Python 基础知识小结
转载自 玩蛇网 http://www.iplaypy.com
注释
分为三类:
1.中文注释(重要)
只要code中包含中文,不管是否在注释中,都需要添加中文注释,
否则很容易出错。
#coding=utf-8
或
#coding=gbk
2.当行注释
使用#号表示当行注释,#号所在行后内容会被忽略。
3.多行注释
使用三对”’注释内容”’或者”“”注释内容”“”表示多行注释,这里需要注意要使用英文字符,容易出现中文字符导致出错。
变量命名规范
python变量命名规范
1、变量名可以包括字母、数字、下划线,但是数字不能做为开头。例如:name1是合法变量名,而1name就不可以。
2、系统关键字不能做变量名使用
3、除了下划线之外,其它符号不能做为变量名使用
4、Python的变量名是区分大小写的,例如:name和Name就是两个变量名,而非相同变量。
查看数据类型type()
查看一个对象的数据类型可以使用内建函数type(),
type()接收一个对象,并返回该对象的数据类型,type()对象本身的数据结构类型为class type型。
>>> type(1)
>>> type(type(1))
内建方法查询dir()
python有很多内建方法,不同类型对象也有各自单独的内建方法,不需要全部记住,可以使用dir()方法获取。
dir(Object) #查看Object对象的内建方法
也可以查看独立模块包含内建方法,但要先导入该模块。
import sys #导入sys模块
dir(sys) #查看sys模块的内建方法
['__displayhook__', '__doc__', '__excepthook__', '__interactivehook__', ...........................................
基本数据类型
主要包含:
1.整型(int)
2.布尔型(bool)
只有True和False
3.字符串型(str)
4.列表list(())
5.元组tuple([])
6.字典dict({”:”})
其中,列表、元组、字典是python常用且与其它语言用法区别较大的类型。(重要)
不可变类型:int 、str、元组属于不可变类型
可变类型: 列表、字典属于可变类型。
字符串
1.创建方法
A.可以使用’ ‘or ” “直接创建字符串
>>>str1 = 'my first string'
>>>str2 = "my second string"
B.使用str()方法创建(重要)
str(Object)可以通过传入一个非字符串对象,把非字符串对象创建为字符串对象。如:
>>>iamint = 123
>>>iamstr = str(iamint)
>>> type(iamstr)
2.字串索引(下标)查找
A.正向索引,从0开始,从左往右递增。
B.反向索引,从-1开始,从右往左递减。(重要)
a = 'a b c d'
正向索引分别为 0 1 2 3
反向索引分别为 -4 -3 -2 -1
3.字符串切片
>>>a[0] ###单独读索引0的字符
>>>a[1:-1] ###取索引1开始到所以-1的字串
整型
1.类型
A.整型int的创建、声明
创建和声明是同一过程,即使用=赋值。
B.整型的特点
既然是整型自然赋值时候的数据要是整数才行,整数简单理解为(正整数和负整数)
C.整型变量间的运算操作符及方法(重要)
python目前可以支持的整型数据类型变量前的操作符有:加(+)、减(-)、乘()、除(/)和幂(**)
特别注意,幂运算是两个星号**
D.整型与字符串之间的转换(重要)
使用int()和str()函数进行整型与字符串之间的转换。
整型和字符串都是不可变类型数据,所以在这里需要注意两点:
a)、因为python int和字符串是不可变数据类型,这里的int( )和str( )方法只引用了原变量对应的数据,而并不是把原变量的类型修改了。
b)、同样因为整型和字符串都是不可变数据类型,所以所得结果一定要重新赋值之后才能被引用。
列表list()##(重要)
Python基础数据类型之一列表list,在python中作用很强在,列表List可以包含不同类型的数据对像,同时它是一个有序的集合。所有序列能用到的标准操作方法,列表也都可以使用,比如切片、索引等,python的list是可变数据类型,它支持添加 append、插入 insert、修改、删除del等操作。(要着重理解列表是一个有序集合,所有序列标准做法列表都可以使用。列表在内存中的数据类型是栈)
1.列表的创建
可以把python中的list列表理解为任意对像的序列,只要把需要的参数值放入到中括号[ ]里面就可以了,就像下面这样操作:
>>>mylist = [a,b,c,d]
列表可以包含不同类型对象,也支持嵌套:
>>>a = ['a',567,['adc',4,],(1,2)]
这个列表中就包含了字符串、整型、元组这些元素,同时还嵌套了一个列表.
