数据分析师养成之路--python实战分类案例2(如何调参,选择模型等)
对the Breast Cancer Wisconsin dataset进行分类
1.准备数据
-载入数据,pd.read_csv..
-其中的label,有’M’和‘B’两个值,我们需要标记为数值型
from sklearn.preprocessing import LabelEncoder
le=LabelEncoder()
y=le.fit_transform(y)#这里,原来的y是M和B,得到的y是0,1-划分训练集和训练集
from sklearn.model_selection import train_test_split
#划分百分之80训练集,百分之20验证集
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.20,random_state=1)2.数据处理建模
-标准化原始数据
-PCA降维
-跑模型
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
pipe_lr=Pipeline([('scl',StandardScaler()),
('pca',PCA(n_components=2)),
('clf',LogisticRegression(random_state=1))])
pipe_lr.fit(X_train,y_train)
print(pipe_lr.score(X_test,y_test))
y_pred=pipe_lr.predict(X_test)
3.模型评估
数据需要分成三部分:
–用于训练模型training set
–用于模型选择和调参validation set
–用于评估最终模型泛化能力test set
-交叉验证—更有效的利用数据
k-fold类方法,检验参数模型的鲁棒性(Robustness)
即将所有数据随机分为k组,一组用于验证,其他用于训练,迭代k次
import numpy as np
from sklearn.cross_validation import KFold
#X_train中的数据,随机分成10份
kfold=KFold(n=len(X_train),n_folds=10,random_state=1)
scores=[]
for k,(train,test) in enumerate(kfold):
pipe_lr.fit(X_train[train],y_train[train])
score=pipe_lr.score(X_train[test],y_train[test])
scores.append(score)
print('Fold:%s,class dist.:%s,Acc:%.3f'%(k+1,np.bincount(y_train[train]),score))
print('\nCV accuracy:%.3f+/- %.3f' %(np.mean(scores),np.std(scores)))
可用Stratified k-fold CV方法切分数据,它会尽量保证各标签比例,使模型效果评估更准确(即上class dist,分为10折,Sk-fold保证每折中训练和验证数据的比例不变,而KFold,每折训练,比例都会有变化)。
以上循环过程可以用sklearn里的cross_val_score函数自动实现,默认使用Sk-fold
from sklearn.cross_validation import cross_val_score
scores=cross_val_score(estimator=pipe_lr,X=X_train,y=y_train,cv=10,n_jobs=-1)#使用cpus的内核数
print('CV accuracy scores:\n %s' % scores)
print('CV accuracy:\n %.3f +/- %.3f' % (np.mean(scores), np.std(scores)))
当然得到的效果与上面的是一样的
-学习曲线与验证曲线—提高泛化能力,除掉,过拟合/欠拟合问题
学习曲线:观察训练样本分布本身是否有偏
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.learning_curve import learning_curve
pipe_lr=Pipeline([('scl',StandardScaler()),
('clf',LogisticRegression(penalty='l2',C=0.1,random_state=1))])
#学习曲线中的scores通过SK-fold cv获得
#(随机抽取10%样本-建模-计算Insample/Outsample的Score--随机抽取20%的样本--... )X 10次
#蓝线代表训练score,绿色代表验证score
train_sizes, train_scores, test_scores =learning_curve(estimator=pipe_lr, X=X_train, y=y_train,
train_sizes=np.linspace(0.1, 0.9, 9),#抽取10%,20%...90% 进行建模计算
cv=10, n_jobs=-1)
#画图准备
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
# plot train_mean
plt.subplots(figsize=(16, 8))
plt.plot(train_sizes, train_mean,
color='blue', marker='o',
markersize=5, label='training accuracy')
# plot train_std 用阴影表示标准差波动
plt.fill_between(train_sizes,
train_mean + train_std,
train_mean - train_std,
alpha=0.15, color='blue')
# plot test_mean
plt.plot(train_sizes, test_mean,
color='green', linestyle='--',
marker='s', markersize=5,
label='validation accuracy')
# plot test_std 用阴影表示标准差波动
plt.fill_between(train_sizes,
test_mean + test_std,
test_mean - test_std,
alpha=0.15, color='green')
plt.grid()
plt.xlabel('Number of training samples')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.ylim([0.9, 1.0])
plt.tight_layout()
# plt.savefig('./figures/learning_curve.png', dpi=300)
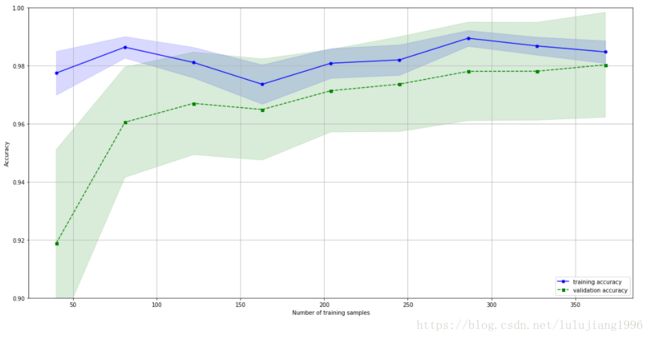
由上图可看出,从样本分布而言,均匀性良好,即使低于总样本30%样本进行建模,依然获得不错的准确度。然而蓝色的训练曲线明显好于绿色的验证曲线,可能存在着过拟合的问题。
-通过验证曲线改善Overfitting和Underfitting问题
from sklearn.learning_curve import validation_curve
# 设定参数选项
param_range = [0.001, 0.01, 0.1, 1.0, 10.0, 100.0]
# 通过 CV 获得不同参数的模型效果
train_scores, test_scores = validation_curve(estimator=pipe_lr,
X=X_train, y=y_train,
param_name='clf__C', # 用 pipe_lr.get_params() 找到参数对应的名称
param_range=param_range, cv=10)
#画图
