信息论实验-通信系统仿真(C++)
实验目的
这是一个综合性的大型实验,通过搭建一个包括信源、信源编译码器、信道、信道编译码器等各模块在内的仿真通信系统, 使学生能够加深对本课程各个重点章节的理解,更好地掌握通信的本质意义。
后面我会将源代码链接给出
实验要求
输入: 各个模块的相关参数
输出:
1.信源产生的原始符号序列
2.信源译码器输出的符号序列
3.信道编码后的信息传输效率
4.整个通信过程的误比特率(BER)
5.信道编译码过程中产生的误码率(BLER)
实验说明
由于搭建一个完整通信系统的工作量较大,所以本实验可以使用Matlab等仿真工具。
下面分别描述系统中各个模块的要求。本程序只使用了C++
离散信源
要求能以指定的概率分布(p,p-1)产生0,1符号构成的二进制信源符号序列。
信源编码
输入时上一步产生的二进制符号序列。要求能选择以下三种中的任意一种
1.无编码(直通)
2.二进制香农-费诺编码
3.二进制霍夫曼编码
当我们在上一步中指定信源的概率分布之后,就可以马上生成这几种编码的码表,实际的编码工作仅
仅只是查表而已。 当然,直接对上一步指定的信源进行编码是不合适的,需要先进行信源的扩展,
换一句话说,需要确定信源分组的长度。 这个长度N也是本系统的一个重要参数,是在系统运行之
前由用户输入的。
信道编码
输入是信源编码器输出的二进制符号序列。编码方式要求能选择以下三种中的任意一种
1.使用无编码
2.3次重复编码
3.Hamming(7,4)码
信道编码器是个简单的一一对应的函数转换模块,没有额外的控制参数,可以事先实现这三种编码器,
统一其输入输出格式,运行时按照指定的类型直接使用即可。
信道
其输入时信道编码器输出的二进制符号序列。经过传输后输出被噪声干扰和损坏了的二进制符号序列。
要求能够模拟理想信道、给定错误概率为p的BSC以及给定符号0,1各自错误概率p,q的任意二进制信道。
信道译码器
由于信源经过信源编码器和信道编码器后的统计特性难以明确给出,所以此时理想译码器准则无法实施。
因此根据第四步给出的信道统计特性,选择采用极大似然译码准则进行译码。
信源译码器
在第二步确定信源编码器之后即可同时确定信源译码器。信源译码器的工作仅仅是简单的查表即可。
实验设计
整个系统我们分为不同的模块进行设计,每个模块执行不同的功能,最后将所有模块连接起来就构成了我们这个通信系统。
模块介绍
- 模块1:信源模块
此模块产生随机信源信号,可根据不同的信息不同属性设置不同的产生概率。
- 模块2:信源编码译码模块
此模块设计信源编码和信源译码器,分别包括Huffman编码,ShannonFano编码
以及无算法编码,即信号不通过任何算法编码直接进入信道编码。
- 模块3:信道编码译码模块
信道编码通过不同的信道编码算法将信源编码后的信号进行映射,映射到另一个空间,
这样信号通过信道后尽管可能会收到随机误差的影响,但通过信道译码算法,可以对错
误的码字进行一定范围的更正这样就在很大程度上减少了信息的损失。这个模块我们实
现了三种编码方式,Hamming(7, 4)编码、三次重复编码、和空编码,空编码即不进行信道
编码算法,直接传输,这些功能我们都可以通过程序仿真出来。
- 模块4:离散信道模块
离散信道模块主要模拟二元离散信道,主要包括两种信道BSC信道和理想信道,BSC信道是需要给定
错误概率的二元离散信道,理想信道是没有干扰的信道。
模块实现流程
通信系统中各个模块相互协作,各自完成自己的任务保证了整个系统的正常运行。图1是我们这个系统的
流程图
从图中我们可以看出信源模块由Source类提供支持,信源编码和译码由SourceCodeUtil类提供函数操作
信道编码译码由ChannelCodeUtil类提供函数操作,各个类的功能我们将在下一节详细介绍。信息先由信源产生,
然后一次经过信源编码器和信道编码器,通过信道,通过信道后的信息需要由信道译码器纠正错误信息,进一步由
信源译码器将压缩的信息提取,最后将信息传输给信宿。
程序实现
实验过程构造的C++ 类
和往常一样,此次的实验也是用C++语言写的,采用面向对象的思想,所以仿真程序中每隔模块都通过
不同的类来实现下面列出此次仿真我写的主要功能类。
-
class Sign 存储信息的结构类
-
class Source 信源操作类
-
class SourceCodeUtil 信源编码译码器设计类
-
class ChannelCodeUtil 信道编码译码器设计类
-
class ChannelBSC 离散无记忆二元信道类
-
class Huffman Huffman编码和译码类
-
class ShannonFano 香农非诺编码译码类
-
class Hamming 汉明编码译码类
-
class ThreeTimes 三次重复信道编码译码类
各个类的依赖关系如下图所示:

从各类的依赖关系中我们可以看出,Sign类是Huffman类和ShannonFano类的
基类,而Hufffman类和ShannonFano类又是SourceCode类的基类。Hamming类和