2.修改列表list中的值
列表是有序的,可以通过python list下标来修改特定位置的值。
>>>a[0]=['b']
>>>a
[['b'],567,['adc',4,],(1,2)]
列表的修改操作,也可以把它看成是特定位置重新赋值的操作。
3.list 列表删除操作
python 列表删除最常用到的方法有三种:del、remove、pop,使用方法和用途也并不相同,这里先了解下del这种最方便的入门级列表删除操作方法。
现有列表 names = [‘ada’,’amy’,’ella’,’sandy’],要求是把上面列表中的’amy’删除,思路是:先知道’amy’在列表names中的索引位置,之后配合del这个方法来删除。列表del方法具体使用方法如下:
>>>names = ['ada','amy','ella','sandy']
>>>del names[1]
>>>names
['ada','ella','sandy']
Python列表的操作方法还有很多,像是python append、count、extend、index、python list insert、python reverse和sort排序等方法。
元组tuple(重要)
元组tuple是一种有序且不可变的数据结构。经常与列表list(有序可变)进行比较。
1.元组的创建
A.()定义法。元组是用小括号( )包括起来的,( )括号中的元素用逗号分割,这样就完成元组的创建了。
mytuple=(1,'a',2)
B.转化法。可以将一个列表或者字串转换为元组。
>>> tuple([1,2,3])
(1, 2, 3)
>>> tuple('sfsfs')
('s', 'f', 's', 'f', 's')
2.如何读取元组中的数据、值
元组是有序的,所以支持索引和切片操作。
3.修改元组数据
元组是不可变数据,不支持在原数据的修改,但可以通过把它转换为列表,在列表上修改数据,再转成元组数据。
>>>a=('a','b','c')
>>>b=list(a)
>>>b
['a','b','c']
>>>b[0]='b'
>>>b
['b','b','c']
>>>a=tuple(b)
>>>a
('b','b','c')
元组知识点总节:
a、元组是一个有序的集合,
b、元组和列表一样可以使用索引、切片来取值。
c、创建元组后不能在原地进行修改替换等操作。
d、元组支持嵌套,可以包含列表、字典和不同元组。
f、元组支持一般序列的操作,例如:+、*
字典(重要)
映射类型字典:字典是用大括号{ }来表示,它是python中最灵活的内置数据类型。它是一个无序的集合,通过键来存取值,而不能用索引。
1.创建
字典的组成:字典是由大括号{ }来包含其数据的,大括号内包含键和其对应的值,一对键和值成为一个项。键和值用冒号:隔开,项和项之间用逗号,号隔开。空字典就是不包含任何项的大括号,像{ }这样就是一个空字典。
注意:字典的键必须是不可变数据类型,如果用元组做键,那必须要保证元组内的对像也是不可变类型。可变数据类型对像不能做键。
>>>mydict = {'name':'messi','age':30}
2.如何访问字典中的值
字典是无序的,要访问字典value,只能通过键key来访问。
>>> mydict['name']
'messi'
3.字典添加键值对
字典添加方式如列表不同:字典变量名[新添加的键名] = 新键对应的值
>>>mydict['work']='football'
>>>mydict
{'name': 'messi', 'age': 30, 'work': 'football'}
4.修改字典值
字典修改格式:字典变量名[要修改值对应的键名] = 新值
>>>mydict['age']=31
>>> mydict
{'name': 'messi', 'age': 31, 'work': 'football'}
5.字典的删除
字典删方法常见有三种,作用也不同。下面简单说下这些方法的格式。
A.del方法:删除键对应的值,del空格 变量名[键名],如果只写变量名就是删除此字典,字典不存在。
B.clear方法:清空字典内容,变量名.clear(),清空字典,但字典依然存在。
