mysql索引优化
- 十分地简单认识下与索引有关的数据结构
- 二叉查找树
- 平衡二叉树
- B+树
B+树索引
- 聚集索引
- 非聚集索引
- InnoDB B+树索引
- MyISAM B+树索引
- Cardinality
- InnoDB与MyISAM中Cardinality值的统计
- 优化器不使用索引及优化
索引的类型
- 普通索引
- 唯一索引
- 主键索引
- 联合索引
- 覆盖索引
- 全文索引
- 创建索引的几大原则
- 简单例子体验下联合索引
1.十分简单地认识下与索引有关的数据结构:
树的简单概念:由n个节点组成具有层次关系的集合,根朝上叶朝下
树的特点:每个节点有0或多个子节点,无父节点称为根节点,每个非根节点有且只有一个父节点,每个节点可分为多个不相交的子树(父节点除外)
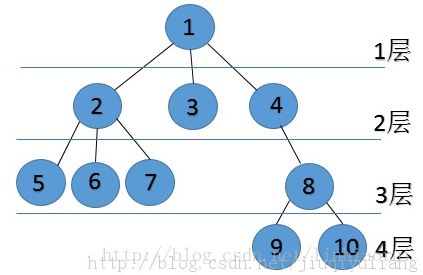
二叉树的简单概念:每个节点最多有2个子树的树结构,有左右子树之分
特点性质:详情跳转到百度百科
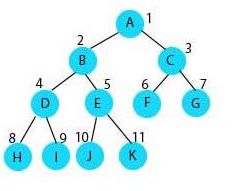
二叉查找树的简单概念:二叉树的前提下,左子树上所有节点的值均小于/等于其父节点的值,右子树上所有几点的值均大于/等于其父节点的值,左右子树也分别为二叉查找树
二叉查找树的查找步骤:小于往左,大于往右,相等则查找成功,子树为空不成功
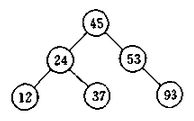
但是,二叉查找树遇到以下的情况效率会很低

于是乎,聪明的地球人发明了二叉平衡树(AVL树)
二叉平衡树的简单概念:在二叉查找树的前提下,任何节点的两棵子树的高度最大差为1(|BF|<=1)
平衡因子(BF):BF=左子树深度—右子树深度
要维持二叉平衡树的平衡,最为重要的是找到其最小不平衡树,最小不平衡树可以这样来找:找距离插入节点最近且平衡因子的绝对值大于1的结点为根的子树,找到最小不平衡树之后呢,需要将其变为平衡,主要是依靠旋转来实现的
如何维持平衡(3种最小不平衡树,3种旋转方式):
a.左旋:BF< -1时,父节点变为该节点的左节点
b.右旋:BF> 1时,父节点变为该节点的右节点
c.左旋+右旋 or 右旋+左旋:插入节点后,最小不平衡树的BF与它的子树的BF符号相反时,依具体情况先旋转一次使符号相同后,再反向旋转一次
看个小例子:

但是,二叉树每一个节点最多也就对应2个子节点,节点一多的话树的高度就会很大,查找起来要遍历的层数会很多,效率还是个问题,于是,B+树便应运而生了
B+树的简单概念:一种特殊的平衡查找树,所有记录节点都是按键值大小顺序存放于同一层的叶子节点,各叶子节点以指针进行衔接,键值小在左,键值大在右

叶子节点从左到右顺序遍历便可得到所有键值的顺序排序,这也是为什么联合索引需满足“最左前缀匹配”的原因,而对于B+树的插入与删除,过于复杂,这里就不多做叙述,奉上一篇很详细的博文“从B树、B+树、B*树谈到R 树”
2.B树索引:
什么是聚集索引:
简单概念:一个表中根据主键创建的一棵B+树,索引的叶子节点存放了表中所有的记录,存储记录在物理位置上是连续的,一个叶子节点存放一条对应的记录(PS:是根据主键创建的B+树,叶子节点存数据记录)
举个例子(以汉语字典为例):
