论文阅读(2)--Picking Deep Filter Responses for Fine-grained Image Recognition
这次阅读的文章是Picking Deep Filter Responses for Fine-grained Image Recognition,这篇文章是来自上海交通大学Xiaopeng Zhang等人的工作,该文章提出了一种对深度网络中的filter进行挑选的方法,基于挑选的filter的结果构建复杂特征表达。
0. 摘要
识别精细类别的子类别比较困难的原因是其在一些特别的部位上有比较高的局部和细微的不同。(due to the highly localized and subtle differences in some specific parts)
本文提出一种基于挑选深度filter response的两个步骤的框架。步骤流程如下图所示:
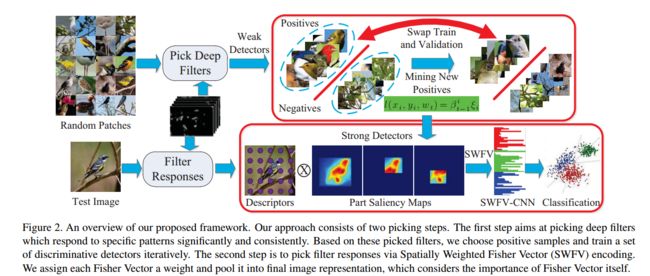
第一步是找出对于特别的部位(specific patterns)比较重要的较敏感的filters,然后通过选择的新的正样本和再训练的部件模型中交替迭代来学习一组部件检测器(a set of part detectors)。
第二步则是通过Spatially Weighted Fisher Vector(SWFV)编码来选择 filter response,这里根据Fisher Vector本身的重要性来给每个Fisher Vector分配一个权重,并将其合并到最终的图片表示中(pool it into final image representation)。
1. 介绍
目前大多数精细分类都需要在训练阶段或者测试阶段需要有物体或者部件的标注,在一些比较新的工作则只需要在训练阶段需要,但是对于大规模的数据库,标注是一个非常耗费时间和精力的事情,同时在实际应用中也需要用户手工标注,因此能够自动发现部件就可以摆脱进行标注这项工作,但是自动发现标注是一个经典的先有鸡还是先有蛋的问题——发现一个部件例子需要有一个准确的外观模型,但是没有部件例子就不能学习到一个好的准确的外观模型。(without an accurate appearance model, examples of a part cannot be discovered, and an accurate appearance model cannot be learned without having part examples.)
本文的第一个贡献是为精细图像识别提出了一个自动部件检测的方法。首先是基于深度 filters的选择性,提出一个新的用于学习检测器的初始化方法。这个方法学习到的检测器都是比较弱的,甚至大部分的检测器都与我们的任务无关,但是这个方法的关键是精心选择具有重要和始终如一的响应的深度 filters。其次,通过迭代选择每类的正样本和再训练正则化的部件模型来学习一组检测器。使用正则化是考虑到正类样本的多样性和可靠性。
第二个贡献是提出了一种非常适合精细图像表示的特征,也就是将CNN的深度 filter responses作为局部的描述符,然后使用SWFV方法来对其进行编码。这个做法是可以更强调对识别有关键作用的响应,以及丢弃掉没有用的响应。
接下来是对论文提出的两个步骤的具体介绍,分别是指学习部件检测器以及使用SWFV编码得到图像表示进行分类两个步骤。
2. 学习部件检测器(Learning Part Detectors)
对于部件检测器的学习方法,分3个步骤,分别是正样本初始化,正则化检测器的训练以及检测器的挑选(positive sample initialization, regularized detector training,and detector selection)。整个过程是一个弱监督的过程,只需要训练样本的标签,不需要任何物体或者部件级别的标注。
选择 Filters:正样本初始化
利用CNN的不同层的滤波器是对特定部件敏感的,比如底层的滤波器主要是对角落以及一些边缘连接,而高层则是对有更有语义意义的区域敏感。当然,这些滤波器作为检测器来说是比较弱的。
首先是利用选择性搜索(selective search)生成一个大量的区域建议(generate a large pool of region proposals),以及随机采样的一个100万个patches的子集。每个proposal调整成大小是107*107。然后,对所有channels中的响应(应该就是指特征图,feature map)进行排序,并选出排在前面1万个响应,最后会得到得分排在前1万区域的响应分布。这个分布是稀疏的,论文在一个鸟类数据库上做的分布显示前面5%的channels包含超过90%的响应。
分布如下图所示:
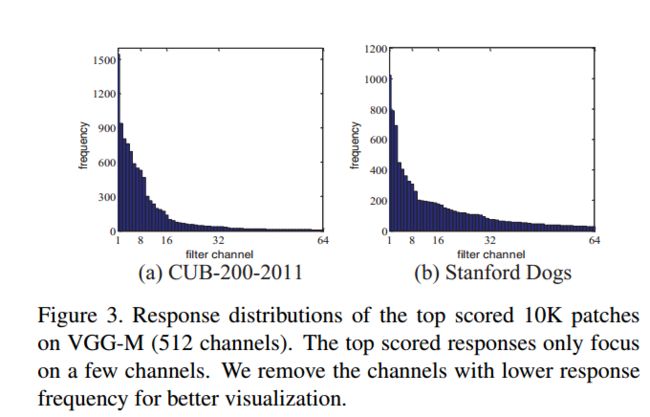
这里,作者将这些channels称为有区分性的滤波器(We refer to these channels as distinctive filters),下图展示了在鸟类数据集上所挑选到的有区分性和没有区分性的滤波器结果。