C.pop方法:删除键对应的值,但它会把对值的应输出后再删除,即弹栈。
集合(重要)
在Python set是基本数据类型的一种集合类型,它有可变集合(set())和不可变集合(frozenset)两种。创建集合set、集合set添加、集合删除、交集、并集、差集的操作都是非常实用的方法。
1.集合的创建
>>> musicstar=set('tfboys')
>>> musicstar
{'t', 'o', 'b', 'f', 's', 'y'}
可以看出集合是无序的。
2.集合的添加和删除
python 集合的添加有两种常用方法,分别是add和update。
A.集合add方法:是把要传入的元素做为一个整个添加到集合中,例如:
>>> musicstar.add('pop')
>>> musicstar
{'t', 'o', 'pop', 'b', 'f', 's', 'y'}
B.集合update方法:是把要传入的元素拆分,做为个体传入到集合中,例如:
>>> musicstar.update('pop')
>>> musicstar
注意:集合中的元素是唯一的,不存在相同的元素,所以添加元素后,如果与原有集合重复,会被归并。
C.集合删除操作方法:remove
>>> musicstar.remove('s')
>>> musicstar
{'p', 't', 'o', 'b', 'f', 'y'}
3.集合运算和操作符号
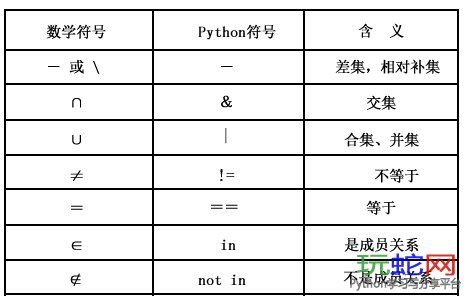
示例:
>>> colorA = set('yello')
>>> colorB = set('blue')
>>> colorA & colorB
{'l', 'e'}
>>> 'e' in colorA
True
>>> 'a' not in colorB
True
>>> colorA == colorB
False
>>> colorA | colorB
{'o', 'e', 'l', 'u', 'b', 'y'}
>>> colorA - colorB
{'y', 'o'}
print方法
1.print语句操作方法
创建一个字符串变量a,分别用print,和变量名来显示,看看效果有什么不一样。
>>> a = 'iplaypython'
>>>
>>> print a
iplaypython
>>>
>>> a
'iplaypython'
print变量名a,是直接输出了变量a的内容。而没用print语句,只用变量名输出的结果是用单引号括起来的。
2.print格式化输出(字符串、整数)
python的print语句和字符串操作符%一起结合使用,可以实现替换的可能。方法很巧妙,应用范围也比较多,操作方法如下:
>>> print "%s is %d old" % ("she",20)
she is 20 old
这里的%s和%d是占位符,分别是为字符串类型和整型来服务的。在占位符相关文章中过详细的来讲解。
print语句自动换行操作
print语句换行与不换行如何操作?
如果想让多个变量数据在同一行显示,操作起来很简单,只需要在变量名后边加逗号就可以了,像下面这样操作:
>>> a = 1
>>> b = 2
>>> c = 3
>>> print a,b,c
1 2 3
在Python 3.0中,print不再是语句而是一个函数,它的基本功能是不变的,print()。
函数
python函数分为内建函数、第三方函数和自定义函数。
内建函数可以直接调用,第三方函数需要导入函数模块才能调用。
定义函数function的方法:
定义函数需要注意的几个事项:
1、def开头,代表定义函数
2、def和函数名中间要敲一个空格
3、之后是函数名,这个名字用户自己起的,方便自己使用就好
4、函数名后跟圆括号(),代表定义的是函数,里边可加参数
5、圆括号()后一定要加冒号: 这个很重要,不要忘记了
6、代码块部分,是由语句组成,要有缩进
7、函数要有返回值return
def hello(name):
return 'hello,'+name+'!'
print(hello('iplaypython.com'))
hello,iplaypython.com!