汉语字典的正文本身就是一个聚集索引,比如我们要查“安”字,由于汉语词典的拼音排序是从“a”开始到“z”结尾的,则“安”字自然而然就排在字典前部,若翻遍了所有以“a”开头的部分仍找不到该字,则说明“安”不在字典中;同理,若想查“张”字,我们会将字典翻到最后一部分,因为拼音是“zhang”。而在我们的这些查找中,我们仅仅依靠正文就可以进行相应的查找;也就是说,字典的正文部分本身就是一个目录,我们不需要再通过其他目录的查找来找到我们需要的内容。正文内容本身就是按照一定规则排列的目录便称为“聚集索引”。每个表只能有一个聚集索引,因为目录只能按照一种方法进行排列,且每个表的主键是唯一的
什么是非聚集索引:
简单概念:非聚集索引是根据索引字段创建的一棵B+树,索引的叶子节点仅存放索引键值以及该键值指向的主键,存储记录在逻辑上是连续的(PS:根据索引字段创建的B+树,叶子节点只存放索引键值与记录的主键)
举个例子(还是以汉语字典为例):
当我们遇到不认识的字且不知道它的发音,这时候,我们就不能按照前面的方法找到要查的字,而是需要根据“偏旁部首”查找要找的字,然后根据这个字后的页码直接翻到某页来找到要找的字,但我们结合“部首目录”和“检字表”而查到的字的排序并不是真正的正文的排序方法,比如我们查“张”字,在查部首之后的检字表中“张”的页码是672页,检字表中“张”的上面是“弛”字,但页面却是63页,“张”的下面是“弩”字,页面是390页,很显然,这些字在正文中并不是真正的分别处于“张”字的上下方,现在看到的连续的“弛,张,弩”三字的顺序实际上就是它们在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射,我们可以通过这种方式来找到所需要的字,但这包含2个过程,先找到目录中的结果,再根据找到的结果来翻到我们所需要的页面,这种目录纯粹是目录,正文纯粹是正文的排序方式就是“非聚集索引”
聚集索引与非聚集索引的主要区别:
a.存储特点的区别:
聚集索引按索引顺序来存储,索引项顺序与表中记录的物理顺序一致,叶子节点即存储了真实数据行,不再有另外的单独数据页,一张表上最多只有一个聚集索引;
非聚集索引表的存储顺序与索引顺序无关,仅仅索引项的逻辑上是连续的,叶子节点存储了索引字段值以及指向数据页数据行的逻辑指针,其行数量与数据表行数据量一致。
b.更新表数据的区别:
插入数据:无聚集索引的表,表中数据行没特定顺序,新行皆被添加到表的末尾;有聚集索引的表,先根据索引找到对应的数据页,挪动已有记录为新数据腾出空间后插入,若数据页已满,则拆分数据页,调整索引指针(若表中有非聚集索引,则更新索引指向新的数据页);
删除数据:无聚集索引的表,直接删除(留下内存空洞);有聚集索引的表,删除行将导致其下的数据行向上移动以填补空白,若删除的行为数据页最后一行,则回收该数据页,相应索引页中记录也被删除。
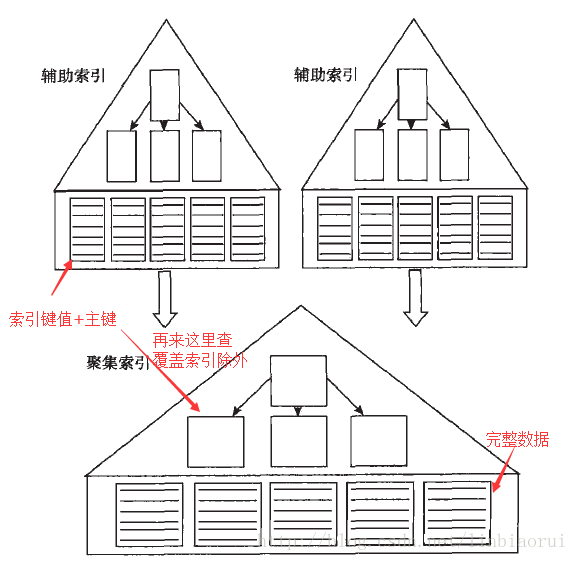
InnoDB的B+树索引:
a.InnoDB是索引组织表的,即数据文件本身就是按照B+树方式存放数据的;
b.InnoDB引擎中可以有聚集索引与非聚集索引,这2种索引每个页大小都为16k,且不能更改;
c.由于非聚集索引不包含行记录所有数据,因此每页可以存放比聚集索引更多的键值,高度一般都小于聚集索引;
d.若在InnoDB表建立时没显式指定主键,则InnoDB会自动创建一个6字节的列作为主键;
e.InnoDB中,主键的值会附加在每个非主键索引(非聚集索引)对应记录后面,无需重复添加到覆盖索引列中,这也是为什么我们常说InnoDB主键长度越小越好;
