云计算(1.3)Google云计算三大核心技术 - 分布式结构化数据表BigTable
前言
前面学习了GFS(分布式存储系统),MapReduce(分布式数据处理)
接下来学习最后一个技术:分布式结构化数据表BigTable
谷歌技术"三宝"之BigTable
Google Bigtable 中文版
引进BigTable
GFS(2003年发表)使用商用硬件集群存储海量数据。文件系统将数据在节点之间冗余复制。MapReduce(2004)是GFS架构的一个补充,因为它能够充分利用GFS集群中所有低价服务器提供的大量CPU
但是两个系统都有一定的缺陷:
- 两个系统都缺乏实时随机存取数据的能力,意味着尚不足以处理Web服务
- GFS的另一个缺陷就是,它适合存储少许非常非常大的文件,而不适合存储成千数万的小文件,文件越多master的压力越大
考虑放弃关系型的特点,采用简单的API来进行增删改查操作,另加一个扫描函数,以在较大的键范围或全表上迭代扫描,最终形成一个管理结构化数据的分布式存储系统BigTable(2006)
GFS MapReduce BigTable关系
BigTable数据模型
BigTable是分布式多维映射表,是一个稀疏的、分布式的、持久化存储的多维度排序Map
持久化的意思很简单,Bigtable的数据最终会以文件的形式放到GFS,即可以长时间保存
Bigtable建立在GFS之上本身就意味着分布式
稀疏的意思是,一个表里不同的行,列可能完完全全不一样
Map
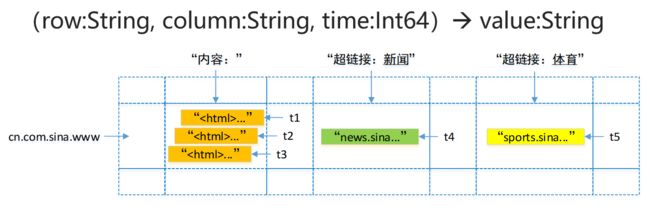
Map键值对,键有三维:行关键字、列关键字、时间戳
有四个属性:行关键字、列关键字、时间戳、值
行row
行键可以是任意字节串,通常有10-100字节。
行的读写都是原子性的。
Bigtable按照行键的字典序存储数据。
将网址作为行关键字
采用网址倒置(cn.com.sina.www):方便判断不同的行
可任意多行
Bigtable的表会根据行键自动划分为片(tablet),片是负载均衡的单元。最初表都只有一个片,但随着表不断增大,片会自动分裂,片的大小控制在100-200MB。行是表的第一级索引
列column
列是第二级索引,每行拥有的列是不受限制的,可以随时增加减少。
为了方便管理,列被分为多个列族(column family,是访问控制的单元),以列族:限定词的形式区分:“内容:”,“超链接:新闻”
可任意多列
时间戳
时间戳是第三级索引,用于处理版本更新
数据的不同版本按照时间戳降序存储,因此先读到的是最新版本的数据
t1,t2,t3就是时间戳

查询时,如果只给出行列,那么返回的是最新版本的数据;
如果给出了行列时间戳,那么返回的是时间小于或等于时间戳的数据(即该版本及以前的版本)
系统架构
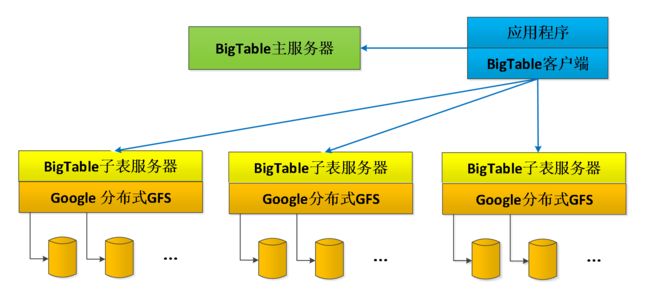 BigTable包括三个主要部分:一个供客户端使用的库,一个主服务器(master server),许多片服务器\子表服务器(tablet server)
BigTable包括三个主要部分:一个供客户端使用的库,一个主服务器(master server),许多片服务器\子表服务器(tablet server)
- Tablet Server
BigTable将表按行分成片(tablet)
一个子表服务器负责一定量的片,处理对其片的读写请求,以及片的分裂或合并
