遗传算法
1.遗传算法背景
遗传算法是从生物现象遗传规律总结而出的。它是根据种群的不断衍化,个体间作为父本和母本产生新的个体,在这一过程中,基因进行交叉、变异、选择。通过不断的衍化逐渐使种群朝向整体逐渐优化(整体基因逐渐得到改良的过程)。这和严复的天演论中“物竞天择,适者生存”相一致,同时也相符与达尔文的物种进化适者生存的原理。但是对于遗传算法贡献最大的生物学理论还应该属孟德尔的豌豆杂交试验,从其中来的染色体交叉、基因变异等理论,这对于遗传算法给出了直接的启示。
1975年美国的Michigan大学J.Holland教授首先提出来这种通过模拟自然进化过程搜索最优解的方法。
2.遗传算法运算过程
1) 初始化
设置进化代数Largest_generation =1000;一个种群中个体数popsize =20;种群数:Largest_size = 30;一个种群进化1000代,进化30个不同随机的种群(模拟30个种群的进化)。TSP 城市选择10个,随机化其城市地理位置(x,y)坐标,区间在x,y[0,1]之间,计算出10个城市之间城市到城市的距离矩阵(类似于邻接矩阵)。
2) 个体评价
适应度函数的计算
![]()
这里面从1到2的距离加2到3 的,一直到9到10,然后10再到1的距离全部求和。矩阵形式用fitness表示。既然是TSP问题,那就要寻求一个最小的总路径。
3) 选择运算
将选择算子运用于群体。其选择的目的是将优良的基因遗传给下一代,或者通过交叉再遗传给下一代。这里选择运算采用轮盘法,其基本思想是:通过上面适应度的计算,将适应度求倒数累加,适应度函数值越低,表明TSP的路径路程越小,就是要对越小路径进行选择的概率越大。这里采用了

每个适应度所占的概率为pi,第1个个体所占的概率范围是[0,p1],第2个个体所占的概率范围是[p1,p1+p2],…第i个个体所占的概率范围是[p1+p2+...+pi-1,p1+p2+...+pi],这样以此类推。对应于下图:

根据轮盘算法,概率大的被选到的机会越大,也就是说好的个体被选择的机会越大。(这里的适应度选最小的,机会越大,这可能看起来有点别扭,但是求类似于这种求最小值的问题并没有什么值得有疑问的地方)
由当前种群中popsize个个体,产生直接遗传给后代或者要进行交叉将基因传给后代的父代亲本,产生的父代亲本数popsize*2,一般是两个父代亲本进行,这里一个作为父亲,另一个为母亲。这就是选择算子,当然这里用的是转盘法。
4) 交叉算子
将交叉算子用于种群。这里有一个交叉概率PC,这里设置为0.75,这可以参考不同的问题参数设置的方法不同。对于二进制遗传算法和实数遗传算法(这里应该对应于不同的编码方式),采取的方式不同。二进制遗传算法交叉,单点交叉,2点交叉,3点交叉和多点交叉等。单点交叉:随机选择一位,
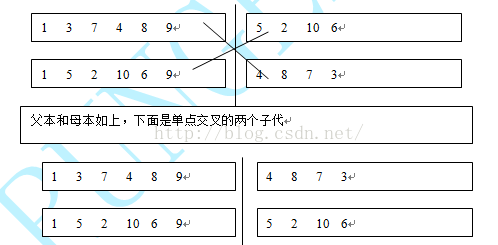
相应的2点交叉和多点交叉,实际上选择几个交叉点的问题,同时父本的个数也可能会随之增加。交叉后,需要进行新产生的子个体修正,因为有重复的数据。重复的城市可以选择一个排列,通过适应值的计算选择一个最优的。或者直接一个对于重复城市组合的随机组合。
对于实数的遗传算法一种方式就是每一维(每一维这里指列向量的每一个值)都会有一个区间[xmin,xmax],每一维的交叉变成了在[father.value mother.value]这个区间段内的一个取值,如:rnum=rand(1),child.value=rnum*father.value+(1-rnum)*mother.value;这对应的是局部搜索。
5)变异算子
用变异算子作用于个体进行变异,可以紧跟着交叉进行。PM为变异参数,一般去很小,如0.001等。这里采用一个点的变异,在生成的子代个体中随机选择两个点位置,互换城市序号(对应于TSP问题)。如果是实数遗传算法(这里并不是对于Tsp问题,举个例子可以
)这是可以选择子代中某一位置点,如child(5,k) = xmin+rand(1)*(xmax-xmin);k表示第k个子代,5表示该子代第5维位置,做变异。
可以看出变异算子可以讲交叉算子的局部搜索引入到全局的范围内。
![]()
6)一个种群进化规定代数,结束
每一次进化都比较选出最佳个体记录到最佳个体和最佳适应值中,进行下一次的进化,直到进化次数结束位置。3.流程图
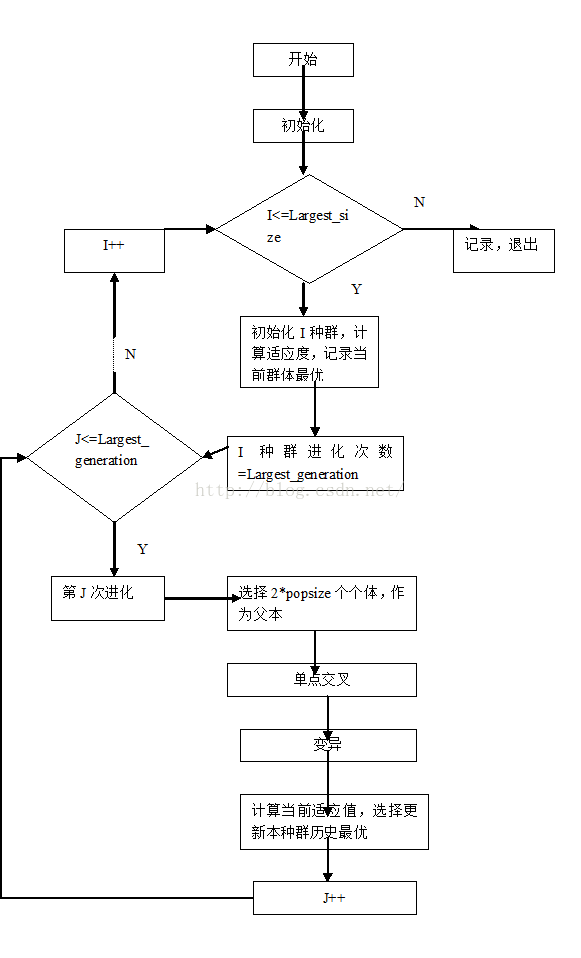
4.实验结果
|
|
城1 |
城2 |
城3 |
城4 |
城5 |
城6 |
城7 |
城8 |
城9 |
城10 |
距离 |
| 群1 |
1 |
5 |
6 |
9 |
7 |
10 |
2 |
4 |
3 |
8 |
3.1255 |
| 群2 |
1 |
3 |
5 |
6 |
9 |
7 |
10 |
2 |
4 |
8 |
3.5785 |
| 群3 |
1 |
5 |
6 |
9 |
7 |
10 |
2 |
4 |
3 |
8 |
3.1255 |
| 群4 |
1 |
3 |
8 |
5 |
6 |
9 |
7 |
10 |
2 |
4 |
3.0098 |
| 群5 |
1 |
5 |
6 |
9 |
7 |
10 |
3 |
8 |
4 |
2 |
3.1205 |
| 群6 |
1 |
5 |
3 |
8 |
4 |
9 |
6 |
7 |
10 |
2 |
3.4649 |
| 群7 |
1 |
3 |
8 |
5 |
6 |
9 |
7 |
10 |
2 |
4 |
3.0098 |
| 群8 |
1 |
3 |
8 |
4 |
2 |
10 |
7 |
9 |
6 |
5 |
3.1943 |
| 群9 |
1 |
6 |
9 |
7 |
10 |
5 |
3 |
8 |
4 |
2 |
3.2856 |
| 群10 |
1 |
3 |
8 |
5 |
6 |
9 |
7 |
10 |
2 |
4 |
3.0098 |
| 群11 |
1 |
9 |
7 |
10 |
2 |
4 |
8 |
3 |
5 |
6 |
3.7764 |
| 群12 |
1 |
5 |
6 |
9 |
7 |
10 |
2 |
3 |
8 |
4 |
3.3149 |
| 群13 |
1 |
3 |
8 |
4 |
2 |
10 |
7 |
9 |
6 |
5 |
3.1943 |
| 群14 |
1 |
3 |
8 |
5 |
6 |
9 |
7 |
10 |
2 |
4 |
3.0098 |
| 群15 |
1 |
6 |
9 |
7 |
10 |
2 |
4 |
8 |
3 |
5 |
3.253 |
| 群16 |
1 |
3 |
8 |
5 |
6 |
9 |
7 |
10 |
2 |
4 |
3.0098 |
| 群17 |
1 |
3 |
8 |
5 |
6 |
9 |
7 |
10 |
2 |
4 |
3.0098 |
| 群18 |
1 |
5 |
3 |
8 |
4 |
2 |
10 |
7 |
9 |
6 |
3.108 |
| 群19 |
1 |
5 |
6 |
9 |
7 |
10 |
2 |
3 |
8 |
4 |
3.3149 |
| 群20 |
1 |
5 |
6 |
9 |
7 |
10 |
2 |
3 |
8 |
4 |
3.3149 |
| 群21 |
1 |
5 |
3 |
8 |
4 |
2 |
10 |
7 |
9 |
6 |
3.108 |
| 群22 |
1 |
6 |
9 |
7 |
10 |
5 |
3 |
8 |
4 |
2 |
3.2856 |
| 群23 |
1 |
5 |
3 |
8 |
4 |
2 |
10 |
7 |
9 |
6 |
3.108 |
| 群24 |
1 |
3 |
8 |
5 |
6 |
9 |
7 |
10 |
2 |
4 |
3.0098 |
| 群25 |
1 |
5 |
6 |
9 |
7 |
10 |
3 |
8 |
4 |
2 |
3.1205 |
| 群26 |
1 |
3 |
8 |
5 |
6 |
9 |
7 |
10 |
2 |
4 |
3.0098 |
| 群27 |
1 |
3 |
8 |
5 |
6 |
9 |
7 |
10 |
2 |
4 |
3.0098 |
| 群28 |
1 |
6 |
9 |
7 |
10 |
2 |
4 |
8 |
3 |
5 |
3.253 |
| 群29 |
1 |
5 |
3 |
8 |
4 |
2 |
10 |
7 |
9 |
6 |
3.108 |
| 群30 |
1 |
5 |
6 |
9 |
7 |
10 |
3 |
8 |
4 |
2 |
3.1205 |
| 30种群距离均值 3.1788 |
|
||||||||||
说明:这里最好将每次循环式种群初始化的距离值给出,或者采用所有种群采用统一初始化的城市与城市间的距离。本数据只是对应不同的初始化的邻接城市距离矩阵。
5.结果分析
(1)本算子并不是跟对于TSP问题的特有算子,仅是一个用遗传算法解决TSP问题的一个例子,因此得出的结果并不理想,但想说明的是这种与特定问题相结合的问题处理接口分析形式。
(2)同时本文也有很多缺点,每次都是不同的城市布局(城市与城间的距离不同,不同种群间没有可比性,仅仅可以看一下自适应度函数值的优劣),因此可以用同一组城市分布,来分钟群进行可比性分析。
(3)同时这里第三个问题就是每次起点都是城市1,这也有些不合理,需要改进。
(4)对于遗传算法有特定的解决TSP问题的算子,大家可以参考其他的文献解决。
(5)对于统计推断,一般认为大于30个样本就可以认为是大样本,可以进行统计上的分析。比如几组结果可以求出期望和方差比较,并用数理分析检验(如T检验),用这种统计推断的方法进行算法优劣的一个判断。
(6)这里还需要进一步说明一点最大的进化次数,一般取50倍或者100倍的一个种群的数量(50*popsize ,100*popsize)。关于维度划分:低维[0,500];高维[500,1000],超高维[1000,…];对于机器学习里面高维数据一般用稀疏矩阵来描述,但空间浪费严重,效率?可以采用降维处理(PCA(主成分分析,数学知识降)、根据物理或者集合意义降等)。
(7)注意这里采用的问题都是无约束、单目标、连续优化算法。
6.论文中算法交流记录
首先想强调的是这里的问题都是针对于单目标无约束连续的优化算法。下面是我们课堂讨论关于一些遗传算法论文的总结:
(1)由一种弱学习过程到强学习过程的转换,这个思想来源于机器学习。它主要的内容是先由50%概率的正确学习概率弱学习,然后逐渐的将该概率提高,每次都得到一个分类器I,直到以大于的概率分类(有n个分类器)的强学习过程为止。
先从所有数据中选取若干作为训练数据得到一个分类器1,之后再从总的训练集中选择没有通过分类器1的数据加入,再得到分类器2,这样依次循环加入新的训练数据,得到分类器N,直到满足相应的概率值。最终分类器M就是我们要的强学习过程结果。
思路就是:
(a) 将每个种群产生的优秀基因作为新种群的初始值,当然这样的缺点就是非常容易陷入局部最优,因此在选择算子上我们可以将该最优的个体的选择概率做一个调整先小后大的一个变化过程,确保起初选择概率小,越往后才收敛的概率越大,比如和模拟退火算法的能量公式结合,或者和指数公式、反比例函数(做些变化如F1-SCORE等形式)
(b) 引入种群进化,将新鲜血液引入,如原本20个个体,现在重新引入10个新个体(随机),重新计算适应度是,优胜劣汰,这样一个缺点就是引入大的计算量,虽然这也是选择。因此可以将之前种群进化最优和当前种群上次历史最优结合,利用之前信息,将他们组合随机1-5个直接替换适应度最差的相应数量的个体。这中比之前的应该要好些,且有历史信息,计算量少了些,而且这也可以仅仅在进化的后期进行。这也可以用锦标赛的形式选择。
(2)对于循环中新的优异个体进行记录,这一般在与进行到一半或者2/3的量上才是记录这里优异个体,利用这些优异各体信息进行处理。
(3)在种群进行到中后期进化过程中,在每一维上都可以得到一个区间,就像用(2)的过程一样,然后交叉,在该区间上交叉,意思就是在该区间上随意取一个值,作为交叉结果(这是实数交叉),这样通过交叉可以得到一个局部最优。
(4)解决费时问题,计算一部分的适应度值,余下的部分用参数估计进行估计。这样就可以减少计算量的问题,但是估计的可信度便成为一个需要考虑的问题。这里它是采用两种模式,模式1:如果个体相似度>=两个母体的相似度,就可以用这两个母体的参数进行估计;模式2:如果个体相似度<=一个母体的,这两就需要进行二次预测;当经过多次预测后<=阈值,当前个体需要进行适应度的真值计算。这里需要有参数估计的只是,还有对于阈值给出一个合理的经验值。算法可能这样看起来有点复制。
(5)个体差的与模式进行学习:这就首先需要得到一些好的模式,所谓模式也就是如
***123****,12*35****,这样固定了一些维上的数值,就可以作为一种模式,这与(4)中的模式1模式2概念是不同的。比如通过(2)或者种群历史最优得到一个模式,选择其中最小边,如12**57****作为一种模式,当前的种群差的模式可以利用这种好的模式进行一个变种,利用与或非的表达进行;优的个体则不进行处理。这是引入模式概念后遗传算法的一个优化。
(6)采用自适应算法,根据自适应值进行调节交叉概率和变异概率。首先将个体保持足够的距离(类似均匀分布,保持不同的吸引域,得到更优的结果),利用算数平均适应值,得到一个标准正态分布,然后根据正态分布取值。(概率取值)。将交叉算子和变异算子的概率自适应成可变,差的个体变化的快(概率大),优的个体变化的慢(概率小点)或者采用适应度和变化概率的公式(许多论文上公式都不相同,都可以参考)
(7)对于变异采用突变和渐变的方式,和(6)的思想有重复。就是优的个体变异概率小,主要以交叉为主;差的个体变异概率大,这样一个思想。相比较(6)更优些,交叉和变异都涉及到了。
(8)采用终止策略:设置一个终止的条件,如500次,每次进化都要进行一次-1,开始时交叉变化快,变异也大,随着过程的深入,交叉变异都慢下来。这也有点自适应度调节参数的意思。只应该只是用进化过程中如1000次中选择500次来进行,效率高点吧。
(9)还有一种就是用实现将各维数据进行一个合理的空间划分,二维和三维和简单,分段或者分立方体等等,但是10维等等就很困难了,分的标准、性能评价的好坏都是问题,有个院士用图论的方式分过,可以搜索看看。
7.总结
遗传算法是一类启发式算法,利用生物遗传交叉变异选择的算子进行模拟分析求解问题。对于具体的问题,关键是找准问题的接口,或者说处理的接口,有些时候有些问题,对应一些算法,但是在我们想用这些算法究竟该如何去处理,问题和模型如何建立关系求解问题,需要我们的考量。此外对于遗传算法的改进:一类是算子的改进;一类是如何利用历史数据信息;一类就是如何利用数学知识;还有一种就是利用新的知识新概念。算子的改进,一般都是根据具体问题,采用的算子可能不同,交叉概率和变异的概率可能利用较多的数学统计分布知识处理,公式改进来提升性能。利用历史数据,不如说记录模式,利用模式在该模式分布上做取值处理等等都可以。起始利用数学知识很大程度上和算子的改进相关,因为算子好多都是利用数学公式进行的改进。利用新的理论或者理论间的结合,这需要新知识,新尝试。博导说GA算法在2000年时就已经在理论上研究的差不多了,先在出的基本上都是应用。大家可以注意一下,判断真伪paper。
是的,感觉这种课堂论文交流形式很给力啊,开拓思路,交流每个人和每个作者的成果,尤其是导师的点评,对于开启研究思路很有借鉴。
附程序matlab代码:
%%智能计算课程---遗传算法应用于旅行商问题,主程序
%旅行商问题,用遗传算法解决,20个父代,10个城市
%TSP GA (gene algorithm)
%算法流程(1)
%
%% Initialization
clear ; close all; clc
%%==================Part one initialparameters=========================
%声明父代的个数(种群数)popsize=20, 城市的个数(维度)dimension =10
%10个城市与城市之间的距离10*10矩阵distance_matrix
popsize = 20;%20个父代 群体个体数
dimension = 10;%10 cities
PC = 0.75;%Probablity cross
PM = 0.01;%变异概率
%x_label,y_label is the 10 cities'scoodinate(x,y)
x_label = rand(1,10);
y_label = rand(1,10);
%10*10 城市间的距离矩阵
distance_matrix =distance_computing(x_label,y_label);
%record the best TSP routine
%best_individual = zeros(dimension,1);
%bestfitness = 0;%全局变量使用时会出错,每次输出结果都一样
%
Largest_generation = 1000;
Largest_size = 30;
best_record =zeros(Largest_size,dimension+1);
%%================== Part two =========================
%
%
%t检验,everytime is the not same the mean,均值好且t检验也好
%30 simples
for i = 1:Largest_size
%inital all generations (初始化所有的初始群体) ,randperm
%用于生成20个子代的40个父代
parent = zeros(dimension,popsize*2);
child = zeros(dimension,popsize*2);
%initial cities,20个当代个体,eachcolmus record one generations
%individual(i,j) means the ith generations' city number ,ie, 2, city 2
individual = zeros(dimension,popsize);
%应该设置成为局部变量
best_individual = zeros(dimension,1);
bestfitness = 0;
%adapted function
fitness = zeros(1,popsize);
%every generations set one start place , here is the city 1
individual(1,:) = 1;
forj = 1:popsize
%to make the every time has different rand value
%rand('state',sum(100*clock)*rand(1));
individual(2:dimension,j) = randperm(dimension-1)'+1;
end
%calculate the every generations fitness function (adaptive fun)
fitness = calculation(individual,distance_matrix);
%record the best resolution and x
[bestfitness index]=min(fitness);
best_individual = individual(:,index);
%loop (问题最优解不知道)或者根据最优解和当前界的误差限于一个很小的数值时结束
%to get a solution nearer to the best
forj=1:Largest_generation
%40 popsize to generate the 20 popsize
%分层次选择适应度好的select 算子 --转轮法
%构造产生20代的40代父类对象
for k=1:2*popsize
temp_index = selection(individual,fitness);
parent(:,k) = individual(:,temp_index);
end
%cross 交叉 operator generate 40 代,局部搜索
for k = 1:popsize
if rand(1) < PC %one point cross
flag = randperm(dimension-2)+1;
child(1:flag(1),2*k-1) = parent(1:flag(1),2*k-1);
child(flag(1)+1:end,2*k-1) = parent(flag(1)+1:end,2*k);
child(1:flag(1),2*k) = parent(1:flag(1),2*k);
child(flag(1)+1:end,2*k) = parent(flag(1)+1:end,2*k-1);
%重复的修补
% child(:,2*k-1) =modifychild(child(:,2*k-1),distance_matrix,flag(1));
% child(:,2*k) =modifychild(child(:,2*k),distance_matrix,flag(1));
child(:,2*k-1) =modifychild_terminal(child(:,2*k-1),parent(:,2*k),distance_matrix,flag(1));
child(:,2*k) =modifychild_terminal(child(:,2*k),parent(:,2*k-1),distance_matrix,flag(1));
else
child(:,2*k-1) = parent(:,2*k-1);
child(:,2*k) = parent(:,2*k);
end
end
%gene heteromorphosis变异 ,not to use or one point change (2*one needto change)
for k=1:2*popsize
if rand(1) tempposition1 = randperm(dimension-1)+1; tempposition2 = randperm(dimension-1)+1; temp = child(tempposition1(1),k); child(tempposition1(1),k) = child(tempposition2(1),k); child(tempposition2(1),k) = temp; end end child_temp_fitness = calculation(child,distance_matrix); [childmin child_index]=sort(child_temp_fitness); for k=1:popsize individual(:,k) = child(:,child_index(1,k)); fitness(1,1:popsize) = childmin(1,1:popsize); end [temp_bestfitness temp_index]=min(fitness); if temp_bestfitness < bestfitness best_individual = individual(:,temp_index); bestfitness = temp_bestfitness; end end % individual,fitness,pause best_record(i,1:dimension) = best_individual'; best_record(i,dimension+1) = bestfitness; end best_record bestmean = mean(best_record(:,dimension+1)') %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %选择子程序 %ind为种群矩阵,fit为该种群适应值 %temp_index为返回选择的单个个体序号 function temp_index = selection(ind,fit) [dim,pop] = size (ind); temp = 1./(fit+1); %minus +max,函数值非负,不能区域0 total = sum(temp); ratio = temp./total;%??? / or ./ for i=2:pop ratio(1,i)=ratio(1,i)+ratio(1,i-1); end temp_number = rand(1); temp_index = 0; for i=1:pop ifratio(1,i)>temp_number %temp_number>... temp_index = i ; % i = temp_index+1; break; end end %index = temp_index; %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%计算每个个体的TSP路径 functiony=calculation(individual,distance_matrix) %%calculate the every generations' total pathlength (TPL) %individual is dim*popsize,distance_matrix isdim*dim %y is 1*popsize ,every is the colmus'sTPL,need return %get the size() [dim popsize] = size(individual); temp_distance = zeros(1,popsize); for i=1:popsize %distance calculation temp_dis = 0.0; forj=1:dim-1 temp_dis = temp_dis+distance_matrix(individual(j,i),individual(j+1,i)); end temp_distance(1,i) =temp_dis+distance_matrix(individual(dim,i)+individual(1,i)); end y = temp_distance; %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %计算邻接矩阵子程序 function distance_matric = distance_computing(x,y) %DISTANCE_COMPUTINT,the functiondistance_computing is computing the %10 cities' each other's distance %parame x and y is a Vector ,and they lengthis same ,ie ..size(x)=size(y) %x(1,i),y(1,i) is