000
batch_size = 50
m = X_train.shape[0]
n_batches = int(np.ceil(m / batch_size))
best_loss_val = np.infty
checks_since_last_progress = 0
max_checks_without_progress = 20
checkpoint_path = "/tmp/my_logreg_model.ckpt"
checkpoint_epoch_path = checkpoint_path + ".epoch"
final_model_path = "./my_logreg_model"
init = tf.global_variables_initializer()
saver = tf.train.Saver()
file_writer = tf.summary.FileWriter(logdir, tf.get_default_graph())
with tf.Session() as sess:
if os.path.isfile(checkpoint_epoch_path):
# if the checkpoint file exists, restore the model and load the epoch number
with open(checkpoint_epoch_path, "rb") as f:
start_epoch = int(f.read())
print("Training was interrupted. Continuing at epoch", start_epoch)
saver.restore(sess, checkpoint_path)
else:
start_epoch = 0
sess.run(init)
for epoch in range(start_epoch, n_epochs):
batch_index = 0
for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size):
sess.run(extra_update_ops, feed_dict={training: True, X: X_batch, y: y_batch})
sess.run(training_op, feed_dict={training: True, X: X_batch, y: y_batch})
if batch_index % 10 == 0:
summary_str = loss_summary.eval(feed_dict={training: True, X: X_batch, y: y_batch})
step = epoch * n_batches + batch_index
file_writer.add_summary(summary_str, step)
batch_index = batch_index+1
acc_batch = accuracy.eval(feed_dict={training: True, X: X_batch, y: y_batch})
acc_val, loss_val = sess.run([accuracy, loss], feed_dict={X: X_valid, y: y_valid})
#acc_val, loss_val, accuracy_summary_str, loss_summary_str = sess.run([accuracy, loss, accuracy_summary, loss_summary], feed_dict={X: X_valid, y: y_valid})
#file_writer.add_summary(accuracy_summary_str, epoch)
#file_writer.add_summary(loss_summary_str, epoch)
if loss_val < best_loss_val:
#save_path = saver.save(sess,checkpoint_path)
best_loss_val = loss_val
checks_without_progress = 0
else:
checks_without_progress += 1
if checks_without_progress > max_checks_without_progress:
print("Early stopping!")
break
print(epoch, "Batch accuracy:", acc_batch, "Val accuracy:", acc_val)
saver.save(sess, checkpoint_path)
with open(checkpoint_epoch_path, "wb") as f:
f.write(b"%d" % (epoch + 1))
saver.save(sess, final_model_path)
os.remove(checkpoint_epoch_path)
acc_test = accuracy.eval(feed_dict={X: X_test, y: y_test})
print("Final accuracy on test set:", acc_test)
file_writer.close()log info:
0 Batch accuracy: 0.96 Val accuracy: 0.9749805
1 Batch accuracy: 0.98 Val accuracy: 0.9820172
2 Batch accuracy: 1.0 Val accuracy: 0.9851446
3 Batch accuracy: 0.98 Val accuracy: 0.9824081
4 Batch accuracy: 0.98 Val accuracy: 0.988663
5 Batch accuracy: 0.96 Val accuracy: 0.98944485
6 Batch accuracy: 1.0 Val accuracy: 0.99022675
7 Batch accuracy: 0.98 Val accuracy: 0.9859265
8 Batch accuracy: 1.0 Val accuracy: 0.98749024
9 Batch accuracy: 1.0 Val accuracy: 0.9878812
10 Batch accuracy: 1.0 Val accuracy: 0.9910086
11 Batch accuracy: 1.0 Val accuracy: 0.98944485
12 Batch accuracy: 1.0 Val accuracy: 0.9878812
13 Batch accuracy: 1.0 Val accuracy: 0.9851446
14 Batch accuracy: 1.0 Val accuracy: 0.99022675
15 Batch accuracy: 1.0 Val accuracy: 0.9913995
16 Batch accuracy: 1.0 Val accuracy: 0.9906177
17 Batch accuracy: 1.0 Val accuracy: 0.9921814
18 Batch accuracy: 1.0 Val accuracy: 0.99022675
19 Batch accuracy: 1.0 Val accuracy: 0.9882721
20 Batch accuracy: 1.0 Val accuracy: 0.9913995
21 Batch accuracy: 1.0 Val accuracy: 0.9937451
22 Batch accuracy: 1.0 Val accuracy: 0.9921814
23 Batch accuracy: 1.0 Val accuracy: 0.9921814
24 Batch accuracy: 1.0 Val accuracy: 0.988663
Early stopping!
