TensorFlow Object Detection API
TensorFlow Object Detection API
这个API的目的是创建一个能够在单个图像中定位和识别多个对象的精确机器学习模型。该API是在tensorflow上构造的开源框架,易于构建、训练和部署目标检测模型。
条件
Window7
Anaconda3 安装
这里Anaconda下载安装就好。
安装完以后,打开Anaconda Prompt,输入清华的仓库镜像,更新包更快:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes推荐第一行命令输入两次,以便把这个镜像地址放在首位。
- 安装TensorFlow
继续打开Anaconda Prompt,输入:
conda create -n tensorflow python=3.6 来创建python的环境。
继续在Anaconda Prompt输入:
activate tensorflow激活环境,然后输入命令
pip install tensorflow - PyCharm配置
要在pycharm下使用tensorflow,要设置好pycharm下解释器interpreter的路径,这里也就是tensorflow的路径。
如果是虚拟的env,或anaconda的env,那就在interpreter路径里添加对应Python。
如果当前路径里没有解释器没有这个,就点击右侧add local在电脑里找。
anaconda3—>envs—>tensorflow—->python2.7(或者Python3.5,用哪个选哪个)
安装Object Detection API
- 打开Anaconda Prompt
activate tensorflow

- 安装pillow, jupyter, matplotlib, lxml,通过conda install XXX 完成安装
- 下载tensorflow/models: https://github.com/tensorflow/models.git
- 下载Protobuf,在链接https://github.com/google/protobuf/releases 中找到合适的版本下载,解压后将bin文件夹中的“protoc.exe”放到C:\Windows,或者添加环境变量。调用cmd,输入protoc发现提示missing input file,证明已经可以使用了。
- 编译Protobuf文件:路径转到-> \models\research\object_detection, 输入:protoc *.proto –python_out=.
不报错即可。
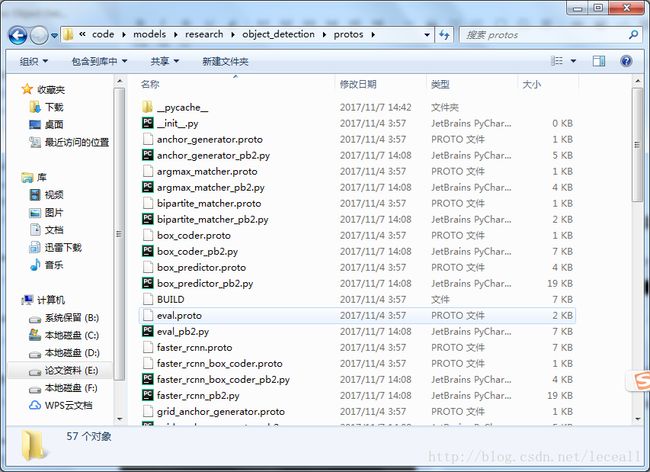
可以看到object_detection/protos/目录下的所有*.proto都生成了对应的py文件。
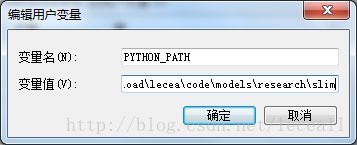
- 添加环境变量PYTHONPATH
两个:
-> \models\research
-> \models\research\slim
测试Object Detection API
用PyCharm直接运行
在->models\research\object_detection文件夹下新建 ‘object_detection_tutorial.py’,内容如下,直接运行即可。
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
## This is needed to display the images.
#%matplotlib inline
# This is needed since the notebook is stored in the object_detection folder.
sys.path.append("..")
from utils import label_map_util
from utils import visualization_utils as vis_util
# What model to download.
MODEL_NAME = 'ssd_mobilenet_v1_coco_11_06_2017'
MODEL_FILE = MODEL_NAME + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb'
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt')
NUM_CLASSES = 90
#download model
opener = urllib.request.URLopener()
#下载模型,如果已经下载好了下面这句代码可以注释掉
opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
tar_file = tarfile.open(MODEL_FILE)
for file in tar_file.getmembers():
file_name = os.path.basename(file.name)
if 'frozen_inference_graph.pb' in file_name:
tar_file.extract(file, os.getcwd())
#Load a (frozen) Tensorflow model into memory.
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
#Loading label map
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
#Helper code
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
# For the sake of simplicity we will use only 2 images:
# image1.jpg
# image2.jpg
# If you want to test the code with your images, just add path to the images to the TEST_IMAGE_PATHS.
PATH_TO_TEST_IMAGES_DIR = 'test_images'
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 3) ]
# Size, in inches, of the output images.
IMAGE_SIZE = (12, 8)
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
# Definite input and output Tensors for detection_graph
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
detection_boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
detection_scores = detection_graph.get_tensor_by_name('detection_scores:0')
detection_classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = load_image_into_numpy_array(image)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
scores = detection_graph.get_tensor_by_name('detection_scores:0')
classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# Actual detection.
(boxes, scores, classes, num_detections) = sess.run(
[boxes, scores, classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8)
plt.figure(figsize=IMAGE_SIZE)
plt.imshow(image_np)
plt.show()检测结果:


借助jupyter-notebook
前提:
activate tensorflow
conda install ipython
conda install jupyter
转到路径->\models\research 运行
jupyter notebook
跳转到了页面:

选择object_detection文件夹,可见Object Detection Demo
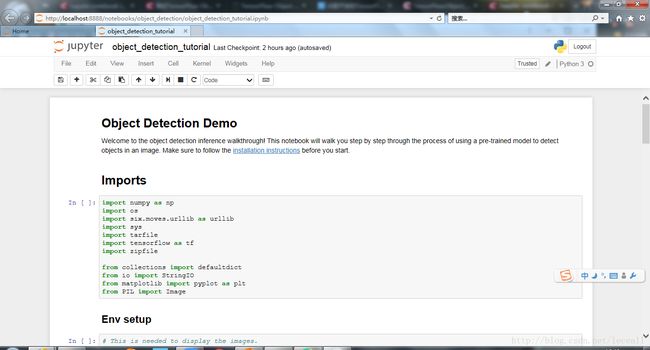
依次按红圈圈的按钮,直到最后。

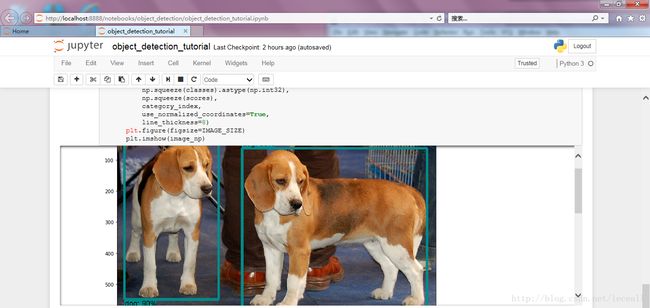
直接运行到最后,两个demo图片,分别是两只狗和海边的风筝,检测结果:
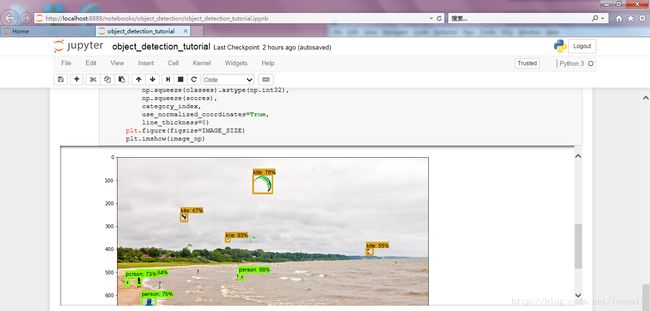
改变测试图片
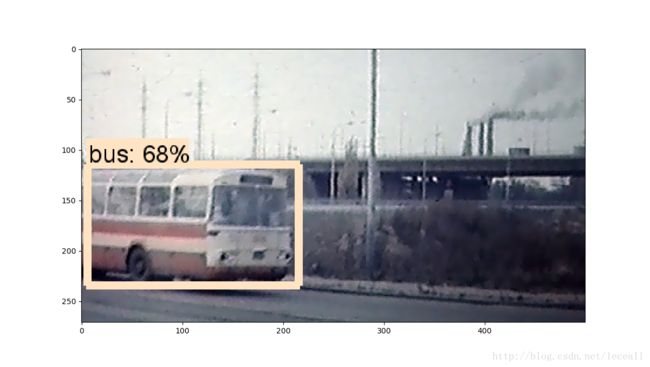
可以自己修改需要检测的图片,修改PATH_TO_TEST_IMAGES_DIR图片路径,或者更改TEST_IMAGE_PATHS为自己的图片路径就可以了。这里我随便选了几张图片,检测结果:

改变模型做检测
公布的模型主要有6个,是在COCO上训练的网络。网络结构分别是SSD+MobileNet、SSD+Inception、R-FCN+ResNet101、Faster RCNN+ResNet101、Faster RCNN+Inception_ResNet和Faster RCNN+NAS。
如何使用其他模型呢?
找到Tensorflow detection model zoo(地址:detection_model_zoo),根据里面模型的下载地址,我们只要分别把MODEL_NAME修改为以下的值,就可以下载并执行对应的模型了:
# What model to download.
MODEL_NAME = 'ssd_mobilenet_v1_coco_11_06_2017'
MODEL_NAME = 'ssd_inception_v2_coco_11_06_2017'
MODEL_NAME = 'rfcn_resnet101_coco_11_06_2017'
MODEL_NAME = 'faster_rcnn_resnet101_coco_11_06_2017'
MODEL_NAME = 'faster_rcnn_inception_resnet_v2_atrous_coco_11_06_2017'
MODEL_NAME = 'faster_rcnn_nas_coco_24_10_2017'
结果对比:
SSD+Mobile:

SSD+Inception:

RFCN+Resnet:

Faster+RCNN+Resnet:

Faster+RCNN++Inception+Resnet:

(PS:以前没有接触过jupyter notebook,感觉很方便的样子,以后要学一下)
专家说明
作者:何之源
链接:https://www.zhihu.com/question/61173908/answer/185074029
来源:知乎
熟悉TensorFlow的人都知道,tf在Github上的主页是:tensorflow,然后这个主页下又有两个比较重要的repo(看star数就知道了),分别是TensorFlow的源代码repo:tensorflow/tensorflow,还有一个tensorflow/models。后者tensorflow/models是Google官方用TensorFlow做的各种各样的模型,相当于示例代码,比如用于图像分类的Slim,深度文字OCR,以及用于NLP任务的句法分析模型syntaxnet,Seq2Seq with Attention等等等等。这次公布的Object Detection API同样是放在了tensorflow/models里。
再来说下这次公布的代码的实现方式。首先,对于目标检测这个任务来说,前面必须有一个像样的ImageNet图像分类模型来充当所谓的特征提取(Feature Extraction)层,比如VGG16、ResNet等网络结构。TensorFlow官方实现这些网络结构的项目是TensorFlow Slim,而这次公布的Object Detection API正是基于Slim的。Slim这个库公布的时间较早,不仅收录了AlexNet、VGG16、VGG19、Inception、ResNet这些比较经典的耳熟能详的卷积网络模型,还有Google自己搞的Inception-Resnet,MobileNet等。
我们在TensorFlow Object Detection API的官方安装指南(地址:tensorflow/models)中,可以看到这样一句代码:
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim很显然,这就是钦点用Slim作特征抽取了。另外,以Faster RCNN为例,之前在github上,可以找到各种各样非官方的TensorFlow实现,但是这些实现使用的特征抽取层都不是Slim,而是五花八门的什么都有,另外一方面实现代码大量copy自原始的caffe的实现:rbgirshick/py-faster-rcnn,这次公布的代码里已经一点也找不到原始caffe实现的痕迹了。最后,原来非官方的Object Detection实现的质量参差不齐,去年我调过一个Faster RCNN,过程比较痛苦,在运行之前疯狂debug了三天才勉强跑了起来。这次Google官方公布的Object Detection API别的不说,代码质量肯定是过的去的,因此以后应该不会有人再造TensorFlow下Faster RCNN、R-FCN、SSD的轮子了。
关注微信公众号:paper大讲堂(paperclasssroom)获取更多教程和资源。