f.若非聚集索引是包含主键的联合索引,也不需要一个额外的列存放主键值,它会通过联合索引中的主键进行查找。
小图一张,展示下InnoDB中聚集索引与非聚集索引的关系
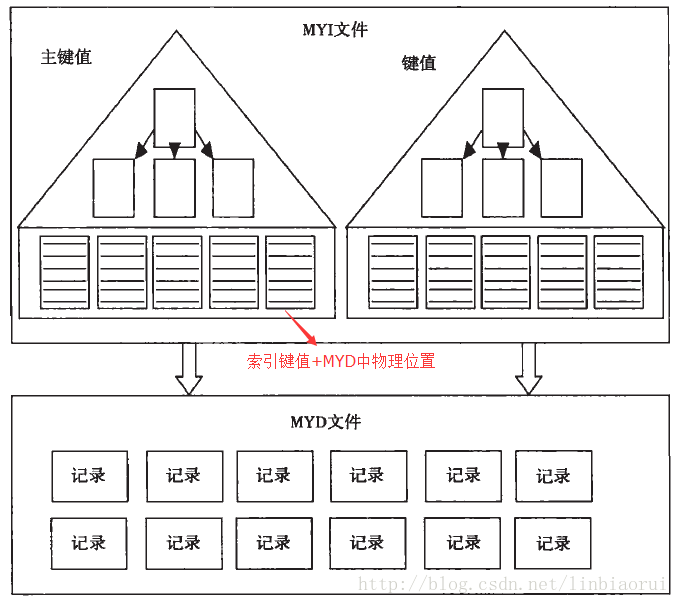
MyISAM 的B+树索引:
a.MyISAM是堆组织表,没有聚集索引的概念;
b.MyISAM表所有的行数据都存放在MYD文件中,B+树索引都存放在MYI文件中,且都是非聚集索引;
c.主键索引与其他索引不同之处在于必须是唯一的,且不可为null,索引页大小为1k,且不可调整;
d.由于没有聚集索引,故其索引叶节点存放的键值不是主键值,而是对应记录在MYD文件中的物理位置;
这也是为什么MyISAM表记录删除之后数据文件大小没什么变化,留下内存碎片,造成“空洞”的现象(可用 “OPTIMIZE TABLE 表名” 进行定期清理,会锁表)。
小图一张,展示下MyISAM中MYD与MYI的关系
Cardinality:
该值表示索引中唯一值记录数量的预估值,如索引值有以下取值:1、3、7、3、5、7,则cardinality=4;
在实际应用中,cardinality/rows_num应尽可能接近1,若该值非常小,则需考虑是否要建索引。
innodb存储引擎cardinality的更新策略:
a.表中1/16数据发生变化;
b.stat_modified_counter>2000000000(发生变化的次数)。
cardinality采样过程:
a.取得B+树索引中叶节点数量,记为A;
b.随机取B+树索引中8个叶子节点,统计每页不同记录的个数,记为P1,P2,…P8;
c.给出预估值:cardinality=(P1+P2+…+P8)*A/8。
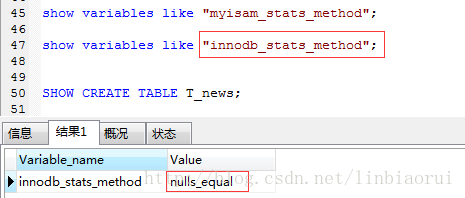
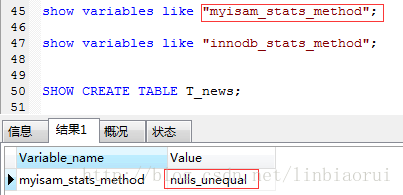
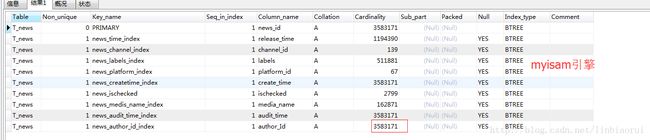
InnoDB与MyISAM中Cardinality值的统计:
对于InnoDB,其认为字段null值是相等的,是同一个值,而对于MyISAM,其认为字段null值是不相等的,不是同一个值,因此会有这么一种情况,同一张表的同一个字段采用InnoDB与MyISAM统计出来的Cardinality值是不相等的,实例如下,对于T_news新闻表,其author_Id字段的Cardinality值明显不同

优化器不使用索引及优化:
a.当访问的数据占表数据20%左右时,不走索引,使用聚集索引进行全表扫描;
b.查找大量数据列而不能使用到覆盖索引(由机械硬盘顺序读取的特性决定的,利用顺序读取替换随机读取);
c.表数据量过少,mysql优化器判定直接全表扫描比使用索引效率要高。
使用index hint优化(确定非聚集索引能带来更好性能):
a.force index(index_name):强制走某个索引;
b.use index(index_name):告诉优化器可以选择使用该索引,但实际上优化器会根据自己判断进行选择,不一定会使用到;
c.ignore index(index_name):告诉优化器在选择索引的时候忽略掉该索引,该索引将不会被使用到。
3.索引的类型:
普通索引:
最基本的索引,没有任何限制,是我们大多数情况下使用到的索引
如何创建:
1.直接创建:
CREATE INDEX index_name ON table(column(length))
2.修改原有表结构:
ALTER TABLE table_name ADD INDEX index_name ON(column(length))
若是char、varchar类型length可不填,默认字段的实际长度,若是blob、text类型则必须指定长度
唯一索引:
与普通索引类似,不同之处在于索引列的值必须唯一,但允许有空值(和主键不同之处),若是联合索引,则列值得组合必须唯一
如何创建:
1.直接创建:
CREATE UNIQUE INDEX index_name ON table(column(length))
2.修改原有表结构:
ALTER TABLE table ADD UNIQUE index_name ON(column(length))
主键索引:
不允许有空值,主键索引建立的规则是int优于varchar,一般在剪标的时候创建,最好是与表的其他字段不想关的列或者是业务不相关的列,一般为int且是AUTO_INCREMENT自增长类型的
联合索引:
通俗地讲就是,索引包含多个字段但只有一个名称,这个才是本篇文章要讲的重点
如何创建:
CREATE INDEX index_name ON table_name(column1(length1),column2(length2……))
一个联合索引根据”最左前缀”会包含多个索引:
比如:建立了联合索引(A,B,C),实际上它包含了3个索引,分别是(A)、(A,B)、(A,B,C),即包含了联合索引的左子集,这也是为什么我们建了联合索引(A,B,C),就没必要再单独建一个普通索引(A)的原因
建立联合索引的时候,通常需要将其他相关的查询都拿来参考,以便做综合评估,进一步提高索引的使用效率与查询效率
联合索引的特点:
实例的背景——在T_news表中建立以ischecked、channel_id、audit_time3个字段为联合索引
a.最左前缀:索引where时的条件要按照建立索引的时候字段的排列顺序
实例如下:
where条件单独使用ischecked字段,符合最左前缀,联合索引起作用
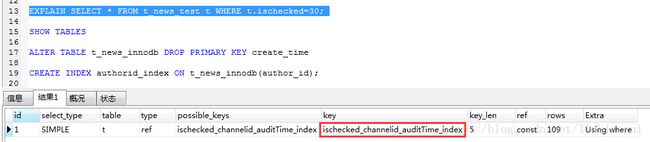
where条件使用ischecked与channel_id字段,符合最左前缀,联合索引起作用
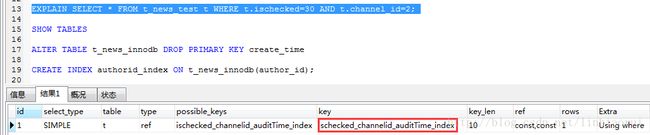
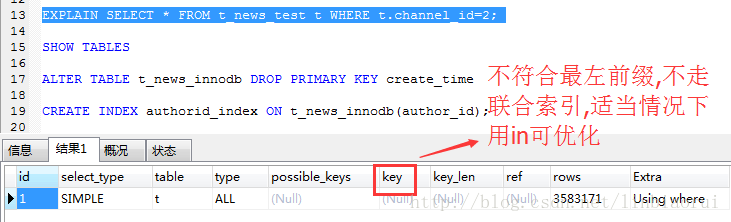
where条件使用channel_id字段,不符合最左前缀,联合索引不起作用
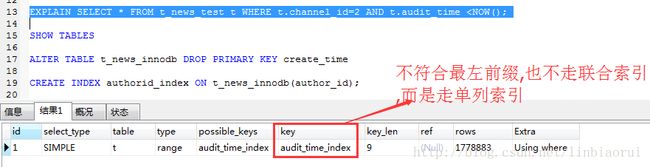
where条件使用channel_id与audit_time字段,不符合最左前缀,联合索引不起作用,使用表原有的单列索引
b.全值=或in匹配where条件可以乱序:索引where时的条件包含了联合索引的全部字段且是等值匹配或in匹配的时候,where条件的顺序可以打乱,优化器会自动优化
实例如下:
where条件顺序为channel_id、ischecked、audit_time的等值匹配

where条件顺序为channel_id、ischecked、audit_time的in匹配

c.查询中某个列有范围查询,则其右边的所有列都无法使用该联合索引