类class定义 方法与属性(重要)
Python中的类(Class)是一个抽象的概念,比函数还要抽象,这也就是Python的核心概念,面对对象的编程方法(OOP),其它如:Java、C++等都是面对对象的编程语言。
1.python类有类的普遍优点
A.封装:封装之后,可以直接调用类的对象,来操作内部的一些类方法,不需要让使用者看到代码工作的细节。
B.继承:类可以从其它类或者元类中继承它们的方法,直接使用。
C类对象是多态的:也就是多种形态,这意味着我们可以对不同的类对象使用同样的操作方法,而不需要额外写代码。
示例:
>>> class Iplaypython:
>>> def fname(self, name):
>>> self.name = name
看一第行,语法是class 后面紧接着,类的名字,最后别忘记“冒号”,这样来定义一个类。
注意:类的名字,首字母,有一个不成文的规定,最好是大写,这样需要在代码中识别区分每个类。
第二行开始是类的方法,大家看到了,和函数非常相似,但是与普通函数不同的是,它的内部有一个“self“,参数,它的作用是对于对象自身的引用。
import语句导入模块语法
1.import语句作用:
import语句作用就是用来导入模块的,它可以出现在程序中的任何位置.
2.import语句语法:
使用import语句导入模块,import语句语法如下:
import module
关键字 模块名
使用方法例如:
import math #入导math模块
math.floor() #调用math模块中的floor()函数
如果要同时导入多个模块,只需要在模块名之前用逗号进行分隔:
import module1,module2,module3…….
同时导入多个模块的方法,对于初学者来说可读性和可理解性不如第一种好。所以想要导入多个模块时,还是比较推荐用第一种方式,把每一个模块都单独进行一次导入,可能会感觉操作起来麻烦一些,但便于理解。
3.import语句导入模块顺序
在编写代码过程中,我们可能需要多种多样的模块,需要注意的是最好把导入模块放在代码的开头。
为什么要把import导入模块放在程序开头使用呢?
解释器在执行语句时,遵循作用域原则。因为这和作用域有关系,如果在顶层导入模块,此时它的作用域是全局的;如果在函数内部导入了模块,那它的作用域只是局部的,不能被其它函数使用。如果其它函数也要用到这个模块,还需要再次导入比较麻烦。
在用import语句导入模块时最好按照这样的顺序:
a、python 标准库模块
b、python 第三方模块
c、自定义模块
4.from-import语句作用
python from import语句也是导入模块的一种方法,更确切的说是导入指定的模块内的指定函数方法。
优点是不用整个模块全部导入,使用函数时无需指定模块名。
缺点是如果不同模块有同名函数,之前的模块函数会被覆盖掉,可能调用到的函数与你意想的不一致。
5.from-import语句语法
from module import name
关键字 模块名 关键字 方法名
例如入导函数math模块中的floor函数方法:
from math import floor
python from使用方法例如:
from math import floor #导入math模块中的floor函数方法
floor() #调用floor()函数方法
help查看帮助
help()函数是查看函数或模块用途的详细说明,
而dir()函数是查看函数或模块内的操作方法都有什么,输出的是方法列表。
1.使用方法
help( )括号内填写参数,操作方法很简单。
open()函数文件打开、读、写操作详解
一、Python open()函数文件打开操作
格式:open(name[,mode[,buffering]])
open函数的文件名是必须的,而模式和缓冲参数都是可选的。比如说有个a.txt的文本文件,存放在c:\text下,那么你要打开它可以这样操作:
>>>x = open(r 'c:\text\a.txt')
二、open()函数文件打开模式参数常用值
‘r’读模式、’w’写模式、’a’追加模式、’b’二进制模式、’+’读/写模式。
三、python文件写入操作
>>>f = open('a.txt', 'w')
>>>f.write('hello,')
>>>f.write('iplaypython')
>>>f.close()
第一行:用写的方式打开a.txt这个文件,并赋给f 。
第二行:f.write方法写入( )括号内的内容。
第三行:同第二行意义相同,重点要说明下f.write写入的内容会追加到文件中已存在的数据后,也就是就此时的’iplaypython’是在’hello,’后边显示的。
