【干货】--手把手教你完成文本情感分类
前言
2017年12月9日,参加了天善组织的线下沙龙活动,在沙龙中自己分享了如何借助于R语言完成情感分析的案例,考虑的其他网友没能够参与到活动现场,这里通过微信公众号作一个简单的分享。
在文本分析中,最基础的工作就是如何完成句子、段落或文章的分词,当然这一步也是非常重要的,因为这会直接影响后面文档词条矩阵的构造和模型的有效性。一般而言,在做分词和清洗时需要完成如下三个步骤:
创建一个自定义词库,并根据这个词库实现正确的分词;
删除分词中的停止词(无用词);
删除其他无用词(如字母、数字等);
首先我们以电视剧《猎场》中的一句台词为例,完成上面三个步骤的任务:
# 加载第三方包library(jiebaR)# 台词sentence <- '滚出去!我没有时间听一个牢里混出来的人渣,在这里跟我讲该怎么样不该怎么样!你以为西装往身上一套,我就看不到你骨子里的寒酸,剪剪头、吹吹风,就能掩藏住心里的猥琐?你差得还远,你这种人我见得多了,但还没有见到过敢对我指手画脚的。消失,快从我面前消失!'# 设置动力和引擎engine <- worker()# 查看引擎配置engine在分词之前,需要跟大家介绍两个函数,它们分别是:
worker()—为分词提供动力和引擎
segment()—为分词提供战斗机
首先来看一下默认的分词引擎【worker()】都有哪些配置:
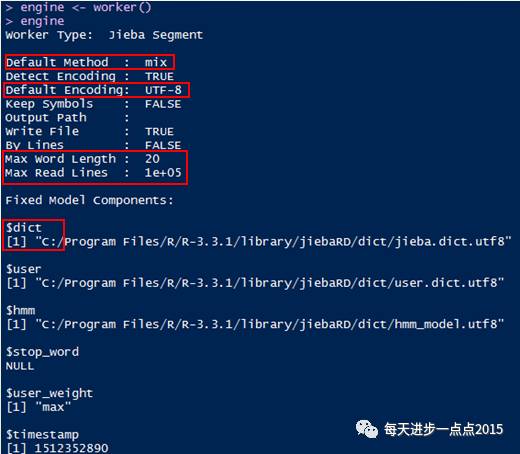
从上图的结果中,我们可知引擎所选择的分词方法是混合法(即最大概率法和隐马尔科夫方法);中文编码为UTF-8;分词最大长度为20个词;一次性可以读取最大10W行记录;同时也提供了超过58W的词库。通过这些默认的配置就可以完成句子的分词,下面我们来看看这段台词的分词效果:
# 分词cuts <- segment(sentence, engine)
cuts
分词结果如上所示,但是你会发现有一些词是切得不正确的,例如“剪剪头”切成了“剪剪”和“头”、“吹吹风”切成了“吹吹”和“风”。按理来说,这些应该作为一个整体被切割,但却被切分开了了。为了避免这种错误的产生,需要用户提供正确切词的词库,然后通过修改worker()函数或使用new_user_word()函数来完成自定义词库的调用:
# 自定义词库--方法一engine2 <- worker(user = 'C:/Program Files/R/R-3.3.1/library/jiebaRD/dict/my_dict.txt')
segment(sentence, engine2)# 自定义词库--方法二new_user_word(engine, c('剪剪头','吹吹风','见到过'))
cuts2 <- segment(sentence, engine)
cuts2第一种方法就是创建词库my_dict文件,并将这个文件路径传递给worker函数;第二种方法使用new_user_word,指定几个自定义词。通过这两种方法,都可以实现正确的切词操作,如下图所示:

词已经按照我们预期的效果完成切割了,但是分词结果中还是存在一些没有意义的停用词(如“的”、“我”、“他”等),为了避免这些停用词对后面建模的影响,需要将这些词删除。这里也通过两种方法实现,具体见下方的代码:
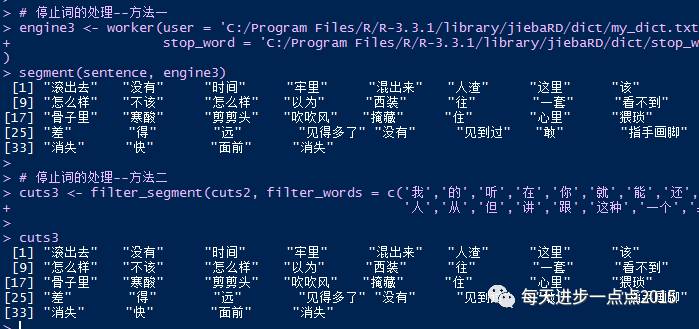
# 停止词的处理--方法一engine3 <- worker(user = 'C:/Program Files/R/R-3.3.1/library/jiebaRD/dict/my_dict.txt',
stop_word = 'C:/Program Files/R/R-3.3.1/library/jiebaRD/dict/stop_words.txt')
