Flink 1.9.1 安装及启动
这里部署环境为 CDH6.2 集群,三个节点,Flink 版本为编译的 Flink1.9.1 版本。
Flink集群有两种部署的模式,分别是 Standalone 以及 YARNCluster 模式。
Standalone 模式,Flink 必须依赖于 ZooKeeper 来实现 JobManager 的 HA(Zookeeper 已经成为了大部分开源框架 HA 必不可少的模块)。在 Zookeeper 的帮助下,一个Standalone 的 Flink 集群会同时有多个活着的 JobManager,其中只有一个处于工作状态,其他处于 Standby 状态。当工作中的 JobManager 失去连接后(如宕机或 Crash), ZooKeeper 会从 Standby 中选举新的 JobManager 来接管 Flink 集群。
YARN Cluaster 模式,Flink 就要依靠 YARN 本身来对 JobManager 做 HA 了。其实这里完全是 YARN 的机制。对于 YARNCluster 模式来说, JobManager 和 TaskManager 都是启动在 YARN 的 Container中。此时的 JobManager,其实应该称之为 Flink Application Master。也就说它的故障恢复,就完全依靠着 YARN 中的 ResourceManager(和 MapReduce 的 AppMaster 一样)。由于完全依赖了 YARN,因此不同版本的 YARN 可能会有细微的差异。
1. 下载解压
Flink官方下载地址 、 Flink阿里镜像站 、 编译CDH6.2版本: Flink1.9.1-CDH6.2 、 Flink-1.10.0-CDH6.2
tar -zxvf flink-1.9.1.tar.gz -C /opt/apps/2. 环境依赖
zookeeper-3.4.x
JDK-1.8+
scala-2.11.x3. 环境变量
# /etc/profile 或者 vim ~/.bashrc
echo export FLINK_HOME=/opt/apps/flink-1.9.1 >> /etc/profile \
&& echo 'export PATH=$PATH:$FLINK_HOME/bin' >> /etc/profile
# 需要配置 HADOOP_CONF_DIR 环境变量,否则会有提示
# Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set.
# 已经配置CDH_HOME
# export CDH_HOME=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373
echo 'export HADOOP_HOME=$CDH_HOME/lib/hadoop/' >> /etc/profile
source /etc/profile4. 启动
1. Local 模式
Local 模式,JobManager 和 TaskManager 共用一个 JVM 来完成 WorkLoad。
如果验证一个简单的应用, Local 模式是最方便的,实际应用中大多使用 Standalone 或者 Yarn Cluster。
Local 模式只需要将安装包解压,启动 ./bin/start-local.sh 即可。
2. Standalone模式
1. 修改配置文件
Flink配置文件说明
1、配置主节点地址和端口,masters 文件
vim $FLINK_HOME/conf/masters
# 设置主节点,非HA模式只配置一个即可
cdh-master:80812、 配置从节点列表,slaves 文件
vim $FLINK_HOME/conf/slaves
# 设置从节点
cdh-master
cdh-slave01
cdh-slave023、 配置集群相关其他信息,flink-conf.yaml 文件
vim $FLINK_HOME/conf/flink-conf.yaml
# jobmanager地址
jobmanager.rpc.address: cdh-master
# jobmanager
jobmanager.heap.size: 1024m
# taskmanger 内存
taskmanager.heap.size: 1024m
# slot个数
taskmanager.numberOfTaskSlots: 2
# 并行度
parallelism.default: 12. 分发到其他节点
lsync同步数据脚本
# lsync脚本分发
lsync flink-1.9.1
# 或者scp分发
scp -r flink-1.9.1/ cdh-slave01:$PWD3. 启动
$FLINK_HOME/bin/start-cluster.sh
# 启动后的进程
# 主节点进程为 StandaloneSessionClusterEntrypoint
# 从节点进程为 TaskManagerRunner启动进程
主节点