第四行:最后调用close方法关闭文件,有打开就要有关闭。
四、python文件读取操作方法
要进行读文件操作,只需要把模式换成’r’就可以,也可以把模式为空不写参数,也是读的意思,因为程序默认是为’r’的。
>>>f = open('a.txt', 'r')
>>>f.read(5)
'hello'
read( )是读文件的方法,括号内填入要读取的字符数,这里填写的字符数是5,如果填写的是1那么输出的就应该是‘h’。
打开文件文件读取还有一些常用到的技巧方法,像下边这两种:
1、read( ):表示读取全部内容。
2、readline( ):表示逐行读取。
异常处理与捕获
Python使用它的异常对象(Exception object)来表示这种错误出现的情况。
只要代码中出现错误,无论是语法错误还是缩进错误,都会引发异常情况。如果这种异常没有被处理或者捕捉,程序就会回溯(Tracebace),抛出异常信息,终止程序运行。
如最常见的除0异常:
>>> 1/0
Traceback (most recent call last):
File "", line 1, in
1/0
ZeroDivisionError: division by zero
一、raise语句主动触发异常
>>> raise Exception
Traceback (most recent call last):
File "", line 1, in
raise Exception
Exception
二、捕捉异常
如果在程序出错的时候捕捉到这个错误,被用自己的方式来处理它,或者不想让使用程序的用户了解程序出错的详细信息,这个时候我们就需要捕捉异常,可以使用 try和except 语言。
>>> a = 10
>>> b = 0
>>> print a / b
这样,程序运行之后会产生异常错误,信息如下:
Traceback (most recent call last):
File "", line 1, in
print a /b
ZeroDivisionError: integer division or modulo by zero
如何处理上面的除零错误,并且返回自己想要的内容,请看下面的代码:
try:
a = 10
b = 0
print(a / b)
except ZeroDivisionError:
print("除零错误,已经捕获!")
如果需要同时捕捉多个可能的异常错误,可以把异常的类型,放入一个元组中,举例说明:
except (ZeroDivisionError, TypeError, NameError)
断言assert
在没完善一个程序之前,我们不知道程序在哪里会出错,与其让它在运行最崩溃,不如在出现错误条件时就崩溃,这时候就需要assert断言的帮助。
1.assert断言的作用
assert断言是声明其布尔值必须为真的判定,如果发生异常就说明表达示为假。可以理解assert断言语句为raise-if-not,用来测试表示式,其返回值为假,就会触发异常。
2.assert断言语句的语法格式
expression assert 表达式
下面做一些assert用法的语句供参考:
assert 1==1
assert 2+2==2*2
3.如何为assert断言语句添加异常参数
assert的异常参数,其实就是在断言表达式后添加字符串信息,用来解释断言并更好的知道是哪里出了问题。格式如下:
assert expression [, arguments]
assert 表达式 [, 参数]
pass语句
pass语句表示它不做任何事情,一般用做占位语句。
一.pass语句在函数中的作用
当你在编写一个程序时,执行语句部分思路还没有完成,这时你可以用pass语句来占位,也可以当做是一个标记,是要过后来完成的代码。比如下面这样:
>>>def iplaypython():
>>> pass
定义一个函数iplaypython,但函数体部分暂时还没有完成,又不能空着不写内容,因此可以用pass来替代占个位置。
pass语句用法总结:
1、空语句,什么也不做
2、在特别的时候用来保证格式或是语义的完整性
global全局变量语句
global语句可以起到声明变量作用域,了可以理解为能修改重新定义全局变量的作用。1.global语句的作用
在编写程序的时候,如果想为一个在函数外的变量重新赋值,并且这个变量会作用于许多函数中时,就需要告诉python这个变量的作用域是全局变量。此时用global语句就可以变成这个任务,也就是说没有用global语句的情况下,是不能修改全局变量的。
2.如何使用global语句
用global语句的使用方法很简单,基本格式是:关键字global,后跟一个或多个变量名
>>>x = 6
