Bitmap算法简介
Bitmap算法中文又叫做位图算法。那么什么是Bitmap算法呢?
位图算法中的位图是内存中连续的二进制位(bit),用于对大量整形数据做去重和查询。
举个例子,给定一块长度是10bit的内存空间,想要依次插入整形数据4,2,1,3。我们需要怎么做呢?
1. 给定长度是10的bitmap,每一个bit位分别对应着从0到9的10个整型数。此时bitmap的所有位都是0。

2. 把整型数4存入bitmap,对应存储的位置就是下标为4的位置,将此bit置为1。

3. 把整型数2存入bitmap,对应存储的位置就是下标为2的位置,将此bit置为1。

4. 把整型数1存入bitmap,对应存储的位置就是下标为1的位置,将此bit置为1。

5. 把整型数3存入bitmap,对应存储的位置就是下标为3的位置,将此bit置为1。

要问此时bitmap里存储了哪些元素?显然是4、3、2、1,一目了然。
Bitmap不仅方便查询,还可以去除掉重复的整型数。
虽然HashSet和HashMap也同样能实现用户的去重和统计,但是如果使用HashSet和HashMap存储的话,每一个数据比如用户ID都要存成int,占4字节即32bit。而一个用户ID在Bitmap中只占一个bit,内存节省了32倍。
不仅如此,Bitmap在做交集和并集运算的时候也有极大的便利。我们来看看下面的例子:
1. 如何查找使用苹果手机的程序员用户?
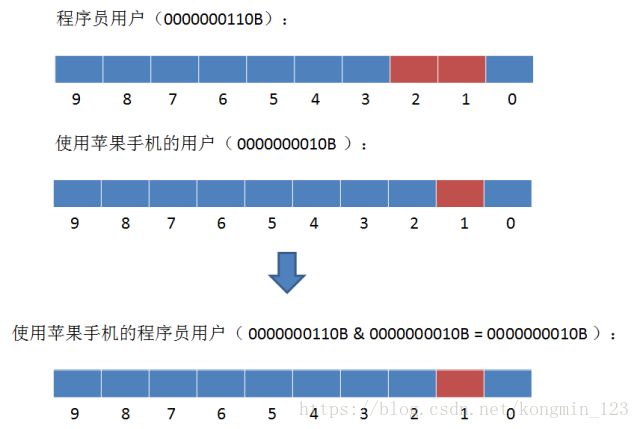
2. 如何查找所有男性或者00后的用户?
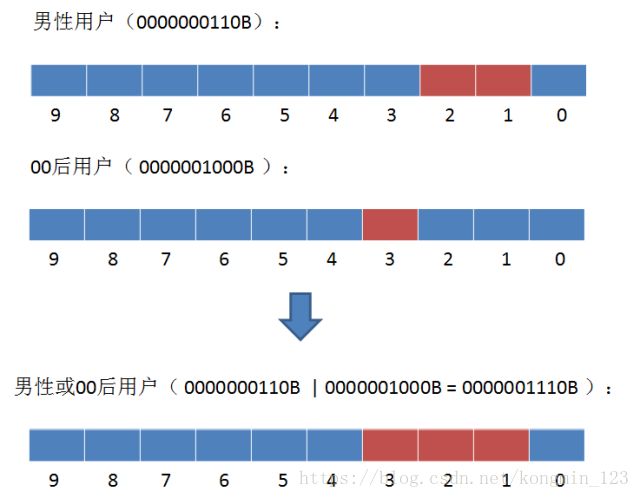
这就是Bitmap算法的另一个优势:位运算的高性能。
那么Bitmap这种解决方案这么方便,它有什么缺点没?
缺点也是存在的,Bitmap不支持[非运算]。比如想要查找不使用苹果手机的用户,Bitmap就无能为力了。
现在也有一些开源的Bitmap的实现:
Bitmap和BitSet的关系:JDK中的BitSet集合是对Bitmap相对简单的实现。
而谷歌开发的EWAHCompressedBitmap则是一种更为优化的实现。
EWAH的意思是Enhanced Word-Aligned Hybrid,在WAH基础上优化而来。
Bitmap的一个缺点无法进行[非运算],为什么不能进行非运算呢?
在统计用户标签这样的特定场景下,Bitmap无法[直接]做非运算。为什么呢?看看下面的例子:
我们以下面的用户数据为例,用户基本信息如下。按照年龄标签,可以划分成90后、00后两个Bitmap:
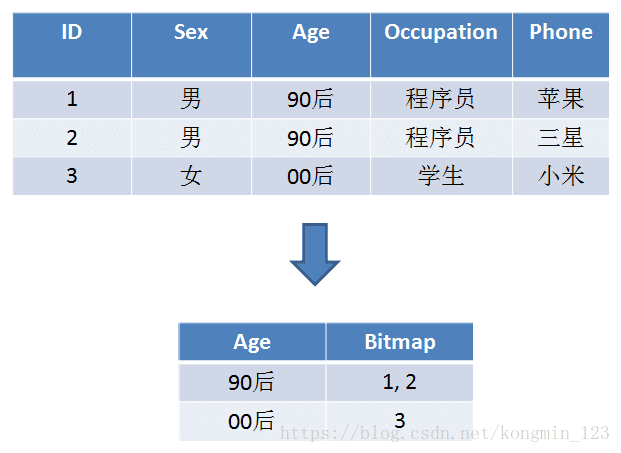
用更加形象的表示,90后用户的Bitmap如下:
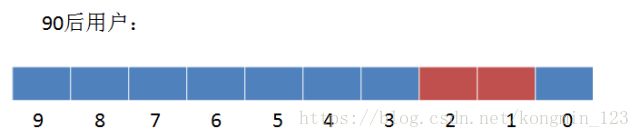
这时候可以直接求得非90后的用户吗?直接进行非运算?
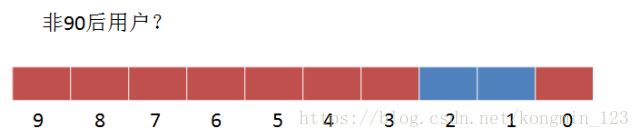
显然,非90后用户实际上只有1个,而不是图中得到的8个结果,所以不能直接进行非运算。
那如果我们一定要求出不属于某个标签的用户数量,该怎么做呢?
这个时候就需要借助一个全量的Bitmap。
同样是刚才的例子,我们给定90后用户的Bitmap,再给定一个全量用户的Bitmap。最终要求出的是存在于全量用户,但又不存在于90后用户的部分。
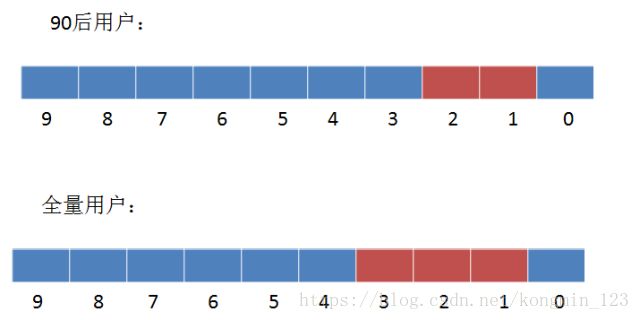
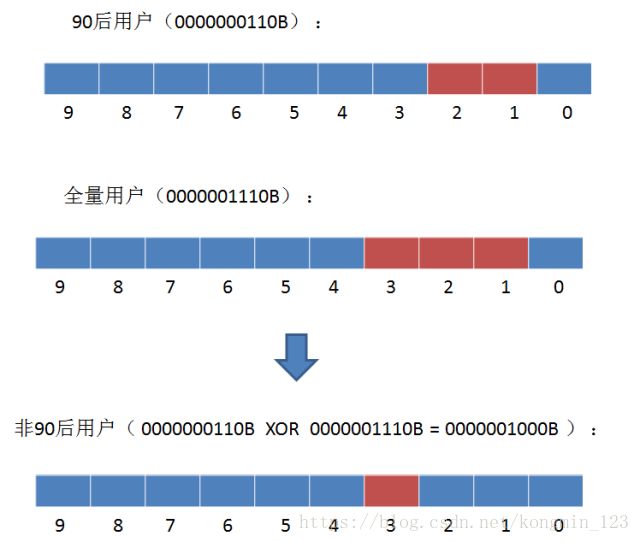
如何求出呢?我们可以使用异或操作,即相同位为0,不同位为1。
Bitmap虽然使用方便,但是如果在一个很长的Bitmap里只存有一两个用户,就会很浪费空间。
针对这个问题,在谷歌所实现的EWAHCompressedBitmap中,对Bitmap存储空间做了一定的优化。
EWAH把Bitmap存储于long数组当中。long数组的每一个元素都可以当做是64位的二进制数,也是整个Bitmap的子集。谷歌把这些子集叫做[Word]。

