深度学习NLP-词向量篇(含代码实现)
本文是最近学习了斯坦福大学的NLP课程CS224N,和一些相关教程后,整理出来的一篇关于词向量的学习笔记。主要记录了关于词向量的产生,关于计数的词向量生成法,基于分布的词向量生成法(Cbow,Skip-gram,GloVe),和一些相关知识。
一、词嵌入的简介
语言模型
在计算机学科里,一个语言模型往往指的是使用一种知识表达的方法,通过计算一个单词/句子产生的概率来表达一种语言规律。传统的语言模型中词的表示是原始的、面向字符串的。两个语义相似的词的字符串可能完全不同,比如“番茄”和“西红柿”。这给所有NLP任务都带来了挑战——字符串本身无法储存语义信息。所以我们提出了基于语义的语言表达方式——通过编码的方式表达单词以及单词间的联系(语义)。这也就是我们今天要介绍的词嵌入。
词嵌入
简单来说,词嵌入就是将文本转换成数字,方法不同,数值表征也不同。在深入之前,先来讨论下为什么需要词嵌入?
人们经过实践得出结论,多数机器学习算法和几乎所有的深度学习框架都不能处理原始个格式的字符串和文本。机器需要数字作为输入,才能执行分类回归这样的任务。文本中蕴含着海量的数据,有必要从中提取出有用的东西,并创建应用,比如亚马逊商品评论、文档或新闻的情感分析、谷歌搜索的分类和聚类。
给词嵌入下个定义:词嵌入是使用词典,将单词映射到矢量上。
二、实现词嵌入的方法
实现词嵌入大体有两种方法:基于频率和基于预测。
基于频率的词嵌入
一般来讲基于频率我们可以简单理解成对每一个单词在语料库中出现次数的计数。一般来说,有三种方式:
- 计数向量
- TF-IDF向量
- 共现向量
这里就不详细展开了,有兴趣的同学可以看一下这篇博客里面有详细记载关于三种计数方式的讲解。
基于预测的词嵌入
基于预测的词嵌入是我们今天讲解的重点。主要有CBow,Skip-gram,和GloVe三个方法。前两个是2012年Mitolov大神推出。本来人家是要推出一个词预测模型的,词嵌入的结果只是副产物。但是由于发现词嵌入矩阵不仅仅能用来预测词。还能作为一种语言表达方式,通过编码单词达到表达单词和单词的语义的效果。故基于预测的词嵌入的方法开始他的传奇。目前,词嵌入作为一个NLP模型的基础操作,已广泛应用到各个NLP任务中了。GloVe是斯坦福大学在2014年推出的一款升级款词嵌入方法。目前也是应用非常广泛的词嵌入Benchmark。
三、基于预测的方法
基于预测的词嵌入方法,说的通俗一点就是学习词向量的分布。下面简单讲解下三个应用广泛的方法。
CBow&Skip-gram

如图所示,我们可以看到两个模型的区别,Cbow用输入的上下文来预测目标单词。Skip-gram用输入的单词预测目标上下文。假设有一个句子“Pineapples are spiked and yellow”,两个模型的预测方式如下:
- 在CBOW中,先在句子中选定一个中心词,并把其他词作为这个中心词的上下文。如 图4 CBOW所示,把“spiked”作为中心词,把“Pineapples are and yellow”作为中心词的上下文。在学习过程中,使用上下文的词向量预测中心词,这样中心词的语义就被传递到上下文的词向量中,如“spiked”=>“pineapple”,从而达到学习语义信息的目的。
- 在Skip-gram中,同样先选定一个中心词,并把其他词作为这个中心词的上下文。如 图4 Skip-gram所示,把“spiked”作为中心词,把“Pineapples are and yellow”作为中心词的上下文。不同的是,在学习过程中,使用中心词的词向量去预测上下文,从而达到学习语义信息的目的。
一般来说,CBOW比Skip-gram训练速度快,训练过程更加稳定,原因是CBOW使用上下文average的方式进行训练,每个训练step会见到更多样本。而在生僻字(出现频率低的字)处理上,skip-gram比CBOW效果更好,原因是skip-gram不会刻意回避生僻字。
CBOW和Skip-gram的算法实现:

如所示,Skip-gram是一个具有3层结构的神经网络,分别是:
Input Layer(输入层):接收一个one-hot张量 作为网络的输入,里面存储着当前句子中心词的one-hot表示。
Hidden Layer(隐藏层):将张量乘以一个word embedding张量,并把结果作为隐藏层的输出,得到一个形状为的张量,里面存储着当前句子中心词的词向量。
Output Layer(输出层):将隐藏层的结果乘以另一个word embedding张量,得到一个形状为的张量。
这个张量经过softmax变换后,就得到了使用当前中心词对上下文的预测结果。根据这个softmax的结果,我们就可以去训练词向量模型。在实际操作中,使用一个滑动窗口(一般情况下,长度是奇数),从左到右开始扫描当前句子。每个扫描出来的片段被当成一个小句子,每个小句子中间的词被认为是中心词,其余的词被认为是这个中心词的上下文。
Skip-gram的理想实现
使用神经网络实现Skip-gram中,模型接收的输入应该有2个不同的tensor:
代表中心词的tensor:假设我们称之为center_words ,一般来说,这个tensor是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中,每个中心词的ID。
代表目标词的tensor:假设我们称之为target_words ,一般来说,这个tensor是一个形状为[batch_size, 1]的整型tensor,这个tensor中的每个元素是一个[0, vocab_size-1]的值,代表目标词的ID。
在理想情况下,我们可以使用一个简单的方式实现skip-gram。即把需要预测的每个目标词都当成一个标签,把skip-gram当成一个大规模分类任务进行网络构建,过程如下:
声明一个形状为[vocab_size, embedding_size]的张量,作为需要学习的词向量,记为。对于给定的输入,使用向量乘法,将乘以,这样就得到了一个形状为[batch_size, embedding_size]的张量,记为。这个张量就可以看成是经过词向量查表后的结果。
声明另外一个需要学习的参数,这个参数的形状为[embedding_size, vocab_size]。将上一步得到的去乘以,得到一个新的tensor ,此时的是一个形状为[batch_size, vocab_size]的tensor,表示当前这个mini-batch中的每个中心词预测出的目标词的概率。
使用softmax函数对mini-batch中每个中心词的预测结果做归一化,即可完成网络构建。
Skip-gram的实际实现 (负采样的使用)
然而在实际情况中,vocab_size通常很大(几十万甚至几百万),导致和也会非常大。对于而言,所参与的矩阵运算并不是通过一个矩阵乘法实现,而是通过指定ID,对参数进行访存的方式获取。然而对而言,仍要处理一个非常大的矩阵运算(计算过程非常缓慢,需要消耗大量的内存/显存)。为了缓解这个问题,通常采取负采样(negative_sampling)的方式来近似模拟多分类任务。
假设有一个中心词和一个目标词正样本。在Skip-gram的理想实现里,需要最大化使用预测的概率。在使用softmax学习时,需要最大化的预测概率,同时最小化其他词表中词的预测概率。之所以计算缓慢,是因为需要对词表中的所有词都计算一遍。然而我们还可以使用另一种方法,就是随机从词表中选择几个代表词,通过最小化这几个代表词的概率,去近似最小化整体的预测概率。比如,先指定一个中心词(如“人工”)和一个目标词正样本(如“智能”),再随机在词表中采样几个目标词负样本(如“日本”,“喝茶”等)。有了这些内容,我们的skip-gram模型就变成了一个二分类任务。对于目标词正样本,我们需要最大化它的预测概率;对于目标词负样本,我们需要最小化它的预测概率。通过这种方式,我们就可以完成计算加速。上述做法,我们称之为负采样。
在实现的过程中,通常会让模型接收3个tensor输入:
代表中心词的tensor:假设我们称之为center_words ,一般来说,这个tensor是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个中心词具体的ID。
代表目标词的tensor:假设我们称之为target_words ,一般来说,这个tensor同样是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个目标词具体的ID。
代表目标词标签的tensor:假设我们称之为labels ,一般来说,这个tensor是一个形状为[batch_size, 1]的tensor,每个元素不是0就是1(0:负样本,1:正样本)。
模型训练过程如下:
用去查询,用去查询,分别得到两个形状为[batch_size, embedding_size]的tensor,记为和。
点乘这两个tensor,最终得到一个形状为[batch_size]的tensor 。
使用sigmoid函数作用在上,将上述点乘的结果归一化为一个0-1的概率值,作为预测概率,根据标签信息label训练这个模型即可。
在结束模型训练之后,一般使用作为最终要使用的词向量,可以用提供的向量表示。通过向量点乘的方式,计算两个不同词之间的相似度。
在这里,提供了Skip-gram的实现代码
四、基于全局信息的GloVe
Cbow 或者Skip-Gram取得了很大的成功,不管在训练效率还是在词向量的计算效果上面。但是考虑到Cbow/Skip-Gram 是一个local context window的方法,比如使用NS来训练,缺乏了整体的词和词的关系,负样本采用sample的方式会缺失词的关系信息。另外,直接训练Skip-Gram类型的算法,很容易使得高曝光词汇得到过多的权重。
Global Vector融合了矩阵分解Latent Semantic Analysis (LSA)的全局统计信息和local context window优势。融入全局的先验统计信息,可以加快模型的训练速度,又可以控制词的相对权重。
设共现矩阵为X,其元素为Xi,j。Xi,j 的意义为:在整个语料库中,单词i和单词j共同出现在一个窗口中的次数。


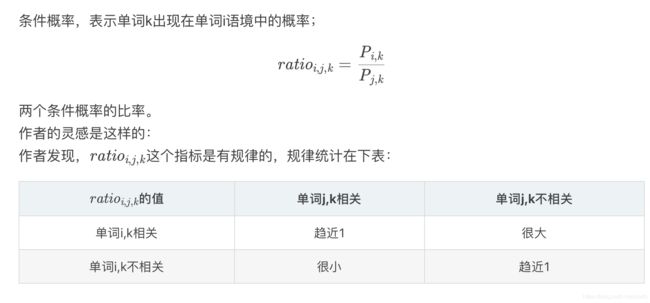

Ref:
斯坦福CS224N课程
词向量的深度解析
word2vec进阶之skim-gram和CBOW模型
cs224n系列之word2vec & 词向量
GloVe原理介绍