实例如下:
where条件顺序包含了联合索引的所有字段,但其中ischecked字段使用了范围查询,联合索引对ischecked后的所有字段不起作用
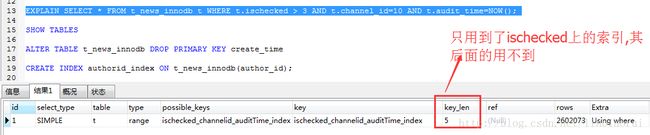
where条件顺序包含了联合索引的所有字段,但其中channel_id字段使用了范围查询,联合索引对channel_id后的所有字段不起作用

d.不能跳过联合索引中的某个字段来进行查询,这样利用不到整个联合索引
如:联合索引(A,B,C),where A=1 and C=2,则只能使用到A索引
实例如下:
where条件只是用了ischecked、audit_time字段,跳过了channel_id字段,利用不了整个联合索引

覆盖索引:
指的是一个包含指定查询所需所有字段的索引,便为覆盖索引(针对特定select语句而言的联合索引)
若mysql使用了覆盖索引,只需通过索引便可返回数据,无需在查到索引之后进行回表查询,减少I/O,提高效率
当在explain select……执行计划中的extra列看到using index提示时,说明该select查询使用了覆盖索引


覆盖索引的限制,遇到以下情况不会使用覆盖索引:
a.索引中的列不能全部覆盖select查询所需的所有列
b.where条件中不能含有对索引进行like的操作
总结:覆盖索引只能使特殊定义的查询性能大幅度提升,在生产环境上并不是理想的索引,索引包含过多的列也会给mysql维护索引带来一定的麻烦,降低写操作的性能
全文索引:
a.mysql版本5.6以下全文索引仅可用于 MyISAM 表(),5.6以上MyISAM 和InnoDB都支持,可以从CHAR、VARCHAR 或 TEXT 列中作为 CREATE TABLE 语句的一部分被创建,或是随后使用 ALTER TABLE 或 CREATE INDEX 被添加
b.用处/场景:当查询条件为where column like ‘%xxx%’时,会让索引失效,此时全文索引便派上用场了
c.创建语句:ALTER TABLE table_name ADD FULLTEXT(column1,column2……)
d.简单查询用法:SELECT * FROM table_name WHERE MATCH(column1,column2) AGAINST(‘xxx’,’sss’,’ddd’)
该语句将column1与column2列中有xxx、sss、ddd的数据记录全部查出来
全文索引注意事项:
a.对于较大的数据集,将数据输入一个没有FULLTEXT索引的表中,然后创建索引,其速度比把数据输入现有FULLTEXT索引的速度更为快
b.生成全文索引是一个非常耗时且非常耗硬盘空间的做法
c.全文索引创建速度慢,而且对有全文索引的各种数据修改操作也慢
d.数据表越大,全文索引效果好,小表返回结果可能不理想
e.不区分大小写,仅能在MyISAM上使用
f.少于3个字符的单词不会被包含在全文索引里,可以通过修改my.cnf的ft_min_word_len选项进行设置
g.最坑爹的一个是不支持中文,需要先采用其他技术来对中文进行处理(如:Sphinx(斯芬克斯)/Coreseek技术)
PS:数据库做全文检索现在很少使用到全文索引,而是使用elasticsearch等其他技术做搜索引擎
创建索引的几大原则:
a.最左前缀匹配原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like ‘%…’)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,若建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整
b.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会优化成索引可识别的形式
c.尽量选择区分度高(cardinality越大越好)的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,一般需要join的字段都要求是0.1以上,当然,使用场景不同,该值也难以确定
d.索引列不能是表达式的一部分或mysql函数的参数,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,因为b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,成本太大,故不能走索引,所以语句应写成create_time = unix_timestamp(’2014-05-29’)
e.尽量的扩展索引,不要新建索引,比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可
4.简单例子体验下联合索引:
场景是这样的:T_news新闻表有大概250W条记录,需要查询经常查询某一时间段内,指定频道下已审核的新闻列表,sql语句是这样的,select news_id,platform_id,media_name,channel_id,labels,title,image,ischecked,create_time,audit_time,author_id
from t_news_innodb n where 1=1 and n.ischecked = 3 and n.channel_id = 1 and n.audit_time > ‘2017-01-08 16:05:00’
and n.create_time > ‘2017-01-08 16:05:00’ ORDER BY n.audit_time DESC,没涉及到多表关联或者其他的复杂查询,仅仅是where条件+order by排序而已,很简单的一条单表查询语句,由于公司没有DBA,因此之前开发对该表索引的建立都是where条件包含哪些字段就在那些字段上建个单列索引,于是乎执行了上面的语句,效果如下:
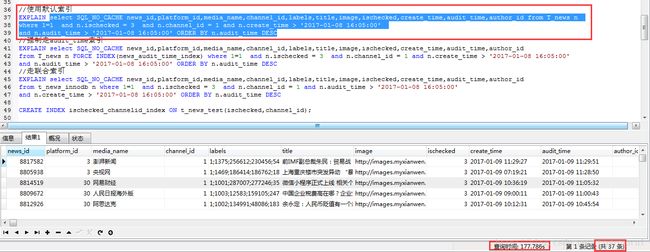
完全懵逼有木有~~就37条记录额,花了整整将近178s,是人都不能忍额
再来使用explain看看执行计划

重点关注下type、key、rows、extra这4列,type列中的值为index_merge说明该查询将索引进行合并了,key列中的值说明使用到了ischecked与channel_id字段的索引,rows列表示这个查询预计要扫描9987条记录,最后的extra列告诉我们该查询将ischecked与channel_id这两个索引进行合并,合并完还不算完,最后order by的排序字段由于用不到索引,于是使用到了mysql自带的文件排序算法,于是这个查询的时间就这么蹭蹭蹭地上天了!!!