ThreeTimes类是ChannelCodeUtil类的基类。最后ChannelBSC类、、SourceCodeUtil类
和ChannelCodeUtil类共同支撑住函数。
系统中各个功能的实现
上面从大局总体的角度将各个类的关系弄清楚了,下面我们关心的可能是各个基础类的
具体实现方式是怎样的。
- class Sign
class Sign
{
public:
struct Freq
{
unsigned char num;
int fre = 0;
};
};
Sign类仅有一个结构体Freq,用来存储字符信息。
2. class Source
class Source
{
private:
public:
double probability; //信源分布概率
Source(double probability);
string generate(int length); //产生随机信源
};
- class SourceCodeUtil
class SourceCodeUtil
{
private:
string IntToString(int n)
{
ostringstream streamm;
streamm << n; //n为int类型
return streamm.str();
}
public:
string source;
vector sourcefrc;
vector count(string s);
SourceCodeUtil(string srcStr);
string encode(int type);
string decode(string decodeString, int type, vector data);
};
SourceCodeUtil是信源编码译码器设计类。有一个内部私有类用来将int型数据转化为string类型
有两个共有属性source和sourcefrc分别存储信源信号和信号各个字符出现的频率信息。
四个公有函数,count()、encode()、decode()和SourceCodeUtil()构造函数。
count()函数用来统计各个字符的频率,encode()执行信源编码工作,decode()执行信源解码工作。
- class ChannelCodeUtil
class ChannelCodeUtil
{
public:
string encode(string src, int type);
string decode(string channelthrough, int type);
};
ChannelCodeUtil类是信道编码译码器设计类,仅有两个公有函数,分别是encode()和decode(), 分别执行信道编码和信道解码的工作。
5. class ChannelBSC
class ChannelBSC
{
public:
string through(string src, double p0, double p1);
};
ChannelBSC 类是离散无记忆二元信道类, 仅有一个through()通过函数,这个函数模拟了信息
通过BSC信道。
- class Huffman
class Huffman
{
public:
struct HuffmanNode
{
unsigned char value; //节点值
int frequency = 0; //节点频数
struct HuffmanNode *Lchild = NULL;
struct HuffmanNode *Rchild = NULL;
};
private:
struct CountVector
{
unsigned char value; //字符
int frequency = 0; //字符频数
struct HuffmanNode *nodeAddress = NULL;
};
struct HuffmanCode
{
unsigned char value;
int frequency = 0;
string code;
int codelen;
};
static bool mysortfunction(CountVector A, CountVector B)
{ //用于sort排序算法
return A.frequency < B.frequency;
}
public:
HuffmanNode *root;
long int NumOfChar;
vector charCountFrequency; //用于存储字符频数
vector HuffmanCodeVec;
Huffman(); //构造函数
string encode(string src, vector data); //编码函数
void CreateHuffmanTree(vector charFrequency); //创建huffman树
void GetHuffmanCode(HuffmanNode *root, int len);
string WriteCode(vector hfCode, string str);