片服务器可以根据负载随时添加和删除
片服务器并不真实存储数据,而相当于一个连接Bigtable和GFS的代理,客户端的一些数据操作都通过片服务器代理间接访问GFS
- Master Server
主服务器负责将片分配给片服务器,监控片服务器的添加和删除,平衡片服务器的负载,处理表和列族的创建等。注意,主服务器不存储任何片,不提供任何数据服务,也不提供片的定位信息(与GFS不同)
- 客户端
客户端需要读写数据时,直接与片服务器联系。因为客户端并不需要从主服务器获取片的位置信息,所以大多数客户端从来不需要访问主服务器,主服务器的负载一般很轻
Table的位置
既然Master Server不负责表的位置信息,那么表的位置在哪
通过阅读BigTable论文可以知道
以一个三层的、类似B+树的结构存储tablet
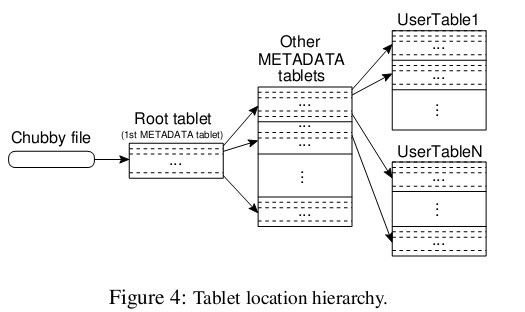 第一层,Chubby file。这一层是一个Chubby文件,它保存着root tablet的位置。这个Chubby文件属于Chubby服务的一部分,一旦Chubby不可用,就意味着丢失了root tablet的位置,整个Bigtable也就不可用了
第一层,Chubby file。这一层是一个Chubby文件,它保存着root tablet的位置。这个Chubby文件属于Chubby服务的一部分,一旦Chubby不可用,就意味着丢失了root tablet的位置,整个Bigtable也就不可用了
第二层是root tablet。root tablet其实是元数据表(METADATA table)的第一个分片,它保存着元数据表其它片的位置,root table永远不会被分割,保证了Tablet的存储信息结构永远是三层
第三层是其它的元数据片,它们和root tablet一起组成完整的元数据表。每个元数据片都包含了许多用户片的位置信息。
位置及分配功能要彻底明白需要挺多知识点,暂时搞不懂,跳过
Tablet服务
BigTable最终片还是要保存在GFS中持久化

将片数据存入GFS:片在GFS里的物理形态就是若干个SSTable文件
下图展示了读写情况
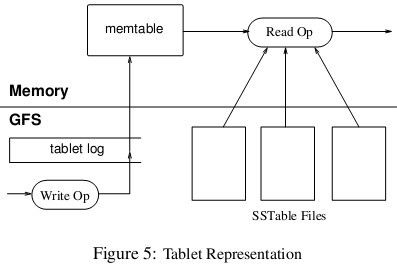
当片服务器收到一个写请求,片服务器首先检查请求是否合法。如果合法,先将写请求提交到日志去,然后将数据写入内存中的memtable。memtable相当于SSTable的缓存,当memtable成长到一定规模会被冻结,Bigtable随之创建一个新的memtable,并且将冻结的memtable转换为SSTable格式写入GFS,这个操作称为minor compaction。
当片服务器收到一个读请求,同样要检查请求是否合法。如果合法,这个读操作会查看所有SSTable文件和memtable的合并视图,因为SSTable和memtable本身都是已排序的,所以合并相当快。
每一次minor compaction都会产生一个新的SSTable文件,SSTable文件太多读操作的效率就降低了,所以Bigtable定期执行merging compaction操作,将几个SSTable和memtable合并为一个新的SSTable。BigTable还有个更厉害的叫major compaction,它将所有SSTable合并为一个新的SSTable。