rabbitmq 生产者创建队列 还是 消费者 创建队列 --- RABBITMQ: WHO CREATES THE QUEUES AND EXCHANGES?
http://gigi.nullneuron.net/gigilabs/rabbitmq-who-creates-the-queues-and-exchanges/
RABBITMQ: WHO CREATES THE QUEUES AND EXCHANGES?
SEPTEMBER 2, 2017 GIGI 4 COMMENTS
Messaging is a fundamental part of any distributed architecture. It allows a publisher to send a message to any number of consumers, without having to know anything about them. This is great for truly asynchronous and decoupled communications.

The above diagram shows a very basic but typical setup you would see when using RabbitMQ. A publisher publishes a message onto an exchange. The exchange handles the logic of routing the message to the queues that are bound to it. For instance, if it is a fanout exchange, then a copy of the same message would be duplicated and placed on each queue. A consumer can then read messages from a queue and process them.
An important assumption for this setup to work is that when publishers and consumers are run, all this RabbitMQ infrastructure (i.e. the queues, exchanges and bindings) must already exist. A publisher would not be able to publish to an exchange that does not exist, and neither could a consumer take messages from an inexistent queue.
Thus, it is not unreasonable to have publishers and/or consumers create the queues, exchanges and bindings they need before beginning to send and receive messages. Let’s take a look at how this may be done, and the implications of each approach.
1. Split Responsibility
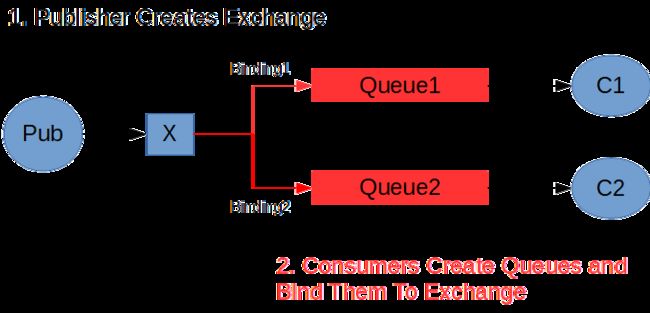
To have publishers and consumers fully decoupled from each other, ideally the publisher should know only about the exchange (not the queues), and the consumers should know only about the queues (not the exchange). The bindings are the glue between the exchange and the queues.
One possible approach could be to have the publisher handle the creation of the exchange, and consumers create the queues they need and bind them to the exchange. This has the advantage of decoupling: as new queues are needed, the consumers that need them will simply create and bind them as needed, without the publisher needing to know anything about them. It is not fully decoupled though, as the consumers must know the exchange in order to bind to it.
On the other hand, there is a very real danger of losing messages. If the publisher is deployed before any consumers are running, then the exchange will have no bindings, and any messages published to it will be lost. Whether this is acceptable is something application-dependent.
2. Publisher Creates Everything
The publisher could be configured to create all the necessary infrastructure (exchanges, queues and bindings) as soon as it runs. This has the advantage that no messages will be lost (because queues will be bound to the exchange without needing any consumers to run first).
However, this means that the publisher must know about all the queues that will be bound to the exchange, which is not a very decoupled approach. Every time a new queue is added, the publisher must be reconfigured and redeployed to create it and bind it.
3. Consumer Creates Everything
The opposite approach is to have consumers create exchanges, queues and bindings that they need, as soon as they run. Like the previous approach, this introduces coupling, because consumers must know the exchange that their queues are binding to. Any change in the exchange (renaming, for instance) means that all consumers must be reconfigured and redeployed. This complexity may be prohibitive when a large number of queues and consumers are present.
4. Neither Creates Anything
A completely different option is for neither the publisher nor the consumer to create any of the required infrastructure. Instead, it is created beforehand using either the user interface of the Management Plugin or the Management CLI. This has several advantages:
- Publishers and consumers can be truly decoupled. Publishers know only about exchanges, and consumers know only about queues.
- This can easily be scripted and automated as part of a deployment pipeline.
- Any changes (e.g. new queues) can be added without needing to touch any of the existing, already-deployed publishers and consumers.
Summary
Asynchronous messaging is a great way to decouple services in a distributed architecture, but to keep them decoupled, a valid strategy for maintaining the underlying messaging constructs (in the case of RabbitMQ, these would be the queues, exchanges and bindings) is necessary.
While publisher and consumer services may themselves take care of creating what they need, there could be a heavy price to pay in terms of initial message loss, coupling, and operational maintenance (in terms of configuration and deployment).
The best approach is probably to handle the messaging system configuration where it belongs: scripting it outside of the application. This ensures that services remain decoupled, and that the queueing system can change dynamically as needed without having to impact a lot of existing services.