string decode(string src, vector data);
};
Huffman类是进行Huffman编码和译码的类参照我的另一篇博文。包含7个属性,和7个函数,其中核心函数是encode(),和 decode()函数,分别执行Huffman 编码和译码操作。
7. class ShannonFano
class Fano
{
public:
struct FanoNode
{
unsigned char value; // 字符
struct FanoNode *Lchild = NULL; //左孩子
struct FanoNode *Rchild = NULL; //右孩子
};
private:
struct CountVector
{
unsigned char value;
int frequency = 0;
struct FanoNode *nodeAddress = NULL;
};
private:
struct FanoCode
{
unsigned char value;
int frequency;
string code;
int codelen;
};
private:
static bool mysortfunction(CountVector A, CountVector B)
{ //排序函数
return A.frequency > B.frequency;
}
public:
FanoNode *root; //存储树的结构
long int NumOfChar;
vector charFrequency; //字符频率
vector FanoCodeVec; //存储Fano码, 包括码长,码字
Fano();
void CreateTree(vector charFrequency, FanoNode *rootNode);
void GetFanoCode(FanoNode* root, int depth);
string WriteCode(vector HFCode, string sourceStr);
string decode(string sourcefile, vector data);
public:
string encode(string src, vector data);
private:
void splitVec(vector charFr, vector &charFr1, vector &charFr2);
};
ShannonFano类是香农非诺编码译码类,和Huffman类比较类似,因为其编码方式和Huffman算法的编码方式
比较接近,所以算法流程近似。不过也有差异,两者构造树的过程有一定的差别。
- class Hamming
class Hamming
{
public:
string encode(string src);
string decode(string src);
private:
int row;
int message[4];//信息位
int S[3]; //校正子
int e[7]; //纠正子
int send[7]; //发送的七位码字
int Y[7]; //收到的七位码字
int C[7]; //接收到的七位代码
int get_code[4]; //接收到的四位信息
int G[4][7] = { { 1,1,0,1,0,0,0 },{ 0,1,1,0,1,0,0 },{ 1,1,1,0,0,1,0 },{ 1,0,1,0,0,0,1 } };
int H[3][7] = { { 1,0,0,1,0,1,1 },{ 0,1,0,1,1,1,0 },{ 0,0,1,0,1,1,1 } };
void CreateCode(int array1[4], int array2[4][7]) //生成七位发送的代码
{
int i, j, m = 0;
for (j = 0; j<7; j++)
{
for (i = 0; i<4; i++)
{
m = (array1[i] * array2[i][j]) ^ m;
}
this->send[j] = m;
m = 0;
}
}
void Syndrome(int array[7], int array1[3][7]) //得出矫正子S
{
int k = 0, a, b;
for (a = 0; a<3; a++)
{
for (b = 0; b<7; b++)
{
k = k ^ (array1[a][b] * array[b]);
}
this->S[a] = k;
k = 0;
}
}
void Comp(int array1[3], int array[3][7]) //得出纠正子e
{
int i = 0, j = 0, m = 1, p;
while (m)
{//j=j+1;
if ((array1[0] == array[0][i]) && (array1[1] == array[1][i]) && (array1[2] == array[2][i]))
{
m = 0;
