Rabbitmq基本原理和架构
全栈工程师开发手册 (作者:栾鹏)
架构系列文章
rabbitmq官网:https://www.rabbitmq.com/rabbitmqctl.8.html
MQ全称为Message Queue, 是一种分布式应用程序的的通信方法,它是消费-生产者模型的一个典型的代表,producer往消息队列中不断写入消息,而另一端consumer则可以读取或者订阅队列中的消息。RabbitMQ是MQ产品的典型代表,是一款基于AMQP协议可复用的企业消息系统。业务上,可以实现服务提供者和消费者之间的数据解耦,提供高可用性的消息传输机制,在实际生产中应用相当广泛。本文意在介绍Rabbitmq的基本原理,包括rabbitmq基本框架,概念,通信过程等。
RabbitMQ内建的集群功能可以实现其高可用,允许消费者和生产者在RabbitMQ节点崩溃的情况下继续工作,同时可以通过添加更多的节点来提高消息处理的吞吐量。
系统架构
Rabbitmq系统最核心的组件是Exchange和Queue,下图是系统简单的示意图。Exchange和Queue是在rabbitmq server(又叫做broker)端,producer和consumer在应用端。
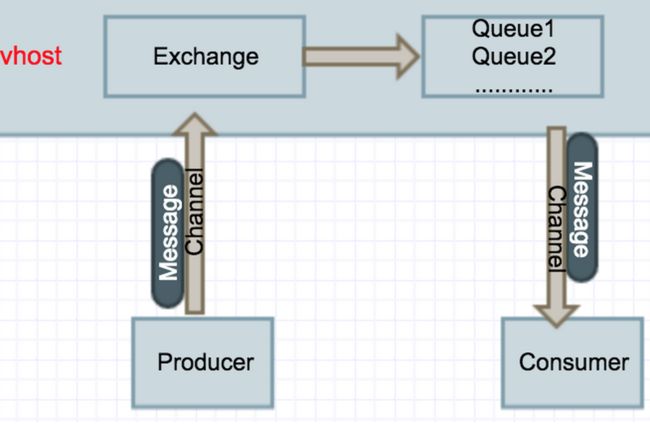
producer&Consumer
producer指的是消息生产者,consumer消息的消费者。
Queue
消息队列,提供了FIFO的处理机制,具有缓存消息的能力。rabbitmq中,队列消息可以设置为持久化,临时或者自动删除。
- 设置为持久化的队列,queue中的消息会在server本地硬盘存储一份,防止系统crash,数据丢失
- 设置为临时队列,queue中的数据在系统重启之后就会丢失
- 设置为自动删除的队列,当不存在用户连接到server,队列中的数据会被自动删除
Exchange
Exchange类似于数据通信网络中的交换机,提供消息路由策略。rabbitmq中,producer不是通过信道直接将消息发送给queue,而是先发送给Exchange。一个Exchange可以和多个Queue进行绑定,producer在传递消息的时候,会传递一个ROUTING_KEY,Exchange会根据这个ROUTING_KEY按照特定的路由算法,将消息路由给指定的queue。和Queue一样,Exchange也可设置为持久化,临时或者自动删除。
Exchange有4种类型:direct(默认),fanout, topic, 和headers,不同类型的Exchange转发消息的策略有所区别:
Direct
直接交换器,工作方式类似于单播,Exchange会将消息发送完全匹配ROUTING_KEY的Queue
fanout
广播是式交换器,不管消息的ROUTING_KEY设置为什么,Exchange都会将消息转发给所有绑定的Queue。
topic
主题交换器,工作方式类似于组播,Exchange会将消息转发和ROUTING_KEY匹配模式相同的所有队列,比如,ROUTING_KEY为user.stock的Message会转发给绑定匹配模式为 * .stock,user.stock, * . * 和#.user.stock.#的队列。( * 表是匹配一个任意词组,#表示匹配0个或多个词组)
headers
消息体的header匹配(ignore)
Binding
所谓绑定就是将一个特定的 Exchange 和一个特定的 Queue 绑定起来。Exchange 和Queue的绑定可以是多对多的关系。
virtual host
在rabbitmq server上可以创建多个虚拟的message broker,又叫做virtual hosts (vhosts)。每一个vhost本质上是一个mini-rabbitmq server,分别管理各自的exchange,和bindings。vhost相当于物理的server,可以为不同app提供边界隔离,使得应用安全的运行在不同的vhost实例上,相互之间不会干扰。producer和consumer连接rabbit server需要指定一个vhost。
通信过程
假设P1和C1注册了相同的Broker,Exchange和Queue。P1发送的消息最终会被C1消费。基本的通信流程大概如下所示:
- P1生产消息,发送给服务器端的Exchange
