浅谈C++中的多线程(一)
本篇文章围绕以下几个问题展开:
- 何为进程?何为线程?两者有何区别?
- 何为并发?C++中如何解决并发问题?C++中多线程的语言实现?
- 同步互斥原理以及多进程和多线程中实现同步互斥的两种方法
- Qt中的多线程应用
引入
传统的C++(C++98)中并没有引入线程这个概念。linux和unix操作系统的设计采用的是多进程,进程间的通信十分方便,同时进程之间互相有着独立的空间,不会污染其他进程的数据,天然的隔离性给程序的稳定性带来了很大的保障。而线程一直都不是linux和unix推崇的技术,甚至有传言说linus本人就非常不喜欢线程的概念。随着C++市场份额被Java、Python等语言所蚕食,为了使得C++更符合现代语言的特性,在C++11中引入了多线程与并发技术。
一.何为进程?何为线程?两者有何区别?
1.何为进程?
进程是一个应用程序被操作系统拉起来加载到内存之后从开始执行到执行结束的这样一个过程。简单来说,进程是程序(应用程序,可执行文件)的一次执行。进程通常由程序、数据和进程控制块(PCB)组成。比如双击打开一个桌面应用软件就是开启了一个进程。
传统的进程有两个基本属性:可拥有资源的独立单位;可独立调度和分配的基本单位。对于这句话我的理解是:进程可以获取操作系统分配的资源,如内存等;进程可以参与操作系统的调度,参与CPU的竞争,得到分配的时间片,获得处理机(CPU)运行。
进程在创建、撤销和切换中,系统必须为之付出较大的时空开销,因此在系统中开启的进程数不宜过多。比如你同时打开十几个应用软件试试,电脑肯定会卡死的。于是紧接着就引入了线程的概念。
2.何为线程?
线程是进程中的一个实体,是被系统独立分配和调度的基本单位。也有说,线程是CPU可执行调度的最小单位。也就是说,进程本身并不能获取CPU时间,只有它的线程才可以。
引入线程之后,将传统进程的两个基本属性分开了,线程作为调度和分配的基本单位,进程作为独立分配资源的单位。我对这句话的理解是:线程参与操作系统的调度,参与CPU的竞争,得到分配的时间片,获得处理机(CPU)运行。而进程负责获取操作系统分配的资源,如内存。
线程基本上不拥有资源,只拥有一点运行中必不可少的资源,它可与同属一个进程的其他线程共享进程所拥有的全部资源。
线程具有许多传统进程所具有的特性,故称为“轻量型进程”。同一个进程中的多个线程可以并发执行。
3.进程和线程的区别?
其实根据进程和线程的定义已经能区分开它们了。
线程分为用户级线程和内核支持线程两类,用户级线程不依赖于内核,该类线程的创建、撤销和切换都不利用系统调用来实现;内核支持线程依赖于内核,即无论是在用户进程中的线程,还是在系统中的线程,它们的创建、撤销和切换都利用系统调用来实现。
但是,与线程不同的是,无论是系统进程还是用户进程,在进行切换时,都要依赖于内核中的进程调度。因此,无论是什么进程都是与内核有关的,是在内核支持下进程切换的。尽管线程和进程表面上看起来相似,但是他们在本质上是不同的。
根据操作系统中的知识,进程至少必须有一个线程,通常将此线程称为主线程。
进程要独立的占用系统资源(如内存),而同一进程的线程之间是共享资源的。进程本身并不能获取CPU时间,只有它的线程才可以。
4.其他
进程在创建、撤销和切换过程中,系统的时空开销非常大。用户可以通过创建线程来完成任务,以减少程序并发执行时付出的时空开销。例如可以在一个进程中设置多个线程,当一个线程受阻时,第二个线程可以继续运行,当第二个线程受阻时,第三个线程可以继续运行......。这样,对于拥有资源的基本单位(进程),不用频繁的切换,进一步提高了系统中各种程序的并发程度。
在一个应用程序(进程)中同时执行多个小的部分,这就是多线程。这小小的部分虽然共享一样的数据,但是却做着不同的任务。
二.何为并发?C++中如何解决并发问题?C++中多线程的语言实现?
1.何为并发?
1.1.并发
在同一个时间里CPU同时执行两条或多条命令,这就是所谓的并发。
1.2.伪并发
伪并发是一种看似并发的假象。我们知道,每个应用程序是由若干条指令组成的。在现代计算机中,不可能一次只跑一个应用程序的命令,CPU会以极快的速度不停的切换不同应用程序的命令,而让我们看起来感觉计算机在同时执行很多个应用程序。比如,一边听歌,一边聊天,还能同时打游戏,我们误以为这是并发,其实只是一种伪并发的假象。
主要,以前的计算机都是单核CPU,就不太可能实现真正的并发,只能是不同的线程占用不同的时间片,而CPU在各个线程之间来回快速的切换。
伪并发的模型大致如下:

整个框代表一个CPU的运行,T1和T2代表两个不同的线程,在执行期间,不同的线程分别占用不同的时间片,然后由操作系统负责调度执行不同的线程。但是很明显,由于内存、寄存器等等都是有限的,所以在执行下一个线程的时候不得不把上一个线程的一些数据先保存起来,这样下一次执行该线程的时候才能继续正确的执行。
这样多线程的好处就是更大的利用CPU的空闲时间,而缺点就是要付出一些其他的代价,所以多线程是否一定要单线程快呢?答案是否定的。这个道理就像,如果有3个程序员同时编写一个项目,不可避免需要相互的交流,如果这个交流的时间远远大于编码的时间,那么抛开代码质量来说,可能还不如一个程序猿来的快。
理想的并发模型如下:
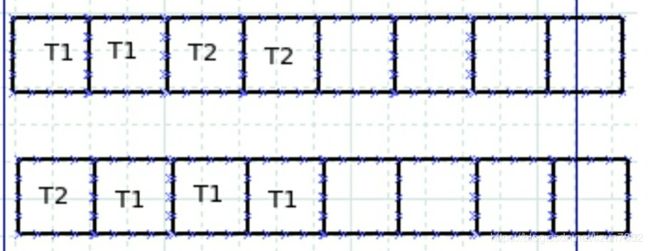
可以看出,这是真正的并发,真正实现了时间效率上的提高。因为每一个框代表一个CPU的运行,所以真正实现并发的物理基础的多核CPU。
1.3.并发的物理基础
慢慢的,发展出了多核CPU,这样就为实现真并发提供了物理基础。但这仅仅是硬件层面提供了并发的机会,还需要得到语言的支持。像C++11之前缺乏对于多线程的支持,所写的并发程序也仅仅是伪并发。
也就是说,并发的实现必须首先得到硬件层面的支持,不过现在的计算机已经是多核CPU了,我们对于并发的研究更多的是语言层面和软件层面了。
2.C++中如何解决并发问题?
显然通过多进程来实现并发是不可靠的,C++中采用多线程实现并发。
线程算是一个底层的,传统的并发实现方法。C++11中除了提供thread库,还提供了一套更加好用的封装好了的并发编程方法。
C++中更高端的并发方法:(此内容因本人暂未理解,暂时搁置,待理解之时会前来更新,请读者朋友谅解)
3.C++中多线程的语言实现?
这里以一个典型的示例——求和函数来讲解C++中的多线程。
单线程版:
#include
#include
#include
using namespace std;
int GetSum(vector::iterator first,vector::iterator last)
{
return accumulate(first,last,0);//调用C++标准库算法
}
int main()
{
vector largeArrays;
for(int i=0;i<100000000;i++)
{
if(i%2==0)
largeArrays.push_back(i);
else
largeArrays.push_back(-1*i);
}
int res = GetSum(largeArrays.begin(),largeArrays.end());
return 0;
} 多线程版:
#include
#include
#include
#include
using namespace std;
//线程要做的事情就写在这个线程函数中
void GetSumT(vector::iterator first,vector::iterator last,int &result)
{
result = accumulate(first,last,0); //调用C++标准库算法
}
int main() //主线程
{
int result1,result2,result3,result4,result5;
vector largeArrays;
for(int i=0;i<100000000;i++)
{
if(i%2==0)
largeArrays.push_back(i);
else
largeArrays.push_back(-1*i);
}
thread first(GetSumT,largeArrays.begin(),
largeArrays.begin()+20000000,std::ref(result1)); //子线程1
thread second(GetSumT,largeArrays.begin()+20000000,
largeArrays.begin()+40000000,std::ref(result2)); //子线程2
thread third(GetSumT,largeArrays.begin()+40000000,
largeArrays.begin()+60000000,std::ref(result3)); //子线程3
thread fouth(GetSumT,largeArrays.begin()+60000000,
largeArrays.begin()+80000000,std::ref(result4)); //子线程4
thread fifth(GetSumT,largeArrays.begin()+80000000,
largeArrays.end(),std::ref(result5)); //子线程5
first.join(); //主线程要等待子线程执行完毕
second.join();
third.join();
fouth.join();
fifth.join();
int resultSum = result1+result2+result3+result4+result5; //汇总各个子线程的结果
return 0;
} C++11中引入了多线程技术,通过thread线程类对象来管理线程,只需要#include
thread first(线程函数名,参数1,参数2,......);每个线程有一个线程函数,线程要做的事情就写在线程函数中。
根据操作系统上的知识,一个进程至少要有一个线程,在C++中可以认为main函数就是这个至少的线程,我们称之为主线程。而在创建thread对象的时候,就是在这个线程之外创建了一个独立的子线程。这里的独立是真正的独立,只要创建了这个子线程并且开始运行了,主线程就完全和它没有关系了,不知道CPU会什么时候调度它运行,什么时候结束运行,一切都是独立,自由而未知的。
因此下面要讲两个必要的函数:join()和detach()
如:thread first(GetSumT,largeArrays.begin(),largeArrays.begin()+20000000,std::ref(result1)); first.join();
这意味着主线程和子线程之间是同步的关系,即主线程要等待子线程执行完毕才会继续向下执行,join()是一个阻塞函数。
而first.detach(),当然上面示例中并没有应用到,则表示主线程不用等待子线程执行完毕,两者脱离关系,完全放飞自我。这个一般用在守护线程上:有时候我们需要建立一个暗中观察的线程,默默查询程序的某种状态,这种的称为守护线程。这种线程会在主线程销毁之后自动销毁。
C++中一个标准线程函数只能返回void,因此需要从线程中返回值往往采用传递引用的方法。我们讲,传递引用相当于扩充了变量的作用域。
我们为什么需要多线程,因为我们希望能够把一个任务分解成很多小的部分,各个小部分能够同时执行,而不是只能顺序的执行,以达到节省时间的目的。对于求和,把所有数据一起相加和分段求和再相加没什么区别。
PS:因篇幅限制,本篇文章先写到这里,余下内容会在下一篇文章中讲解。谢谢读者朋友们的阅读,欢迎提出宝贵意见,期待与您交流!