非常全面的前端协作规范(长文建议先收藏)
原文作者:掘金 _sx_
原文链接:https://juejin.im/post/5d3a7134f265da1b5d57f1ed
万字长文,继续刷新我的文章长度记录,涉及前端开发的方方面面。本文将持续更新和完善, 文章部分观点可能比较武断或不完整,欢迎评论和补充,一起完善该文章. 谢谢
笔者长期单枪匹马在前端领域厮杀(言外之意就是团队就一个人),自己就是规范。随着公司业务的扩展,扩充了一些人员,这时候就要开始考虑协作和编码规范问题了。本文记录了笔者在制定前端协作规范时的一些思考,希望能给你们也带来一些帮助.
一个人走的更快,一群人可以走得更远,前提是统一的策略,还要不断地反省和优化。
以下是目录概览, 看出这是一篇浩浩荡荡的长文
1 工作流规范
1.1.1 版本规范
1.1.2 版本控制系统规范
1.1.3 提交信息规范
1.1 开发
1.2 构建规范
1.3 发布工作流规范
1.4 持续集成
1.5 任务管理
2 技术栈规范
2.1 技术选型
2.2 迎接新技术
3 浏览器兼容规范
3.1 确定兼容策略
3.2 确定浏览器分级
3.3 获取统计数据
4 项目组织规范
4.1 通用的项目组织规范
4.2 目录组织的风格
4.3 脚手架和项目模板
5 编码规范
5.1 Javascript
5.2 HTML
5.3 CSS
5.4 代码格式化
5.5 集大成的
5.6 特定框架风格指南
5.7 Code Review
6 文档规范
6.1 建立文档中心
6.2 文档格式
6.3 定义文档的模板
6.4 讨论即文档
6.5 注释即文档
6.6 代码即文档
7 UI设计规范
8 测试规范
8.1 测试的流程
8.2 单元测试
9 异常处理、监控和调试规范
9.1 异常处理
9.2 日志
9.3 异常监控
10 前后端协作规范
10.1 协作流程规范
10.2 接口规范
10.3 接口文档规范
10.4 接口测试与模拟
11 培训/知识管理/技术沉淀
11.1 新人培训
11.2 营造技术氛围
12 反馈
CHANGELOG
2019.7.28 新增技术选型
2019.7.29 新增浏览器统计数据获取
2019.9.6 建立技术氛围一节 新增面试题库
什么是规范?
规范,名词意义上:即明文规定或约定俗成的标准,如:道德规范、技术规范等。动词意义上:是指按照既定标准、规范的要求进行操作,使某一行为或活动达到或超越规定的标准,如:规范管理、规范操作.
为什么需要规范?
降低新成员融入团队的成本, 同时也一定程度避免挖坑
提高开发效率、团队协作效率, 降低沟通成本
实现高度统一的代码风格,方便review, 另外一方面可以提高项目的可维护性
规范是实现自动化的基础
规范是一个团队知识沉淀的直接输出
规范包含哪些内容?
如文章标题,前端协作规范并不单单指‘编码规范’,这个规范涉及到前端开发活动的方方面面,例如代码库的管理、前后端协作、代码规范、兼容性规范;
不仅仅是前端团队内部需要协作,一个完整的软件生命周期内,我们需要和产品/设计、后端(或者原生客户端团队)、测试进行协作, 我们需要覆盖这些内容.
下面就开始介绍,如果我是前端团队的Leader,我会怎么制定前端规范,这个规范需要包含哪些内容?
1 工作流规范
1.1 开发
1.1.1 版本规范
项目的版本号应该根据某些规则进行迭代, 这里推荐使用语义化版本规范, 通过这个规范,用户可以了解版本变更的影响范围。规则如下:
主版本号:当你做了不兼容的 API 修改,
次版本号:当你做了向下兼容的功能性新增,
修订号:当你做了向下兼容的问题修正。
1.1.2 版本控制系统规范
大部分团队都使用git作为版本库,管理好代码也是一种学问。尤其是涉及多人并发协作、需要管理多个软件版本的情况下,定义良好的版本库管理规范,可以让大型项目更有组织性,也可以提高成员协作效率.
比较流行的git分支模型/工作流是git-flow, 但是大部分团队会根据自己的情况制定自己的git工作流规范, 例如我们团队的分支规范
Git 有很多工作流方法论,这些工作流的选择可能依赖于项目的规模、项目的类型以及团队成员的结构.
比如一个简单的个人项目可能不需要复杂的分支划分,我们的变更都是直接提交到 master 分支;
再比如开源项目,除了核心团队成员,其他贡献者是没有提交的权限的,而且我们也需要一定的手段来验证和讨论贡献的代码是否合理。所以对于开源项目 fork 工作流更为适合.
了解常见的工作流有利于组织或创建适合自己团队的工作流, 提交团队协作的效率:

简单的集中式
基于功能分支的工作流
Git Flow ????
Fork/Pull Request 工作流
1.1.3 提交信息规范

组织好的提交信息, 可以提高项目的整体质量. 至少具有下面这些优点:
格式统一的提交信息有助于自动化生成CHANGELOG
版本库不只是存放代码的仓库, 它记录项目的开发日志, 它应该要清晰表达这次提交的做了什么. 这些记录应该可以帮助后来者快速地学习和回顾代码, 也应该方便其他协作者review你的代码
规范化提交信息可以促进提交者提交有意义的、粒度合适的'提交'. 提交者要想好要怎么描述这个提交,这样被动促进了他们去把控提交的粒度
社区上比较流行的提交信息规范是Angular的提交信息规范, 除此之外,这些也很不错:
Atom
Ember
Eslint
JQuery
另外这些工具可以帮助你检验提交信息, 以及生成CHANGELOG:
conventional-changelog - 从项目的提交信息中生成CHANGELOG和发布信息
commitlint - 检验提交信息
commitizen - ????简单的提交规范和提交帮助工具,推荐
standard-changelog - angular风格的提交命令行工具
1.2 构建规范
对于团队、或者需要维护多个项目场景,统一的构建工具链很重要, 这套工具应该强调"约定大于配置",让开发者更专注于业务的开发。笔者在<为什么要用vue-cli3?>文章中提出了vue-cli3更新有很多亮点,非常适合作为团队构建工具链的基础:
首先这类工具是推崇'约定大于配置'。即按照他们的规范,可以实现开箱即用,快速开发业务. 在团队协作中这点很重要,我们不推荐团队成员去关心又臭又长的webpack构建配置
vue-cli3抽离了cli service层,可以独立更新工具链。也就是说项目的构建脚本和配置在一个独立的service项目中维护,而不是像以前一样在每个项目目录下都有webpack配置和依赖. 这样做的好处是独立地、简单地升级整个构建链灵活的插件机制。对于团队的定制化构建应该封装到插件中,这样也可以实现独立的更新。
我们可以选择第三方CLI, 当然也定制自己的构建链,按照上面说的这个构建链应该有以下特点:
强约定,体现团队的规范。首先它应该避免团队成员去关心或更改构建的配置细节,暴露最小化的配置接口。 另外构建工具不仅仅是构建,通常它还会集成代码检查、测试等功能。
方便升级。尤其是团队需要维护多个项目场景, 这一点很有意义
下面是社区上比较流行的构建工具. 当然,你也可以根据自己的团队情况开发自己的CLI, 但是下面的工具依然很有参考价值:
create-react-app - ????零配置开始React开发
vue-cli - ????零配置、渐进增强的项目构建CLI
parcel - 零配置的Web应用打包工具
Fusebox - 高速易用的打包工具
microbundle - 零配置, 基于Rollup,适合用于打包‘库’
1.3 发布工作流规范
发布工作流指的是将‘软件成品’对外发布(如测试或生产)的一套流程, 将这套流程规范化后,可以实现自动化.
举个例子, 一个典型的发布工作流如下:
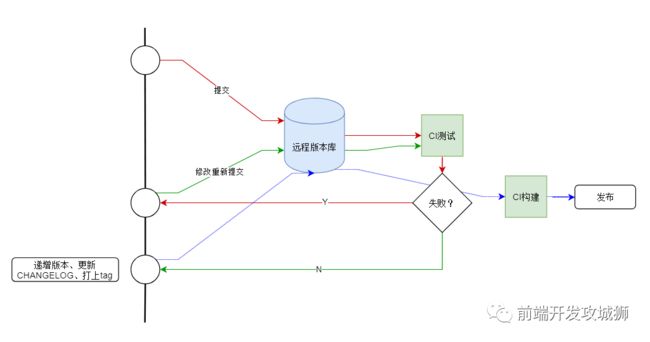
代码变更
提交代码变更到远程版本库
程序通过CI测试(例如Travis变绿)
提升package.json中的版本
生成CHANGELOG
提交package.json和CHANGELOG.md文件
打上Tag
推送
如果你遵循上面的规范,那么就可以利用社区上现有的工具来自动化这个流程. 这些工具有:
conventional-changelog-cli
conventional-github-releaser
实际上自己开发一个也不是特别难的事情.
1.4 持续集成
将整套开发工作流确定下来之后, 就可以使用持续集成服务来自动化执行整个流程。比如一个典型的CI流程:

持续集成是什么,有什么意义呢?
我们需要持续集成拆成两个词分别来理解, 什么是持续? 什么是集成?
持续(Continuous), 可以理解为'频繁'或者‘连续性’. 不管是持续集成还是敏捷开发思维、看板,都认为‘持续’是它们的基础。
举一个通俗的例子,比如代码检查,‘持续的’的代码检查就是代码一变动(如保存,或者IDE实时检查、或者提交到版本库时)就马上检查代码,而‘非持续’的代码检查就是在完成所有编码后,再进行检查。对比两者可以发现,持续性的代码检查可以尽早地发现错误,而且错误也比较容易理解和处理,反之非持续性的代码检查,可能会发现一堆的错误,失之毫厘谬以千里,错误相互牵连,最终会变得难以收拾。
‘持续’的概念,可以用于软件开发的方方面面,本质上就是把传统瀑布式的软件开发流程打碎,形成一个个更小的开发闭环,持续地输出产品,同时产品也持续地给上游反馈和纠正。

那什么是‘集成’呢?狭义的集成可以简单认为是‘集成测试’吧. 集成测试可以对代码静态测试、单元测试、通过单元测试后可以进行集成测试,在应用组成一个整体后在模拟环境中跑E2E测试等等。也就是说,在这里进行一系列的自动化测试来验证软件系统。
广义的持续集成服务,不仅仅是测试,它还衍生出很多概念,例如持续交付、持续部署,如下图
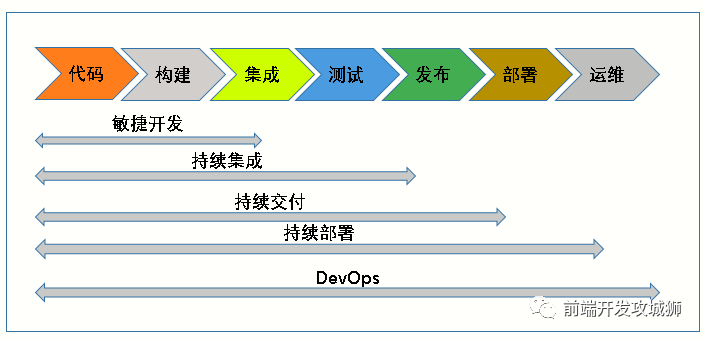
OK, 总结一下为什么持续集成的好处:
尽早发现错误,快速试错。越早发现错误,处理错误的成本越低
自动化工作流,减少人工干预。人类比机器容易犯错, 而且机器擅长做重复的事情
对于持续集成规范一般会定义这些内容:
执行的环境. 比如容器、Node版本、操作系统等等
触发的条件。比如定时触发、在哪个分支触发、会触发什么任务等等
执行的任务
划分持续集成的阶段. 比如
检查:包括单元测试和代码lint. 所有push到版本库的代码都会跑这个阶段. 一般可以在提交title中包含[ci skip]来跳过这个阶段
构建: 对前端项目进行构建. 只有打上版本tag的提交或release分支会跑构建任务
发布: 将前端的构建结果进行交付/发布. 只有打上版本tag的提交或者release分支在构建成功后会跑发布任务
定义持续集成脚本模板
常用的CI服务:
Github
Travis CI
CircleCI
完整列表
GitLab: Gitlab-CI
通用
Jenkins
扩展
持续集成是什么
1.5 任务管理

作为前端Leader少不了任务管理。看板是目前最为流行的任务管理工具,它可以帮助我们了解项目的进度、资源的分配情况、还原开发现场.
笔者毕业第一年在一家很小的外包公司中工作,初生牛犊不怕虎,我竟然给老板推销起了看板和敏捷项目管理,想要改善项目管理这块效率低下问题,老板表示很支持,但是其他成员积极性并不高, 结果当然是失败的。
当时还起草了一份‘看板实施细则’, 所以任务管理这一块也算小有心得吧.
说说一些比较好用的工具吧:
基于issue看板 - 可以基于Gitlab或Github的Issue来做任务管理,它们都支持看板。很Geek,推荐
Tower - 专门做看板任务管理的。小团队基本够用。我们现在就使用这款产品
teambition - 和Tower差不多,没有深入使用过
Trello - 颜值高.
2 技术栈规范
笔者现在所在的公司之前前端技术栈就非常混乱,Vue、React和AngularJS三大框架都有, 而且风格相差也很大. 当时我就想收包裹走人. 关于技术栈不规范的下场可以参考印度的飞机: <为什么印度的飞机频繁被摔?>
很少有人能精通这三个框架的,更别说是一个团队。
三大框架跟编程语言一样都有自己的设计哲学,这跟库是不一样, 一个库的替换成本很低;而框架的背后是一个架构、一个生态。每个框架背后牵涉着开发思维、生态系统、配套工具、最佳实践、性能调优。要精通和熟练一个框架需要付出的成本是很高。
所以说团队的开发效率是基于稳定且熟练的技术栈的。稳定的技术栈规范有利于团队协作和沟通; 另外如果团队精通这个技术栈,当出现问题或者需要深入调优, 会相对轻松。
前端技术栈规范主要包含下面这些类型:
编程语言 - Typescript或Javascript
UI框架及其配套生态, 以及备选方案。其背后的生态非常庞大:
UI框架
路由
状态管理
组件库
国际化
动画
服务端渲染
脚手架、CLI工具
组件测试
样式. 包含了命名规范、预处理器、方法论等等
动画引擎
QA. 包含了测试、Lint、格式化工具、监控
项目构建工具流. 例如webpack、vue-cli
包管理器。npm、yarn
项目管理工具
时间处理。例如Moment.js
模板引擎
开发工具
后端开发框架
工具库
开发/调试工具
等等
可以参考一下我们团队的技术栈规范
2.1 技术选型
如何从零对团队的技术栈进行规范, 或者说怎么进行选型呢?举个例子, 先确定备选项, 你现在要选Vue还是选React(一个可能引起论战的主题)?
恰好前几天在SegmentFault回答了一个问题: <什么时候用vue什么时候用react?>, 我讲了一个我们几年前是如何决定要使用React还是Vue的例子(注意结果不重要!):

<谈谈技术选型的注意事项>这篇文章写得非常好,给了我一些启发。结合上面的回答的例子, 来讲一讲在对相关技术进行选型的一些方法(评分项):
选择你最熟悉的技术。上面说到团队如果熟悉该技术,则可以很好地控制使用过程中的风险,方便对程序进行调优。所以成员熟悉、或至少Leader熟悉程度,是技术选型的一个打分项。
我们团队最终选择React的一个原因,就是我们熟悉它,它已经在现有的几个应用中良好的运行了,所以 React + 1
选择拥有强大生态和社区支撑的开源技术。有强大的生态和社区意味着,很多东西你不需要重复去造轮子,或者遇到问题可以很快解决,有更多的选择。从公司层面、使用活跃的技术也比较好招人。
上面的例子也提到了这点,几年前React的生态是强于Vue的,所以 React + 1
选择成长期的技术。<谈谈技术选型的注意事项>里面有一句话:'选择一个技术的最低标准是,技术的生命周期必须显著长于项目的生命周期'
我们选择的技术应该是向前发展的、面向未来的, 这是选型的基本原则。所以我们一般不会去选择那些'过气'的技术,比如
AngularJS(1.x)、Backbone. 因为现在有更好的选择,不必过于保守。‘向前’还意味着Leader要能够预判该技术未来走向,这里有很多参考因素,比如大厂的支撑、目前社区的活跃度、开发活跃度等等
React、Vue都非常有动力,比如React最近的React Hook、还有未来的ConcurrentMode、Async Rendering... 在这点上Vue和React打成平手吧
API的稳定性。比较典型的例子就是Angular和Python,API不稳定会导致社区的割裂,也会导致项目升级成本变高、或者无法升级, 最终成为技术债。
不过值得庆幸的是因为有这么多历史教训,现在开源项目在API变更上面是非常谨慎的,参考[译] Vue 最黑暗的一天事件.
这点上React和Vue依旧打平
基础设施配合。一个技术往往不是孤立存在的,它需要和其他技术相互配合,这种技术之间的融合度也是需要考虑的。
这个根据团队使用情况来定,比如我们团队统一使用Typescript,Vue跟Typescript配合使用其实不理想,所以 React + 1
业务考虑 <谈谈技术选型的注意事项> 提到一点就是‘学会从业务端开始思考’. 意思就是选型需要充分地理解业务,理解用户需求,当下需要解决的首要问题,以及可能的风险有哪些,再将目标进行分解,进行具体的技术选型、模型设计、架构设计.
一个典型的例子就是10年前火遍世界的
Rails, 后端是使用Rails还是Java/C#/PHP这些传统后端技术? 很多初创公司(如Github、Gitlab、Twitter)选择了前者,他们需要快速开发原型、快速占领市场, Rails开发很爽很快啊, 这种选型就是符合‘业务需求的’。那么前端好像跟业务离得有点远? 随着‘大前端’的发展,我们的工作对公司业务的影响只会越来越大。
比如上面提到的React Native,我们当时有考虑在移动端应用React Native技术,实现客户端的跨平台,这就是业务影响啊。这时候React是不是又要 +1? 同理还有什么服务端渲染、Serverless等等,期待前端的地位会越来越高
综上,在这个案例中,React是胜出的。
扩展:
谈谈技术选型
谈谈技术选型的注意事项
2.2 迎接新技术
当然,对于团队而言也要鼓励学习新的技术、淘汰旧的技术栈。因为一般而言新的技术或解决方案,是为了更高的生产力而诞生的。当团队容纳一个新的技术选型需要考虑以下几点:
学习成本。考虑团队成员的接纳能力。如果成本小于收获的利益,在团队里面推行估计阻力会比较大
收益。是否能够解决当前的某些痛点
考虑风险。一般我们不能将一个实验阶段的技术使用的生产环境中
就我们团队而言,每个成员都有自己感兴趣的方向和领域,所以我们可以分工合作,探索各自的领域,再将成果分享出来,如果靠谱的话则可以在实验项目中先试验一下,最后才推广到其他项目.
3 浏览器兼容规范
前端团队应该根据针对应用所面对的用户情况、应用类型、开发成本、浏览器市场统计数据等因素,来制定自己的浏览器兼容规范,并写入应用使用手册中.
有了浏览器兼容规范,前端开发和兼容性测试就有理有据,避免争议; 同时它也是前端团队的一种对外声明,除非特殊要求,不符合浏览器兼容规范的浏览器,前端开发人员可以选择忽略。
3.1 确定兼容策略

渐进增强还是优雅降级. 这是两个不同方向策略,渐进增强保证低版本浏览器的体验,对于支持新特性的新浏览器提供稍好的体验;优雅降级则是相反的,为现代浏览器提供最好的体验,而旧浏览器则退而求之次,保证大概的功能.
选择不同的策略对前端开发的影响是比较大的,但是开发者没有选择权。确定哪种兼容策略,应该取决于用户比重,如果大部分用户使用的是现代浏览器,就应该使用优雅降级,反之选择渐进增强.
3.2 确定浏览器分级

YUI就曾提出浏览器分级原则,到今天这个原则依然适用。简单说就是将浏览器划分为多个等级,不同等级表示不同的支持程度. 比如我们团队就将浏览器划分为以下三个等级:
完全兼容: 保证百分百功能正常
部分兼容: 只能保证功能、样式与需求大致一致。对于一些不影响主体需求和功能的bug,会做降低优先级处理或者不处理。
不兼容: 不考虑兼容性
一般而言, 根据浏览器市场分布情况、用户占比、开发成本等因素划分等级.
举个例子,下面是我们对管理系统的兼容规范:

3.3 获取统计数据

百度统计是中文网站使用最为广泛的、免费的流量分析平台. 如上图,通过这些统计平台可以获取到终端真实的浏览器使用情况, 点击查看示例。
如果公司没有开发自己监控服务,还是建议使用这些免费的,有大厂支持的监控工具:
百度统计
友盟
Google Analytics 需要kx上网
可以从这些地方获取通用的浏览器统计数据:
百度流量研究院:主要提供国内浏览器统计
statcounter: 国际浏览器统计
浏览器发布年份统计
确定浏览器是否支持某个特性:
caniuse
MDN
4 项目组织规范
项目组织规范定义了如何组织一个前端项目, 例如项目的命名、项目的文件结构、版本号规范等等。尤其对于开源项目,规范化的项目组织就更重要了。
4.1 通用的项目组织规范
一个典型的项目组织规范如下:
README.md: 项目说明, 这个是最重要。你必须在这里提供关于项目的关键信息或者相关信息的入口. 一般包含下列信息:
简要描述、项目主要特性
运行环境/依赖、安装和构建、测试指南
简单示例代码
文档或文档入口, 其他版本或相关资源入口
联系方式、讨论群
许可、贡献/开发指南
CHANGELOG.md: 放置每个版本的变动内容, 通常要描述每个版本变更的内容。方便使用者确定应该使用哪个版本. 关于CHANGELOG的规范可以参考keep a changelog
package.json: 前端项目必须. 描述当前的版本、可用的命令、包名、依赖、环境约束、项目配置等信息.
.gitignore: 忽略不必要的文件,避免将自动生成的文件提交到版本库
.gitattributes: git配置,有一些跨平台差异的行为可能需要在这里配置一下,如换行规则
docs/: 项目的细化文档, 可选.
examples/: 项目的示例代码,可选.
build: 项目工具类脚本放置在这里,非必须。如果使用统一构建工具,则没有这个目录
dist/: 项目构建结果输出目录
src/: 源代码目录
tests/: 单元测试目录. 按照Jest规范,
__tests__目录通常和被测试的模块在同一个父目录下, 例如:/src __tests__/ index.ts a.ts index.ts a.ts 复制代码tests: 全局的测试目录,通常放应用的集成测试或E2E测试等用例
.env*: 项目中我们通常会使用
环境变量来影响应用在不同运行环境下的行为. 可以通过dotEnv来从文件中读取环境变量. 通常有三个文件:基本上这些文件的变动的频率很少,团队成员应该不要随意变动,以免影响其他成员。所以通常会使用
.env.*.local文件来覆盖上述的配置, 另外会设置版本库来忽略*.local文件..env通用的环境变量.env.development开发环境的环境变量.env.production生成环境的环境变量
对于开源项目通常还包括这些目录:
LICENSE: 说明项目许可
.github: 开源贡献规范和指南
CONTRIBUTING: 贡献指南, 这里一般会说明贡献的规范、以及项目的基本组织、架构等信息
CODE_OF_CONDUCT: 行为准则
COMMIT_CONVENTION: 提交信息规范,上文已经提及
ISSUE_TEMPLATE: Issue的模板,github可以自动识别这个模板
PULL_REQUEST_TEMPLATE: PR模板
任意一个优秀的开源项目都是你的老师,例如React、Vue...
4.2 目录组织的风格
上面只是一个通用的项目组织规范,具体源代码如何组织还取决于你们使用的技术栈和团队喜好。网上有很多教程,具体可以搜索怎么组织XX项目. 总结一下项目组织主要有三种风格:
Rails-style: 按照文件的类型划分为不同的目录,例如
components、constants、typings、views. 这个来源于Ruby-on-Rails框架,它按照MVC架构来划分不同的目录类型,典型的目录结构如下:app models # 模型 views # 视图 controllers # 控制器 helpers # 帮助程序 assets # 静态资源 config # 配置 application.rb database.yml routes.rb # 路由控制 locales # 国际化配置 environments/ db # 数据库相关 复制代码Domain-style: 按照一个功能特性或业务创建单独的目录,这个目录就近包含多种类型的文件或目录. 比如一个典型的Redux项目,所有项目的文件就近放置在同一个目录下:
Users/ Home/ components/ actions.js actionTypes.js constants.js index.js model.js reducer.js selectors.js style.css index.js rootReducer.js 复制代码Ducks-style: 优点类似于Domain-style,不过更彻底, 它通常将相关联的元素定义在一个文件下。Vue的单文件组件就是一个典型的例子,除此之外Vuex也是使用这种风格:
复制代码My Todo App!
大部分情况下, 我们都是使用混合两种方式的目录结构,例如:
src/
components/ # ???? 项目通用的‘展示组件’
Button/
index.tsx # 组件的入口, 导出组件
Groups.tsx # 子组件
loading.svg # 静态资源
style.css # 组件样式
...
index.ts # 到处所有组件
containers/ # ???? 包含'容器组件'和'页面组件'
LoginPage/ # 页面组件, 例如登录
components/ # 页面级别展示组件,这些组件不能复用与其他页面组件。
Button.tsx # 组件未必是一个目录形式,对于一个简单组件可以是一个单文件形式. 但还是推荐使用目录,方便扩展
Panel.tsx
reducer.ts # redux reduces
useLogin.ts # (可选)放置'逻辑', 按照????分离逻辑和视图的原则,将逻辑、状态处理抽取到hook文件
types.ts # typescript 类型声明
style.css
logo.png
message.ts
constants.ts
index.tsx
HomePage/
...
index.tsx # ????应用根组件
hooks/ # ????可复用的hook
useList.ts
usePromise.ts
...
index.tsx # 应用入口, 在这里使用ReactDOM对跟组件进行渲染
stores.ts # redux stores
contants.ts # 全局常量
复制代码框架官方很少会去干预项目的组织方式,读者可以参考下面这些资源来建立自己项目组织规范:
Redux 常见问题:代码结构
react-boilerplate
vuex 项目结构
React组件设计实践总结02 - 组件的组织
4.3 脚手架和项目模板
在将项目结构规范确定下来后,可以创建自己的脚手架工具或者项目模板,用于快速初始化一个项目或代码模板。
相关资源:
yeoman - 老牌的项目脚手架工具
plop - 代码生成辅助CLI
hygen - 类似于plop
generact - 生成React组件, 大部分组件的文件结构差不多, 这个工具就是帮助你生成这些重复的代码
babel-code-generator - 利用babel来实现更高级的代码编辑和自动生成
5 编码规范
网络上大部分‘前端规范’指的都是编码规范, 这是一种‘狭义’的前端规范.
统一的编码规范对团队项目的长远维护不无裨益. 一致性的代码规范可以增强团队开发协作效率、提高代码质量、减少遗留系统维护的负担。
最直接的好处就是避免写出糟糕的代码, 糟糕的代码与新手和老手关系不大,我也见过好处工作很多年的‘资深’工程师写出恶心的代码. 这样的代码随着项目的迭代会变得难以控制。
现代的Lint工具已经非常先进,几乎可以约束各种编码行为. 比如约束一个文件的长度、函数的复杂度、命名规范、注释规范、接口黑名单、DeadCode、检查简单的逻辑错误...
每一个程序员心目中对‘好代码’都有自己的主见,统一的编码规范可以像秦始皇统一战国一样,避免不必要的论战和争议。
其实与其自己建立前端编码规范,笔者推荐选择社区沉淀下来的规范. 这方面的资源非常多,所以本文也不武断地提出自己的规范建议. 推荐下面这些资源:
5.1 Javascript
Lint工具
ESLint - ????目前是社区最流行的、通用的Javascript Lint工具,Lint界的Babel。支持定制插件、preset。如果不想折腾可以选择它的一些预定义配置
TSLint - Typescript Lint工具。不过即将废弃了, 推荐使用ESLint
规范
JavaScript Standard Style - ???? 零配置的、‘标准’的Javascript编码规范. 底层基于Eslint。目前不支持Typescript
Airbnb JavaScript Style Guide - Airbnb的编码规范,业界标杆
类型检查. 暂时将它们归类到这里,因为它们同属于‘静态测试’
Typescript - ???? Javascript语言的超集,这是一门‘新’的语言,而不是简单的类型检查器. 不过它也支持原生Javascript的类型检查
Flow - Facebook出品的类型检查器,语法和Typescript类似. 个人推荐使用Typescript
5.2 HTML
Lint工具
HTMLHint
bootlint
规范
Code Guide
5.3 CSS
Lint工具
stylelint - ???? 通用的CSS编码检查工具,支持最新的CSS语法、CSS-in-js、以及其他类CSS语法(如SCSS、Less). 它也有预定义配置,推荐使用
规范
Airbnb CSS / Sass Styleguide
Code Guide
更多
方法论
BEM - ???? BEM命名规范
OOCSS
smacss
关于CSS可以学习Bootstrap这些传统UI框架,他们的代码组织性非常好, 值得学习
5.4 代码格式化

Prettier - ???? 关于代码格式化的所有东西都交给它吧!
基本上,所有代码格式相关的工作都可以交给Prettier来做,在这个基础上再使用Eslint覆盖语义相关的检查
5.5 集大成的
isobar 前端代码规范及最佳实践
凹凸实验室代码规范
百度FEX规范
老牌的NEC规范 - 有点老
5.6 特定框架风格指南
vue-style-guide
Airbnb React/JSX Style Guide
React组件设计实践总结 - 自荐一下笔者写的React组件设计相关实践
5.7 Code Review

上述的Lint工具和类型检查器, 可以约束代码风格、避免低级的语法错误。但是即使通过上面的Lint和类型检查,代码也可能未必是‘好代码’。
很多代码设计的‘最佳实践’是无法通过具象化的自动化工具或文档覆盖的, 这时候,'经验'或者'群体智慧'就派上用场了. 比如Code Review阶段会检查这些东西:
编程原则、设计思想. 例如符合SOLID原则? 是否足够DRY?接口设计是否简洁易扩展、
模块耦合程度、代码重复
代码健壮性。是否存在内存泄露、是否线程安全、是否有潜在性能问题和异常、错误是否被处理
代码的性能和效率。
是否有没有考虑到的场景?
如果你们是第一次推行Code Review, 可以建立一个检查列表,对照着进行检查。熟练后,心中自然无码。
Code Review有很多好处,比如:
Code Review可以让其他成员都熟悉代码。这样保证其他人都可以较快地接手你的工作,或者帮你解决某些问题
提高代码质量。毫无疑问. 一方面是主动性的代码质量提升,比如你的代码需要被人Review,会自觉尽量的提高代码质量;另一方面,其他成员可以检查提交方的代码质量
检查或提高新成员的编程水平。培养新人时,由于不信任它们提交的代码,我们会做一次Review检查代码是否过关。另一方面这是一次真实的案例讲解, 可以较快提高他们的能力
Code Review有两种方式: 一个提交时、一个是定时:
提交时. 大部分开源项目采用这种方式。通俗讲就是Pull Request。只有代码通过测试、和其他成员的Review才可以合进正式版本库。这种方式也称为‘阻塞式’代码检查,一般配合GitFlow使用。定时. 在项目完结后、项目的某个里程碑、或者固定的时间(每天、每个星期..). 团队成员聚在一起,回顾自己写的代码, 让其他成员进行审查
Code Review是比较难以推行的,不过这个也要看你们团队的情况,向我们钱少活多的团队,很少的时间去立马去兼顾其他成员的代码. 这时候定时Review会更有用,因为看起来更‘节省时间’.
而提交时Review则可以针对新人,比如你不信任他们的代码或者希望帮助他们提高编码能力。
相关资源:
Code Review最佳实践
是否要做Code Review?与BAT资深架构师争论之后的思考
一些Code Review工具
6 文档规范
文档对于项目开发和维护、学习、重构、以及知识管理非常重要。
和写测试一样、大部分开发人员会觉得写文档是一件痛苦的事情,不过只有时间能够证明它的价值。比如对于人员流动比较大的公司,如果有规范的文档体系,转交工作就会变动非常轻松.
广义的文档不单指‘说明文件’本身,它有很多形式、来源和载体,可以描述一个知识、以及知识形成和迭代的过程。例如版本库代码提交记录、代码注释、决策和讨论记录、CHANGELOG、示例代码、规范、传统文档等等
6.1 建立文档中心
我们公司是做IM的,所以之前我们优先使用'自己的'通讯工具来分享文档,这种方式有很大问题:
如果没有存档习惯(比如后端的API文档,因为由后端维护,一般不会主动去存档), 文档就可能丢失,而且通讯工具是不会永久保存你的文档的。当丢失文件就需要重新和文档维护者索要
糟糕的是文档维护者也是自己手动在本地存档的,这样导致的问题是: 如果工作转交,其他开发者需要花费一点时间来查找; 丢失了就真的没了
每一次文档更新要重新发一份, 这很麻烦,而且可能出现漏发的情况, 导致前后不一致.
关于知识的学习、以及有意义的讨论记录无法归档。
上面介绍的是一种非常原始的文档共享方式,很多小团队就是这么干的。
对于项目本身的文档建议放置在关联项目版本库里面,跟随项目代码进行迭代, 当我们在检索或跟踪文档的历史记录时,这种方式是最方便的。
然而很多应用是跨越多个团队的,每个团队都会有自己的文档输出(比如需求文档、系统设计文档、API文档、配置文档等等),而且通常也不会在一个版本库里。这时候文档就比较分散。所以一个统一的文档中心是很有必要。
我们公司现在选择的方案是Git+Markdown,也就是说所有的文档都放置在一个git版本库下。之前也考虑过商业的方案,譬如石墨文档、腾讯文档, 但管理层并不信任这些服务。
大概的git项目组织如下:
规范/
A应用/
产品/
设计/
API文档/
测试/
其他/
B应用/
复制代码Git版本库(例如Gitlab)有很多优势,例如历史记录跟踪、版本化、问题讨论(可以关联issue、或者提交)、多人协作、搜索、权限管理(针对不同的版本库或分组为不同人员设置权限)等等。
Git+Markdown可以满足开发者的大部分需求。但是Git最擅长的是处理纯文本文件、对于二进制是无能为力的,无法针对这些类型的文档进行在线预览和编辑。
所以Git+Markdown并不能满足多样化的文档处理需求,比如思维导图、图表、表格、PPT、白板等需求. 毕竟它不是专业的文档处理工具。所以对于产品、设计人员这些富文档需求场景,通常会按照传统方式或者更专业的工具对文档进行管理.
6.2 文档格式
毫无疑问,对于开发者来说,Markdown是最适合的、最通用的文档格式。支持版本库在线预览和变更历史跟踪。
下面这些工具可以提高Markdown的开发效率:
可视化编辑器
Visual Code: 大部分代码编辑都支持Markdown编辑和预览
Mou: Mac下的老牌编辑器
typora: 跨平台的Markdown编辑器,推荐
markdownlint: 编码检查器
扩展(Visual Studio Code):
Markdown All in One: All you need to write Markdown (keyboard shortcuts, table of contents, auto preview and more)
Markdown TOC: markdown 目录生成,我最常用的markdown插件
图表绘制工具:
drawio 基于Web的图表绘制工具、也有离线客户端
KeyNote/PPT 临时绘图也不错
6.3 定义文档的模板
关于如何写好文档,很难通过标准或规范来进行约束,因为它的主观性比较强, 好的文档取决于编辑者的逻辑总结能力、表达能力、以及有没有站在读者的角度去思考问题。
所以大部分情况下,我们可以为不同类型的文档提供一个模板,通过模板来说明一个文档需要包含哪些内容, 对文档的编写者进行引导.
例如一个API文档可能需要这些内容:
接口的索引
接口的版本、变更记录
用法和整体描述, 认证鉴权等等
描述具体的接口
功能说明
方法名称或者URI
参数和返回值定义
调用示例
注意事项等等
具体规范内容因团队而异,这里点到为止.
扩展:
中文技术文档的写作规范
React RFC模板
6.4 讨论即文档
一般情况下,对于一个开源项目来说除了官方文档,Issues也是一个很重要的信息来源。在Issue中我们可以获取其他开发者遇到的问题和解决方案、给官方反馈/投票、关注官方的最新动态、和其他开发者头脑风暴唇枪舌战等等。
所以相对于使用IM,笔者更推荐Issue这种沟通模式,因为它方便归档组织,索引和查找。而IM上的讨论就像流水一样,一去不复返。
当然两种工具的适用场景不一样,你拿IM的使用方式来使用Issue,Issue就会变得很水。Issue适合做有意义的、目的明确的讨论。所以要谴责一下在Github Issue上灌水的开发者。
关于Issue有很多妙用,推荐阅读这篇文章<如何使用 Issue 管理软件项目?>
现在很多开源项目都引入了RFC(请求意见稿)流程(参考React采用新的RFC流程, 以及Vue 最黑暗的一天), 这让开发者有‘翻身农奴、当家做主’的感觉,任何人都可以参与到一个开源项目重大事件的决策之中。每个RFC会说明决策的动机、详细设计、优缺点。除了官方文档之外,这些RFC是很有价值的学习资料。
我觉得如果不涉及机密,团队应该要让更多人参与到项目的设计和决策中,对于新手可以学到很多东西,而对于发起者也可能有考虑不周的情况。
那对于企业应用开发, Issue有用吗?
当然有用, 比如我们可以将这类话题从IM转移到Issue:
设计方案
决策/建议
新功能、新技术引入
重构
性能优化
规范
问题讨论
重大事件
计划或进度跟踪
...
另外Issue通常通过标签来进行分类,方便组织和检索:

6.5 注释即文档
必要和适量的注释对阅读源代码的人来说就是一个路牌, 可以少走很多弯路.
关于注释的一些准则,<阿里巴巴Java开发手册>总结得非常好, 推荐基于这个来建立注释规范。另外通过ESlint是可以对注释进行一定程度的规范。
6.6 代码即文档
现在有很多种工具支持从代码中解析和生成文档, 这可以给开发者简化很多文档维护的工作。
举个例子,我们经常会遇到修改了代码,但是文档忘记同步的情况。通过‘代码即文档’的方式至少可以保持文档和代码同步更新;另外很多工具会分析代码的数据类型,自动帮我们生成参数和返回值定义,这也可以减少很多文档编写工作以及出错率。
比如可以通过下面注释方式来生成组件文档:
import * as React from 'react';
import { Component } from 'react';
/**
* Props注释
*/
export interface ColumnProps extends React.HTMLAttributes {
/** prop1 description */
prop1?: string;
/** prop2 description */
prop2: number;
/**
* prop3 description
*/
prop3: () => void;
/** prop4 description */
prop4: 'option1' | 'option2' | 'option3';
}
/**
* 对组件进行注释
*/
export class Column extends Component {
render() {
return Column;
}
}
复制代码 相关的工具有:
API文档
jsdoc Javascript文档注释标准和生成器
tsdoc Typescript官方的注释文档标准
typedoc 基于tsdoc标准的文档生成器
Typescript
Javascript
后端接口文档
Swagger Restful接口文档规范
GraphQL: 这个有很多工具,例如graphiql, 集成了Playground和文档,很先进
Easy Mock 一个可视化,并且能快速生成模拟数据的服务
组件文档
vue-styleguidist
有更好的工具请评论告诉我
Docz
Styleguidist
StoryBook 通用的组件开发、测试、文档工具
React
Vue
7 UI设计规范

这是一个容易被忽略的规范类型。笔者就深受其苦,我们公司初期UI并不专业,没有所谓的设计规范,这就导致他们设计出来的产品都是东借西凑,前后不统一,多个应用之间的组件不能复用。这搞得我们不得不浪费时间,写很多定制化样式和组件,为他们的不专业买单.
关于UI设计规范的重要性有兴趣的读者可以看这篇文章<开发和设计沟通有多难?- 你只差一个设计规范>.
简单总结一下UI设计规范的意义:
提供团队协作效率(产品和开发)
提高组件的复用率. 统一的组件规范可以让组件更好管理
保持产品迭代过程中品牌一致性
建立一个定义良好的设计规范需要UI设计和开发的紧密配合,有时候也可以由我们前端来推动。
比如很多开源的UI框架,一开始都是开发者YY出来的,并没有设计参与,后来组件库慢慢沉淀成型,UI设计师才介入规范一下。
如果你们团队不打算制定自己的UI设计规范,则推荐使用现成的开源组件库:
Ant Design
Material-UI
Element UI
WeUI
Microsoft Fabric
这些开源组件库都经过良好的设计和沉淀, 而且配套了完善的设计原则、最佳实践和设计资源文件(Sketch 和 Axure),可以帮助业务快速设计出高质量的产品原型。
8 测试规范
测试是保障代码质量的重要手段,但是很少有人愿意在这里花太多时间。
比如笔者,我很少会去给业务代码和组件写单元测试,除非自己对代码非常没有信心,按照我的理念写测试不如将代码写得更简单一点,比如把一个函数拆分为更小的函数,保持单一职责。
但是对于一些底层、共享的代码模块还是有测试的必要的。
我在不知道测试什么?这些是你需要知道的软件测试类型和常识文章中,列举了一些开发者需要关注的测试类型和常识, 如果按照测试的阶段进行分类,大概是这样子的:
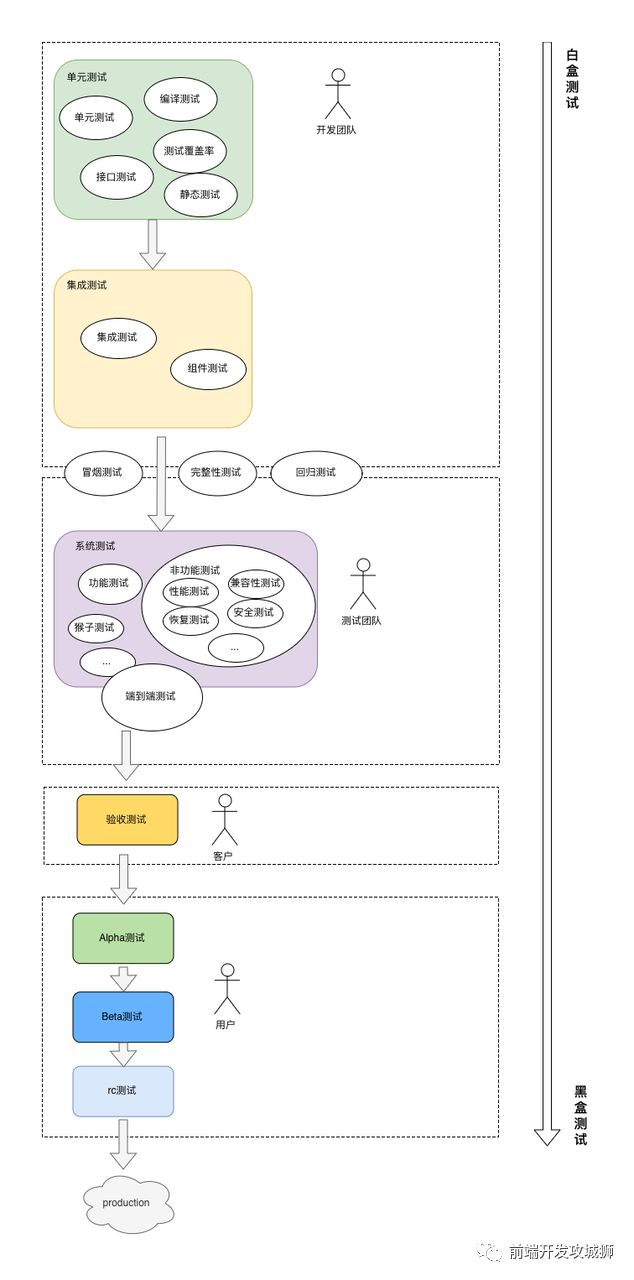
其中前端开发者需要关注的主要有以下几种测试类型:
单元测试: 对独立的软件模块进行测试
UI组件测试: 包括了快照(Snapshot)测试
集成测试: 在单元测试的基础上,将模块组合起来,测试它们的组合性
E2E测试: 在完整、真实的运行环境下模拟真实用户对应用进行测试。主要测试前端和后端的协调性
兼容性测试: 上面提到了浏览器兼容规范,在将版本提交给测试/发布之前,需要确保能符合兼容性要求
性能测试: 测试和分析是否存在性能问题
其他:
安全测试
SEO测试
因为对于小公司来说整个软件开发流程可能没有那么规范,比如很难构建一个完整的端对端测试环境,这些都不是前端团队可以操作的范围, 所以自动化测试很难推行。但是可以根据团队和业务情况逐步进行开展。
可实施性比较高的, 也比较简单是单元测试,所以本文也重点关注单元测试.
8.1 测试的流程
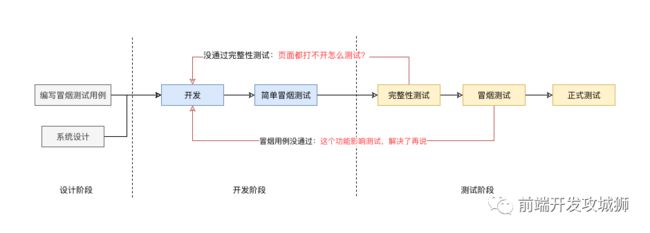
首先要定义一个合适的软件测试流程, 合适的测试流程可以降低开发和测试团队之间的沟通协作成本、提高测试效率。例如我们团队目前的测试流程:
8.2 单元测试
单元测试有很多好处, 比如:
提高信心,适应变化和迭代. 如果现有代码有较为完善的单元测试,在代码重构时,可以检验模块是否依然可以工作, 一旦变更导致错误,单元测试也可以帮助我们快速定位并修复错误
单元测试是集成测试的基础
测试即文档。如果文档不能解决你的问题,在你打算看源码之前,可以查看单元测试。通过这些测试用例,开发人员可以直观地理解程序单元的基础API
提升代码质量。易于测试的代码,一般都是好代码
测什么?
业务代码或业务组件是比较难以实施单元测试的,一方面它们比较多变、另一方面很多团队很少有精力维护这部分单元测试。所以通常只要求对一些基础/底层的组件、框架或者服务进行测试, 视情况考虑是否要测试业务代码
测试的准则:
推荐Petroware的Unit Testing Guidelines, 总结了27条单元测试准则,非常受用.
另外<阿里巴巴的Java开发手册>中总结的单元测试准则, 也不错,虽然书名是Java,准则是通用的.
单元测试指标:
一般使用测试覆盖率来量化,尽管对于覆盖率能不能衡量单元测试的有效性存在较多争议。
大部分情况下还是推荐尽可能提高覆盖率, 比如要求语句覆盖率达到70%;核心模块的语句覆盖率和分支覆盖率都要达到100%. 视团队情况而定
扩展:
测试覆盖(率)到底有什么用?
相关工具
Headless Browsers: 无头浏览器是网页自动化的重要运行环境。常用于功能测试、单元测试、网络爬虫
puppeteer
Headless Chromium
测试框架
组件测试
testing-library ????
Enzyme
Jest ????Facebook的单元测试框架. 零配置, 支持组件快照测试、模块Mock、Spy. 一般场景, 单元测试学它一个就行了
Intern
单元测试
AVA
Jasmine
Mocha
Tape
断言库
Chai
expect.js
should.js
Mock/Stubs/Spies
sinon.js
代码覆盖率
istanbul
基准测试
benchmark.js
jsperf.com
9 异常处理、监控和调试规范
很多开发者常常误用或者轻视异常的处理, 合理有效的异常处理可以提高应用的健壮性和可用性,另外还可以帮助开发者快速定位异常.
9.1 异常处理
<阿里巴巴的Java开发手册>中总结的异常处理规范对JavaScript的异常处理也很有参考意义,比如:
异常不要用来做流程控制,条件控制。
捕获异常是为了处理它,不要捕获了却什么都不处理而抛弃之,如果不想处理它,请将该异常抛给它的调用者。最外层的业务使用者,必须处理异常,将其转化为用户可以理解的内容。
catch时请分清稳定代码和非稳定代码,稳定代码指的是无论如何不会出错的代码。对于非稳定代码的catch尽可能进行区分异常类型,再做对应的异常处理。不要对大段代码进行try-catch
...
然后再根据JavaScript本身的异常处理特点总结一些规范行为, 例如:
不要throw非Error对象
不要忽略异步异常
全局监控Javascript异常
...
资源:
从1000+个项目中总结出来的前10个JavaScript错误, 以及如何避免它们
Javascript异常处理‘权威’指南
前端异常处理最佳实践
9.2 日志
对于前端来说,日志也不是毫无意义(很多框架性能优化建议在生产环境移除console)。尤其是在生产现场调试代码时,这时候可贵的控制台日志可以帮助你快速找到异常的线索.
不过通常我们只要保留必要的、有意义的日志输出,比如你不应该将console.log放到一个React渲染函数中、或者放到一个循环中, DDos式的日志信息并不能帮助我们定位问题,反而会影响运行的性能. 所以需要一个规范来约束日志输出行为, 比如:
避免重复打印日志
谨慎地记录日志, 划分日志级别。比如生产环境禁止输出debug日志;有选择地输出info日志;
使用前缀对日志进行分类, 例如:
[User] xxxx只记录关键信息, 这些信息可以帮助你诊断问题
...
扩展资源
debug 适合Node.js和浏览器的debug日志工具, 支持动态开启日志打印
vConsole 移动端调试利器
9.3 异常监控
因为程序跑在不受控的环境,所以对于客户端应用来说,异常监控在生产环境是非常重要的,它可以收集各种意料之外生产环境问题,帮助开发者快速定位异常。
异常监控通常会通过三种方式来收集异常数据:
全局捕获。例如使用window.onerror, 或者
unhandledrejection主动上报。在try/catch中主动上报.
用户反馈。比如弹窗让用户填写反馈信息.
和日志一样,不是所有‘异常’都应该上报给异常监控系统,譬如一些预料之内的‘异常’,比如用户输入错误、鉴权失败、网络错误等等. 异常监控主要用来上报一些意料之外的、或者致命性的异常.
要做好前端的异常监控其实并不容易,它需要处理这些东西:
浏览器兼容性。
碎片收集(breadcrumbs)。收集‘灾难’现场的一些线索,这些线索对问题诊断很重要。例如当前用户信息、版本、运行环境、打印的日志、函数调用栈等等
调用栈的转换。通常在浏览器运行的压缩优化过的代码,这种调用栈基本没什么可读性,通常需要通过SourceMap映射到原始代码. 可以使用这个库: source-map
数据的聚合。后端监控系统需要对前端上报的信息进行分析和聚合
对于小团队未必有能力开发这一套系统,所以推荐使用一些第三方工具。例如
Sentry ????免费基本够用
FunDebug 付费增强
扩展:
前端异常监控解决方案研究
搭建前端监控系统
10 前后端协作规范
前端是Web的一个细分领域,往往不能脱离后端而存在。所以和后端协作的时间是最长的.
10.1 协作流程规范
前后端团队经过长期的合作,一般可以总结出一条对于双方开发效率最优的协作流程. 将这个落实为规范,后面的团队成员都遵循这个步调进行协作。
一个典型的前后端协作流程如下:

需求分析。参与者一般有前后端、测试、以及产品. 由产品主持,对需求进行宣贯,接受开发和测试的反馈,确保大家对需求有一致的认知
前后端开发讨论。讨论应用的一些开发设计,沟通技术点、难点、以及分工问题.
设计接口文档。可以由前后端一起设计;或者由后端设计、前端确认是否符合要求
并行开发。前后端并行开发,在这个阶段,前端可以先实现静态页面; 或者根据接口文档对接口进行Mock, 来模拟对接后端接口
在联调之前,要求后端做好接口测试
真实环境联调。前端将接口请求代理到后端服务,进行真实环境联调。
10.2 接口规范
首先应该确定下来的是接口规范。其实使用哪种接口标准是其次,重要的是统一,且要满足前后端的开发效率要求.
笔者不建议后端去定义自己的接口标准,而应该去选择一些通用的、有标准定义接口形式, 例如:
RESTful: RESTful是目前使用最为广泛的API设计规范, 基于HTTP本身的机制来实现.
笔者个人是比较喜欢这个API规范,但是我发现很多开发者并不能真正(或者说没心思)理解它,设计出来的接口,跟我想象的相差甚远。换句话说,对于RESTful,开发者之间很难达成一致的理解,容易产生分歧。
因为是使用最广泛的API形式,所以社区上有很多工具来对RESTful接口进行文档化、测试和模拟.
JSONRPC 这是一种非常简单、容易理解的接口规范。相对于RESTful我更推荐这个,简单则不容易产生分歧,新手也可以很快接受.
GraphQL ????更为先进、更有前景的API规范。但是你要说服后端配合你使用这种标准可能很有难度
接口设计需要注意的点:
明确区分是正常还是异常, 严格遵循接口的异常原语. 上述接口形式都有明确的异常原语,比如JSONRPC,当出现异常时应该返回
错误对象响应,而不是在正常的响应体中返回错误代码. 另外要规范化的错误码, HTTP响应码就是一个不错的学习对象明确数据类型。很多后端写的接口都是string和number不分的,如果妥协的话、前端就需要针对这个属性做特殊处理,这也可能是潜在的bug
明确空值的意义。比如在做更新操作是,空值是表示重置,还是忽略更新?
响应避免冗余的嵌套。
接口版本化,保持向下兼容。就像我们上文的‘语义化版本规范’说的,对于后端来说,API就是公共的接口. 公共暴露的接口应该有一个版本号,来说明当前描述的接口做了什么变动,是否向下兼容。现在前端代码可能会在客户端被缓存,例如小程序。如果后端做了break change,就会影响这部分用户。
10.3 接口文档规范
后端通过接口文档向前端暴露接口相关的信息。通常需要包含这些信息:
版本号
文档描述
服务的入口. 例如基本路径
测试服务器. 可选
简单使用示例
安全和认证
具体接口定义
方法名称或者URL
方法描述
请求参数及其描述,必须说明类型(数据类型、是否可选等)
响应参数及其描述, 必须说明类型(数据类型、是否可选等)
可能的异常情况、错误代码、以及描述
请求示例,可选
人工维护导致的问题:
上文‘代码即文档’就提到了人工维护接口文档可能导致代码和文档不同步问题。
如果可以从代码或者规范文档(例如OpenAPI这类API描述规范)中生成接口文档,可以解决实现和文档不一致问题, 同时也可以减少文档编写和维护的投入.
10.4 接口测试与模拟
为了做到高效率的前后端并行开发,接口的测试与模拟是必要的。
前端要求后端在联调之前,需要测试验证好自己的接口是否可以正常工作。而不是在联调期间,把前端当‘接口测试员’,阻塞接口联调进度
另外前端需要在后端接口未准备好之前,通过接口模拟的方式,来编写业务逻辑代码。
针对接口测试与模拟,存在下图这样一个理想的模型:

一切从定义良好的接口文档出发,生成Mock Server和Mock Client, Mock Server给前端提供模拟数据,而Mock Client则辅助后端对它们的接口进行测试.
资源:
RESTful
Swagger 这是最为接近上面理想模型的一个解决方案
JSON Server 快速生成JSON mock服务器
Easy Mock 可视化的、在线的接口mock服务
GraphQl
GraphQL Faker
graphql-tools
模拟数据生成
faker.js ????强大的模拟数据生成工具,支持Node和浏览器
Mock.js 数据生成和模拟工具
11 培训/知识管理/技术沉淀
我觉得一个团队的知识管理是非常重要的. 你要问一个刚入行的新手加入团队希望得到什么?很多人的回答是'学习', 希望自己的技术可以更加精进, 钱倒还是其次。
然而现实是目前很多公司的氛围并不是这样的,一天到晚写业务代码、工作量大、每天做重复的事情,而且还加班,工作多年技术也没感觉有多少进步, 确实会让人非常沮丧。包括笔者也是这样的。
所以为了改善这种情况,我来聊聊最近在‘小团队’做的一些尝试.
11.1 新人培训
如果团队有规范的新成员培训手册,可以节省很多培训的时间,避免每次重复口述一样的内容。培训手册包含以下内容:
产品架构与组织架构. 介绍公司背景和产品,一般组织的团队结构和产品的架构是相关联的. 以笔者所在公司为例, 主要产品是即时通信:
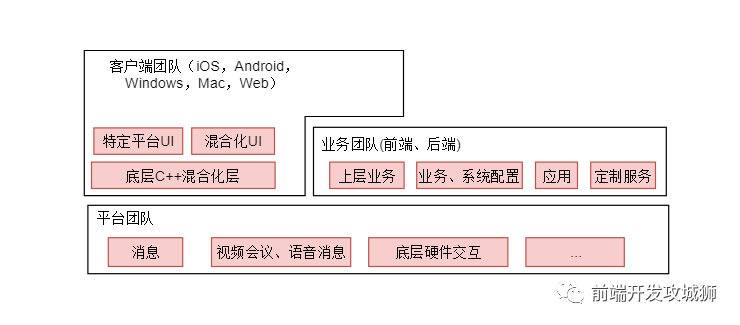
产品研发流程: 介绍产品开发和迭代会涉及到的流程、以及团队之间的协作衔接,例如:

工作范围: 团队成员的职责范围
建立资源索引: 开发需要设计到的资源,比如各种文档地址、研发系统入口(例如gitlab、bug跟踪系统、文件共享、发布平台、开发/测试环境、监控系统)、协作规范等等。将这些资源整理好可以减少不必要的沟通成本
规范: 即本文的主体'前端协作规范'。有规范可循,可以让成员以较快的速度入手开发、同时也减少培训成本投入。
培训手册将可以文档具象化的内容整理为文档,和上文说到的Code Review一样,一些东西无法通过文档来说明,所以我们一般会搭配一个‘培训导师’,在试用期间,一对一辅导。
11.2 营造技术氛围
鼓励成员写技术博客,或者建立自己的团队专栏. 写一篇好的文章不容易
鼓励参与开源项目
建立面试题库 组织一起解一些面试题或算法题,加深对知识点的理解
定期的专题分享. 鼓励团队成员定期进行专题学习和研究,编写技术博客,并将学习的成果分享给其他成员. 这是一种抱团取暖的学习方式,旨在帮助团队成员一起学习和成长。
比如开发老手可以分享自己的经验,研究更深层次的技术;新手则可以研究某些开发技巧、新技术,例如CSS Grid,svg动画等等。推荐团队成员有个明确的研究领域,这样分工合作可以学习到更多东西.
专题怎么来?
专题请求. 可以请求其他成员完成专题,比如比较深的知识,可以要求团队比较有经验的进行学习分享
学习总结.
项目回顾
难点攻克
项目规范
工具使用
落实和完善开发规范. 规范本身就是团队知识沉淀的一种直接输出
图书分享. 和离散的文章或教程相比,图书的知识会比较系统,另外很多经典的图书是要静下来好好欣赏的。
鼓励重构和持续优化代码
抽象一套基础库或框架,减少重复工作, 提高工作效率. 不加班先从提高工作效率开始