segment(sentence, engine3)# 停止词的处理--方法二cuts3 <- filter_segment(cuts2, filter_words = c('我','的','听','在','你','就','能','还','对', '人','从','但','讲','跟','这种','一个','身上'))cuts3第一种方法就是创建停止词词库stop_words文件,并将这个文件路径传递给worker函数;第二种方法使用filter_segment函数,过滤掉指定的那些停止词。通过这两种方法,都可以实现停止词的删除,如下图所示。
由于台词中不包含数字、字母等字符,这里就不说明如何删除这些内容了,但后面的评论数据例子中是含有这些字符的,那边会有代码说明。接下来需要说一说如何构造文档-词条矩阵了,先来看下面这个图:
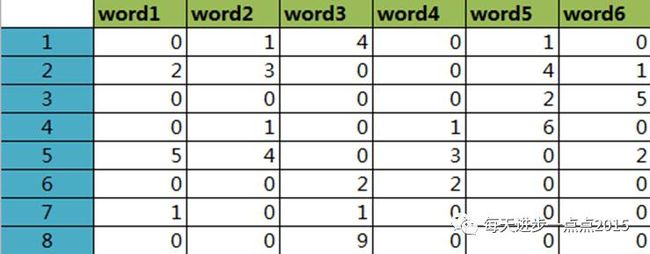
图中的行就代表一个个文档,列就代表一个个词,矩阵中的值就代表每一个词在某个文档中出现的频数。由于不同文档的长度不一致,如果使用简单的频数作为矩阵的值是不理想的。故考虑使用词频-逆文档频率(TFIDF)作为矩阵中的值,其公式如下图所示:

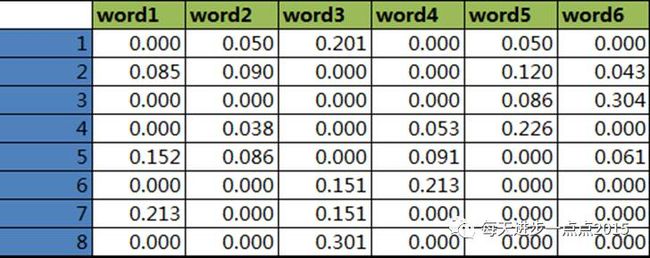
具体计算的结果,可以查看下面的这个文档-词条矩阵图:
在R语言中,构建这个矩阵就太简单了,只需调用tm包中的DocumentTermMatrix()函数即可。下面我们就以某酒店的评论数据为例,来构建这个文档-词条矩阵。
# 导入所需的开发包library(readxl)library(jiebaR)library(plyr)library(stringr)library(tm)library(pROC)library(ggplot2)library(klaR)library(randomForest)# 读取评论数据evaluation <- read_excel(path = file.choose(),sheet = 2)# 查看数据类型str(evaluation)# 转换数据类型evaluation$Emotion <- factor(evaluation$Emotion)# 分词(自定义词和停止词的处理)engine <- worker(user = 'C:\\Users\\Administrator\\Desktop\\HelloBI\\all_words.txt',
stop_word = 'C:\\Users\\Administrator\\Desktop\\HelloBI\\mystopwords.txt')
cuts <- llply(evaluation$Content, segment, engine)#剔除文本中的数字和字母Content <- lapply(cuts,str_replace_all,'[0-9a-zA-Z]','')# 检查是否有空字符创,如有则删除idx <- which(Content == '')
Content2 <- Content[-idx]# 删除含空字符的元素结果Content3 <- llply(Content2, function(x) x[!x == ''])# 将切词的评论转换为语料content_corpus <- Corpus(VectorSource(Content3))# 创建文档-词条矩阵dtm <- DocumentTermMatrix(x = content_corpus,
control = list(weighting = weightTfIdf,
wordLengths = c(2, Inf)))
dtm# 控制稀疏度dtm_remove <- removeSparseTerms(x = dtm, sparse = 0.95)
dtm_remove# 查看变量名
