InnoDB 事务与锁的前世今生
本文目录:
- 写在开头
- 1.InnoDB 支持的特性
- 2.事务
- Ⅰ. 什么是事务
- Ⅱ. 事务的四个特性(ACID)
- Ⅲ. 事务并发带来的问题
- Ⅳ. 事务四种隔离级别
- Ⅴ.查看 MySQL 事务隔离级别
- Ⅵ.查看 MySQL 是否开启事务
- 3.锁
- 3.1 共享锁(S锁)
- 3.2 排他锁(X锁)
- 3.3 意向锁
- 3.3.1 意向共享锁(IS锁)
- 3.3.2 意向排他锁(IX锁)
- 3.4 自增锁(AUTO-INC Lock)
- 3.5 临键锁 & 间隙锁 & 记录锁
- 3.5.1 临键锁 (Next-key Lock)(InnoDB引擎默认行锁算法)
- 3.5.2 间隙锁(Gap Lock)
- 3.5.3 记录锁(Record Lock)
- 4.事务并发问题解决方案
- 4.1 +X锁,解决脏读问题
- 4.2 +S锁,解决不可重复读问题
- 4.3 +Next key锁,解决幻读问题
- 5. 死锁问题
- 5.1 死锁复现
- 5.2 如何避免死锁
写在开头
在你读到本文时,默认你已经对 MySQL存储引擎、索引 内容有了一定的掌握。如果你对这两个部分的内容还不是太了解,建议你先去了解以下这部分的内容再继续往下读:
- 一文带你看懂 MySQL 存储引擎
- 还不了解 MyISAM 和 InnoDB 的区别?看这里就够了
- MySQL为什么没有走索引?是这些原因在搞鬼
- 一条SQL语句的坎坷之旅(MySQL底层执行流程分析)
- 不会MySQL调优?来来瞅瞅SQL的执行计划吧
1.InnoDB 支持的特性
我们已经知道 MySQL 在 5.5 版本及以后,MyISAM已经让出太子之位,选择 innoDB作为默认存储引擎。InnoDB能够将其拉下马,自然有它的过人之处。下图我们就来细数一下。(该图摘自:MySQL官网,InnoDB 当属C位出道)
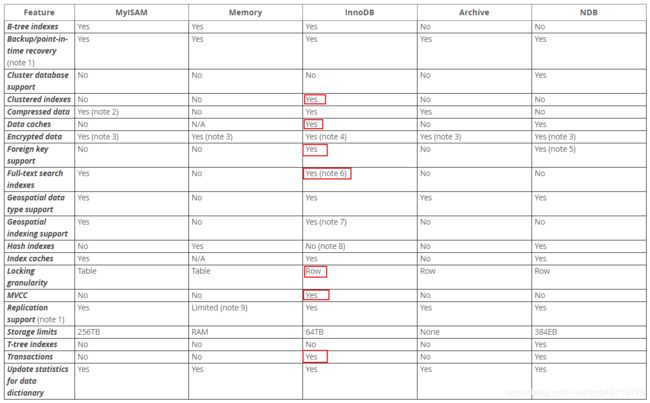
对图分析,我们发现 InnoDB 支持聚集索引(Clustered indexes)、数据缓存、外键、全文索引(MySQL 5.6 and later支持)、行锁、MVCC、事务操作等特性。相比来说:MyISAM 就差了一截了。不过 MyISAM 也有它强的地方,可以参考:还不了解 MyISAM 和 InnoDB 的区别?看这里就够了。
本文就从事务和锁的角度,来对 InnoDB 进行一个全方位的分析,继续往下看↓↓↓
2.事务
Tip:事务的概念,大家应该都了解。此处再累赘一次。本文是 MySQL事务介绍。初学者一定要将此和 Spring 事务有所区分。Spring 事务相关内容,可以来这里瞧瞧:Spring Transaction 源码解析
Ⅰ. 什么是事务
事务(Transaction),是指作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行。 事务处理可以确保除非事务性单元内的所有操作都成功完成,否则不会永久更新面向数据的资源。简单理解事务,即:当前操作要么全部成功,要么全部失败。这样可以简化错误恢复并使应用程序更加可靠。
Ⅱ. 事务的四个特性(ACID)
事务 4 大特性:原子性、一致性、隔离性、持久性。通常称为 ACID 特性。
- 原子性(Atomicity):指一个事务是一个不可分割的工作单元,事务中包括的所有操作要么都完成,要么都不完成。
- 一致性(Consistency):指事务必须是使数据库从