- Exchange收到消息,根据ROUTINKEY,将消息转发给匹配的Queue1
- Queue1收到消息,将消息发送给订阅者C1
- C1收到消息,发送ACK给队列确认收到消息
- Queue1收到ACK,删除队列中缓存的此条消息
Consumer收到消息时需要显式的向rabbit broker发送basic.ack消息或者consumer订阅消息时设置auto_ack参数为true。在通信过程中,队列对ACK的处理有以下几种情况:
- 如果consumer接收了消息,发送ack,rabbitmq会删除队列中这个消息,发送另一条消息给consumer。
- 如果cosumer接受了消息, 但在发送ack之前断开连接,rabbitmq会认为这条消息没有被deliver,在consumer在次连接的时候,这条消息会被redeliver。
- 如果consumer接受了消息,但是程序中有bug,忘记了ack,rabbitmq不会重复发送消息。
- rabbitmq2.0.0和之后的版本支持consumer reject某条(类)消息,可以通过设置requeue参数中的reject为true达到目地,那么rabbitmq将会把消息发送给下一个注册的consumer。
Meta Data
RabbitMQ内部主要包含以下四种Meta Data:
- vhost meta data:为RabbitMQ内部的Queue, Exchange, Binding提供命名空间级别的隔离
- exchange meta data:记录Exchange的名称、类型、属性等
- binding meta data:表示Routing Key和Queue之间的绑定关系,即描述如何将消息路由到队列Queue中
- queue meta data: 记录队列的名称及其属性
单个节点的RabbitMQ会将这些meta data保存到内存中,同时对于那些属性为持久化的信息,例如durable的Exchange、Queue等持久化到硬盘上,持久化到硬盘上的Exchange和Queue可以在RabbitMQ节点重启后被重新创建。
当以集群形式部署RabbitMQ的多个节点时,RabbitMQ集群需要新的meta data来保存集群的信息。RabbitMQ集群有以下两种模式:
-
普通模式:在这种模式下,对于集群中rabbit1和rabbit2两个节点,一个消息只会存在于其中某个节点上的Queue上。rabbit1和rabbit2这两个节点仅仅是拥有相同的meta data,即队列的结构和属性。当consumer连接rabbi2消费rabbit1上的消息时,RabbitMQ会在这两个节点上进行消息传输,将rabbit1上的消息传输到rabbit2上。在该模式下consumer和producer应该尽量连接每个节点,在多个节点建立物理队列,这样也起到了线性扩展的作用。但是在这种模式下要考虑一种情况,某个节点挂掉时其上面还有没有被消费的消息:如果队列和消息都做了持久化,只有该节点恢复时,消息才可以继续被消费;如果队列和消息没有持久化的话,就会丢失消息。
-
镜像模式:就是把队列做成镜像队列,存在于多个节点上,在该模式下,消息会在节点的镜像队列间做同步,这样可以实现RabbitMQ高可用,但会降低系统性能,特别是镜像队列数量较多,大量消息进入和同步时会占用集群内部大量带宽。因此镜像模式使用于对可靠性要求比较高的场景。
接下来看一下镜像队列的声明,可以通过rabbitmqctl命令或在RabbitMQ Management WebUI中通过创建Policies的方式来声明镜像队列。例如:
rabbitmqctl set_policy ha-all "^ha\." '{"ha-mode":"all"}'
上面这个命令配置了策略,所有名称以ha.开始的队列,都会在集群的所有节点上成为镜像队列。这里使用的ha模式是all,另外还有exactly, nodes两种模式,分别可以指定具体的镜像节点数量,镜像节点名称,可以参考Highly Available (Mirrored) Queues,这里不再展开。
通过上面对RabbitMQ基础知识的一个简单的回顾,在使用RabbitMQ需要考虑一下几点:
- Queue和Message是否要做持久化
- 在使用RabbitMQ的集群时是否要使用镜像队列
可以参考:https://www.jianshu.com/p/5319b06f2e80