【大数据】5分钟快速快速搭建Solr企业级搜索引擎,附Java操作SDK实战搜索
前言:Solr是采用Java开发,基于Lucene的全文搜索服务器,性能强悍,使用简单,常被作为企业级应用的搜索服务器.Solr通过http协议和Json进行响应,所以用Solr搭建的搜素引擎可以跨语言使用,对企业应用而言非常友好.
如果你想学习非常详细的Solr教程,建议可以去W3C进行学习:https://www.w3cschool.cn/solr_doc/solr_doc-g1az2fmd.html
如果你想快速上手搭建使用,看这篇就对了! 仅需两步,即可实现Solr的搭建与使用.不要被文章的篇幅所迷惑,大部分是代码,可以跳过代码部分,其实核心内容就两块,所以学起来还是非常快的.
目录
1.Solr服务器搭建
1.1下载与启动
1.2新增Core
1.3配置分词器
1.4配置数据源
2.SolrJ使用
2.1SolrJ简介
2.2SolrJ实战
2.2.1引入及封装
2.2.2普通参数查询
2.2.3Query参数查询
2.2.4分词及高亮查询
2.3SolrJ总结
1.Solr服务器搭建
1.1下载与启动
Solr官方下载地址:https://lucene.apache.org/solr/downloads.html
读者可根据自己服务器环境及需要选择版本.
前置环境:必须安装JDK及Maven
前置知识:了解Lucene及其原理,了解分词原理.(非必须,即使没有学习,依旧不影响本篇内容,
感兴趣可以戳这里恶补:https://blog.csdn.net/lovexiaotaozi/article/details/103125034)
本文环境:windows操作系统,solr版本:8.3.0 (截止2019-12-03 最新版本) 单机版本,暂不演示集群配置.
下载解压后可以看到如图所示的文件结构,经常被用到的文件已被我圈出:

进入bin文件夹,按下shift键然后单击鼠标右键在此处打开cmd窗口,然后输入:./solr start 即可启动solr

启动后可以在浏览器中访问:http://localhost:8983/
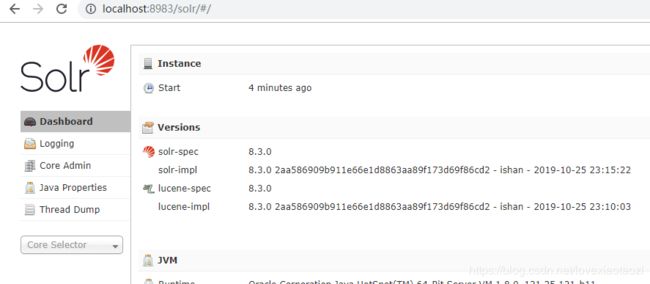
如果你能看到这个界面,那么恭喜你,Solr已成功启动,一个搜索引擎就初步搭建好了!
1.2新增Core
这里的Core你可以理解为是一个应用,一个Solr搜索引擎其实可以为多款应用同时服务的.
Core的创建可以用命令,也可以用UI界面,这里我用UI界面创建,点击Core Admin -> Add Core ->填写信息(可以保持默认)

创建完成后,可以在Solr的解压路径下找到new_core文件夹:solr-8.3.0\server\solr\new_core
然后把同级目录下configsets中的_default/conf文件夹下的内容全部copy出来放置在new_core文件夹下:

Solr的配置文件主要就在这里了,如果你没有复制这步操作,在Solr页面的loging日志中会报错.
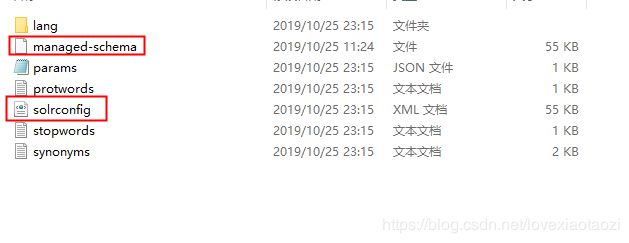
其中managed-schema主要负责配置分词相关的内容()在老版本中对应schema.xml),solrconfig负责solr全局的一些配置.
1.3配置分词器
由于Solr和Lucene对中文分词都不友好,smart-cn分词虽然效率比较高,但是词库不能自定义,所以这里还是采用国人自己开发,且比较主流的中文分词器:IK分词器.
下载地址:https://github.com/EugenePig/ik-analyzer-solr5
下载后通过manven打包 :mvn clean package
![]()
将该jar包复制到:solr-8.3.0\server\solr-webapp\webapp\WEB-INF\lib 目录下
然后打开new_core下的managed-schema,加入如下配置:
然后重启你的solr,重启后,选择core->Analysis 然后填入内容,选择分词器,点击如果可以正确分词就说明生效了:

如果要加入自定义分词可以在刚刚打包好的jar包中编辑扩展词库ext.dic或者在IDE中编辑后重新打包.

1.4配置数据源
在实际业务中,搜索引擎常与数据源绑定在一起使用,这里我以Mysql为例,将Mysql库里的数据导入到Solr中,并持久化起来.
①从maven中央仓库下载一份适中版本的MySQL的JDBC包:
![]()
②然后将其拷贝至solr-8.3.0\server\solr-webapp\webapp\WEB-INF\lib 目录下
③从solr-8.3.0\example\example-DIH\solr\solr\conf目录下copy一份solr-data-config至solr-8.3.0\server\solr\new_core目录下
![]()
④修改db-data-config中的内容
这里document可以理解为Mysql中的一个库,然后entity可以理解为mysql中的某张表,filed则是对应字段.
⑤配置solrconfig
编辑solr-8.3.0\server\solr\new_core目录下的solrconfig.xml,加入如下内容
db-data-config.xml
完成以上步骤后,重启solr,然后Dataimport->选填信息之后->Execute

执行完成之后,如果它把你“绿了”,那就是成功了,我这里有两万多条数据,全部进搜索引擎了

可以打开query节目验证一下:
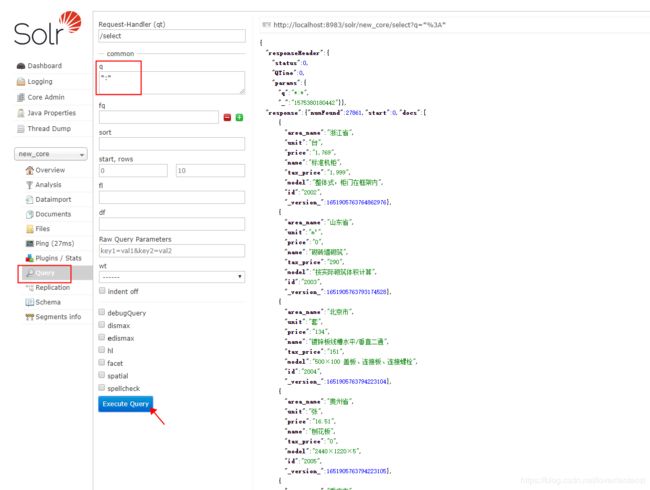
发现数据已被完美导入,也可以通过各种搜索条件灵活查出。
对于数据导入,Solr还支持增量导入,定时导入等强大功能,具体不在此浪费篇幅,有需要可以参考官网:https://lucene.apache.org/solr/guide/8_3/
2.SolrJ使用
2.1SolrJ简介
SolrJ是Apache为Solr配套提供的Java SDK,拥有封装好的方法供开发者调用Solr以开发一些复杂的功能,通过SolrJ,我们便可以通过Java语言,将Solr的功能发挥到极致。
2.2SolrJ实战
2.2.1引入及封装
①在你项目的pom中加入solrJ依赖:
org.apache.solr
solr-solrj
8.3.0
②封装连接
在Solr的使用中会频繁涉及到SolrClient的创建,所以你可以封装一个工具类或者静态代码块初始化构建连接,或者用spring去管理都OK,在SpringBoot中可以直接在yml中直接配置...
private final static String SOLR_URL = "http://localhost:8983/solr/new_core"; /**
* 构建链接
*
* @return
*/
private static SolrClient build() {
return new HttpSolrClient.Builder(SOLR_URL)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build();
}
2.2.2普通参数查询
Solr提供用Map来组装参数进行查询的方式,虽然非常灵活,但个人感觉封装不够友好,用起来不方便:
/**
* 采用普通Map参数查询
*
* @param client
* @return
* @throws IOException
* @throws SolrServerException
*/
private static SolrDocumentList testMapParam(SolrClient client) throws IOException, SolrServerException {
//构建查询参数
final Map queryParamMap = new HashMap<>(4);
queryParamMap.put("q", "*:*");
MapSolrParams queryParams = new MapSolrParams(queryParamMap);
//do查询
final QueryResponse response = client.query(queryParams);
return response.getResults();
} public static void main(String[] args) throws IOException, SolrServerException {
final SolrClient client = build();
测试普通Map参数查询
SolrDocumentList documents = testMapParam(client);
documents.forEach(System.out::println);
}
2.2.3Query参数查询
相比之下,采用SolrQuery进行查询就友好很多,相似的功能阿里的openSerach也有提供
/**
* 采用SolrQuery参数查询
*
* @param client
* @return
* @throws IOException
* @throws SolrServerException
*/
private static List testQueryParam(SolrClient client) throws IOException, SolrServerException {
//构建查询参数
SolrQuery query = new SolrQuery();
query.setSort("id", ORDER.asc);
query.setParam("q", "model:*钢* && price:0");
//do查询
final QueryResponse response = client.query(query);
return response.getBeans(MainMaterial.class);
}2.2.4分词及高亮查询
关于分词查询,8.3版本在获取分词时有bug,坑了我一下午,用网上的方法会NPE,但我用另外一种方式实现了,虽然不那么优雅,期待官方修复,分词查询的流程大致如下:
我输入一段文字,然后系统会按照中文分词把这段文字进行分词,然后根据分词后的关键词进行查询,把匹配到的结果进行"高亮"显示.整个过程可以类比我们去百度搜索某项内容
/**
* 采用分词查询及高亮显示
*
* @param client
* @param text
