Python实现《谁说菜鸟不会数据分析(入门篇)》的案例
这段时间在学习Excel和Python相关内容,Excel数据分析入门有一本《谁说菜鸟不会数据分析(入门篇)》,内容细致,简洁易懂,注重培养分析的思维而不仅仅是告知方法。在学习Python过程中萌发了通过使用Python的方式实现《谁说菜鸟不会数据分析(入门篇)》中对Excel文件的处理的想法,借此提高对Python数据分析的使用,理解数据处理的方式。因为才刚开始接触学习Python和Excel,可能Python有些问题处理方式过于繁琐,不够简洁,只是进行一下尝试。
1. 重复数据处理
有时候数据中会出现重复行,干扰数据分析,这就需要对重复数据进行处理。
剔除数据中重复数据,在DataFrame中主要运用duplicated方法和drop_duplicates方法:
- duplicated方法返回的是一个布尔型的Series,用来只是各行是否重复,如果重复则为True,否则为False。
- drop_duplicates直接返回已经删除了重复行的DataFrame。
默认drop_duplicates方法会判断所有列,只有所有列的值都重复才算重复行,如果仅需要依据某一列或者某几列进行重复项判断。可以添加列名的列表:drop_duplicates([‘K1’])或者drop_duplicates([‘K1’,’K2’])。删除的重复值可以选择保留第一项还是最后一项,添加 keep = ‘last’,会保留最后一个重复值,keep = ‘first’会保留第一个重复值。
Excel文件读取
pandas的ExcelFile类或pandas.read_excel函数支持读取存储在Excel 2003(或更高版本)中的表格型数据。这两个工具分别使用扩展包xlrd和openpyxl读取XLS和XLSX文件。你可以用pip或conda安装它们。
要使用ExcelFile,通过传递xls或xlsx路径创建一个实例,然后用存储在表单中的数据可以read_excel读取到DataFrame
import pandas as pdxlsx = pd.ExcelFile('E:/Docs/Python/excel_data/ch04/4.2/重复数据处理.xls')
# 这里路径要用'/',否则使用右斜杠'\'会报OSError Invalid argument错误
frame = pd.read_excel(xlsx,'Sheet1')如果要读取一个文件中的多个表单,创建ExcelFile会更快,但你也可以将文件名传递到pandas.read_excel:
frame1 = pd.read_excel('E:/Docs/Python/excel_data/ch04/4.2/重复数据处理.xls','Sheet1')
frame1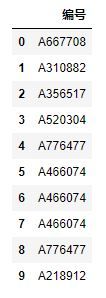
重复数据处理
使用DataFrame的drop_duplicates()进行重复数据的删除
frame_ = frame.drop_duplicates(keep = 'last')
# keep = 'last',会保留最后一个重复值,keep = 'first'会保留第一个重复值
frame_
处理数据另存为Excel文件
如果要将pandas数据写入为Excel格式,你必须首先创建一个ExcelWriter,然后使用pandas对象的to_excel方法将
数据写入到其中:
writer = pd.ExcelWriter('E:/Docs/Python/excel_data/ch04/4.2/重复数据处理_处理后.xls')
frame_.to_excel(writer,'Sheet1')
writer.save()你还可以不使用ExcelWriter,而是传递文件的路径到to_excel:
frame_.to_excel('E:/Docs/Python/excel_data/ch04/4.2/重复数据处理_处理后.xls')2. 检查数据逻辑错误
逻辑错误是根据数据来源、数据性质等进行判断的,比如年龄出现负值等等。
这里的例子是在多选题中需要选择3项,为0代表未选择,不为0代表选择,所以需要判断每一行数据中不为0的个数是否等于3.