dtm_remove$dimnames$Terms# 转换为数据框df_dtm <- as.data.frame(as.matrix(dtm_remove))
head(df_dtm)
这张图反映的是最初的文档-词条矩阵,显示713个文档,1264个词条,而且这个矩阵的稀疏度为100%。为了降低矩阵的系数度,通过removeSparseTerms()函数设定稀疏度,如下图所示,此时的词条数就压缩到了13个,即13个变量。

接下来,还需要将这个矩阵转换为数据框,因为分类算法(如贝叶斯、随机森林等)不接受上面生成的矩阵类型。有了下面这个数据框,我们就可以将数据集拆分为两部分,一部分用于分类器的构造,另一部分用于验证分类器的效果好坏。
在构建贝叶斯模型之前,还需要简单介绍一下朴素贝叶斯的理论知识,这样有助于对算法的理解。贝叶斯算法核心是计算条件概率,而此处条件概率的计算又依赖于两个前提假设,即连续变量服从正态分布和各解释变量之间是互相独立的。首先来看一下这个条件概率公式,其可以写成下面这个形式:
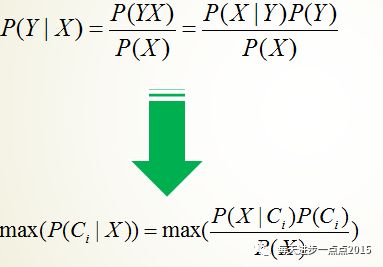
很显然,要求得每个样本下的条件概率最大值,只需求解分子的最大化即可。根据解释变量之间互相独立的假设,还可以将分子转换为下面这个公式:

而下面这个公式的概率是很好求的,在已知某分类的情况下,计算每个变量取值的概率(当X变量离散时,用变量值的频率代替条件概率;当X变量连续时,用变量的正态概率密度值代替条件概率)。OK,原理很简单,在R语言中,通过调用klaR包中的NaiveBayes()函数就可以实现贝叶斯分类器的构建了。函数语法如下:
NaiveBayes(x, grouping, prior, usekernel = FALSE, fL = 0, …)
x指定需要处理的数据,可以是数据框形式,也可以是矩阵形式;
grouping为每个观测样本指定所属类别;
prior可为各个类别指定先验概率,默认情况下用各个类别的样本比例作为先验概率;
usekernel指定密度估计的方法(在无法判断数据的分布时,采用密度密度估计方法),默认情况下使用标准的密度估计,设为TRUE时,则使用核密度估计方法;
fL指定是否进行拉普拉斯修正,默认情况下不对数据进行修正,当数据量较小时,可以设置该参数为1,即进行拉普拉斯修正。
接下来,进入贝叶斯分类器的实战部分,包含模型的构建、测试集的预测和模型的验证,具体代码如下:
# 拆分为训练集和测试集set.seed(1)
index <- sample(1:nrow(df_dtm), size = 0.75*nrow(df_dtm))
train <- df_dtm[index,]
test <- df_dtm[-index,]# 贝叶斯分类器bayes <- NaiveBayes(x = train, grouping = evaluation$Emotion[-idx][index], fL = 1)# 预测pred_bayes <- predict(bayes, newdata = test)
Freq_bayes <- table(pred_bayes$class, evaluation$Emotion[-idx][-index])# 混淆矩阵Freq_bayes# 准确率sum(diag(Freq_bayes))/sum(Freq_bayes)#ROC曲线roc_bayes <- roc(evaluation$Emotion[-idx][-index],factor(pred_bayes$class,ordered = T))
Specificity <- roc_bayes$specificities
Sensitivity <- roc_bayes$sensitivities# 绘制ROC曲线p <- ggplot(data = NULL, mapping = aes(x= 1-Specificity, y = Sensitivity))