* @param targetField
* @return
* @throws IOException
* @throws SolrServerException
*/
private static List testQueryParam(SolrClient client, String text, String targetField)
throws IOException, SolrServerException {
//构建查询参数
SolrQuery query = new SolrQuery();
query.setSort("id", ORDER.asc);
//将搜索语句进行分词,并组装
List analysisList = getAnalysisList(client, text);
StringBuilder sb = new StringBuilder();
for (int i = 0; i < analysisList.size(); i++) {
sb.append(targetField)
.append(":")
.append("*")
.append(analysisList.get(i))
.append("*")
.append(" ");
if (i < analysisList.size() - 1) {
sb.append("||").append(" ");
}
}
//设置高亮
query.setHighlight(true);
query.setParam("q", sb.toString());
query.addHighlightField(targetField);
query.setHighlightSimplePre("");
query.setHighlightSimplePost("/");
//do查询
final QueryResponse response = client.query(query);
//打印高亮字段
System.out.println("高亮:" + response.getHighlighting());
return response.getBeans(MainMaterial.class);
}
/**
* 获取分词后的词组
*
* @param client
* @param text
* @return
* @throws IOException
* @throws SolrServerException
*/
private static List getAnalysisList(SolrClient client, String text)
throws IOException, SolrServerException {
//创建请求对象
FieldAnalysisRequest request = new FieldAnalysisRequest(ANALYSIS_URI);
request.setFieldValue(text);
//设置分词类型,我这里采用ik
request.addFieldType("text-ik");
FieldAnalysisResponse response = request.process(client);
//把执行结果中的分词拿出来
List result = new ArrayList<>();
response.getAllFieldTypeAnalysis().forEach(f -> {
f.getValue().getIndexPhases().forEach(i -> {
i.getTokens().forEach(t -> result.add(t.getText()));
});
});
return result;
} 效果,我搜索:"超级无敌钢制防盗门",Solr从我提供的几万条主材数据中查询出了相似的内容:
![]()
整体还是比较简单,完整代码我也贴一份出来供大家参考:
public class Test {
private final static String SOLR_URL = "http://localhost:8983/solr/new_core";
private final static String ANALYSIS_URI = "/analysis/field";
public static void main(String[] args) throws IOException, SolrServerException {
final SolrClient client = build();
//测试普通Map参数查询
//SolrDocumentList documents = testMapParam(client);
//documents.forEach(System.out::println);
//System.out.println(documents.size());
//测试query参数查询
//List list = testQueryParam(client);
//list.forEach(System.out::println);
String text = "超级无敌钢制防盗木门";
String targetField = "model";
List list = testQueryParam(client, text, targetField);
list.forEach(System.out::println);
}
/**
* 构建链接
*
* @return
*/
private static SolrClient build() {
return new HttpSolrClient.Builder(SOLR_URL)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build();
}
/**
* 采用普通Map参数查询
*
* @param client
* @return
* @throws IOException
* @throws SolrServerException
*/
private static SolrDocumentList testMapParam(SolrClient client) throws IOException, SolrServerException {
//构建查询参数
final Map queryParamMap = new HashMap<>(4);
queryParamMap.put("q", "*:*");
MapSolrParams queryParams = new MapSolrParams(queryParamMap);
//do查询
final QueryResponse response = client.query(queryParams);
return response.getResults();
}
/**
* 采用SolrQuery参数查询
*
* @param client
* @return
* @throws IOException
* @throws SolrServerException
*/
private static List testQueryParam(SolrClient client) throws IOException, SolrServerException {
//构建查询参数
SolrQuery query = new SolrQuery();
query.setSort("id", ORDER.asc);
query.setParam("q", "model:*钢* && price:0");
//do查询
final QueryResponse response = client.query(query);
return response.getBeans(MainMaterial.class);
}
/**
* 采用分词查询及高亮显示
*
* @param client
* @param text
* @param targetField
* @return
* @throws IOException
* @throws SolrServerException
*/
private static List testQueryParam(SolrClient client, String text, String targetField)
throws IOException, SolrServerException {
//构建查询参数
SolrQuery query = new SolrQuery();
query.setSort("id", ORDER.asc);
//将搜索语句进行分词,并组装
List analysisList = getAnalysisList(client, text);
StringBuilder sb = new StringBuilder();
for (int i = 0; i < analysisList.size(); i++) {
sb.append(targetField)
.append(":")
.append("*")
.append(analysisList.get(i))
.append("*")
.append(" ");
if (i < analysisList.size() - 1) {
sb.append("||").append(" ");
}
}
//设置高亮
query.setHighlight(true);
query.setParam("q", sb.toString());
query.addHighlightField(targetField);
query.setHighlightSimplePre("");
query.setHighlightSimplePost("/");
//do查询
final QueryResponse response = client.query(query);
//打印高亮字段
System.out.println("高亮:" + response.getHighlighting());
return response.getBeans(MainMaterial.class);
}
/**
* 获取分词后的词组
*
* @param client
* @param text
* @return
* @throws IOException
* @throws SolrServerException
*/
private static List getAnalysisList(SolrClient client, String text)
throws IOException, SolrServerException {
//创建请求对象
FieldAnalysisRequest request = new FieldAnalysisRequest(ANALYSIS_URI);
request.setFieldValue(text);
//设置分词类型,我这里采用ik
request.addFieldType("text-ik");
FieldAnalysisResponse response = request.process(client);
//把执行结果中的分词拿出来
List result = new ArrayList<>();
response.getAllFieldTypeAnalysis().forEach(f -> {
f.getValue().getIndexPhases().forEach(i -> {
i.getTokens().forEach(t -> result.add(t.getText()));
});
});
return result;
}
} @Data
@NoArgsConstructor
@AllArgsConstructor
public class MainMaterial {
@Field
private String id;
@Field
private String model;
@Field
private String name;
@Field
private String price;
@Field("tax_price")
private String taxPrice;
@Field
private String unit;
@Field("area_name")
private String areaName;
}2.3SolrJ总结
solr还提供了对文档及索引的更新,删除,新增等操作,这里也不一一演示了,一篇文章也根本介绍不完,不过个人认为掌握查询即可,其它的可以在需要时翻阅文档.
借助SolrJ,我们可以开发一些功能类似百度的搜索应用,数据可以从各网站上写爬虫爬取,也可以在一些电商应用或数据库读操作压力过大的应用上构建一个搜索引擎,来显著减少负载...总之,很强大.