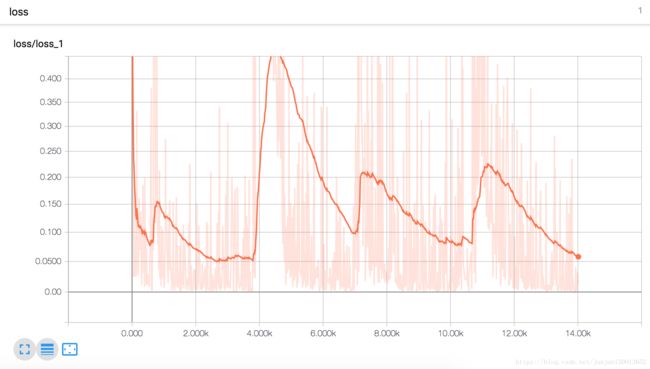
Final accuracy on test set: 0.99163264learning curves:
-
Is the model overfitting the training set? Try adding dropout to every layer and try again. Does it help?
import tensorflow as tf
import numpy as np
from datetime import datetime
import os
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
X_train = X_train.astype(np.float32).reshape(-1, 28*28) / 255.0
X_test = X_test.astype(np.float32).reshape(-1, 28*28) / 255.0
y_train = y_train.astype(np.int32)
y_test = y_test.astype(np.int32)
X_valid, X_train = X_train[:5000], X_train[5000:]
y_valid, y_train = y_train[:5000], y_train[5000:]
X_train = X_train[y_train < 5]
y_train = y_train[y_train < 5]
X_valid = X_valid[y_valid < 5]
y_valid = y_valid[y_valid < 5]
X_test = X_test[y_test < 5]
y_test = y_test[y_test < 5]
he_init = tf.variance_scaling_initializer()
training = tf.placeholder_with_default(False, shape=(), name='training') # extra ops for batch normalization
dropout_rate = 0.5 # extra for dropout
def log_dir(prefix=""):
now = datetime.utcnow().strftime("%Y%m%d%H%M%S")
root_logdir = "tf_logs"
if prefix:
prefix += "-"
name = prefix + "run-" + now
return "{}/{}/".format(root_logdir, name)
def shuffle_batch(X, y, batch_size):
rnd_idx = np.random.permutation(len(X))
n_batches = len(X) // batch_size
for batch_idx in np.array_split(rnd_idx, n_batches):
X_batch, y_batch = X[batch_idx], y[batch_idx]
yield X_batch, y_batch
def dnn(inputs,layers=5,n_neural=100,init_type=he_init,batch_norm_momentum = 0.9,activation=tf.nn.elu,name=""):
with tf.variable_scope("dnn"):
for layrnum in range(layers):
head = "hidden"
tname = "{}{}".format(head, layrnum+1)
inputs = tf.layers.dense(inputs, n_neural,kernel_initializer=init_type, name=tname )
inputs = tf.layers.batch_normalization(inputs, training=training, momentum=batch_norm_momentum) # extra ops for batch normalization
inputs = activation(inputs)
inputs = tf.layers.dropout(inputs, dropout_rate, training=training) # extra for dropout
return inputs
logdir = log_dir("mnist_dnn")
n_inputs = 28*28
n_outputs = 5
learning_rate = 0.01
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
X_drop = tf.layers.dropout(X, dropout_rate, training=training) # extra for dropout
y = tf.placeholder(tf.int32, shape=(None), name="y")
with tf.name_scope("dnn"):
outputs = dnn(X_drop)
logits = tf.layers.dense(outputs, n_outputs, name="logits")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
loss_summary = tf.summary.scalar('loss', loss)
with tf.name_scope("train"):
optimizer = tf.train.AdamOptimizer(learning_rate)
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) # extra ops for batch normalization
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
accuracy_summary = tf.summary.scalar('accuracy', accuracy)
n_epochs = 10000
batch_size = 50
m = X_train.shape[0]
n_batches = int(np.ceil(m / batch_size))
best_loss_val = np.infty
checks_since_last_progress = 0
max_checks_without_progress = 20
checkpoint_path = "/tmp/my_logreg_model.ckpt"
checkpoint_epoch_path = checkpoint_path + ".epoch"
final_model_path = "./my_logreg_model"
init = tf.global_variables_initializer()
saver = tf.train.Saver()
file_writer = tf.summary.FileWriter(logdir, tf.get_default_graph())
with tf.Session() as sess:
if os.path.isfile(checkpoint_epoch_path):
# if the checkpoint file exists, restore the model and load the epoch number
with open(checkpoint_epoch_path, "rb") as f:
start_epoch = int(f.read())
print("Training was interrupted. Continuing at epoch", start_epoch)
saver.restore(sess, checkpoint_path)
else:
start_epoch = 0
sess.run(init)
for epoch in range(start_epoch, n_epochs):
batch_index = 0
for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size):
sess.run(extra_update_ops, feed_dict={training: True, X: X_batch, y: y_batch})
sess.run(training_op, feed_dict={training: True, X: X_batch, y: y_batch})
if batch_index % 10 == 0:
summary_str = loss_summary.eval(feed_dict={training: True, X: X_batch, y: y_batch})
step = epoch * n_batches + batch_index
file_writer.add_summary(summary_str, step)
batch_index = batch_index+1
acc_batch = accuracy.eval(feed_dict={training: True, X: X_batch, y: y_batch})
acc_val, loss_val = sess.run([accuracy, loss], feed_dict={X: X_valid, y: y_valid})
#acc_val, loss_val, accuracy_summary_str, loss_summary_str = sess.run([accuracy, loss, accuracy_summary, loss_summary], feed_dict={X: X_valid, y: y_valid})
#file_writer.add_summary(accuracy_summary_str, epoch)
#file_writer.add_summary(loss_summary_str, epoch)
if loss_val < best_loss_val:
#save_path = saver.save(sess,checkpoint_path)
best_loss_val = loss_val
checks_without_progress = 0
else:
checks_without_progress += 1
if checks_without_progress > max_checks_without_progress:
print("Early stopping!")