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
plt.subplots(figsize=(16, 8))
plt.plot(param_range, train_mean,
color='blue', marker='o',
markersize=5, label='training accuracy')
plt.fill_between(param_range, train_mean + train_std,
train_mean - train_std, alpha=0.15,
color='blue')
plt.plot(param_range, test_mean,
color='green', linestyle='--',
marker='s', markersize=5,
label='validation accuracy')
plt.fill_between(param_range,
test_mean + test_std,
test_mean - test_std,
alpha=0.15, color='green')
plt.grid()
plt.xscale('log')
plt.legend(loc='lower right')
plt.xlabel('Parameter C')
plt.ylabel('Accuracy')
plt.ylim([0.9, 1.0])
plt.tight_layout()
# plt.savefig('./figures/validation_curve.png', dpi=300)
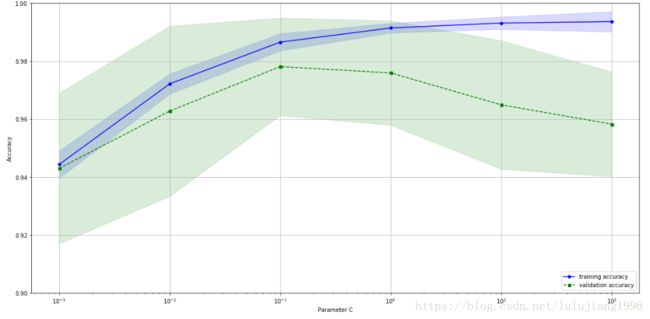
如上图,随着C增加(Regularization减少),模型由underfit—optimal—overfit
最佳C参数应选用0.1
-Grid Search调参—参数调优,找到最好的参数
# brute-force exhaustive search, 遍历
from sklearn.grid_search import GridSearchCV
from sklearn.svm import SVC
svc = SVC(random_state=1)
param_range = [0.0001, 0.001, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0]
param_grid = {'C': param_range}
gs = GridSearchCV(estimator=svc,
param_grid=param_grid,
scoring='accuracy',
cv=10,
n_jobs=-1) # use all CPU
gs = gs.fit(X_train, y_train)
print(gs.best_score_) # validation accuracy best
print(gs.best_params_)结合Pipeline和gridSearch
pipe_svc = Pipeline([('scl', StandardScaler()),
('clf', SVC(random_state=1))])
# linear SVM: inverse regularization parameter C
# RBF kernel SVM: both C and gamma parameter
param_range = [0.0001, 0.001, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0]
param_grid = [{'clf__C': param_range,
'clf__kernel': ['linear']},
{'clf__C': param_range, 'clf__gamma': param_range,
'clf__kernel': ['rbf']}]
gs = GridSearchCV(estimator=pipe_svc,
param_grid=param_grid,
scoring='accuracy',
cv=10,
n_jobs=-1) # use all CPU
gs = gs.fit(X_train, y_train)
print(gs.best_score_) # validation accuracy best
print(gs.best_params_)0.978021978022
{'clf__C': 0.1, 'clf__kernel': 'linear'}
# 看在测试集上的效果
clf = gs.best_estimator_
clf.fit(X_train, y_train)
print('Test accuracy: %.3f' % clf.score(X_test, y_test))Test accuracy: 0.965
GridSearch是一个有效的调参方法,但是多参数调参会很复杂
一个可替代的方法是用scikit-learn 中的randomized search
from scipy.stats import expon
from sklearn.grid_search import RandomizedSearchCV
pipe_svc = Pipeline([('scl', StandardScaler()),
('clf', SVC(random_state=1))])
param_dist = {'clf__C': expon(scale=100),
'clf__gamma': expon(scale=0.1),
'clf__kernel': ['rbf']}
np.random.seed(0)
rs = RandomizedSearchCV(estimator=pipe_svc,
param_distributions=param_dist,
n_iter=20, scoring='accuracy',
cv=10, n_jobs=-1)
rs = rs.fit(X_train, y_train)
print(rs.best_score_)
print(rs.best_params_)0.975824175824
{'clf__C': 7.3685354912847876, 'clf__kernel': 'rbf', 'clf__gamma': 0.0091161029119000477}
clf = rs.best_estimator_
clf.fit(X_train, y_train)
print('Test accuracy: %.3f' % clf.score(X_test, y_test))Test accuracy: 0.974
-模型选择--用nested cross-validation
比较SVM和决策树模型
gs = GridSearchCV(estimator=pipe_svc,
param_grid=param_grid,
scoring='accuracy',
cv=2)
scores = cross_val_score(gs, X_train, y_train, scoring='accuracy', cv=5)
print('CV accuracy: %.3f +/- %.3f' % (np.mean(scores), np.std(scores)))CV accuracy: 0.965 +/- 0.025
from sklearn.tree import DecisionTreeClassifier
gs = GridSearchCV(estimator=DecisionTreeClassifier(random_state=0),
param_grid=[{'max_depth': [1, 2, 3, 4, 5, 6, 7, None]}],
scoring='accuracy',
cv=2)
scores = cross_val_score(gs, X_train, y_train, scoring='accuracy', cv=5)
print('CV accuracy: %.3f +/- %.3f' % (np.mean(scores), np.std(scores)))CV accuracy: 0.921 +/- 0.029如以上结果可知,SVM效果更好