因为原先的xls文件有合并单元格,首先手动将其删除,只留下标题列ABCDEFG和表内容。
frame2 = pd.read_excel('E:/Docs/Python/excel_data/ch04/4.2/检查数据逻辑错误.xls','Sheet1')frame2_ = frame2.copy()
frame2_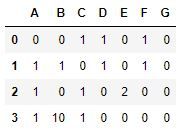
DataFrame的loc和iloc方法可以选中行进行计算判断,loc和iloc分别通过索引和整数索引进行选择,ABCDEFG7道题中只能选择3项,用不等于0的值是否是3来短判断,多或者少都是错误的。
# for循环记得for、if、else语句后面都有:
for i in range(len(frame2_)):
if (frame2_.loc[i] != 0).sum() == 3:
frame2_.loc[i,'检验'] ='正确'
else:
frame2_.loc[i,'检验'] ='错误'
frame2_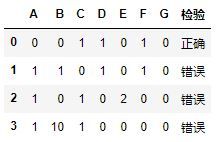
3. 字段分列(带分隔符)
在数据源数据中,有时根据需要,需要从某一列数据中提取信息(比如从身份证号中提取出生年月信息)或者对数据进行分割(比如类似2011-01-05的日期,提取年月日信息单独成列)。根据数据的不同分为两种情况,利用字符串的分隔提取方法解决:
1. 需要分列的信息之间有特殊的分隔符,比如逗号、空格等,可以直接用split方法分割;
2. 没有特殊分隔符时,采用对字符串的索引方式,如 对x = ‘spam’;可以使用x[0],x[-1],x[1:3]等进行信息提取
本例是针对英文名进行分割,中间有空格作为分隔符
excel文件比较随意,只添加了数据内容,没有列名,先手动添加列名 name
frame3 = pd.read_excel('E:/Docs/Python/excel_data/ch04/4.3/字段分列.xls','Sheet1')
frame3
首先提取需要分列的列,用split()分列,这里的分隔符是空格
frame3_ = pd.DataFrame((x.split(' ') for x in frame3.name),index=frame3.index,columns=['A','B'])
frame3_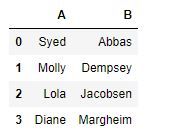
4. 字段分列(无特定分隔符)
frame4 = pd.read_excel('E:/Docs/Python/excel_data/ch04/4.3/数据抽取.xls','Sheet1')
frame4
字段本质上为字符串,固定的位置可以直接用索引直接选取
frame4['姓'] = pd.Series((x[0]) for x in frame4['姓名'])
frame4
5. 字段匹配
在excel中,vlookup是字段匹配搜索的神器,加上INDEX和MATCH函数几乎所向披靡。在DataFrame中,merge是合并两个DataFrame的方法,可以利用on = ‘列名’选择该列进行匹配,还可以选择选择交集、并集、左合并、右合并,功能十分强大
在本例中,员工职位表中有员工的姓名、工号、职务等信息,而在员工个人信息表中缺少职务信息,需要从员工职位表中将职务信息对应添加到员工个人信息表中。选择工号列进行匹配。
frame51 = pd.read_excel('E:/Docs/Python/excel_data/ch04/4.3//字符匹配/员工职位表.xlsx','Sheet1')
frame51
frame52 = pd.read_excel('E:/Docs/Python/excel_data/ch04/4.3//字符匹配/员工个人信息表(销售部).xlsx','Sheet1')
frame52
需要从《员工职位表》中提取‘职务’信息到《员工个人信息表》中,这相当于两个DataFrame合并,连接键为‘工号’,需要的字段为职务
pd.merge(frame52,frame51[['工号','职务']],on = '工号')
6. 简单计算
本质上相当于在DataFrame添加一列,该列由前面列的数据生成,直接两列相乘即可
本例中是计算销售额(运用公式:销售额 = 销售数量 * 单价)
frame6 = pd.read_excel('E:/Docs/Python/excel_data/ch04/4.3//简单计算.xls','Sheet1')
frame6
frame6['销售额'] = frame6['销售数量']* frame6['单价']
frame6
# 这里销售额已经计算完毕,因为看到表格中还有合计项,顺便联系一下iloc的用法
frame6.iloc[5,1:] = frame6.iloc[0:5,1:].sum()
frame6
7. 函数计算
计算平均值和总和直接使用mean和sum函数,因为是计算每行的值,需要设置axis=1。
frame7 = pd.read_excel('E:/Docs/Python/excel_data/ch04/4.3//函数计算.xls','Sheet1')
frame7
frame7['季度平均'] = frame7[['一季度','二季度','三季度','四季度']].mean(axis = 1)
frame7['总销售量'] = frame7[['一季度','二季度','三季度','四季度']].sum(axis = 1)
frame7
文中所涉及的excel数据文件和Jupyter的ipynb文件放在:
https://pan.baidu.com/s/1_ZfhpUTRoFEEglbqF7AhZA 密码:586r
《谁说菜鸟不会数据分析(入门篇)》的图书需要自己解决。