最后看下详细的执行计划,看下这条查询的主要时间是花在什么哪一步操作上额
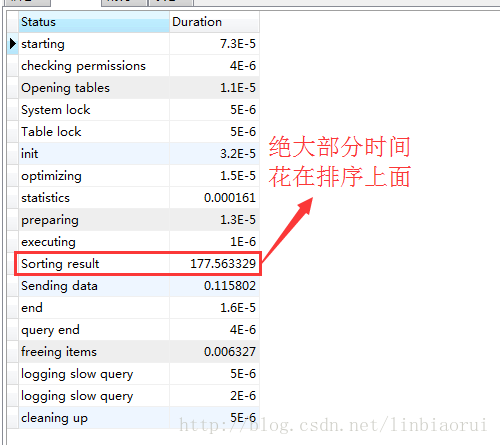
可以看到,绝大部分的时间是花在对记录进行排序上面,因此我们的查询语句应当尽量避免文件排序,尽可能地让索引帮我们排序
再来看下使用了ischecked、channel_id、audit_time这3字段为联合索引后的查询效果,执行相同的语句,效果如下:
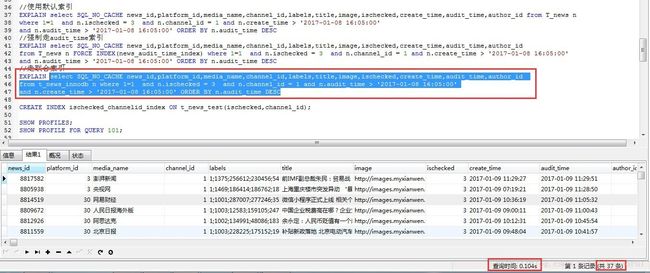
查询效率的提升相比于上面的简直是恐怖有木有!!!用了大概1/10秒,相比于上面的,查询速度约是它的1780倍额
再来使用explain看看执行计划
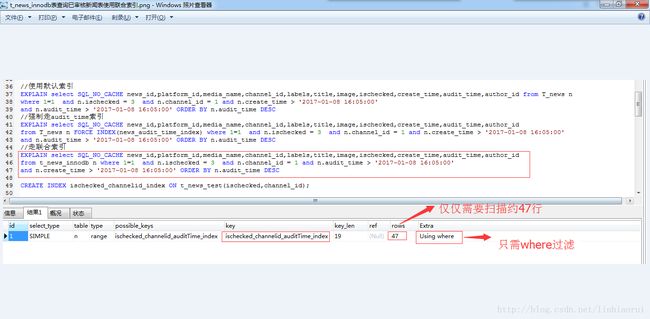
相比于上面的,因为where条件与order by的排序字段都使用到了联合索引,于是什么索引合并、文件排序通通都木有了,只需要用到where过滤掉不符合的记录,而且预计需要扫描的行数仅仅47,查询速度自然不再同一级别
最后看下详细的执行计划

相比于之前,排序花的时间几乎可以忽略
PS:这个例子只是想说明,在很多情况下,一个好的,适合查询语句的索引可以使查询的效率上升一个甚至多个数量级,索引并不是越多越好,千万不要觉得where条件有什么字段就建个索引下去,这样往往帮助不大,反而会使得索引过多影响MDL操作效率,合适才是最重要的,因为本示例只是单纯地想对比下单列索引与联合索引,因此在建立联合索引的时候,需要综合考虑指定表中常用的查询语句,建立可以适用多个查询而效率又不太低的联合索引,适当时候改写下sql语句使得其用上联合索引。
本文到此为止,参考了文章细说MySQL索引