>>>def func():
>>> global x
>>> x = 1
>>> print(x)
6
>>>func()
>>>print x
1
用print语句输出x的值,此时的全局变量x值被重新定义为1。python中的global语句是被用来声明是全局的,所以在函数内把全局变量重新赋值时,这个新值也反映在引用了这个变量的其它函数中。
if控制流语句
if语句用于控制条件代码的执行,else和elif也是同样的功能,通常和for循环语句搭配使用。
1.标准python if条件语句格式
python if语句的一般格式如下:
python if决策条件:
执行语句块
for循环控制语句
for循环语句是python中的一个循环控制语句,任何有序的序列对象内的元素都可以遍历,比如字符串、列表List、元组等可迭代对像。之前讲过的if语句虽然和for语句用法不同,但可以用在for语句下做条件语句使用。
1.for语句的基本格式
python for循环的一般格式:第一行是要先定义一个赋值目标(迭代变量),和要遍历(迭代)的对像;首行后面是要执行的语句块。
for 目标 in 对像:
print 赋值目标
while循环控制流语句
while循环语句和for语句都是python的主要循环结构。while语句是python中最通用的迭代结构,也是一个条件循环语句。
1.python while循环语句和if语句有哪些不同之处
要想知道while与if两种语句有何不同,首先要知道while语句的工作原理。if语句是条件为真True,就会执行一次相应的代码块;而while中的代码块会一直循环,直到循环条件不能满足不再为真。
2.while语句一般标准语法
while循环语句的语法如下所示:
python while 条件:
执行代码块
while循环中的执行代码块会一直循环执行,直到当条件不能被满足为假False时才退出循环,并执行循环体后面的语句。python while循环语句最常被用在计数循环中。
else与elif语句
else和elif语句也可以叫做子句,因为它们不能独立使用,两者都是出现在if、for、while语句内部的。else子句可以增加一种选择;而elif子句则是需要检查更多条件时会被使用,与if和else一同使用,elif是else if 的简写。
1.if和else、elif语句使用时要注意以下两点:
A、else、elif为子块,不能独立使用
B、一个if语句中可以包含多个elif语句,但结尾只能有一个else语句
2.else在while、for循环语句中的作用
python中,可以在while和for循环中使用else子句,它只是在循环结束之后才会被执行,如果同时使用了break语句那么else子句块会被跳过。所以注意else子句和break语句不能同时使用!
匿名函数Lambda
Lambda表达式
在Python语言中除了def语句用来定义函数之外,还可以使用匿名函数lambda,它是Python一种生成函数对象的表达式形式。匿名函数通常是创建了可以被调用的函数,它返回了函数,而并没有将这个函数命名。lambda有时被叫做匿名函数也就是这个原因,需要一个函数,又不想动脑筋去想名字,这就是匿名函数。# 普通python函数 def func(a,b,c): return a+b+c print func(1,2,3) # 返回值为6 # lambda匿名函数 f = lambda a,b,c:a+b+c print f(1,2,3) # 返回结果为6注意观察上面的Python示例代码,f = lambda a,b,c:a+b+c 中的关键字lambda表示匿名函数,冒号:之前的a,b,c表示它们是这个函数的参数。匿名函数不需要return来返回值,表达式本身结果就是返回值。
2.匿名函数作用
A.lambda是一个表达式,而并非语句
因为lambda是一个表达式,所以在python语言中可以出现在def语句所不能出现的位置上;
lambda与def语句相比较,后者必须在一开始就要将新函数命名;而前者返回一个新函数,可以有选择性的赋值变量名。
B.lambda主体只是单个表达式,并而一个代码块
lambda与普通函数function定义方法来比较它的功能更小,它只是一个为简单函数所服务的对象,而def能处理更大型的数据任务。
C.为什么要使用lambda?
用python学习手册中的一段话来回答这个问题非常好“lambda有起到速写函数的作用,允许在使用的代码内嵌入一个函数的定义。在仅需要嵌入一小段可执行代码的情况下,就可以带来更简洁的代码结构。”lambda的使用在python基础知识学习中就会遇到,但真正应用时还是在python进阶的阶段,这时需要你做更深入学习。