p + geom_line(colour = 'red', size = 1) +
coord_cartesian(xlim = c(0,1), ylim = c(0,1)) +
geom_abline(intercept = 0, slope = 1)+
annotate('text', x = 0.5, y = 0.25, label=paste('AUC=',round(roc_curve$auc,2)))+
labs(x = '1-Specificity',y = 'Sensitivity', title = 'ROC Curve') +
theme(plot.title = element_text(hjust = 0.5, face = 'bold', colour = 'brown'))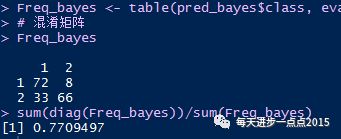
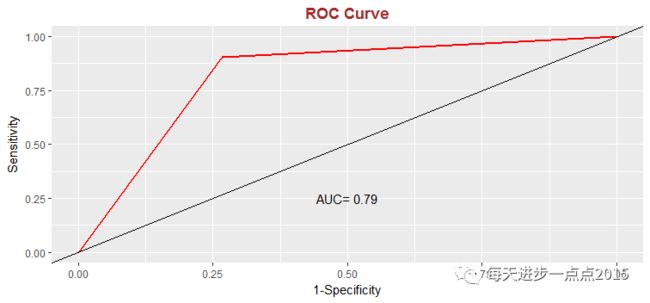
结果如上图所示,模型的准确率为77%(即混淆矩阵中主对角线数值之和除以4个元素之和);ROC曲线下的面积也达到了0.79(理想的AUC在0.8以上)。相对来说,模型的效果还是比较理想的。为了比较,我们再使用一个集成算法(随机森林),看看集成算法是否比单一的贝叶斯算法要好一些。
# 随机森林rf <- randomForest(x = train, y = evaluation$Emotion[-idx][index])
pred_rf <- predict(rf, newdata = test)# 混淆矩阵Freq_rf <- table(pred_rf,evaluation$Emotion[-idx][-index])
Freq_rf# 准确率sum(diag(Freq_rf))/sum(Freq_rf)#ROC曲线roc_rf <- roc(evaluation$Emotion[-idx][-index],factor(pred_rf,ordered = T))
Specificity <- roc_rf$specificities
Sensitivity <- roc_rf$sensitivities# 绘制ROC曲线p <- ggplot(data = NULL, mapping = aes(x= 1-Specificity, y = Sensitivity))
p + geom_line(colour = 'red', size = 1) +
coord_cartesian(xlim = c(0,1), ylim = c(0,1)) +
geom_abline(intercept = 0, slope = 1)+
annotate('text', x = 0.5, y = 0.25, label=paste('AUC=',round(roc_rf$auc,2)))+
labs(x = '1-Specificity',y = 'Sensitivity', title = 'ROC Curve') +
theme(plot.title = element_text(hjust = 0.5, face = 'bold', colour = 'brown'))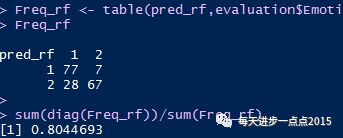
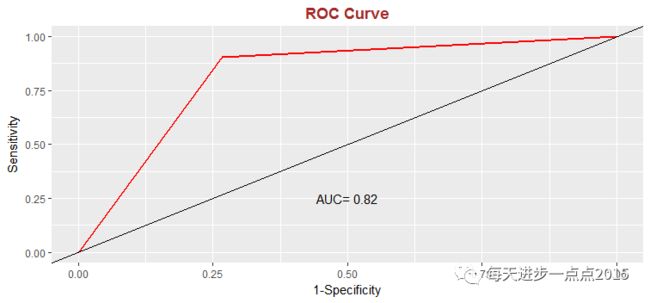
很显然,集成算法要比贝叶斯算法要优秀一些,模型的准确率超过80%,而且AUC值也达到了0.82。
结语
OK,关于使用R语言完成文本情感分类的实战我们就分享到这里,下一期,我将使用Python做一个对比。如果你有任何问题,欢迎在公众号的留言区域表达你的疑问。同时,也欢迎各位朋友继续转发与分享文中的内容,让更多的人学习和进步。
关注“每天进步一点点2015”,回复“文本分析”,即可获得脚本、评论数据、词库等内容!