row = j;
for (p = 0; p<7; p++)
{
if (p == row)
{
this->e[p] = 1;
}
else
{
this->e[p] = 0;
}
}
}
else
{
j = j + 1; i++;
if (i == 7)
{
for (p = 0; p<7; p++)
{
this->e[p] = 0;
}
m = 0;
}
}
}
}
void CorrectCode(int array3[7], int array4[7]) //得出正确的码字
{
int z;
for (z = 0; z<7; z++)
{
this->C[z] = this->Y[z] ^ this->e[z];
}
for (z = 0; z<4; z++)
{
this->get_code[z] = this->C[z + 3];
}
}
string IntToString(int n)
{
ostringstream stream;
stream << n; //n为int类型
return stream.str();
}
};
Hamming类是汉明编码译码类参照Blog,执行信道的Haming(7, 4)编码译码工作,encode() decode()是唯一两个和外部交互的公有函数,执行Hamming(7, 4)的编码和译码工作,剩余的10个属性和5个函数都是内部私有函数,在执行操作时实现算法的细节部分,但不能和外部类成员交互。
9. class ThreeTimes
class ThreeTimes
{
public:
string encode(string src);
string decode(string src);
private:
char Correct(char a, char b, char c);
};
ThreeTimes类是三次重复信道编码译码类,包含两个公有的函数和一个私有的函数,两个公有函数进行重复三次的编码和译码算法,私有函数执行了译码时更正信道产生误差的操作。
仿真结果
第一步输入各个模块需要的参数信息
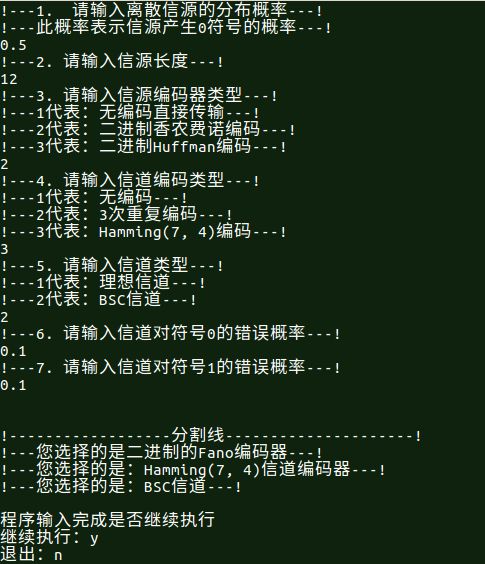
通过对各个模块的参数进行初始设置,首先设定随机信源的信息长度,然后选取一种信源编码方式,rhein我们选择2
也就是Fano编码方式,选取信道编码方式,我们选取Hamming(7, 4)编码方式,接着我们选取BSC信道。最后
指定在信道中字符1和字符0分别传输错误的概率,这里信道并不一定是对称的。
第二步继续执行函数
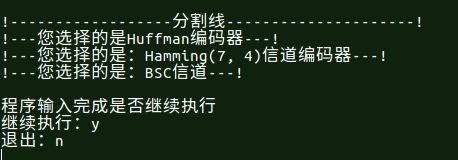
输出选定的参数,让运行程序者进一步确定是否是自己想要的参数,然后继续执行程序。
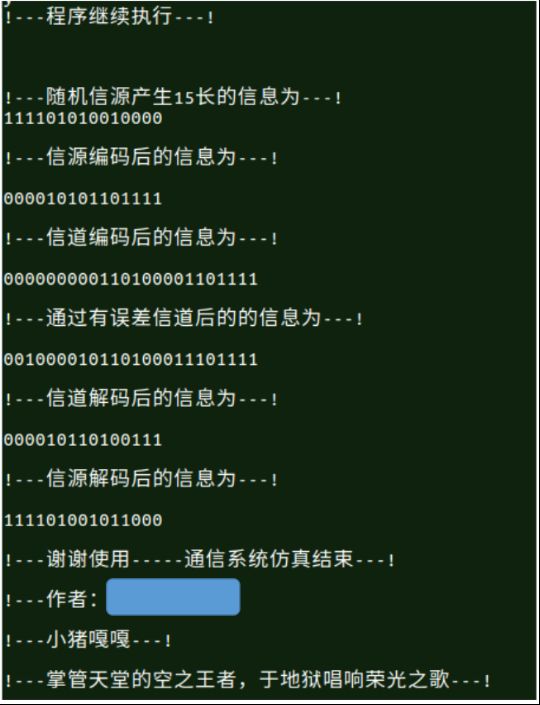
第三步对各个模块的结果进行输出
总结
通过这几次的信息论实验,加上最后一次的综合实验,我们对信息论这门学科有了更深的认识,实验过程
不但很好的巩固了信息论相关的基础知识,而且进一步锻炼了编程能力和动手能力,使我们的思维有了很好的
锻炼。信息论课程的外延很广,因此在学习时对本课程与其他课相关联的内容进行特意地深究,是非常有必要的。这样就可以建立起课程之间的联系,课程与课程之间不再是离散的信息孤岛,而是有框架组织和脉络条理的信息树。这样我们逐渐会把不同课程的知识融会贯通,从而使我们学习的兴趣和动力得到进一步提升。另外,由于信息论方法具有普遍的适用性,因此可以把课上学习的内容和我们的日常生活紧密结合起来,从而提高学习的兴趣。例如,在学习多符号离散信源时,可以和日常生活中大家在电视上见到的摇奖场面联系起来。一台简单的摇奖机,从十个号码球中摇出一个数字号码,可以看作一个单符号离散信源,它有十个符号,从0至9。如果需要摇出七位数的体育彩票号码,这可以看成是一个多符号信源,一次同时发出七个符号,而且是单符号离散信源的7次扩展。又如,在学习汉明距离时,可以和英语学习联系起来。在
英语中拼写非常接近的单词很容易混淆或者拼写错误,用信息论的观点来看就是两个码字的汉明距离(不同位的个数)太小,因此抗干扰的能力差。
信息论是信息科学的主要理论基础之一,它是在长期通信工程实践和理论基础上发展起来的。信息论是应用概率论、随机过程和数理统计和近代代数等方法,来研究信息的存储、传输和处理中一般规律的学科。它的主要目的是提高通信系统的可靠性、有效性和安全性,以便达到系统的最优化。编码理论与信息论紧密
关联,它以信息论基本原理为理论依据,研究编码和译码的理论知识和实现方法。由于信息论方法具有相当普遍的意义和价值,因此在计算机科学、人工智能、语言学、基因工程、神经解剖学甚至金融投资学等众多领域都有广泛的应用,信息论促进了这些学科领域的发展,同时也促进了整个社会经济的发展。人们已经开始利用信息论的方法来探索系统的存在方式和运动变化的规律,信息论已经成为认识世界和改造世界的手段,信息论对哲学领域也有深远的影响。
补充:前文说要放上源代码的,开始写Blog的时候没有整理好,这次将源代码补充上。PiggyGaGa git