Kaggle入门数据集Titanic代码记录
本文大部分文字翻译自Kaggle的“Titanic Data Science Solutions”,以及大部分代码也搬运自此。初入Kaggle坑,拿到Titanic数据集时可以说是毫无头绪,“数据集中的冗余特征怎么通过代码去除?”“缺失值怎么补足?”“特征工程需要做哪些工作?”这些问题让我不知从何下口。记录的初衷在于作为机器学习小白的自己,试图通过这种方法理清思路,加深印象,若能帮到路过的同学,那更是喜不自胜了。
1.导入库
import numpy as np
import pandas as pd
import random as rnd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier2.数据探索
(1)数据概览
下载数据
[Titanic数据集下载地址](https://www.kaggle.com/c/titanic/data)
探索数据
下载页面中共有三个文件,分别是train.csv,test.csv,gender_submission.csv。train是编码为1-891共891名乘客的训练数据,test和gender_submission分别为测试数据和需要提交结果的格式以及正确答案。
首先在存放数据集的目录下的空白处按住shift键并单击右键,打开cmd。输入python或者ipython,进入python环境。
(2)基于数据的假设
根据目前为止的数据分析,我们得出如下假设。我们需要进一步验证这些假设,才能进行下一步分析。
•相关性
我们希望知道每个特征与Survived的相关性。我们也希望在project前期做这些工作,而且在之后的建模中匹配这些相关性。
•填充
1.填充与Survived明确相关的Age特征。
2.Embarked可能与Survived相关,也可能与其他重要的属性相关,也要填充
1.分析中可能不用Ticket特征,因为该特征包含大量的(22%)重复数据,而且Ticket可能与Survived无关。
2.Cabin特征也不用,因为它的完成度较低,training和test数据集中都中含有大量null数据。
3.PassengerId因为对Survived没有任何贡献,所以也是无关特征。
4.Name特征的格式相对不够规范,可能对Survived也没有直接贡献,去掉。
•创造特征
1.可以通过Parch和 SibSp特征的加和得出船上的家庭成员总数,从而创造Family特征。
2.从Name特征提取缩写得到Title特征。
3.Age分支由连续的数字特征转换为离散的分类特征。
4.也可以创造一个Fare的区间特征用来辅助分析。
•分类
我们也可从问题描述中描述的问题来提出假设。
1.女性更有可能活下来
2.孩子更有可能活下来。
3.头等舱(Pclass=1)的人更有可能活下来。
(3)分析数据
为了确认我们的观察和假设是正确的,我们可以分析特征的相关性。我们仅在现阶段特征中没有空值的时候这样做,也只是在特征值为分类(Sex),序列(Pclass)或者离散(SibSp,Parch)的时候才有意义。
•Pclass
可以看出Survived和Pclass在Pclass=1的时候有较强的相关性(>0.5),所以最终模型中包含该特征。
data[['Pclass','Survived']].groupby(['Pclass'],as_index=False).mean().sort_values(by='Survived', ascending=False)结果如下:
| Index | Pclass | Survived |
|---|---|---|
| 0 | 1 | 0.629630 |
| 1 | 2 | 0.472826 |
| 2 | 3 | 0.242363 |
•Sex
可以确定在问题定义中的观察——女性有更高的活下来的概率(74%)——是正确的
data[['Sex','Survived']].groupby(['Sex'],as_index=False).mean().sort_values(by='Survived', ascending=False)结果如下:
| Index | Sex | Survived |
|---|---|---|
| 0 | female | 0.742038 |
| 1 | male | 0.188908 |
•SibSp and Parch
这些特征与特定的值没有相关性,最好是由这些独立的特征派生出一个新特征或者一组新特征。
SibSp
data[['SibSp', 'Survived']].groupby(['SibSp'], as_index=False).mean().sort_values(by='Survived', ascending=False)结果如下:
| Index | SibSp | Survived |
|---|---|---|
| 1 | 1 | 0.535885 |
| 2 | 2 | 0.464286 |
| 0 | 0 | 0.345395 |
| 3 | 3 | 0.250000 |
| 4 | 4 | 0.166667 |
| 5 | 5 | 0.000000 |
| 6 | 8 | 0.000000 |
Parch
data[['Parch', 'Survived']].groupby(['Parch'], as_index=False).mean().sort_values(by='Survived', ascending=False)结果如下:
| Index | Parch | Survived |
|---|---|---|
| 3 | 3 | 0.600000 |
| 1 | 1 | 0.550847 |
| 2 | 2 | 0.500000 |
| 0 | 0 | 0.343658 |
| 5 | 5 | 0.200000 |
| 4 | 4 | 0.000000 |
| 6 | 6 | 0.000000 |
(3)通过可视化分析数据
现在我们可以用可视化数据分析的方式进一步确定我们的假设
关联数值特征
直方图在分析类似于Age特征的连续数值变量时有助于模式识别。直方图可以直观的看出样本的分布特点。
注意直方图的X轴代表样本计数或者乘客数量。
观察
•婴儿(Age≤4)存活率更高
•最老的乘客(Age=80)活下来了
•很大一部分15-25岁的人没活下来
•幸存者多数在15-35岁
决定
这个简要的分析确定了我们的假设就是下一步的工作。
•在训练模型时应该考虑年龄
•Age特征中没有值的需要填充
•年龄需要分组
g = sns.FacetGrid(data, col='Survived')
g.map(plt.hist, 'Age', bins=20)
plt.show()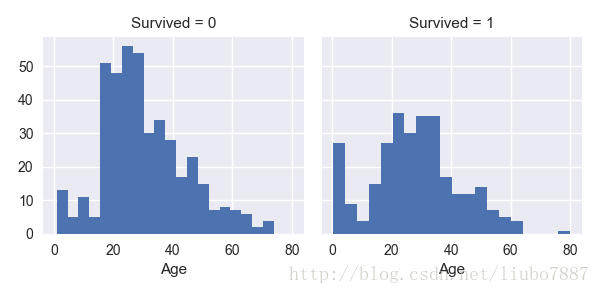
关联数值和序列特征
我们用一个简单的绘图识别了多项特征的相关性,这种手段可以用于样本值为数字的特征。
观察
•Pclass=3的乘客数量最多,但是幸存率最低。证实了我们以上‘分类’中的假设2
•婴儿乘客在Pclass=2和Pclass=3中最有可能幸存,进一步证实了‘分类’中的假设2
•大部分Pclass=1中的乘客幸存下来,证实了‘分类’中的假设3
•Pclass改变了乘客关于Age的分布
决定
•在训练模型时考虑Pclass
grid = sns.FacetGrid(data, col='Survived', row='Pclass', size=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', alpha=0.5, bins=20)
grid.add_legend()
plt.show()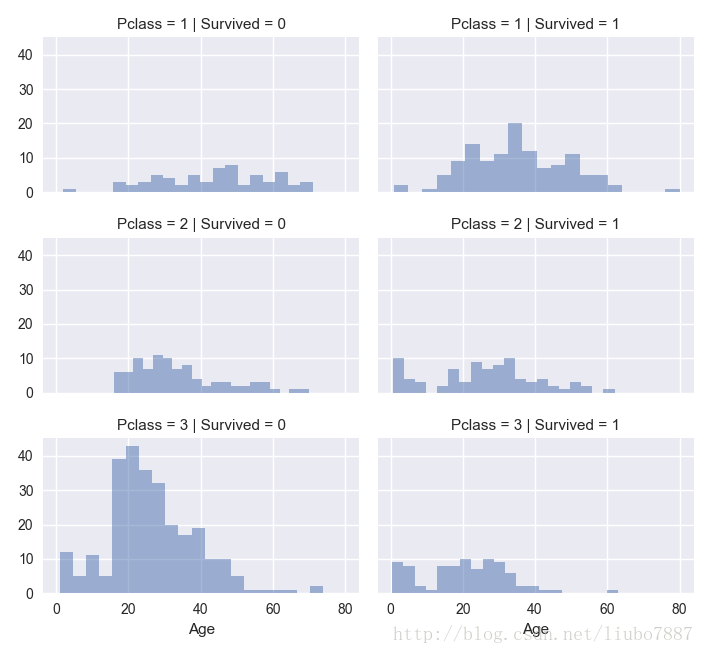
关联分类特征
现在我们可以把要解决的目标与分类特征关联起来了。
观察
•女性乘客的存活率优于男性
•Embarked=C里面的男性幸存率高于女性是个例外,不必要建立Embarked与Survived之间的联系
•从C和Q港口来的男性在Pclass=3中的幸存率高于Pclass=2
•Pclass=3中的不同港口登船的存活率规律与整体男性乘客的存活率规律不同
决定
•把Sex特征考虑到模型中
•把Embarked特征完善,并添加到训练模型中
grid = sns.FacetGrid(data, row='Embarked', size=2.2, aspect=1.6)
grid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette='deep')
grid.add_legend()
plt.show()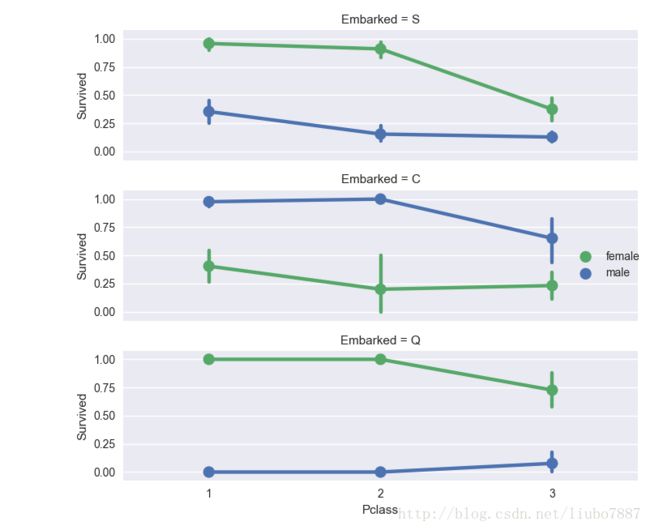
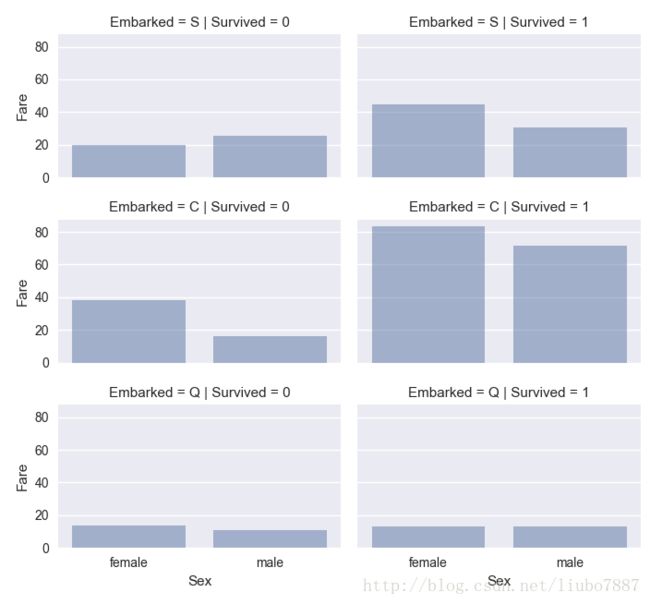
关联分类和数值特征
我们希望关联分类特征(没有数字值)和数值特征。我们可以考虑关联Embarked(分类,无数值),Sex(分类,无数值),Fare(连续数值),以及Survived(分类,数值)
观察
•票价高的乘客更有可能获救
•登船的港口与幸存率有关
决定
•考虑加入票价因素
grid = sns.FacetGrid(data, row='Embarked', col='Survived', size=2.2, aspect=1.6)
grid.map(sns.barplot, 'Sex', 'Fare', alpha=.5, ci=None)
grid.add_legend()