break
print(epoch, "Batch accuracy:", acc_batch, "Val accuracy:", acc_val)
saver.save(sess, checkpoint_path)
with open(checkpoint_epoch_path, "wb") as f:
f.write(b"%d" % (epoch + 1))
saver.save(sess, final_model_path)
os.remove(checkpoint_epoch_path)
acc_test = accuracy.eval(feed_dict={X: X_test, y: y_test})
print("Final accuracy on test set:", acc_test)
file_writer.close()log info:
0 Batch accuracy: 0.96 Val accuracy: 0.9628616
1 Batch accuracy: 0.86 Val accuracy: 0.96207976
2 Batch accuracy: 0.94 Val accuracy: 0.9702893
3 Batch accuracy: 0.98 Val accuracy: 0.977717
4 Batch accuracy: 0.9 Val accuracy: 0.97615325
5 Batch accuracy: 0.9 Val accuracy: 0.9765442
6 Batch accuracy: 0.96 Val accuracy: 0.98084444
7 Batch accuracy: 0.96 Val accuracy: 0.97888976
8 Batch accuracy: 0.9 Val accuracy: 0.9820172
9 Batch accuracy: 0.96 Val accuracy: 0.9816263
10 Batch accuracy: 0.92 Val accuracy: 0.98397183
11 Batch accuracy: 0.94 Val accuracy: 0.98319
12 Batch accuracy: 0.96 Val accuracy: 0.98358095
13 Batch accuracy: 0.96 Val accuracy: 0.98397183
14 Batch accuracy: 1.0 Val accuracy: 0.9882721
15 Batch accuracy: 0.98 Val accuracy: 0.98553556
16 Batch accuracy: 0.98 Val accuracy: 0.98631746
17 Batch accuracy: 0.96 Val accuracy: 0.98631746
18 Batch accuracy: 0.94 Val accuracy: 0.9870993
19 Batch accuracy: 0.96 Val accuracy: 0.98553556
20 Batch accuracy: 0.94 Val accuracy: 0.9847537
21 Batch accuracy: 0.9 Val accuracy: 0.98670834
22 Batch accuracy: 0.88 Val accuracy: 0.9878812
23 Batch accuracy: 1.0 Val accuracy: 0.9882721
24 Batch accuracy: 0.98 Val accuracy: 0.9882721
25 Batch accuracy: 0.98 Val accuracy: 0.98553556
26 Batch accuracy: 0.92 Val accuracy: 0.98749024
27 Batch accuracy: 1.0 Val accuracy: 0.98553556
28 Batch accuracy: 0.98 Val accuracy: 0.9882721
29 Batch accuracy: 1.0 Val accuracy: 0.98749024
30 Batch accuracy: 0.98 Val accuracy: 0.98670834
31 Batch accuracy: 0.98 Val accuracy: 0.98944485
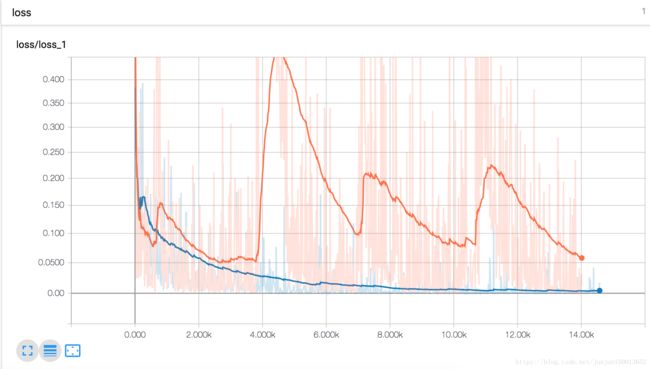
......learning curves: