红帽(redhat linux)6.1之高可用性(High Availability)配置实例
高可用性(HighAvailability)配置实例
前言
RHEL6上,每个节点至少要1GB的内存,只支持x86_64位平台,32位平台不再支持。配置集群的服务器需要配置时间服务器,以保证集群服务器的时间一致。只有两个节点的集群默认不启用仲裁机制。
一、架构安排
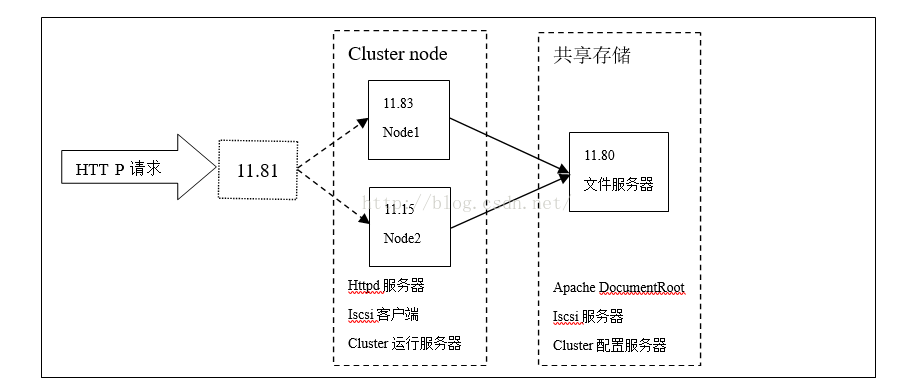
准备3台linux机器,5个IP地址,其中:
机器:
28.6.11.83是HP服务器【物理机】
28.6.11.15是IBM x346型号服务器【物理机】
28.6.11.80是VMWARE虚拟机
公有网络:
28.6.11.81:虚拟IP地址,没有与具体的物理机对应,作为集群服务器的IP地址资源使用,通过该IP和相应的端口访问集群提供的HTTP服务。
28.6.11.83:集群服务器节点1,比集群节点28.6.11.15具有更高的优先权。
28.6.11.15:集群服务器节点2,比集群节点28.6.11.83的优先权低。
私有网络:
28.6.11.86:为28.6.11.83的HP iLo Device【Fence Device】设备配置的IP地址。
28.6.11.82:为28.6.11.15的IPMI Lan Device【Fence Device】设备配置的IP地址。
注:建议fence设备地址使用相同的网段,集群的运行需要借助多播方式发送心跳信号,须查看交换机是否支持多播通信。心跳信号量比较大,建议使用私有网络。一般私有网络和公有网络分处不同网段,私有网络必须使用专有的维护链接才可以访问。
二、Fence Device配置
本节所需安装软件可以在安装光盘的Packages目录直接安装,不需要配置yum源。
(一)HP iLo Device配置
首先接通HP服务器的iLo端口和交换机的链路连接,并把相应交换机端口设置为11网段,然后重新启动机器,在启动界面进行如下的配置:

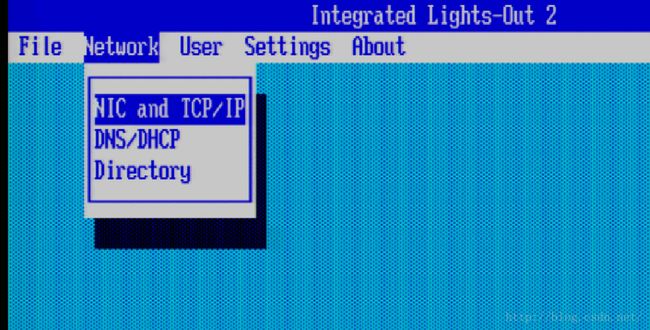
在如上的界面中按【F8】键,进入iLo配置界面,按照下面的图示配置iLo的IP地址:

按【F10】保存IP配置信息。
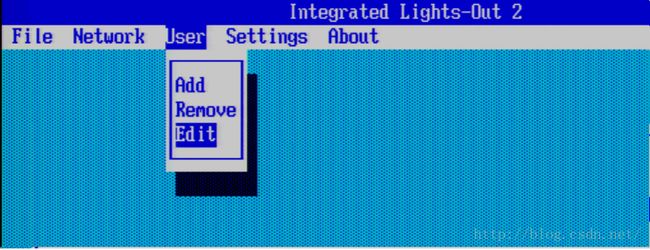
按照下面的图示,配置iLo的认证用户:
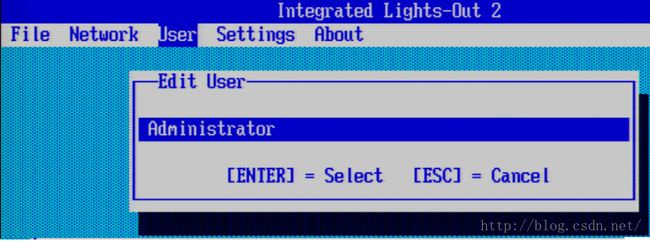

【F10】保存认证用户配置信息。
退出iLo配置界面完成iLo的配置,让机器重新正常启动,再进行如下的配置信息验证:

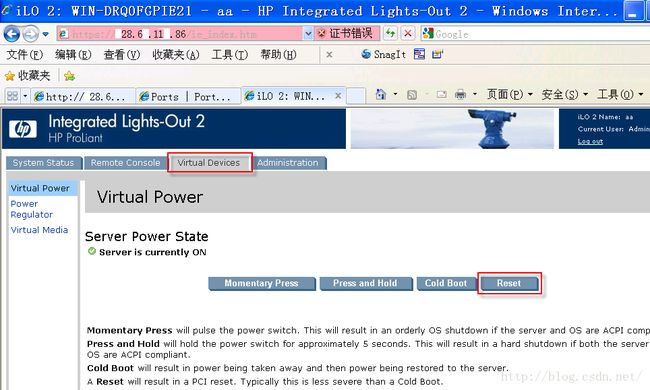
手动测试iLo是否可以手动重启机器。
可以访问iLo界面并可以手动重启机器说明iLo配置成功。
(二)IBM IPMI Lan Device配置
IPMI是Intel公司推出的远程管理解决方案,也称为Baseboard Management Cards (BMCs) ,可以在服务器通电(没有启动操作系统)情况下对服务器进行远程管理。Dell的 Baseboard Management Controller (BMC) 是IPMI的一个实现。该BMC可以通过主板集成的第一块网卡实现网络管理。并且这个BMC管理IP是独立的IP地址(需要单独占用)。
有两种方式配置IPMI,一种是服务器启动时进行设置,可以激活IPMI远程访问;另一种方式是安装了Linux操作系统,在Linux操作系统中使用ipmitool来设置(前提是已经加载了一 些ipmi内核模块)。本实例中两种方法结合使用进行IPMI的设置。前者用于IP地址等信息的设置,后者用于用户信息等的设置。
通过IBM红皮书网站http://www.redbooks.ibm.com/redbooks/SG246495/wwhelp/wwhimpl/js/html/wwhelp.htm 查询得知如下:

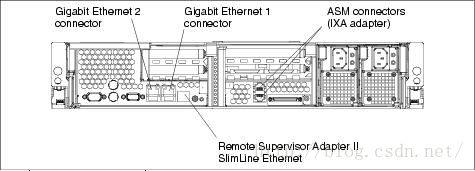
Figure2-9 Rear ports of the xSeries 346
IBM x346型号机器的BMC端口和网卡1共用。在本实例中本机器的28.6.11.15 IP使用的是2号网卡,因此接通该服务器的网卡1和交换机的链路连接,并把相应交换机端口设置为11网段。打开本机console,重启机器进行下面的配置。
按【F1】进入【Setup】界面,如下:
选择【AdvancedSetup】,进入如下界面:
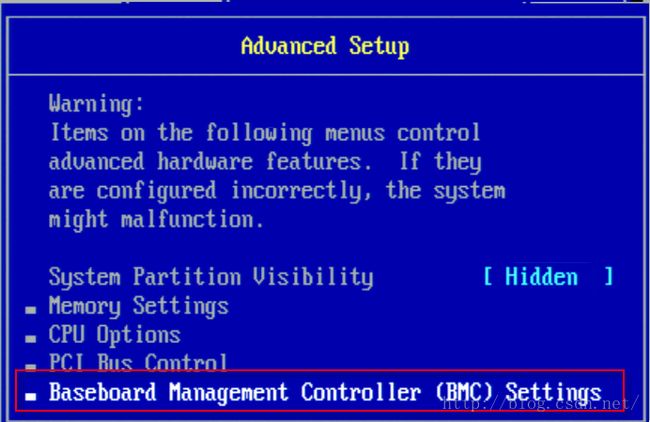
选择【BaseboardManagement Controller(BMC) Settings】进入如下界面:

确保如上设置,并选择【BMCNetwork Configuration】进入如下界面:
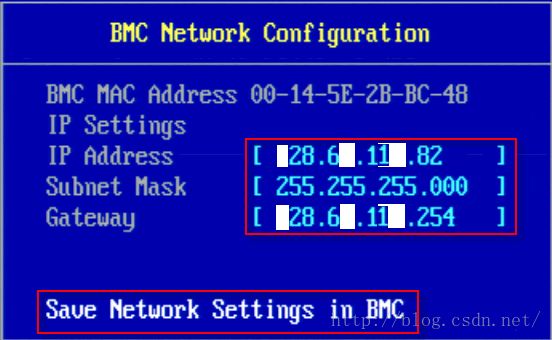
确保如上设置,并选择【SaveNetwork Settings in BMC】进行保存,如下:

点击【Enter】按钮进行保存。按【Escape】键退到如下的界面:
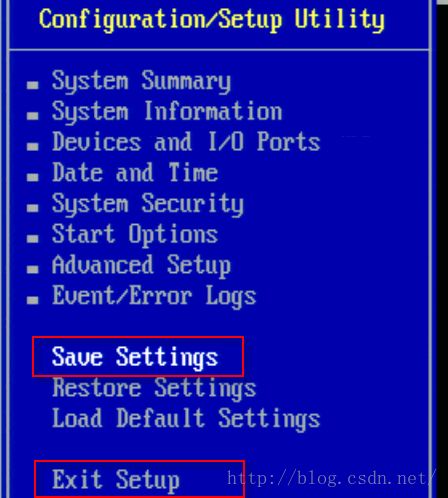
保存退出后,重新启动机器。可以在机器28.6.11.83上进行是否可以ping通28.6.11.82的测试:
[root@linux1183 ~]# ping 28.6.11.82
进入操作系统后,在28.6.11.15上安装如下的软件包:
freeipmi-bmc-watchdog-0.7.16-3.el6.x86_64
ipmitool-1.8.11-7.el6.x86_64
freeipmi-0.7.16-3.el6.x86_64
freeipmi-ipmidetectd-0.7.16-3.el6.x86_64
同时在28.6.11.83上安装如下的软件包,以方便后面的异机测试:
ipmitool-1.8.11-7.el6.x86_64
为加强BMC安全,禁止非授权用户重启服务器。需要修改默认的SNMP通讯串,null用 户密码,以及管理员用户密码。如下:
修改默认的SNMP通讯串:
/usr/bin/ipmitool -I open lan set 1 snmp COMUNIATION
设置null用户的密码
/usr/bin/ipmitool -I open lan set 1 password PASSWD
设置管理员用户密码前,先查看管理员用户名
| [root@linux1115 ~]# ipmitool user list 1 ID Name Callin Link Auth IPMI Msg Channel Priv Limit 1 true false true NO ACCESS 2 USERID true true true ADMINISTRATOR |
确保【Link Auth】和【IPMI Msg】为true ,如果是false,使用如下命令进行修改:【ipmitool user enable id号】。从上面的命令输出得知,具有管理员权限的用户的ID是2,用户名是USERID(该用户名可以修改),为该用户设置密码为PASSWD:
/usr/bin/ipmitool -I open user set password 2 PASSWD
使用如下的命令查看IPMI的设置信息【该命令在本机上执行】:
| [root@linux1115 ~]# ipmitool -I open lan print 1 Set in Progress : SetComplete Auth Type Support : NONEMD2 MD5 PASSWORD Auth Type Enable :Callback : :User : MD2 MD5 PASSWORD :Operator : MD2 MD5 PASSWORD :Admin : MD2 MD5 PASSWORD :OEM : IP Address Source :Static Address IP Address : 28.6.11.82 Subnet Mask :255.255.255.0 MAC Address :00:14:5e:2b:bc:48 SNMP Community String :COMUNIATION IP Header : TTL=0x40 Flags=0x40 Precedence=0x00TOS=0x10 Default Gateway IP : 28.6.11.254 Default Gateway MAC :00:00:00:00:00:00 Backup Gateway IP :0.0.0.0 Backup Gateway MAC :00:00:00:00:00:00 CipherSuite Priv Max : Not Available |
使用如下命令检查整个IPMI设置是否正确,如下:
| [root@linux1183 ~]# ipmitool -I lan -U USERID -H 28.6.11.82 -achassis power status Password: ChassisPower is on |
再使用如下命令看是否可以重启机器:
ipmitool -I lan -U USERID -H 28.6.11.82 -achassis power cycle
是否可以在28.6.11.83上对28.6.11.15进行重启:
[root@linux1183 ~]#ipmitool -I lan -U USERID-H 28.6.11.82 -a chassis power cycle
如果可以重启,说明配置正确无误。
三、iscsi配置
机器准备好后,并关掉这台机器的防火墙,在每台机器的/etc/hosts文件中加入如下内容:
| 28.6.11.83 linux1183.domain.com linux1183 28.6.11.15 linux1115.domain.com linux1115 28.6.11.80linux1180.domain.com linux1180 |
注:建议把集群中的机器设置为同一个Domain。
(一)iscsi服务端配置
1、在28.6.11.80上,另外再增加一块8G的磁盘sdb,用fdisk划分为一个分区/dev/sdb1,准备用作iscsi共享存储,用于存放apache页面。另外再增加一块大小不少于100M的硬盘/dev/sdc,通过iscsi共享给linux1183和linux1115访问,做集群的qdisk使用。
| [root@linux1180 ~]# fdisk -l
Disk /dev/sda: 10.7 GB, 10737418240 bytes 255 heads, 63 sectors/track, 1305 cylinders Units = cylinders of 16065 * 512 = 8225280bytes Sector size (logical/physical): 512 bytes /512 bytes I/O size (minimum/optimal): 512 bytes / 512bytes Disk identifier: 0x000673ff
Device Boot Start End Blocks Id System /dev/sda1 * 1 64 512000 83 Linux Partition 1 does not end on cylinderboundary. /dev/sda2 64 1306 9972736 8e Linux LVM
Disk /dev/sdc: 209 MB, 209715200 bytes 64 heads, 32 sectors/track, 200 cylinders Units = cylinders of 2048 * 512 = 1048576bytes Sector size (logical/physical): 512 bytes /512 bytes I/O size (minimum/optimal): 512 bytes / 512bytes Disk identifier: 0x00000000
Disk /dev/sdc doesn't contain a validpartition table
Disk /dev/sdb: 8589 MB, 8589934592 bytes 255 heads, 63 sectors/track, 1044 cylinders Units = cylinders of 16065 * 512 = 8225280bytes Sector size (logical/physical): 512 bytes /512 bytes I/O size (minimum/optimal): 512 bytes / 512bytes Disk identifier: 0x29abae1b
Device Boot Start End Blocks Id System /dev/sdb1 1 1044 8385898+ 83 Linux |
2、安装scsi-target-utils软件提供iscsi服务
| [root@linux1180 ~]# yum installscsi-target-utils |
3、修改/etc/tgt/targets.conf,添加:
| backing-store /dev/sdb1 backing-store /dev/sdc |
4、重启tgtd服务,并将其设为开机启动:
| [root@linux1180~]# /etc/init.d/tgtd restart [root@linux1180~]# chkconfig tgtd on [root@linux1180~]# chkconfig tgtd --list tgtd 0:off 1:off 2:on 3:on 4:on 5:on 6:off |
4、查看服务状态,可以看到已经提供了一个7G的ISCSI LUN 1卷
| [root@linux1180~]# tgt-admin --show Target 1:iqn.2011-06.com.domain:server.target1 System information: Driver: iscsi State: ready LUN information: LUN: 0 Type: controller SCSI ID: IET 00010000 SCSI SN: beaf10 Size: 0 MB, Block size: 1 Online: Yes Removable media: No Readonly: No Backing store type: null Backing store path: None Backing store flags: LUN: 1 Type: disk SCSI ID:IET 00010001 SCSI SN:beaf11 Size: 8587MB, Block size: 512 Online: Yes Removablemedia: No Readonly:No Backingstore type: rdwr Backing store path: /dev/sdb1 Backingstore flags: LUN: 2 Type: disk SCSI ID:IET 00010002 SCSI SN:beaf12 Size: 210MB, Block size: 512 Online: Yes Removablemedia: No Readonly:No Backingstore type: rdwr Backingstore path: /dev/sdc Backingstore flags: Account information: ACL information: ALL |
6、打开防火墙端口3260或者关闭防火墙
(二)iscsi客户端配置
1、在28.6.11.83安装iscsi客户端软件iscsi-initiator-utils
| [root@linux1183 ~]# yum install iscsi-initiator-utils |
2、发现服务器28.6.11.80的iscsi共享卷
| [root@linux1183~]# iscsiadm -m discovery -t sendtargets -p linux1180 28.6.11.80:3260,1iqn.2011-06.com.domain:server.target1 |
2、登录iscsi存储
| [root@linux1183~]# iscsiadm -m node -T iqn.2011-06.com.domain:server.target1 -p 28.6.11.80:3260-l Logging in to[iface: default, target: iqn.2011-06.com.domain:server.target1, portal: 28.6.11.80,3260] Loginto [iface: default, target: iqn.2011-06.com.domain:server.target1, portal: 28.6.11.80,3260]successful. |
| 使用iscsiadm -m node -T target名称 -p targetIP地址:端口号 –login 命令 卸载ISCSI存储命令: iscsiadm-m node -T iqn.2011-06.com.domain:server.target1 -p 28.6.11.80:3260 -u |
4、查看本地存储,可以发现/dev/sdb
| [root@linux1183~]# fdisk -l
Disk/dev/cciss/c0d0: 220.1 GB, 220122071040 bytes 255 heads, 32sectors/track, 52687 cylinders Units =cylinders of 8160 * 512 = 4177920 bytes Sector size(logical/physical): 512 bytes / 512 bytes I/O size(minimum/optimal): 512 bytes / 512 bytes Diskidentifier: 0x517b413f
Device Boot Start End Blocks Id System /dev/cciss/c0d0p1 * 1 126 512000 83 Linux Partition 1does not end on cylinder boundary. /dev/cciss/c0d0p2 126 5266 20971520 83 Linux /dev/cciss/c0d0p3 5266 7836 10485760 82 Linux swap / Solaris
Disk /dev/sdb: 8587 MB, 8587160064 bytes 64 heads, 32 sectors/track, 8189 cylinders Units = cylinders of 2048 * 512 = 1048576 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x00000000
Disk /dev/sdb doesn't contain a valid partition table
Disk /dev/sdc: 209 MB, 209715200 bytes 7 heads, 58 sectors/track, 1008 cylinders Units = cylinders of 406 * 512 = 207872 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x00000000 Disk /dev/sdc doesn't contain a valid partition table |
【在28.6.11.15上执行同上的操作命令】
注:在上面的第四步查看本地存储时,看到的有可能不是/dev/sdb,有可能是/dev/sda或者/dev/sdc。出现这种现象是因为HP服务器和IBM服务器的硬盘编号方法不同所致,并不影响操作和使用。
四、集群软件安装配置
分为集群节点和配置管理器(Luci,RHCS的web管理工具,仅仅只是配置工具,集群可脱离它正常运行)。
本节所需安装软件可以在安装光盘的Packages目录直接安装,不需要配置yum源。
(一)集群节点
1、安装集群软件包
| [root@linux1183 ~]# yum install ricci openais cmanrgmanager lvm2-cluster gfs2-utils |
2、打开防火墙相应端口
| 端口 协议 程序 5404,5405 UDP corosync/cman 11111 TCP ricci 21064 TCP dlm 16851 TCP modclusterd |
3、或者直接禁用防火墙
| [root@linux1183~]# /etc/init.d/iptablesstop [root@linux1183~]#chkconfig iptables off |
4、关闭节点上的ACPI服务
| [root@linux1183~]# /etc/init.d/acpid stop [root@linux1183~]# chkconfig apcid off |
5、禁用NetworkManager
| [root@linux1183~]# /etc/init.d/NetworkManager stop [root@linux1183~]# chkconfig NetworkManager off |
6、给软件用户ricci设置密码
| [root@linux1183 ~]# passwd ricci |
7、启动ricci服务
| [root@linux1183~]# /etc/init.d/ricci start [root@linux1183~]# chkconfig ricci on |
【在28.6.11.15上执行同上的操作命令】
(二)集群配置管理器(luci)
可以安装在节点上,现在安装在存储服务器上,更利于监控集群状态。
1、在28.6.11.80上安装管理软件
| [root@linux1180 ~]# yum install luci |
2、打开软件相应端口
| 端口 协议 程序 8084 TCP luci |
3、或者直接禁用防火墙
| [root@linux1180~]# service iptables stop [root@linux1180~]# chkconfig iptables off |
4、启动luci
| [root@linux1180~]# /etc/init.d/luci start Addingfollowing auto-detected host IDs (IP addresses/domain names), corresponding to`linux1180.domain.com' address, to the configuration of self-managedcertificate `/var/lib/luci/etc/cacert.config' (you can change them by editing`/var/lib/luci/etc/cacert.config', removing the generated certificate`/var/lib/luci/certs/host.pem' and restarting luci): (none suitablefound, you can still do it manually as mentioned above) Generating a2048 bit RSA private key writing newprivate key to '/var/lib/luci/certs/host.pem' 正在启劢 saslauthd: [确定] Start luci... [确定] Point your webbrowser to https://linux1180.domain.com:8084 (or equivalent) to access luci [root@linux1180~]# chkconfig luci on |
【集群配置测试中,经过多次的删除和修改后,luci配置界面可能出现不稳定表现,这时可以考虑重新安装luci】
五、集群配置
1、登录管理服务器的luci界面:

2、输入用户名root和密码,登录

3、转到managecluster界面

4、点击Create,创建集群
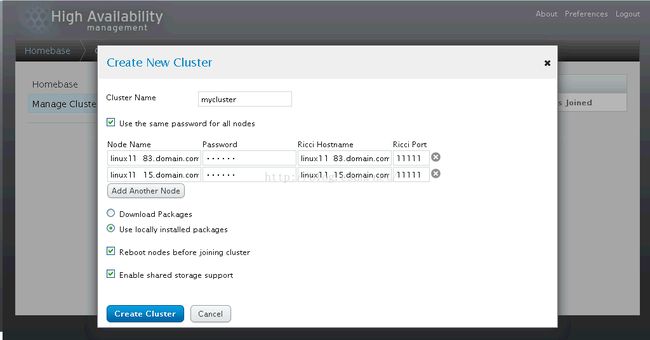
【上图中输入的是ricci用户密码】
5、集群创建成功

6、转到FenceDevices创建fence设备
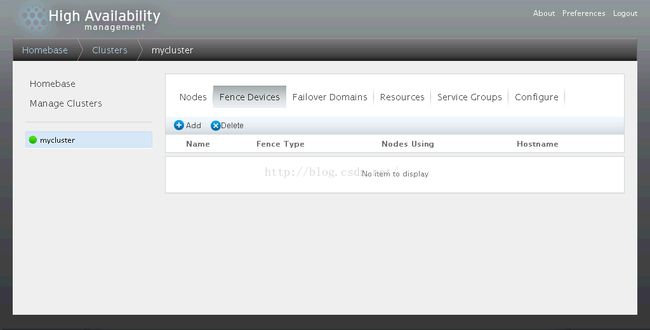
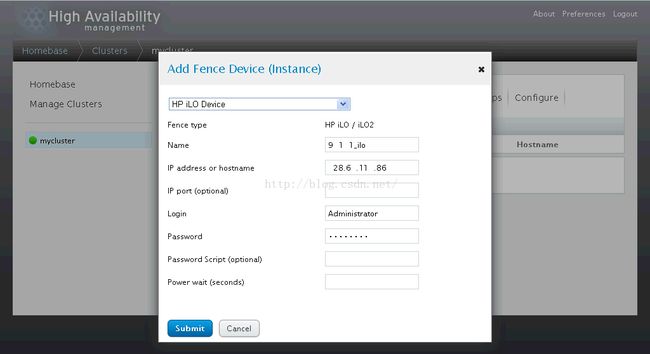
7、点击【Add】创建28.6.11.83的HP iLo Fence设备
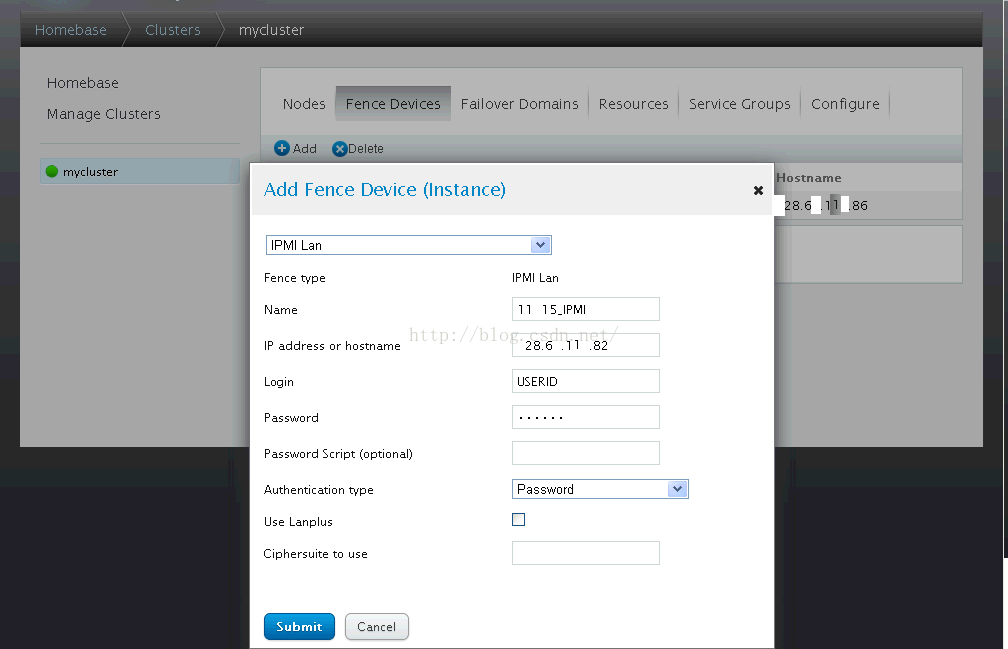
8、点击【Add】创建28.6.11.15的IPMI Lan Fence设备
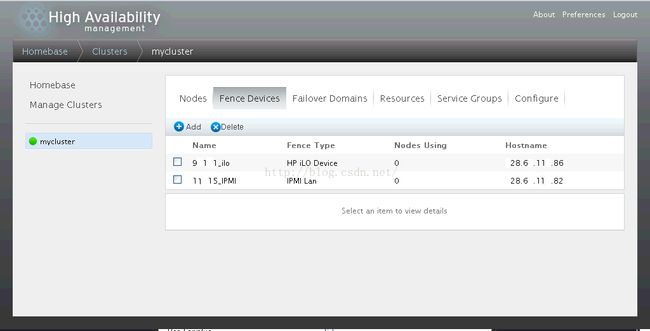
9、创建完成如下:
10、回到nodes菜单下,点击linux1183.domain.com,出现节点详情后点击add fence method添加一个method

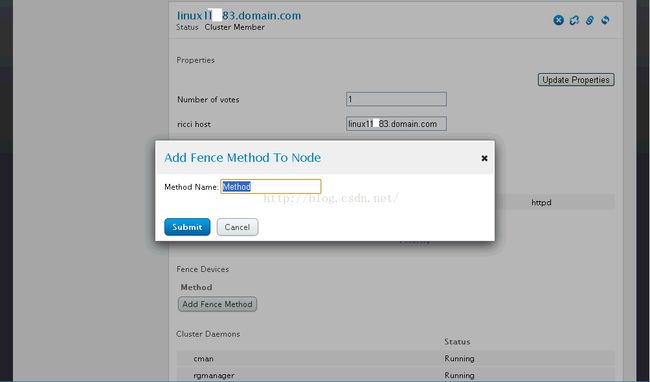
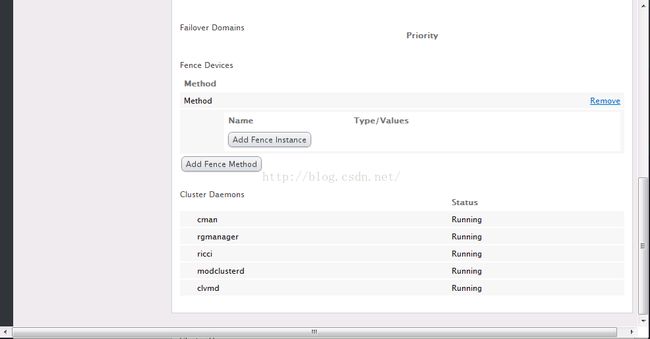
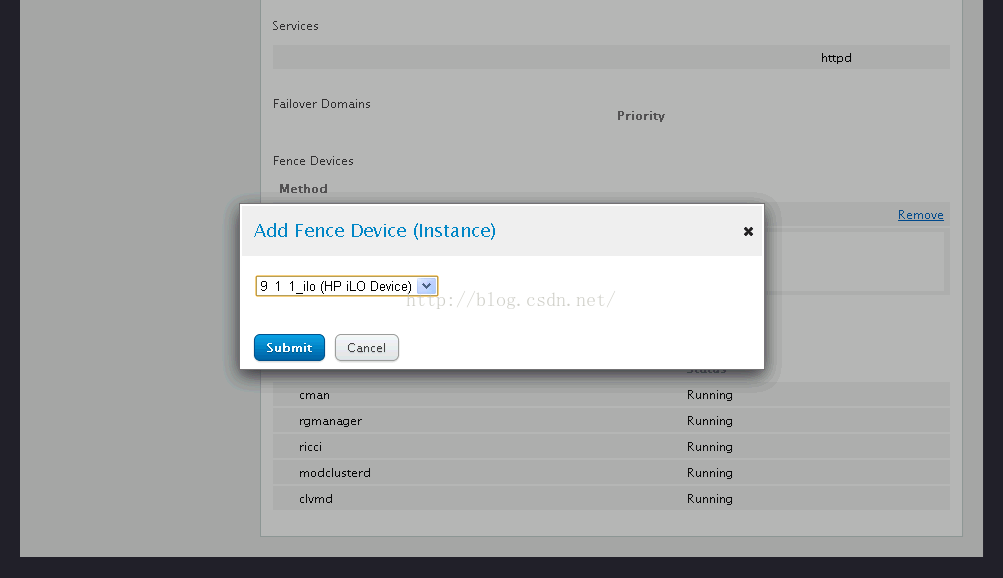
11、点击【add fence instance】,添加刚才设定的HP iLo Fence设备
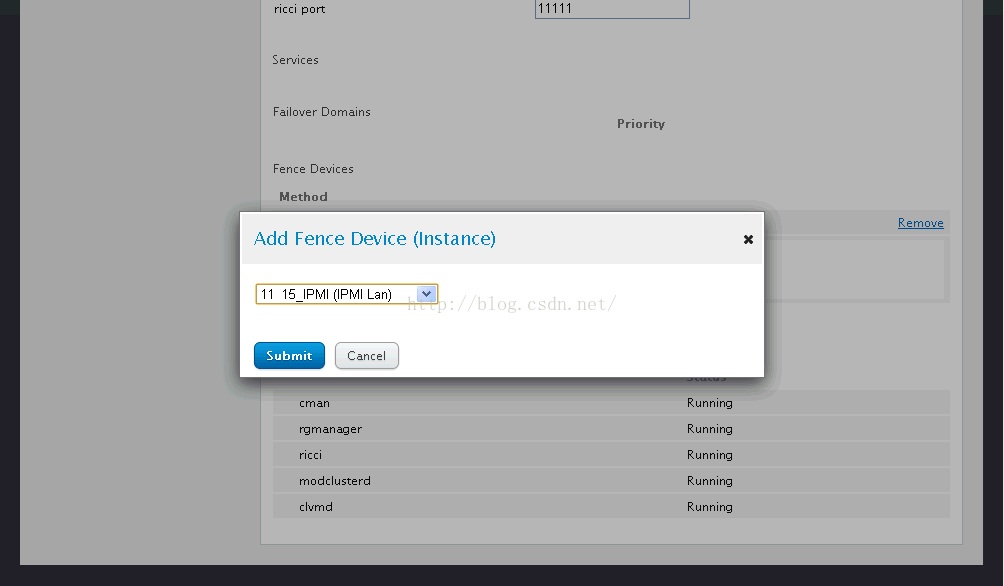
12、使用同样的方法为28.6.11.15添加IPMI Lan Fence设备:
六、配置Qdisk
Qdisk(仲裁盘)是一块裸设备,可以用来解决集群节点间的脑裂现象(集群节点之间无法通信,互相认为对方死亡),该设备可以分区也可以不分区。Qdisk创建后将被分为16块,对应集群可以支持的最大16个节点数,每个块里分别记录了对应节点的时间戳和状态等信息。
1、创建Qdisk
/dev/sdc为linux1180上共享出来的一块硬盘,在节点服务器linux1115上执行如下:
| [root@linux1115 ~]# mkqdisk -c /dev/sdc -l QDISK |
2、在luci界面下进行如下配置

点击“Apply”保存。
其中,Heuristics(试探) 是集群里的一个小程序,每隔2秒(internal)执行一次ping -c1 -t1 28.6.11.254(这里的IP地址一般是个稳定的网关)的命令,每成功一次得2分(score),如果执行10次(TKO)后,得分依然小于2分(Minimumtotal score),该集群节点便自动自我隔离,自我重启。
七、为共享卷创建GFS文件系统
1、创建LVM卷【这个操作在28.6.11.83上操作便可】
| [root@linux1183 ~]#pvcreate /dev/sdb Physical volume "/dev/sdb" successfully created
[root@linux1183 ~]#vgcreate vg1 /dev/sdb Clustered volume group "vg1" successfully created
[root@linux1183 ~]#lvcreate -L 10G -n lv1 vg1 Logical volume "lv1" created |
2、在两台节点上手劢重启/etc/clvmd服务
| [root@linux1183~]#/etc/init.d/clvmd restart [root@linux1115 ~]#/etc/init.d/clvmd restart |
3、用fdisk查看磁盘,在两边主机上都可以看到新建的lvm卷
| [root@linux1183 ~]#fdisk -l ......... Disk /dev/sdb doesn't containa valid partition table
Disk /dev/mapper/vg1-lv1:7516 MB, 7516192768 bytes 255 heads, 63 sectors/track,913 cylinders Units = cylinders of 16065 *512 = 8225280 bytes Sector size(logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal):512 bytes / 512 bytes Disk identifier: 0x00000000 Disk /dev/mapper/vg1-lv1 doesn't contain a validpartition table |
| [root@linux1115 ~]#fdisk -l ......... Disk /dev/sdb doesn't containa valid partition table
Disk /dev/mapper/vg1-lv1:7516 MB, 7516192768 bytes 255 heads, 63 sectors/track,913 cylinders Units = cylinders of 16065 *512 = 8225280 bytes Sector size(logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal):512 bytes / 512 bytes Disk identifier: 0x00000000 Disk /dev/mapper/vg1-lv1 doesn't contain a validpartition table |
| [root@linux1183 ~]#mkfs.gfs2 -p lock_dlm -t mycluster:data1 -j 4/dev/vg1/lv1 |
| -p指定lock参数,-t指定 集群名:文件系统名 –j指定可以连接的节点数 |
5、节点上挂载GFS2文件系统
| [root@linux1183 ~]#mkdir /mnt/data1 [root@linux1183 ~]#mount /dev/vg1/lv1/mnt/data1/
[root@linux1115 ~]#mkdir /mnt/data1 [root@linux1115 ~]#mount /dev/vg1/lv1 /mnt/data1/ |
6、测试GFS2文件系统是否正常运行,在Linux1183和linux1115上分别新建文件,在双方查看是否相同
7、让GFS2文件系统开机自动挂载
在linux1183和Linux1115的/etc/fstab文件中,分别加入如下:
| /dev/mapper/vg1-lv1/mnt/data1 gfs2 defaults 0 0 |
8、重启节点验证是否可以自动挂载成功
八、建立WEB高可用服务
(一)配置WEB服务器
两个节点上建立web服务器,实际使用中网站根目录均应使用/mnt/data1/下的相同目录,测试中为了更好的验证,分别使用/mnt/data1/www1和/mnt/data1/www2。
1、修改两个节点上的/etc/httpd/conf/httpd.conf
| [root@linux1183 ~]# vim/etc/httpd/conf/httpd.conf DocumentRoot"/var/www/html"改为 DocumentRoot "/mnt/data1/www1" |
| [root@linux1183 ~]# vim/etc/httpd/conf/httpd.conf DocumentRoot"/var/www/html"改为 DocumentRoot "/mnt/data1/www2" |
2、新建目录及网页文件index.html
| [root@linux1183 ~]#mkdir/mnt/data1/www1 /mnt/data1/www2 [root@linux1183 ~]# vim/mnt/data1/www1/index.html this is 28.6.11.83 [root@linux1183 ~]# vim/mnt/data1/www2/index.html this is 28.6.11.15 |
3、启动两台机器上的http服务
| [root@linux1183 ~]#/etc/init.d/httpd start [root@linux1115 ~]#/etc/init.d/httpd start |
4、测试http服务是否正常
访问28.6.11.83得到如下界面:
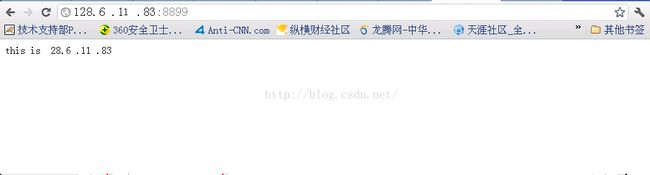
访问28.6.11.15得到如下界面:

(二)创建集群服务组
1、创建IP地址资源(28.6.11.81为虚拟IP,是集群服务的访问入口)
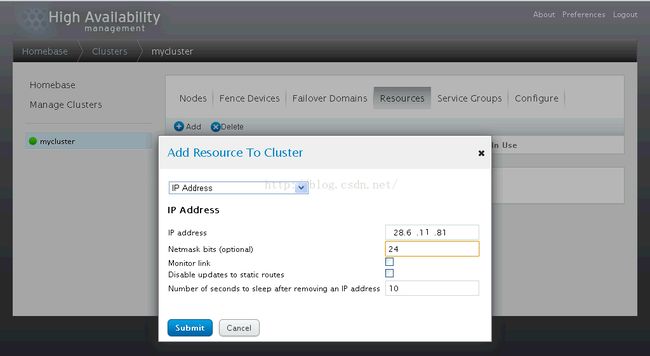
2、创建脚本资源(集群调用该脚本启动WEB服务)
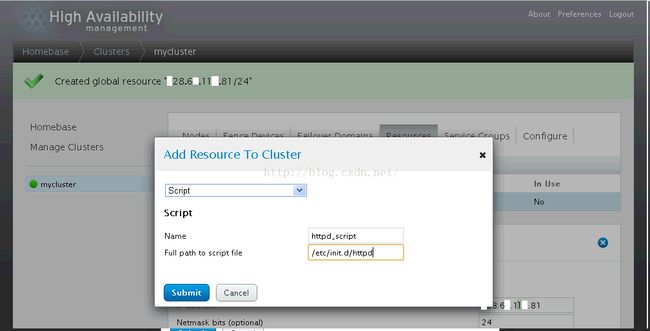
3、新建故障切换域
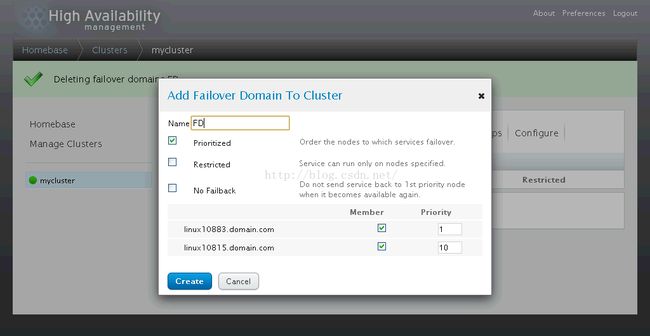
【Priority值越小,优先级越高】
4、新建服务组

5、添加IP资源

6、添加脚本资源
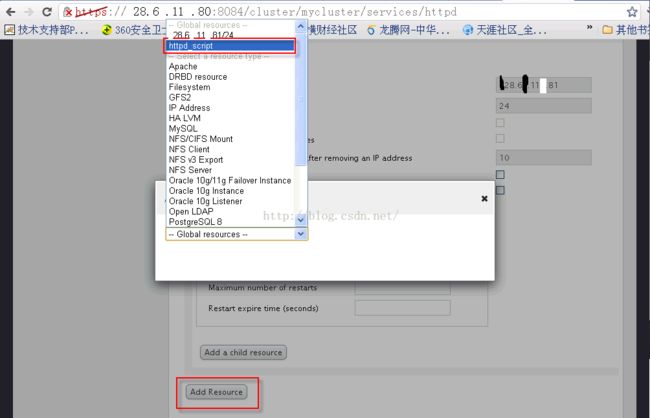
注:IP地址和脚本可以设置为两个独立的资源,也可以设置为父子从属型(Add a child resource)。在创建的服务启动时,独立资源分别加载,无论谁加载失败都互不影响,父子关系情况下,父资源加载失败时,子资源不会被加载。
添加完成后注意保存。

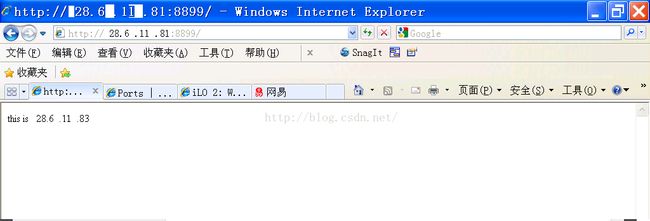
7、查看服务启动情况

如果配置准确,可以看到服务已经运行在linux1183。打开IE访问虚拟IP 28.6.11.81可以得到如下的界面:
九、高可用性验证
(一)手动切换测试
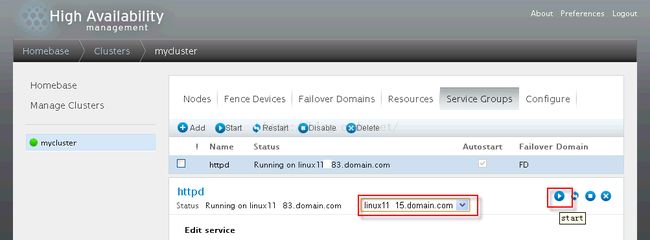
按照上图的操作,手工把服务切换到linux1115上运行,得到如下【需要刷新就】:
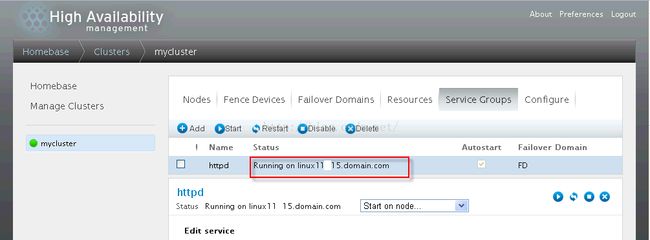
打开IE访问虚拟IP 28.6.11.81可以得到如下的界面:

【当Fence配置错误时,手动切换也可以成功】
(二)自动切换测试
当Fence配置错误时,无法进行自动切换。
使用命令检查Fence信息配置是否正常,方法如下:
打开linux1183或者linux1115的/etc/cluster/cluster.conf文件【集群配置成功后,所有节点拥有相同的cluster.conf配置文件】,得到如下的内容:
| |
使用上面的信息,用命令行异机测试的方法获取机器的状态,以验证配置的准确性。如下:
在linux1183上获取linux1115的机器状态信息:
| [root@linux1183 ~]# ipmitool -I lan -UUSERID -H 28.6.11.82 -a chassis power status -P PASSWD Password:【不用输入密码直接回车就可以】 ChassisPower is on |
| 重启命令:ipmitool -I lan -U USERID-H 28.6.11.82 -a chassis power cycle |
在linux1115上获取linux1183的机器状态:
| [root@linux1115 ~]# fence_ilo -o status -a 28.6.11.86-l Administrator -p password Status:ON |
| 重启命令:fence_ilo -o reboot -a 28.6.11.86-l Administrator -p password |
如果上面的两项测试都可以正常获得机器状态信息,可以进行如下的AB测试:
A、接上节,现在服务运行在linux1115上,手动关闭linux1115后,服务应该自动切换到linux1183上运行。因为在故障切换域的设置中linux1183的优先级高于linux1115的优先级,所以当linux1115恢复启动后,服务依然会在linux1183上运行。
B、当linux1115恢复启动后,手动关闭linux1183,服务应该自动切换到linux1115上运行,当linux1183恢复启动后,服务会再次切换到linux1183上运行(如果优先级(1-100)设置相同,当linux1183恢复后服务不会切换到linux1183上运行)。
如上的AB测试成功后,下面再进行Fence设备的自动重启测试:
C、假设服务目前运行在linux1183上面,在linux1183的console界面上运行命令:
| [root@linux1183 ~]# service network stop |
此时,服务自动切换到linux1115上运行,而后,linux1183将自动重启,启动成功后服务再次切换到linux1183上运行。
D、假设服务目前运行在linux1115上面,在linux1115的console界面上运行命令:
| [root@linux1115 ~]# service network stop |
此时,服务自动切换到linux1183上运行,而后,linux1115将自动重启,启动成功后服务依然保持在linux1183上运行。
上面的测试通过后,说明集群可以正常使用。
附录
(一)有关集群的概念
1、集群:集群是一组协同工作的服务实体,用来提供比单一服务实体更具扩展性以及可用性的服务平台。
2、集群的可扩展性:可以动态的加入新的服务节点来提高集群的综合性能,而不需要停掉集群提供的服务。
3、集群的高可用性:集群实体通过内部服务节点的冗余方式来避免客户端访问时出现out of service的状况。也就是说,集群中同一服务可以由多个服务节点提供,当部分节点失效后,其他服务可以接管服务。
4、集群的实体地址:是客户端访问集群实体获取服务的唯一入口。
5、负载均衡:指集群中的分发设备将用户的请求比较均衡的分发给集群实体中各个服务节点的计算、存储、以及网络资源。
6、负载均衡器:负责提供负载均衡的设备。其一般具备如下功能:
1)维护集群地址
2)负责管理各个服务节点的加入和退出
3)集群地址向内部服务节点地址的转换
7、错误恢复:指集群中的某个或者某些服务节点不能正常工作或者提供服务时,其他服务节点可以资源透明的完成原有任务。
8、HA集群:高可用性集群,通过特殊的软件将独立的node连接起来,组成一个能够提供故障切换的集群。它保证了在多种故障中,关键性服务的可用性、可靠性、以及数据的完整性。主要应用与文件服务,WEB服务,数据库服务等关键应用中。
9、LB集群:负载均衡集群,在LB服务器上使用专门的路由算法,将数据包分散到多个真实服务器上进行处理,从而达到网络服务的负载均衡的作用。主要运用于公共WEB服务,FTP服务,数据库服务等高负载的服务中。
10、集群技术的优势:低成本,高可用,高扩展,高资源利用率。
(二)HA 高可用集群
1 、HA集群的三种方式:对称,主从,多机。
1)对称方式:包括2台服务器以及至少1个服务,2台服务器都运行服务,哪台先起则在哪台上启动服务,当一台失效时,服务迁移至另外一台上,当失效机恢复正常时,服务不会迁回至该机。
2)主从方式:包括2台服务器以及至少1个服务,其中权重较高的服务器运行服务,另外一台作为备份服务器,并且监视Master的状态,当Master发生故障时,服务会切换至Slave服务器;当Master恢复正常,服务迁回至Master。
3)多机方式:2台以上服务器以及至少1个服务的对称方式或者主从方式。
2 、HA的基本组成
1)Service:是HA集群中提供的特定资源。
2)Node:HA集群中实际运行服务提供特定资源的服务器。
3)FailoverDomain:HA集群中所有提供特定资源的成员服务器的集合。
4)Hearbeat:通过网络数据包来监视服务器状态的方法。
5)ShareStorage:共享存储来储存HA集群所需的数据。
6)单一故障点:HA集群中可能出现故障的单个设备。
7)仲裁:判断服务器及其服务是否运行正常
8)服务失效转移:当node出现硬件或者服务失效时,应将相应的服务迁移至失效域中的其他节点
9)Watchdog:定时向各节点发送信息,来确定节点或者节点上的服务的运行状态
10)可编程的电源控制器:由外部控制的电源控制器,连接各节点,当某台节点死锁时,可以通过其他成员服务器或者设备强行关闭该节点的电源。
(三)集群日志
如果需要查看日志信息,可以在luci的界面上打开日志开关,以降低调试难度,如下:
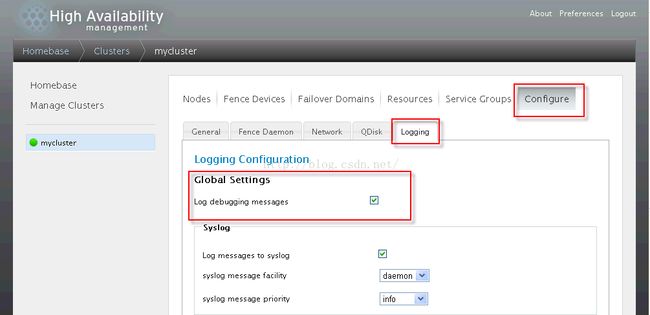
打开或者关闭要关注的日志类型:
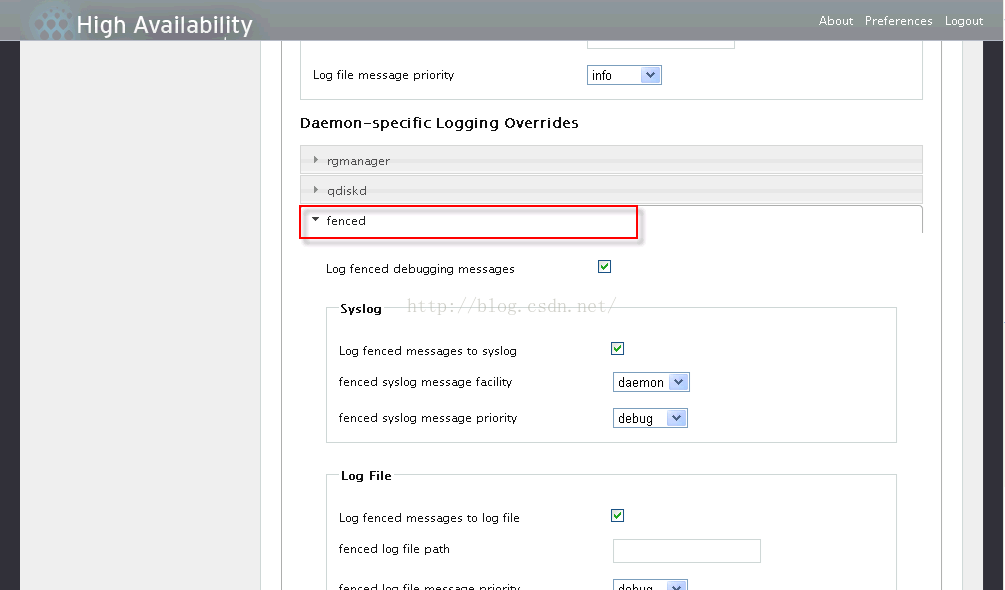
然后在console上执行tailf /var/log/messages,可以看到持续的日志滚动输出,如下:
| [root@linux1183 ~]# tailf /var/log/messages Nov 7 19:44:31 linux1183 rgmanager[2428]: Service service:httpd is stopped Nov 7 19:44:36 linux1183 rgmanager[2428]: Service service:httpd is nowrunning on member 2 Nov 7 20:14:33 linux1183 modcluster: Updating cluster.conf Nov 7 20:14:33 linux1183 corosync[1720]: [QUORUM] Members[2]: 1 2 Nov 7 20:14:33 linux1183 modcluster: Updating cluster version Nov 7 20:14:34 linux1183 rgmanager[2428]: Reconfiguring Nov 7 20:14:34 linux1183 rgmanager[2428]: Loading Service Data Nov 7 20:14:37 linux1183 rgmanager[2428]: Stopping changed resources. Nov 7 20:14:37 linux1183 rgmanager[2428]: Restarting changed resources. Nov 7 20:14:37 linux1183 rgmanager[2428]:Starting changed resources. |
(四)有关集群命令
1、Clustat查看集群状态
| [root@linux1183 ~]# clustat Cluster Status for mycluster @ Mon Nov 7 20:49:42 2011 Member Status: Quorate
Member Name ID Status ------ ---- ---- ------ linux1183.domain.com 1 Online, Local, rgmanager linux1115.domain.com 2 Online, rgmanager
Service Name Owner (Last) State ------- ---- ----- ------ ----- service:httpd linux1115.domain.com started |
配置Qdisk后的输出:
| [root@linux1183 ~]# clustat Cluster Status for mycluster @ Fri Nov 1802:11:03 2011 Member Status: Quorate
Member Name ID Status ------ ---- ---- ------ linux1183.domain.com 1 Online, Local,rgmanager linux1115.domain.com 2 Online, rgmanager /dev/block/8:16 0 Online, QuorumDisk
Service Name Owner (Last) State ------- ---- ----- ------ ----- service:httpd linux1115.domain.com started |
2、fence命令
| fence_ack_manual fence_egenera fence_rsa fence_apc fence_eps fence_rsb fence_apc_snmp fence_ibmblade fence_sanbox2 fence_bladecenter fence_ifmib fence_scsi fence_bladecenter_snmp fence_ilo fence_tool fence_brocade fence_ilo_mp fence_virsh fence_cisco_mds fence_intelmodular fence_virt fence_cisco_ucs fence_ipmilan fence_vmware fenced fence_node fence_vmware_helper fence_drac fence_nss_wrapper fence_wti fence_drac5 fence_rhevm fence_xvm |
3、集群启停顺序和命令
| 停止顺序: 现在luci界面上停止服务 service rgmanager stop service gfs2 stop【自动umount gfs2文件系统】 service clvmd stop service cman stop 如果要重启linux1180上的tgtd服务,还需要在每个节点客户端上执行: iscsiadm -m node -Tiqn.2011-06.com.domain:server.target1 -p 28.6.11.80:3260 -u
启动顺序: service cman start service clvmd start service gfs2 start servicergmanager start |
4、命令行切换
| [root@linux1115 ~]# clustat Cluster Status for mycluster @ Tue Nov 8 09:00:55 2011 Member Status: Quorate
Member Name ID Status ------ ---- ---- ------ linux1183.domain.com 1 Online, rgmanager linux1115.domain.com 2 Online, Local, rgmanager
ServiceName Owner (Last) State ------- ---- ----- ------ ----- service:httpd linux1115.domain.com started [root@linux1115 ~]# clusvcadm -r httpd -m linux1183 'linux1183' not in membership list Closest match: 'linux1183.domain.com' Trying to relocate service:httpd to linux1183.domain.com...Success service:httpd is now running on linux1183.domain.com [root@linux1115 ~]# clustat Cluster Status for mycluster @ Tue Nov 8 09:02:22 2011 Member Status: Quorate
Member Name ID Status ------ ---- ---- ------ linux1183.domain.com 1 Online, rgmanager linux1115.domain.com 2 Online, Local, rgmanager
Service Name Owner (Last) State ------- ---- ----- ------ ----- service:httpd linux1183.domain.com started |