一个一致性状态变到另一个一致性状态,是否一致性与原子性是密切相关的。 - 隔离性(Isolation):指一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对 并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
- 持久性(Durability):指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的,接下来的其他操作或故障不应该对这些数据有任何影响。
一致性这个概念不好理解,举个栗子。eg: 比如银行有2000块,A1000,B1000。A转账100给B,中间出现异常,也不会影响银行2000块这个总数的不一致,不会出现A:1100 、 B 1000 这种情况。
Ⅲ. 事务并发带来的问题
(利用锁来解决,具体解决方案,可参考本文第4部分内容:https://blog.csdn.net/lzb348110175/article/details/106765504#4_240,你可以继续往下看先来了解一下 InnoDB 锁的分类)
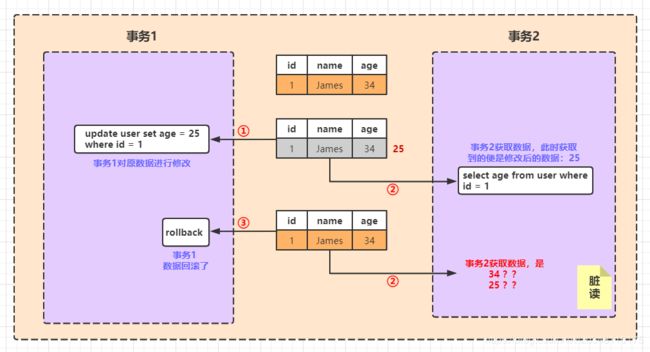
- 脏读 :一个事务对数据进行了增删改,但未提交,另一事务可以读取到未提交的数据。如果第一个事务这时候回滚了,那么第二个事务就读到了脏数据。
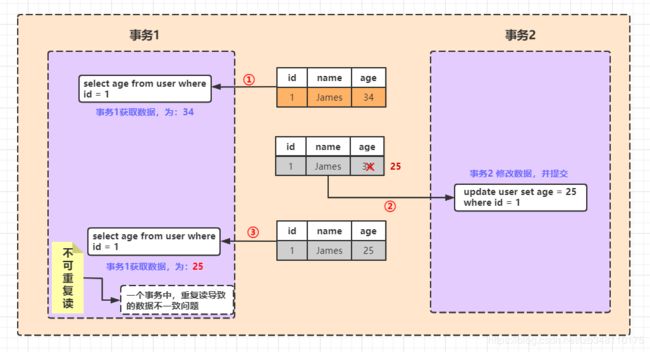
- 不可重复读:一个事务中发生了两次读操作,第一次读操作和第二次操作之间,另外一个事务对数据进行了修改,这就会导致两次读取的数据是不一致的。
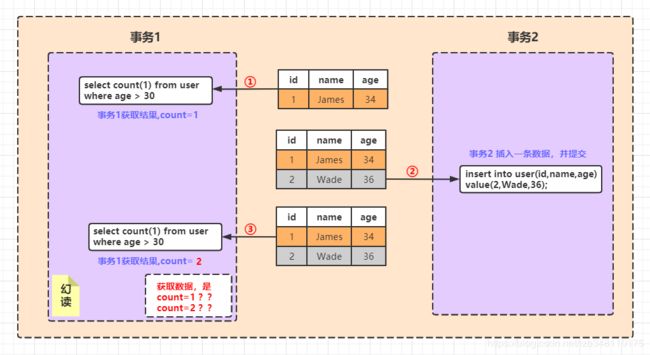
- 幻读:第一个事务对一定范围的数据进行批量修改,第二个事务在这个范围增加一条数据,这时候第一个事务就会丢失对新增数据的修改。
Ⅳ. 事务四种隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 总结(导致的问题) |
|---|---|---|---|---|
| READ UNCOMMITTED(未提交读) | 是 | 是 | 是 | 可能会导致脏读、不可重复读、幻读 |
| READ COMMITTED(已提交读) | 否 | 是 | 是 | 可以解决脏读问题,但是可能会导致不可重复读、幻读 |
| REPEATABLE READ(可重复读) | 否 | 否 | 是 | 可以解决脏读,不可重复读问题,但是允可能会导致幻读 (注:InnoDB除外,InnoDB引擎可解决幻读问题,其他引擎解决不了) |
| SERIALIZABLE(串行化) | 否 | 否 | 否 | 串行化读,事务只能一个一个执行,可以解决脏读、 不 可重复读、幻读。执行效率慢,使用时慎重 |
Ⅴ.查看 MySQL 事务隔离级别
MySQL 默认事务隔离级别为 REPEATABLE-READ
//查看事务隔离级别命令:
select @@tx_isolation;
//修改事务隔离级别命令:
set global/session transaction isolation level 事务隔离级别 //(全局设置:使用global;当前会话设置:使用session)
//具体设置如下:
//设置read uncommitted级别:
set session transaction isolation level read uncommitted;
//设置read committed级别:
set session transaction isolation level read committed;
//设置repeatable read级别:
set session transaction isolation level repeatable read;
//设置serializable级别:
set session transaction isolation level serializable;
Ⅵ.查看 MySQL 是否开启事务
MySQL 事务默认是打开状态。①我们可以设置全局事务开启; ②也可以针对某个会话开启/关闭事务。
//查看当前数据库是否开启事务(会话级别,等同于 show session variables like 'autocommit')
show variables like 'autocommit';
//查看全局事务状态
show global variables like 'autocommit';
//查看当前会话事务状态
show session variables like 'autocommit';
//关闭/开启事务(会话级别,等同于 set session autocommit = off))
set autocommit = off/on;
//关闭/开启全局事务
set global autocommit = off/on;
//关闭/开启会话事务
set session autocommit = off/on;
关闭 MySQL 事务之后,我们也可以通过手动的方式来开启一个事务。
START TRANSACTION;//开启一个事务(BEGIN;也可以,二选一)
select * from orders where id = 4 name = '徐勇';//SQL查询
rollback;//事务回滚
commit;//或事务提交
3.锁
锁的出现,就是用于解决不同事务对共享资源并发访问所引起的脏读、不可重复读、幻读问题。
MySQL InnoDB 锁类型,分别是:共享锁(Shard Lock)、排它锁(Exclusive Lock)、意向共享锁(Intention Shared Lock)、意向排它锁(Intention Exclusive Lock)、自增锁(AUTO-INC Lock)、临键锁(Next-key Lock)、间隙锁(Gap Lock)、记录锁(Record Lock) 八种。(记录锁、间隙锁、临键锁这三种锁,都是行锁的具体实现算法。我们可以将其理解为锁类型,也可以理解为行锁的具体实现算法)
提示:接下来锁相关介绍,均以事务关闭状态,手工开启为前提来进行demo演示。
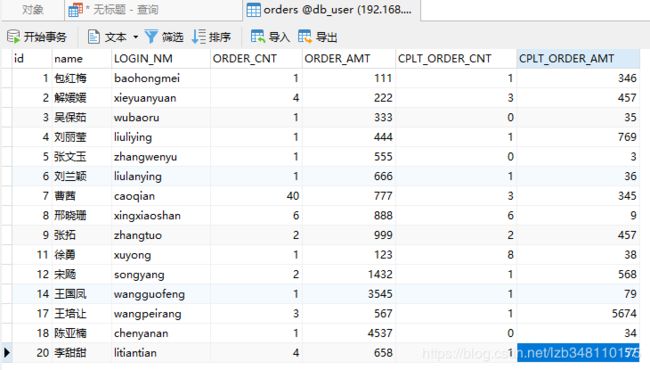
orders 表数据:
3.1 共享锁(S锁)
又称为读锁。简称S锁。 行级锁,未命中索引会退变为表锁。顾名思义,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。添加共享锁方式如下:
// 在查询语句末尾,需要通过 LOCK IN SHARE MODE 的方式添加共享锁
select * from users where id = 1 LOCK IN SHARE MODE;
测试:
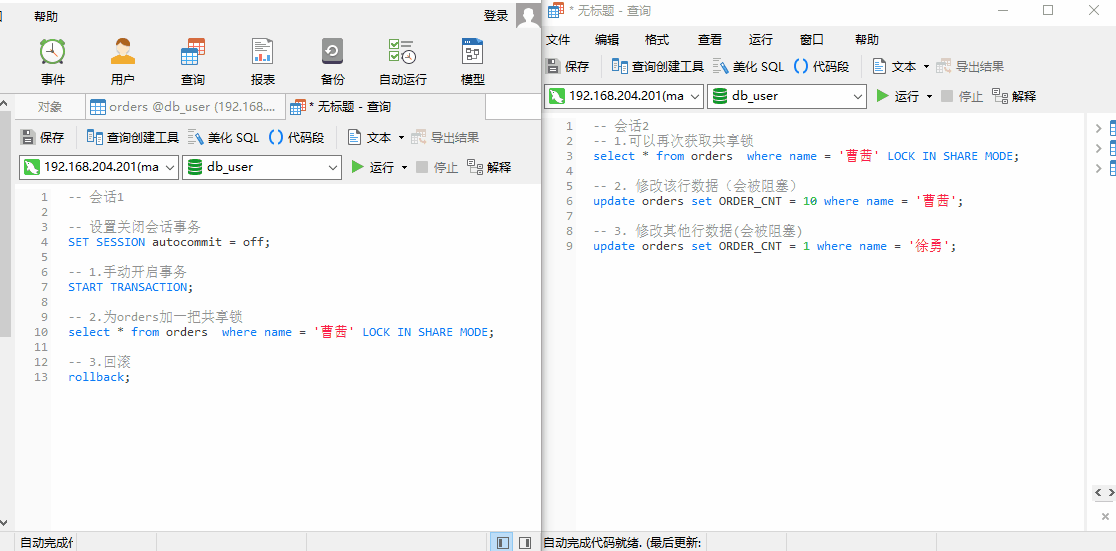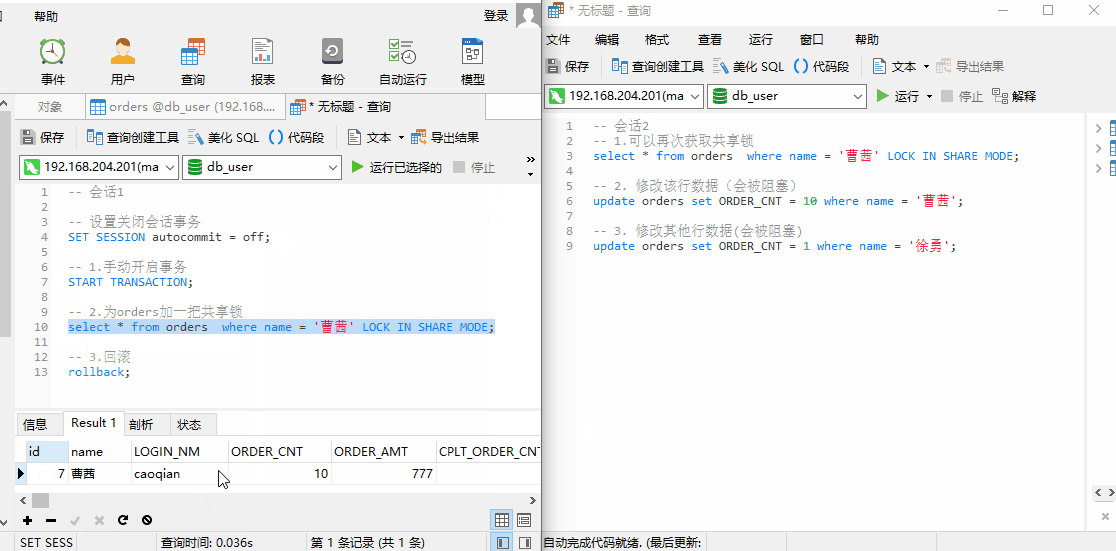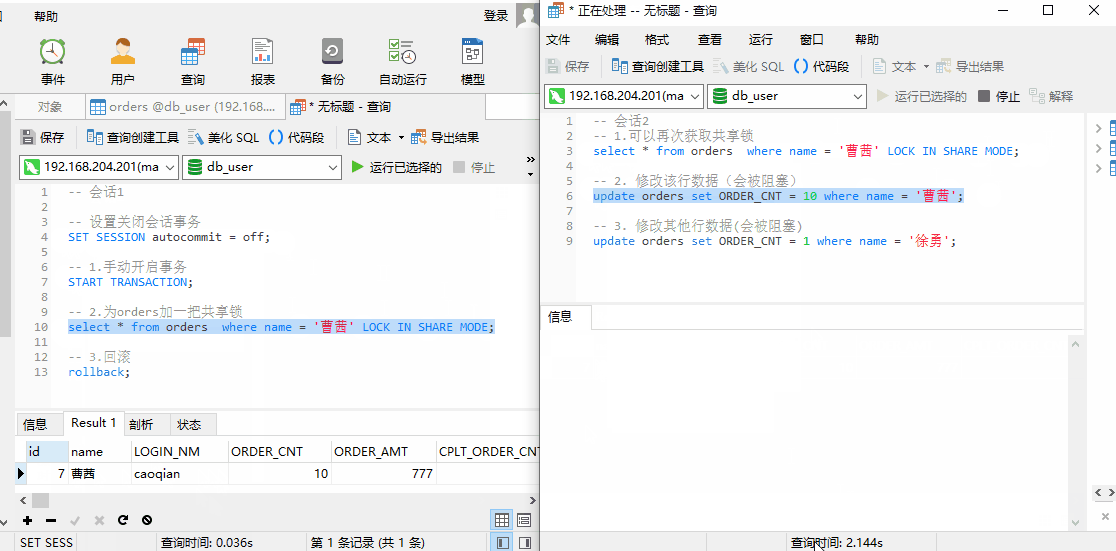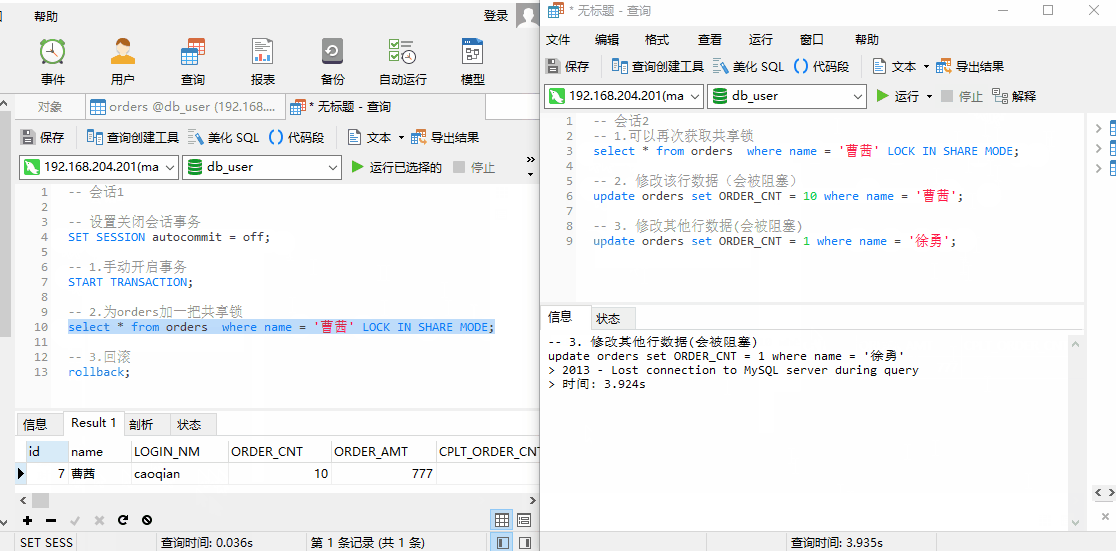