从节点

WebUI 地址
http://cdh-master:8081/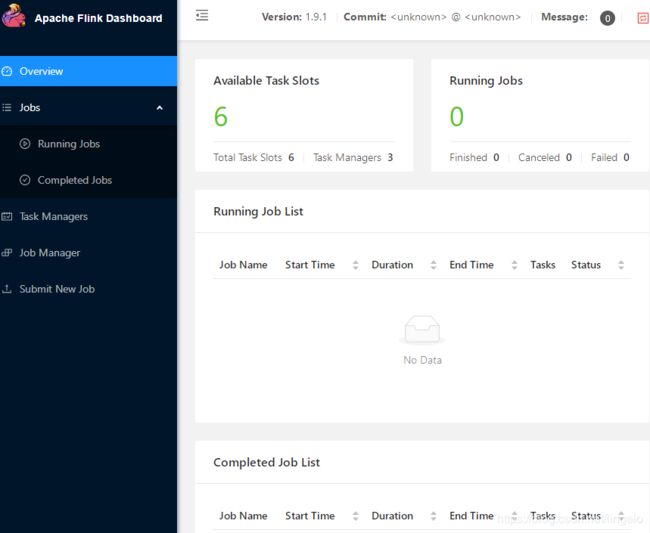
Standalone 模式启动完成!
停止
$FLINK_HOME/bin/stop-cluster.sh
3. Standalone HA模式
1. 修改配置文件
1、配置主节点地址和端口,masters 文件
vim $FLINK_HOME/conf/masters
# 设置主节点,HA 设置active及standby两个
cdh-master:8081
cdh-slave01:80812、 配置从节点列表,slaves 文件
vim $FLINK_HOME/conf/slaves
# 设置从节点
cdh-master
cdh-slave01
cdh-slave023、 配置集群相关其他信息,flink-conf.yaml 文件
vim $FLINK_HOME/conf/flink-conf.yaml
# 基础配置
jobmanager.rpc.address: cdh-master
jobmanager.heap.size: 1024m
taskmanager.heap.size: 1024m
taskmanager.numberOfTaskSlots: 3
parallelism.default: 5
# 指定使用 zookeeper 进行 HA 协调
high-availability: zookeeper
high-availability.storageDir: hdfs://BigdataCluster/flink/ha/
high-availability.zookeeper.quorum: cdh-master:2181,cdh-slave01:2181,cdh-slave02:2181
high-availability.zookeeper.client.acl: open
# 指定 checkpoint 的类型和对应的数据存储目录
state.backend: filesystem
state.checkpoints.dir: hdfs://BigdataCluster/flink/flink-checkpoints
jobmanager.execution.failover-strategy: region
# Rest和网络配置
rest.port: 8081
rest.address: cdh-master
# 高级配置,临时文件目录
io.tmp.dirs: /tmp
# 配置 HistoryServer
jobmanager.archive.fs.dir: hdfs://BigdataCluster/flink/completed-jobs/
historyserver.web.address: cdh-slave01
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://BigdataCluster/flink/completed-jobs/
historyserver.archive.fs.refresh-interval: 100002. 拷贝 Zookeeper 及 HDFS 配置文件
cp $CDH_HOME/lib/zookeeper/conf/zoo.cfg /opt/apps/flink-1.9.1/conf/
cp /etc/hadoop/conf/core-site.xml /opt/apps/flink-1.9.1/conf/
cp /etc/hadoop/conf/hdfs-site.xml /opt/apps/flink-1.9.1/conf/3. 分发到其他节点
lsync同步数据脚本
# lsync脚本分发
lsync flink-1.9.1
# 或者scp分发
scp -r flink-1.9.1/ cdh-slave01:$PWD4. 启动
$FLINK_HOME/bin/start-cluster.sh
# 启动后的进程
# 主节点进程为 StandaloneSessionClusterEntrypoint
# 从节点进程为 TaskManagerRunner启动进程
主节点

standby节点

从节点

WebUI
http://cdh-master:8081
Standalone HA模式启动完成!
停止
$FLINK_HOME/bin/stop-cluster.sh
4. Flink On YARN 模式
启动 YARN Cluster 集群,参考 Flink On YARN
5. 提交 Job
flink run -m cdh-master:8081 \
$FLINK_HOME/examples/batch/WordCount.jar
# 或者指定输入输出目录
flink run -m cdh-master:8081 \
$FLINK_HOME/examples/batch/WordCount.jar \
--input hdfs:///flink/input/ \
--output hdfs:///flink/flinkoutput不指定输出目录,会直接显示在控制台
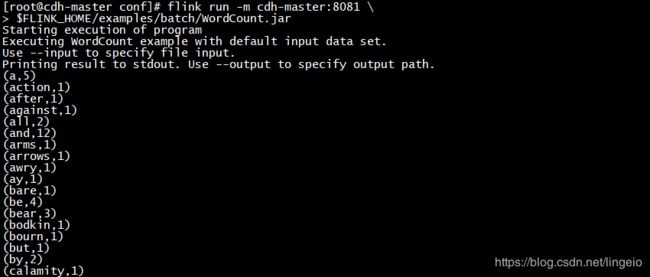
指定输出目录

