源代码阅读方法(附Go语言项目的代码阅读技巧)
公众号首发:https://mp.weixin.qq.com/s/qzsn-hKkEdTX8pDqDVuI_g
目录
-
目录
-
说明
-
一:摆正认识
-
二:找到入口
-
三:梳理目录
-
四:逐行阅读
-
Go项目的一些阅读技巧
-
技巧1:忽视真正入口之前的代码
-
技巧2:接口的实现一般就在接口定义的下方
-
技巧3:见到了类似于「类」的结构,要感动地想哭
-
技巧4:发现套路(代码框架)
说明
之前在阅读代码方面存在认知误区,一开始就从入口开始阅读,并不停地跳转,试图理清每一个细节。这种方式会让阅读代码的过程比较煎熬,耗费时间长效果却不好,不是正确的做法。正确的做法是先看森林再观树木,即先对整个项目的代码结构有基本认知,摸清项目代码的实现套路,然后按需逐行阅读。
一:摆正认识
摆正认识,对阅读代码这件事有正确的认识很重要,核心思想指导行动,方法构建在核心思想之上,如果核心思想不正确,方法就不可靠。核心思想用比较现代的语言表述就是:元认知。
我们要阅读的代码不是一堆杂乱文件和字符,而是经过深思熟虑、精心安排好的,是有内在规律的,越是庞大成熟、被广泛使用的项目越是如此,这一认识是后续方法的基本盘:
-
要相信有几十年发展历史的软件工程是有料的,我们现在能看到重要项目不会是杂乱无序的;
-
要相信前辈大牛们创造的各种编程技术是在降低编码阅读难度的;
-
要相信重要开源项目的核心开发人员的水平是很高的,他们在方法论方面的认识和水准超过绝大多数人;
-
要相信技术水平高的人是喜欢制定并遵循套路的,这些套路会让工作更简单,阅读开发代码的过程更轻松。
在初次阅读代码的时候,首要目标就是找到「套路」,并时刻保持清醒,避免过早陷入细节而忘记了首要目标。
二:找到入口
万事开头难,刚刚开始接触一个全新的陌生项目时,是最难受的,因为一无所知。这时候如果自己能够把代码编译成可执行的文件,并知道了程序的入口位置,内心的焦躁就会大幅减少,因为剩下的就是时间问题了。
除非是构建过程特别复杂的项目,否则一定要自己编译一遍,并阅读 makefile 或者编译脚本,大概了解作者维护这套代码的方式。大部分开源项目都会在 README.md、Install 等文档中详细介绍编译、部署的方法,通常是2~3个命令,无脑执行即可,但有时候会遇到比较烦恼的挫折。
第一个常见挫折是因为国内特殊的网络环境,一些需要从网上获取的资源被卡住,导致构建不通过,这个挫折除了找一个全局代理的「维劈N」似乎没有其它的破解方法了。
第二个常见挫折是有些项目的构建过程本身就很复杂,并且大量运用 makefile 和 shell 的特性,为寻找程序入口增加了重重障碍。这个挫折除了硬着头皮去看或者直接找人问,似乎也没有其它破解方法了。
另外现在比较流行用 docker 做环境编译,这种方式使构建环境统一带来不少益处,但对于要掌握构建过程的人来说,在 makefile 和 shell 之外又需要掌握一套工具,对于完全不了解 docker,特别是对一些经验尚浅的在校生来说,是个不小的障碍。
有些项目还用到了其它比较小众的构建工具…没有什么好办法,多看多学,见多了就熟了!
三:梳理目录
找到程序入口之后,不用着急从入口阅读代码,先把所有的目录看一下,大概了解目录的层次结构和用途,这样会事半功倍。如果没有搞清楚目录结构,就从入口开始阅读代码,每次跳转都进入一个完全陌生的目录或文件中,连续跳转几次就完全陷入到具体目录中,找不回主线了。
在梳理目录的时候,如果目录下有说明文件一定要仔细阅读,然后快速扫视目录中每个文件的内容。文件开头的注释要认真看,文件中比较复杂的结构体、类、函数或方法列表等要关注,通过快速扫视对每个目录的用途有一个大概的判断。
这个阶段酌情了解一下函数或者方法的实现即可,一般情况下只要看一下函数或方法的名字,就能大概猜到这个目录中代码的用途。
即使完全判断不出某个目录的用途也不要紧,提前扫视一遍至少眼熟,在后面逐行阅读代码时,没准就串联起来并瞬间想通了。随着了解的目录越来越多,对整个项目的代码结构的认识越来越清晰,最终完成了从0到1的认知构建。
认知构建的过程是比较不愉快的,因为要在完全陌生的内容里折腾,贵在坚持,「眼熟」了,就顺畅了,最后如鱼得水、酣畅淋漓。有一个技巧可以应用,扫视的时候在心里不停地问,这段代码是在干嘛?逼迫自己从更高的维度去看和想,而不是只见树木不见森林的陷入到细节中。
四:逐行阅读
对项目的目录结构有了基本认知之后,接下来就是最后一步:从程序入口开始逐行阅读。
这期间经常遇到没见过的函数或者代码库,还有一些设计模式相关的代码。老外写代码特别喜欢用 factory、helper 等等,各种传递各种类型转换,还有各种自动生成的代码,往往要向下穿透好几层才能找到熟悉的直白执行的代码。
第一个应对方法很简单:见得多了,就熟悉了;第二个应对方法是:掌握好阅读的深度。
如果不是特殊需要,遇到一个陌生的库只需要知道它是什么、能用来做什么怎么用,至于是怎么实现的可以先不关心。要把时间和精力用在主线上,别一头扎入某个库的细节,忘了当前项目的主线,变成研究另一个项目了。
特别是一些使用了框架的项目,先知道框架怎么用,把当前项目搞清楚后,再去研究框架自身是怎么实现的。
掌握好阅读深度非常关键,因为代码浩如烟海,是读不完的,只依赖标准库的项目还好一些,否则 A 引 B、B 引 C,最终代码量成指数型增加。要善于抽象总结,逐行读代码,不是逐行看字母abcd,而是揣摩这些代码表达的意思,透过代码把握作者的思路想法。
有时候代码实在太复杂了,那就有选择的阅读,譬如看到一整屏的初始化代码,如果去追究每个初始化是在干嘛的,等折腾明白了,黄花菜都凉了。我们先知道这里是在做初始化就好了,然后继续往下,等遇到困难或者有需要的时候,再回过头来研究相关的初始化代码。
Go项目的一些阅读技巧
平常阅读 Go 开发的项目代码多一些,因此只总结了几个还算实用的 Go 代码阅读技巧。
技巧1:忽视真正入口之前的代码
最开始找到的 main 函数常常不是我们想要的入口函数,例如正在阅读 gloo 的代码,语法意义上的 main 函数是:

image
但真正要阅读的程序执行入口是 SetupFunc 中的 RunGloo,直接从 RunGloo 开始阅读,前面的可以暂时不关心:

image
直接从 RunGloo 开始阅读,前面的可以暂时不关心。
Kubelet 的代码更过分了,app.NewKubeletCommand()->Run()->run()->RunKubelet()->startKubelet()->k.Run(),整整经过六次跳转,穿越了上千行初始化代码后,才知道真正的入口是 pkg/kubelet/kubelet.go 中的 Run():
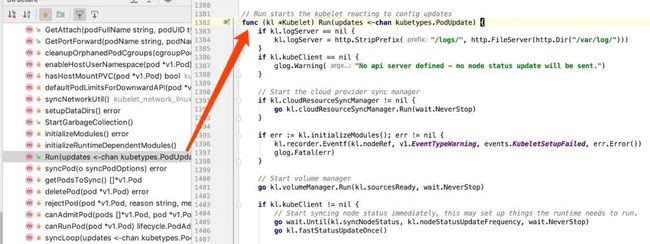
image
技巧2:接口的实现一般就在接口定义的下方
逐行阅读 Go 代码的时候,经常遇到一个尴尬,要看一个函数的具体实现的时候,跳转过去,发现是接口中的方法,或者要看个变量的类型的定义,跳转过去发现是个接口:

image
这时候通常只能不断地回退,直到找到创建变量的代码,才知道这个变量的实际类型,进而找到接口方法的实现。当前的变量常常经过了多次传递、赋值,等找到最开始创建的地方,也差不多晕了,下次看代码再次到这个位置的时候,一般早就忘了这个变量是咋回事了,又要重新找。
后来发现一个近乎「约定俗成」的规律,接口定义和接口的实现通常在同一个文件中,一般至少有一个默认实现,最常用的也是这个默认实现。因此找到了接口定义,也就找到了接口的实现:

image
这个很常见的做法不是语法上的约束,只是一种自律。不是所有的接口都只有一个实现,但为了不给自己添麻烦,绝大多数人一定是把接口的实现和定义放在邻近位置,譬如同一个目录下。
下图是 plugin 的接口定义和诸多实现(每个实现是一个子目录):

image
掌握了这个技巧,代码读起来就畅快多了,而且会充分享受到接口的好处。接口比具体实现高一个维度,通过查看一两个实现代码,明白了接口的用途,以后再看到接口方法,反而不执着于寻找接口的实现了。
技巧3:见到了类似于「类」的结构,要感动地想哭
接口、类、类似于类的结构都是我们好朋友,因为类的代码是高度内聚的,在当前文件中就能搞清楚这个类是干嘛的,能做些什么。还是以 kubelet 的代码为例,当发现真正的入口是 struct Kubelet 的 Run() 时,看到的是下面的景象:

image
上面红色箭头所指的函数都在 Kubelet 中,以后要查看 kubelet 某块功能的具体实现时,直奔 Kubelet 找对应的方法,直奔主题!只需要要记住有这么一个「类」,就再也不用从 main 开始一步又一步的寻找了!
技巧4:发现套路(代码框架)
以 kubernetes 的 kube-apiserver 代码为例,要找到它处理 http 请求的 handler 是相当费劲的!从两年前一知半解时写的笔记《Kubernetes 的 Apiserver 的工作过程》中可以感受到。
发现了套路后会豁然开朗,找到某个接口的处理逻辑非常简单:全都在 pkg/registry 目录中,每类资源占一个目录,每个目录的结构和文件内容都是高度相似。创建前、更新前以及其它阶段的处理代码都在这里:

image
这个公众号不错,关注后加微信

image
华为的5G代码被英国喷了:太复杂,看不懂
公众号首发:https://mp.weixin.qq.com/s/qzsn-hKkEdTX8pDqDVuI_g