the ith city's coordinate(xi,yi) %the city (xi,yi) to the city (xm,ym) ,thedistance ... % ((xi-xm)^2+(yi-ym)^2)^(1/2), at the sametime the distance beteewn (xm,ym) % and (xi,yi) is also the same distance ,theyare all symmetry(对称) % %so the distance_matric need to return back %initl m = length(x) or y m = size(x,2); % needto return these variables correctly. distance_matric = zeros(m,m); % ====================== CODE HERE ====================== % %主对角线Inf(无穷或者设为0,看实际需要),主对角线其右侧计算,左侧对称过去即可 for i = 1:m forj = (i+1):m distance_matric(i,j) = ((x(j)-x(i))^2+(y(j)-y(i))^2)^(1/2); end end for i = 1:m forj = 1:i if i == j distance_matric(i,j) = Inf; else distance_matric(i,j) = distance_matric(j,i); end end end %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %修正交叉的子代 function modify_child = modifychild_terminal(child,mother,distance_matrix,flag) [n m] = size(child); lackindex= zeros(1,flag); addationalnum=zeros(1,flag); tempchild= child(1:flag,1); tempmother=mother(1:flag,1); fori=1:flag tempflag = tempchild==tempmother(i); ttflag = sum(tempflag); if ttflag==0 lackindex(1,i)=i;%mother 中含有的不同的数据记录下标 end tempflag_moth= tempmother==tempchild(i); ttflag_moth=sum(tempflag_moth); if ttflag_moth==0 addationalnum(1,i)=i; %child中含有不同数据记录下标,也就是重复数据下标,需要替换 end end k=size(perms( find(addationalnum~=0)),1); temp_modify_child = zeros(n,k); fori=1:k temp_modify_child(:,i)= child; end temp_modify_child(find(addationalnum~=0),:)=perms(tempmother(find(lackindex~=0),1)')';%%%%% child_temp_fitness = calculation(temp_modify_child,distance_matrix); [childmin child_index]=sort(child_temp_fitness); modify_child = temp_modify_child(:,child_index(1)); %%%%此函数如果用flag对于n/2进行前后判断,选择最少的{前面一段数据量少,后面数据量少} %%%%选择前面时,可以直接用改程序;如果改用后面一段的程序, %%%%应该对应child(后段2*k-1)--father--parent(2*k-1)对应, %%%%child(2*k)----mother---parent(2*k)后段比较 %%%%这就是考虑交叉时子代来源,同时用于比较重复的父代来源 %%%%也就是同时调用这个函数时,所填入的参数也不同。 %该修正算法使用全排列形式,可能速度很慢 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%