对这些选择出来的滤波器,挑选具有排在前m(论文中m=100)个响应的patches作为对应的部件模型的初始正样本。
正则化检测器训练
选择好初始的正样本后,通过优化一个线性SVM分类器来学习对应的检测器。
由于初始的正样本并不是很好开始(如下图所示,有些样本中没有准确定位部件的位置),所以这里训练SVM检测器是需要进行迭代。

每次迭代,在前一轮迭代中排在前10%的检测器都会作为新的正样本。但是直接使用这个方法并不能有多大提高,因为学习到的检测器容易对初始的正样本过拟合,为了解决这个问题,论文是选择将训练集均分成2个没有重叠的子集,一个作为训练集,另一个作为验证集,并且在迭代过程中重复交换作为训练集和验证集的子集,直到收敛为止。
训练物体/部件检测器的另一个问题就是最好的检测器总是会锁定几个容易检测的子类,而不能从大部分其他子类中发现到这些子类的正样本。
为了解决这个问题,论文提出了一个在每轮训练中对每类的正样本使用正则化的损失函数。
以上步骤如下列算法步骤所示

检测器的选择
论文提到上述算法最后会得到数十个检测器,这里需要进一步挑选,通过这些检测器的识别准确率进行挑选,最后剔除识别率低于40%的检测器,最终得到的检测器会比较少,论文中的实验是得到少于10个。
3. Bag of Parts Image Representation
在得到上述训练好的检测器后,就可以从每种图片中检测到对应的部件。
一个直接的可以得到部件表示的方法就是直接使用从这些检测器检测到的部件中提取CNN的特征,这里主要是使用CNN的倒数第二个全连接层的特征,并且之前大部分工作都是如此做法。这种做法有两个限制,一是背景的干扰,二是来自检测的不准确性,可能会丢失关键的细节。
论文提出的新的方法是计算部件显著性图和将CNN特征和SWFV合并在一起(we propose to compute part saliency map and pool CNN features with Spatially Weighted Fisher Vector(SWFV-CNN))。
4. 小结
文章中报告的结果表明,利用该方法在CUB-200-2011和Stanford Dogs两个数据集上都取得了较优异的成果。值得一提的是,该方法并未利用人工标注信息(bbox+parts),在测试集上相比于利用标注信息的方法有了显著提高。该方法并非采用End-to-End的结构,在中间的环节如Spatial weighting, FV pooling需要针对数据分布的不同而做细致调整。
大概简单看完,论文的想法是挺好的,通过自动检测部件来避免工作量非常大的人工标注,由于深度学习,特别是CNN的强大,现在对数据库的规模都是抱着越大越好,如果需要对图片都进行人工标注,这真是一件非常痛苦的事情。
不过感觉论文中的关键应该就是第一步中的选择滤波器了,如何挑选到真正有用的滤波器作为用于检测部件的detector就是非常重要,论文的做法似乎是对CNN中的所有特征图进行一个排序,首先是分不同channel,然后根据出现的频率做一个分布,这些channel就被作为是有区分性的detector,并根据这个来选择初始的正样本。接着用这些正样本来进行挑选检测器,使用SVM分类器来进行迭代训练,并加入正则化来增加多样性和可靠性。
不过对于具体的实现细节还是不太清楚,需要再多读几遍。