测试结果:
- 会话 1 关闭会话事务,并手动开启当前会话事务,为 orders 表加一把共享锁;
- 此时会话 2 ,可以再次获取该行数据 的共享锁;
- 共享锁只能读,不支持修改。所以对
曹茜、徐勇两条数据进行修改时,都会被阻塞。(因为没有创建 name 字段索引,所以都会被阻塞) - 当我们创建 name 字段索引后,以 name 字段查询来修改
徐勇这条数据时,由于命中索引,所以此处不会被阻塞。(想要测试,请自行创建吧)
说明:
添加共享锁之后,如果查询未命中索引,则不会使用行锁,会退变为表锁。所以在没有创建name索引时,修改徐勇数据时,会被阻塞;
当创建name索引后,由于查询命中索引,所以行锁将曹茜这条数据锁住,并不会影响表中其他数据的操作。此时修改徐勇这条数据能够成功。
由于行锁、表锁的原因,其他事务会处于等待状态。锁超时等待,默认为 50 s。我们可通过命令:show variables like ‘innodb_lock_wait_timeout’;来查看(CSDN原因,将引号修改为英文状态单引号)。锁超时时间也分会话/全局级别,我们可通过set session innodb_lock_wait_timeout = 20; 或 set global innodb_lock_wait_timeout = 20; 来进行修改设置。
3.2 排他锁(X锁)
又称写锁,简称X锁。 行级锁,未命中索引会退变为表锁。排他锁不能与其他锁并存。如一个事务获取了一个数据行的排他锁,那么其他事务就不能再获取该行的锁(共享锁、排他锁),只有该获取了排他锁的事务是可以对这一数据行进行读取和修改。(其他事务可以读取数据,数据来自于快照(快照相关,和 MySQL MVCC 相关 :MVCC介绍))添加排他锁方式如下:
//删除、修改、插入,默认会加上X锁
delete /update / insert
//查询语句,需要通过 FOR UPDATE 的方式添加排他锁
select * from users where id = 1 FOR UPDATE
测试:
测试结果:
- 如果不创建 name 字段索引,以name字段查询并不会命不中索引,会退变为表锁。同共享锁类似,修改
徐勇数据也会被阻塞; - 此时,我们以创建 name 字段索引来介绍。会话1 我们为 orders 表加一把排他锁后,会话 2 便不能够获取该数据的共享锁/排它锁;
- 修改数据时,由于有排它锁的原因,该行已经被锁住,所以修改同样会被阻塞;
- 但是修改其他行,由于命中 name 索引,所以使用了行锁,其他行数据还是可以被修改的,所以
徐勇这条数据是可以修改成功的。
说明:
添加排他锁之后,如果 name 字段查询未命中索引,则不会使用行锁,会退变为表锁。所以在没有创建name索引时,修改徐勇数据时,会被阻塞;
当创建name索引后,由于 name 字段查询命中索引,所以行锁会将曹茜这条数据锁住(其他会话无法获取该条数据的共享锁、排它锁),并不会影响表中其他数据的操作。此时修改徐勇这条数据能够成功。
此时查询数据是可以正常进行的。是因为 InnoDB 还有一个"一致性的非锁定读"的概念,就是说行锁未释放之前,其他事务读取该行数据读取的是它的快照数据,并不会与行锁冲突
由于行锁、表锁的原因,其他事务会处于等待状态。锁超时等待,默认为 50 s。如何修改,参考 3.1 共享锁。
3.3 意向锁
意向锁的由来,我们来分析下面这个示例:
多个事务:A、B、C三个事务为例;
-
A事务添加了行锁,此时其他事务无法再添加表锁,但是可以添加(其他行的)行锁;
-
A事务如果添加了表锁,那么其他事务则无法再添加行锁、表锁。
-
即:一个表,不同行可以有多个行锁。但是 行锁和表锁只能二选一存在。(这就是因为 IS、IX锁的原因)
3.3.1 意向共享锁(IS锁)
表锁。表示事务准备给数据行加入共享锁时,即一个数据行加共享锁前必须先取得该表的 IS 锁, 意向共享锁之间是可以相互兼容的
3.3.2 意向排他锁(IX锁)
表锁。表示事务准备给数据行加入排他锁时,即一个数据行加排他锁前必须先取得该表的 IX 锁, 意向排它锁之间是可以相互兼容的
意向锁(IS锁、IX锁)是 InnoDB 数据操作之前自动加的,不需要用户干预。所以此处不做介绍,有个概念即可。当事务想去进行锁表时,可以先判断意向锁是否存在,存在时则可快速返回该表不能启用表锁。
Tips:意向锁相当于 Java 中的 flag,就是一个标记,在加锁前会判断该表是否有锁。
3.4 自增锁(AUTO-INC Lock)
自增锁,是针对自增列自增长的一个特殊的表级别锁。比如说我们建表时,通常会指定某一列为 id 自增长列,该列便会使用到这个自增锁。
自增锁有一个默认值,是从 1 开始的,这个值不建议大家随意修改。我们可以通过命令:show variables like ‘innodb_autoinc_lock_mode’;(CSDN原因,将引号修改为英文状态单引号)。通常情况下,我们在数据库表中会发现自增 id 列并不连续,这就是自增锁在搞事情。
当我们插入数据时,自增锁会 +1,但是此时如果事务执行了 rollback 等其他操作,导致数据并没有插入成功,此时自增锁 id 并不会随之回退,会永久丢失,从而导致的自增 id 列不连续。
3.5 临键锁 & 间隙锁 & 记录锁
这三种锁,都是行锁。我们可以将其单独理解为一种类型的锁。此处我将这三种锁理解为是MySQL InnoDB 行级锁实现的三种算法来介绍。这块你怎么理解都可以,我是更倾向于行级锁的是那种实现算法。
以下示例,对表数据进行修改,增大数据之间的区间。
orders 表数据:(已添加 id 字段索引)

3.5.1 临键锁 (Next-key Lock)(InnoDB引擎默认行锁算法)
临键锁(Next-key Lock),作为 InnoDB 引擎默认行锁算法。就是解决 幻读 问题。当 SQL 执行按照索引进行数据查询时,查询条件为范围查找(between and 、< 、> 等)并有数据命中时,此时 SQL 语句加上的锁为 Next-key Lock,锁住的是索引的记录+下一个区间(左开右闭)。
使用临键锁条件:
- 查询命中索引;
- 范围查询;
- 有数据命中时。
测试结果:
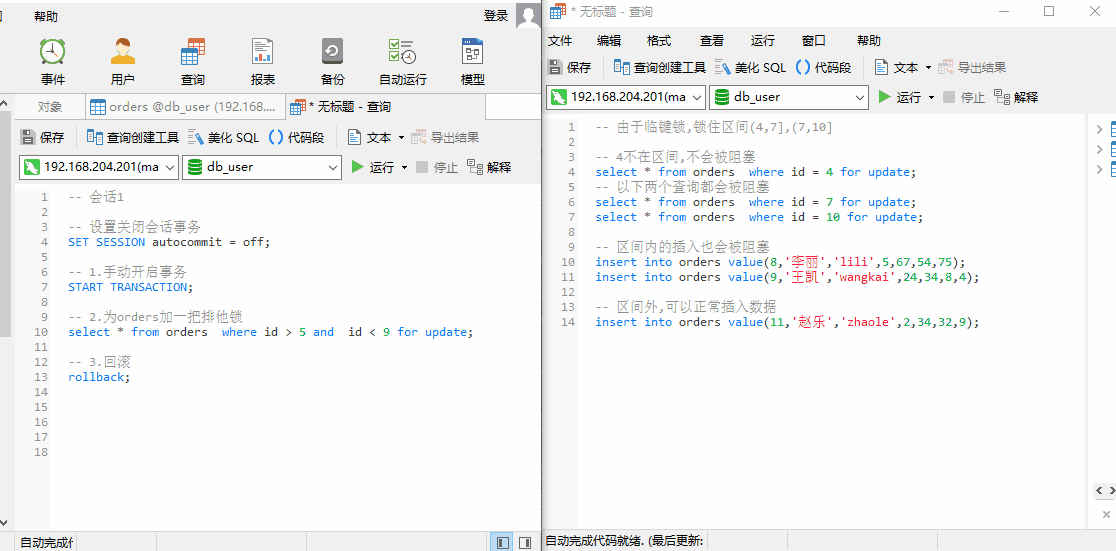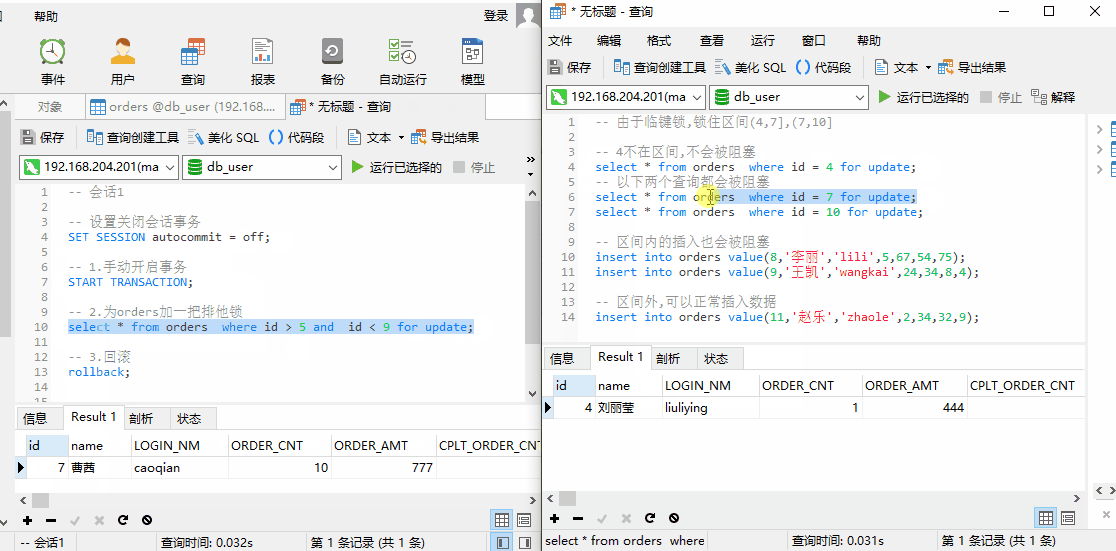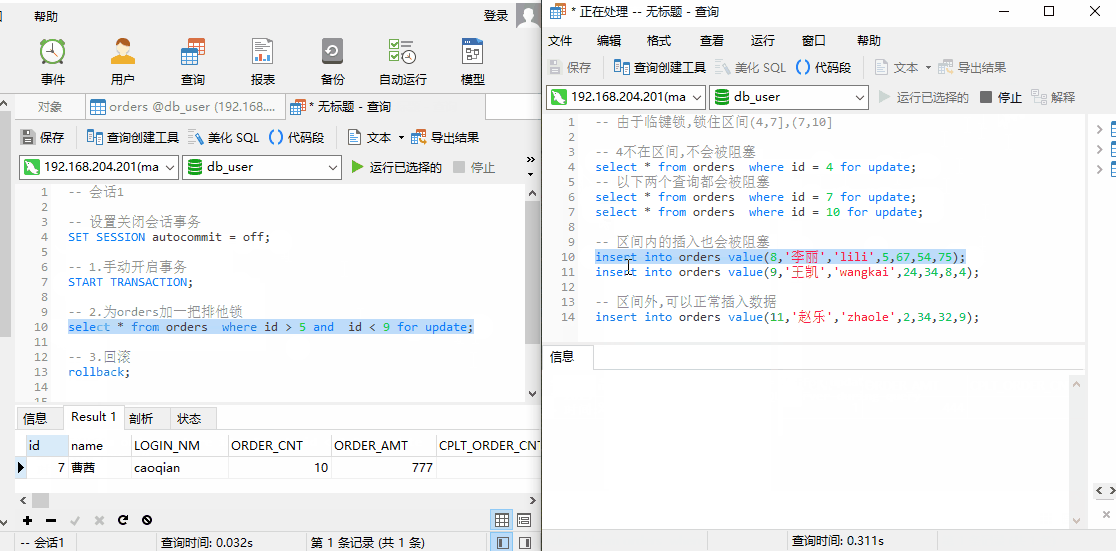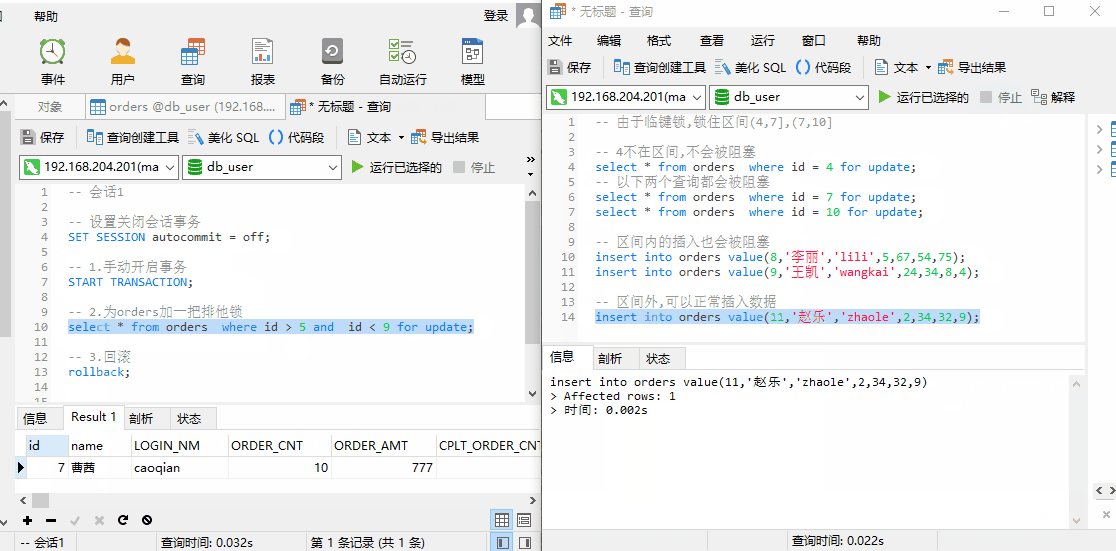
我们使用 SQL 进行查询。针对 orders 表中的数据,InnoDB 引擎会将数据进行如下区间划分:并锁住当前数据所在区间+下一个区间。

此时,我们对 id = 4 进行查询,由于不在锁住区间内,并不会阻塞;id = 7,10 进行查询,插入id = 8,9 的数据。发现都会被阻塞。当我们插入 id = 11 时,可以成功插入,说明上述查询锁住的区间为 (4,7],(7,10]
临键锁,为什么要锁住下一个区间?
这和索引底层 B+Tree 有关系。MySQL 索引底层选择 B+Tree。B+Tree 数据都保存在叶子节点,并且具有顺序性,从左到右依次增大。临键锁锁住相邻区间,此时 insert 插入数据时,我们并不能够将数据成功的插入到该区间,就能够满足每次查询的数据一致,从而解决幻读问题。
示例解释:还是select * from orders where id > 5 and id < 9 for update;这个查询,事务A 第一次查询出来一条 id = 7 的数据。如果不锁住相邻区间,此时事务B 插入了一条 id = 8 的数据。那么事务A 在插入时就会查询出 2 条数据。如果锁住相邻区间,那么只要在事务 A 没结束期间,查询到的都会只有 id = 7 这1条数据。这就解决了幻读问题。
彩蛋:你还不了解 MySQL 索引选择 B+Tree??? 请参考这篇博文:MySQL 索引底层为什么选择B+Tree
3.5.2 间隙锁(Gap Lock)
间隙锁(Gap Lock)。当 SQL 执行按照索引进行数据查询时,查询条件的数据不存在,此时 SQL 语句加上的锁即为 Gap Lock,锁住的是数据不存在的区间(左开右开)。
使用间隙锁条件:
- 查询命中索引;
- 范围查询
- 无数据命中时。
测试结果:
同临键锁类似,当查询无数据命中时,临键锁(Next-key Lock) 便会退变成 Gap 锁。Gap 锁锁住的是数据不存在的区间(左开右开)。如下图所示:
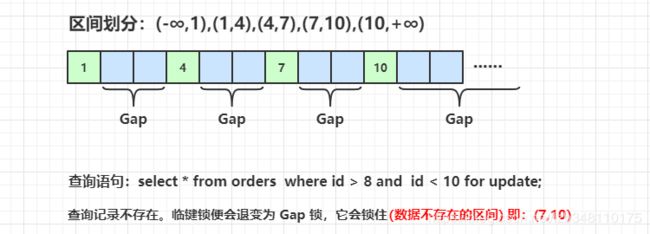
由于锁住(7,10)这个区间,此时我们无法插入 id = 8,9 的数据,我们可以插入 id = 11 的数据,说明上述查询 Gap 锁,锁住的区间为 (7,10)。
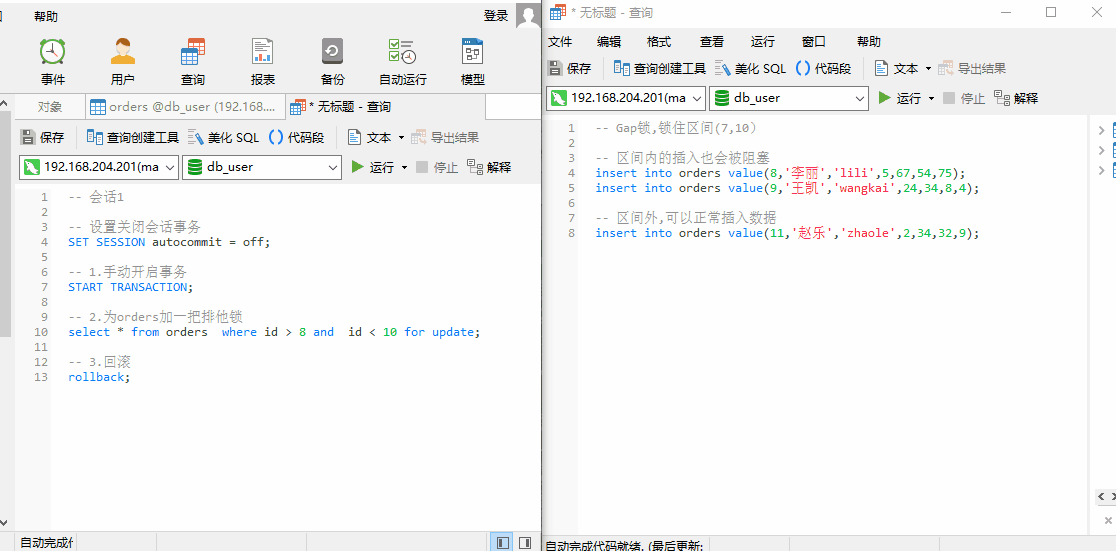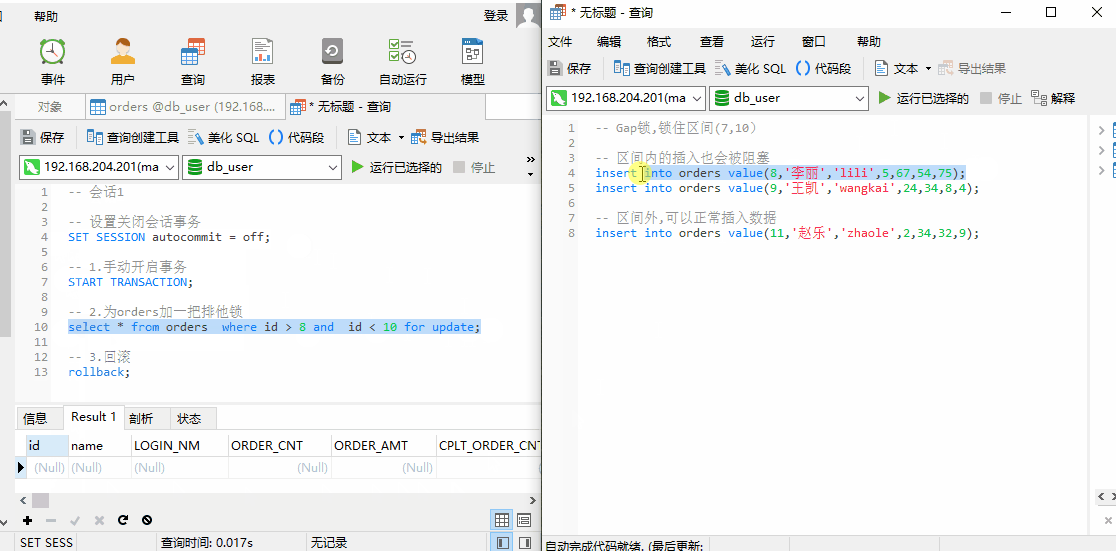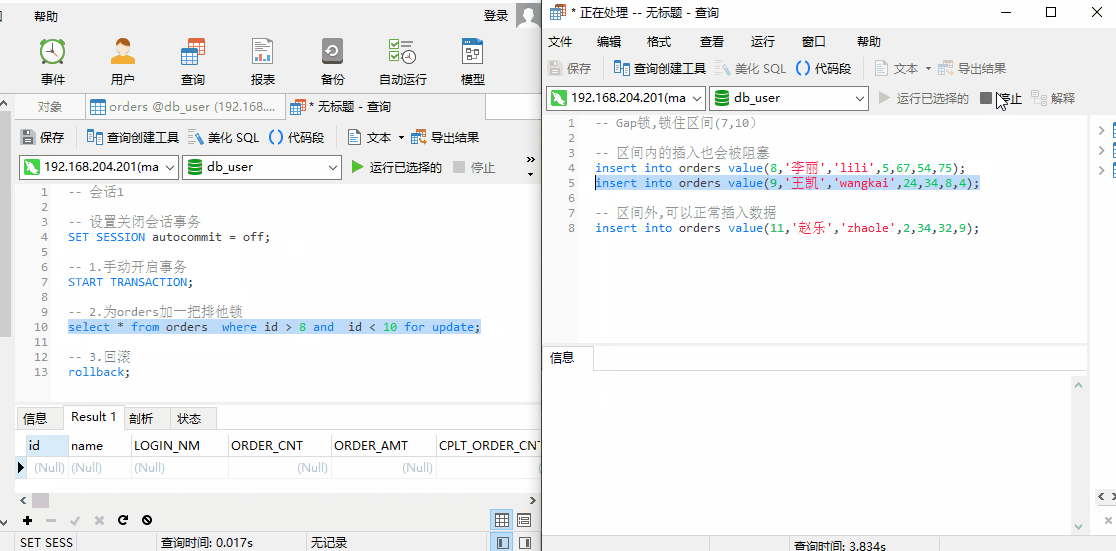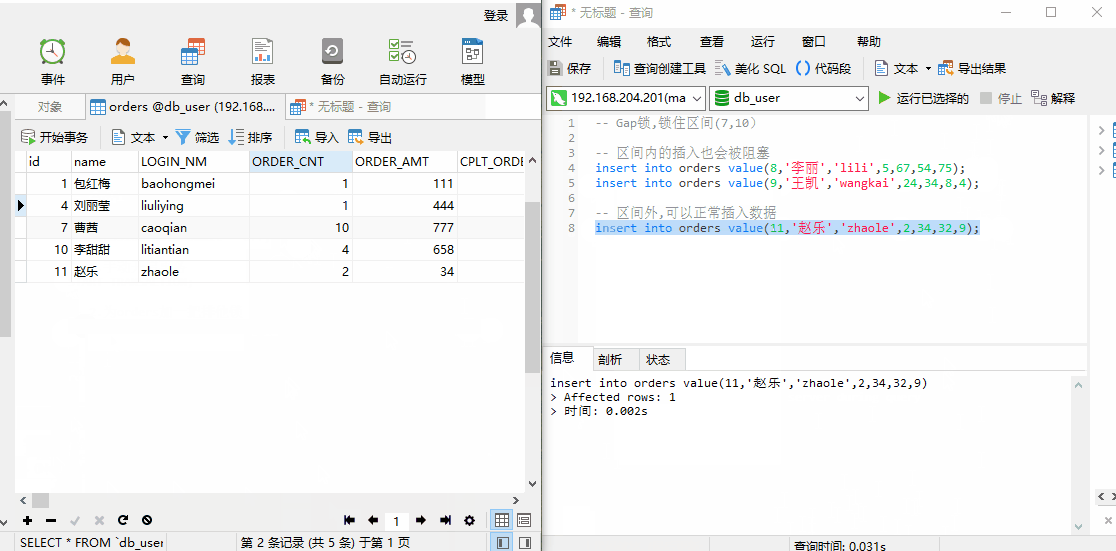
Gap 锁,只有在事务隔离级别为 RR(Repeatable Read) 下存在

因为只有在 RR 事务隔离级别下,InnoDB 引擎才能够解决数据幻读的问题。临键锁(Next-key Lock) = 间隙锁(Gap Lock) + 记录锁(Record Lock),所以 Gap 锁只有在 RR 级别下存在。可参考:四种隔离级别
3.5.3 记录锁(Record Lock)
记录锁(Record Lock)。当 SQL 执行按照唯一性(Primary key、Unique key)索引进行数据查询时,查询条件等值匹配且查询的数据存在,此时 SQL 语句加上的锁即为 Record Lock,锁住的是具体的索引项。
使用记录锁条件:
- 唯一性索引查询(主键索引、唯一性索引);
- 精确等值查询;
- 有数据命中时。
测试结果:
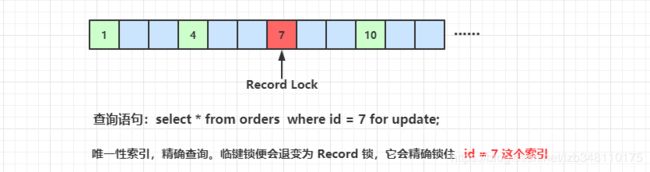
由于锁住 id = 7 这个索引,此时我们可以查询 id = 4 的数据,但是无法查询 id = 7 的数据。说明:锁住的区间为 id = 7 这个索引。
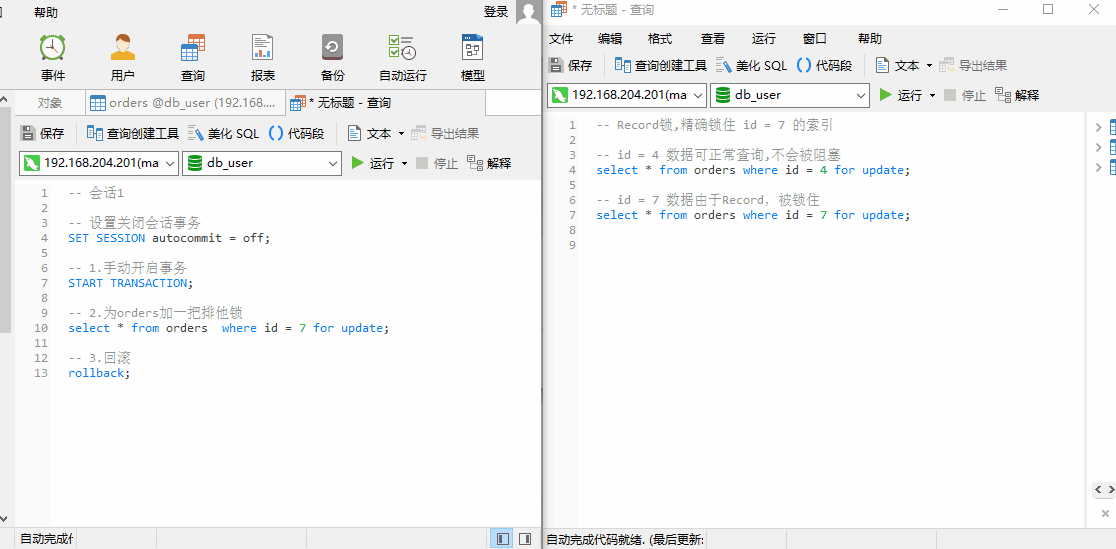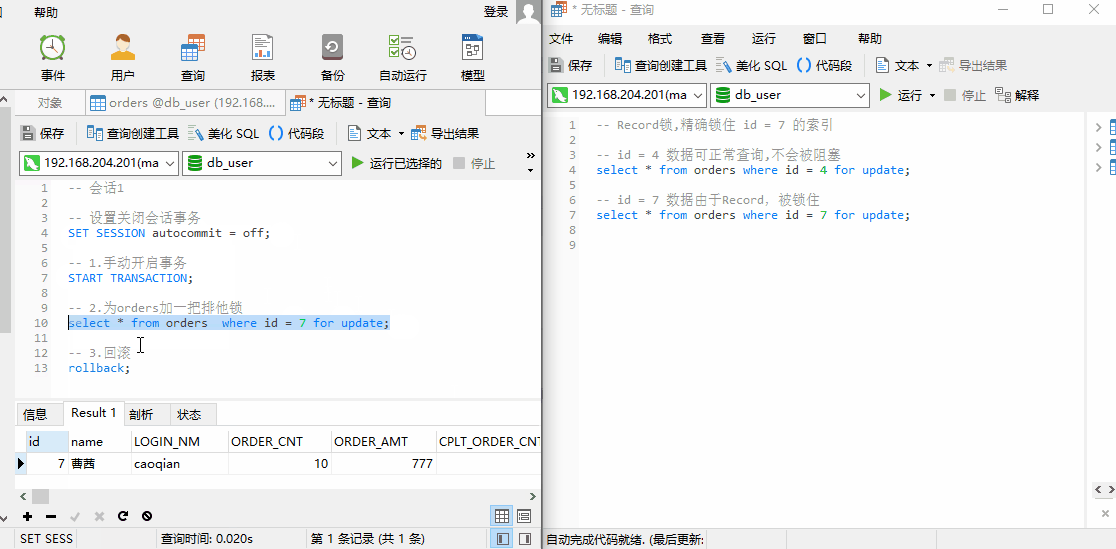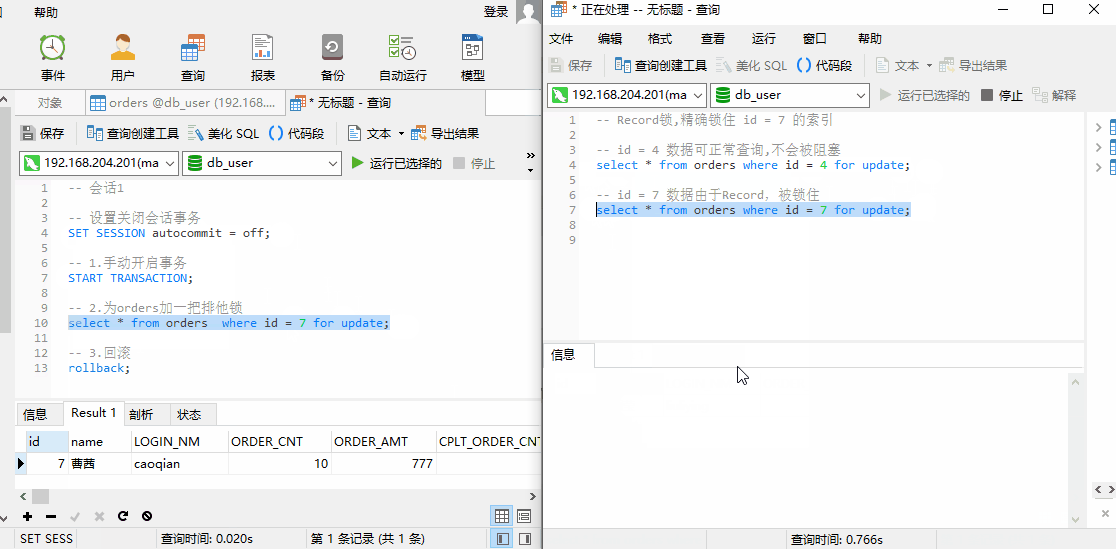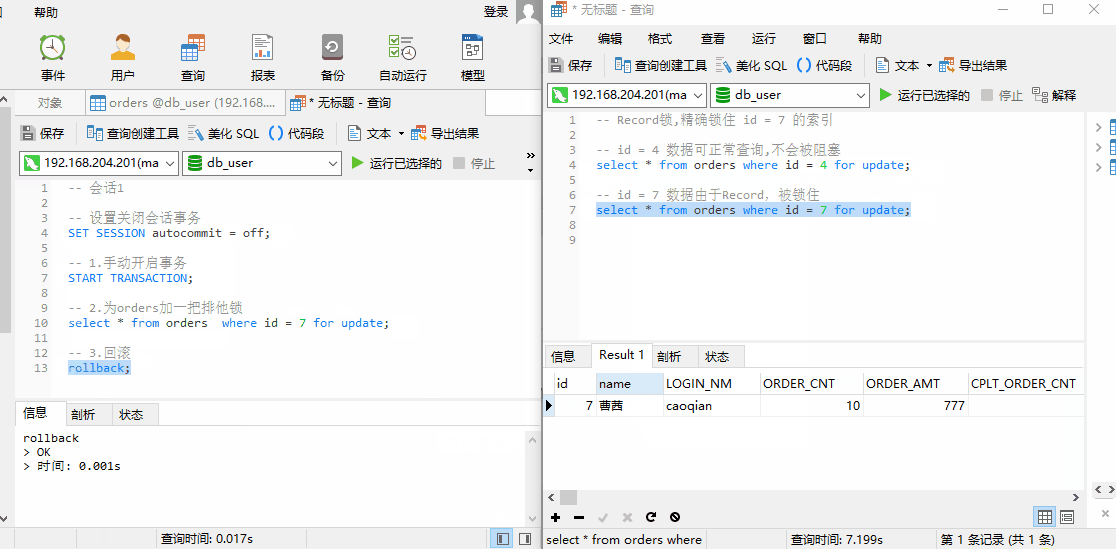
4.事务并发问题解决方案
4.1 +X锁,解决脏读问题

4.2 +S锁,解决不可重复读问题
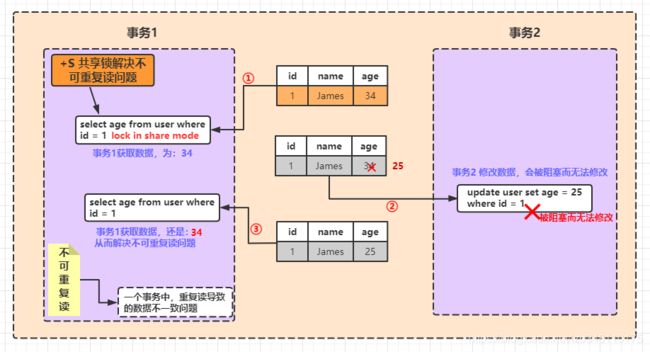
4.3 +Next key锁,解决幻读问题

5. 死锁问题
在了解了 InnoDB 引擎锁相关内容之后,死锁问题应该就很好理解了。死锁就是两个并发,或者多个并发,每个事务都持有锁(或者等待锁),每个事务都需要继续持有锁,事务之间就产生了彼此的循环等待,从而形成死锁。(可以理解为:三角恋无限死循环)
5.1 死锁复现
有两个表 orders、users(默认已创建 id、userID 索引);有两个事务A、B。如下为事务 A 和 事务B 执行步骤:
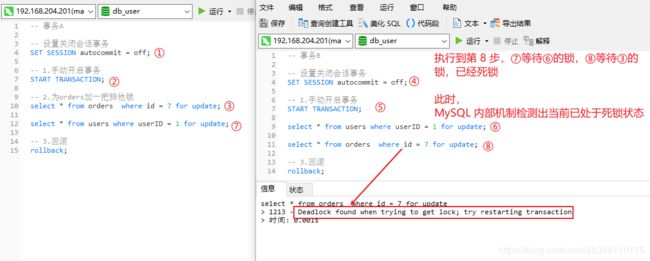
MySQL 内部其实也有一些检测机制的,它也会发现你的查询形成了一个闭环(有向无环图),便会提示。有些情况下,MySQL 如果没有检测出来,那就真正的死锁在那里了。死锁问题,最好还是在开发中应该注意一下。
5.2 如何避免死锁
- 类似的业务逻辑以固定的顺序访问表和行;
- 大事务拆小。大事务更倾向于死锁,如果业务允许,将大事务拆小;
- 在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁概率;
- 降低隔离级别,如果业务允许,将隔离级别调低也是较好的选择 (比较扯蛋,一般不用,但也能解决问题);
- 为表添加合理的索引。可以看到如果不走索引将会为表的每一行记录添加上锁(或者说是表锁)。
MySQL 同系列文章,请参考:
- 了解MySQL体系结构
- 一文带你看懂 MySQL 存储引擎
- 还不了解 MyISAM 和 InnoDB 的区别?看这里就够了
- MySQL为什么没有走索引?是这些原因在搞鬼
- 一条SQL语句的坎坷之旅(MySQL底层执行流程分析)
- 不会MySQL调优?来来瞅瞅SQL的执行计划吧
- InnoDB 事务与锁的前世今生
- 一文带你了解 InnoDB 中的 MVCC、Undo、Redo 机制
博主写作不易,加个关注呗
求关注、求点赞,加个关注不迷路 ヾ(◍°∇°◍)ノ゙
博主不能保证写的所有知识点都正确,但是能保证纯手敲,错误也请指出,望轻喷 Thanks♪(・ω・)ノ