当创建一个空的Bitmap时,初始只有4个Word,也即long数组的长度是4。随着数据的不断插入,Word数量会随之扩充。
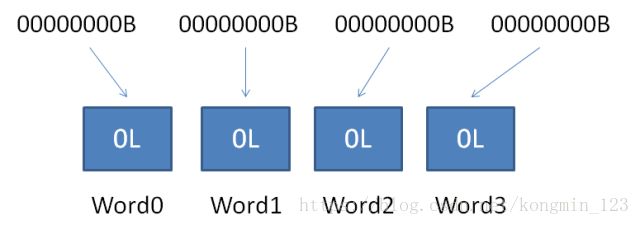
初始情况由于还未插入任何数据,此时所有的Word值都是0。
EWAH有些Word存储实际数据,有些Word存储数据和数据之间的间隔个数,当节点之间跨度很大时,Bitmap不会傻傻把长度扩充到Bitmap的最高位那么多,他会由一个节点专门存储两个节点之间的跨度信息,以此达到节省空间的目的。在插入新的数据的时候,如果数据不存放在已有的Word当中,EWAH还会进行动态扩充或对存储跨度的节点进行分裂。
关于EWAH实现原理的更多信息,可以参考EWAH的算法论文:《Sorting improves word-aligned bitmap indexes》。
EWAHCompressedBitmap对应的maven依赖如下:
com.googlecode.javaewah
JavaEWAH
1.1.0
关于Bitmap的基础知识就简单介绍到这里啦。
参考:程序员小灰—《Bitmap算法 整合版》