RabbitMQ集群搭建

欢迎扫描文末二维码关注本人微信公众号,持续输出原创,永不停步!
推荐相关文章阅读:
入门RabbitMQ
RabbitMQ核心原理和知识点
实战RabbitMQ
安装和准备节点
1、准备3个节点(下面是笔者的主机列表):
主机名称 |
ip |
node1 |
10.68.212.101 |
node2 |
10.68.212.102 |
node3 |
10.68.212.103 |
官方强烈建议集群节点数量为奇数,例如:1、3、5、7。
2、每个节点安装好rabbitmq服务,关于安装可以查看本人前面发布的公众号文章。
入门RabbitMQ
3、修改每个对应节点的hostname:
# node1节点执行
hostnamectl set-hostname node1
# node2节点执行
hostnamectl set-hostname node2
# node3节点执行
hostnamectl set-hostname node3
reboot #重启
因为集群节点之间默认通过节点名称标识相互联系,所以集群节点名称必须唯一。节点名称默认为:rabbit@hostname,例如node1节点的默认节点名称为rabbit@node1,这里hostname很重要,一定是本机hostname,且要确保所有节点正确配置了/etc/hosts,因为节点之间是通过节点名称的hostname部分进行通信的,除了默认之外节点名称还可以通过配置环境变量RABBITMQ_NODENAME来修改,但是格式一定要符合xxx@hostname。
4、每个节点配置/etc/hosts,通过hostname获取主机节点名称后进行配置,笔者这里配置如下:
10.68.212.101 node1
10.68.212.102 node2
10.68.212.103 node3
#通过ping进行测试
ping node1
ping node2
ping node3
5、通过下面命令启动每个节点rabbitmq服务,确保能够正常启动:
rabbitmq-server -detached
6、通过下面命令查看每个节点的集群状态,默认单节点启动就是一个单节点的集群:
rabbitmqctl cluster_status
正常情况下可以看到如下输出:
Cluster name: rabbit@node1 #集群名称,默认是节点名称
Disk Nodes # 磁盘类型节点列表
rabbit@node1 # 节点名称
Running Nodes # 正在运行节点列表
rabbit@node1
............省略其它
至此,3个节点安装完毕,且能够正常启动,下面我们开始创建集群。
创建集群
1、因为集群节点之间需要互相通信,所以需要开通端口策略,简单粗暴方式是直接关闭防火墙,但是生产环境不推荐这么做,推荐做法是所有节点执行下面linux命令开通必要的端口:
firewall-cmd --zone=public --add-port=4369/tcp --permanent
firewall-cmd --zone=public --add-port=25672/tcp --permanent
firewall-cmd --zone=public --add-port=5672/tcp --permanent
firewall-cmd --zone=public --add-port=15672/tcp --permanent
firewall-cmd --zone=public --add-port=35672-35682/tcp --permanent
firewall-cmd --reload
2、配置cli命令工具和rabbitm服务身份验证的erlang cookie,对每个节点通过如下方式进行配置:
# 停止所有节点的rabbitmq服务和erlang jvm进程
rabbitmqctl stop
# 配置root用户使用CLI命令cookie为123456(123456可以改为其它复杂的值)
echo "123456" > /root/.erlang.cookie
# 创建rabbitmq服务端cookie目录和文件
mkdir -p /var/lib/rabbitmq
touch /var/lib/rabbitmq/.erlang.cookie
# 配置rabbitmq服务端cookie为123456
echo "123456" > /var/lib/rabbitmq/.erlang.cookie
3、通过下面命令启动所以节点:
rabbitmq-server -detached
4、将node2节点重置后加入node1节点集群,在node2节点上执行下面的命令:
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@node1

5、查看node1集群情况,回到node1节点,执行下面的命令:
rabbitmqctl cluster_status

6、回到node2执行下面命令,启动node2节点:
rabbitmqctl start_app
7、再次回到node1,查看集群状态:
rabbitmqctl cluster_status

8、继续将node3加入node1集群:
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@node1
rabbitmqctl start_app
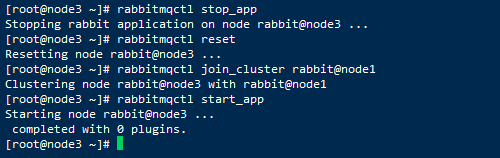
9、回到node1节点查看集群状态,当然也可以直接在node2和node3节点通过查看集群状态显示的结果也是和在node1节点查看显示结果是一样的:
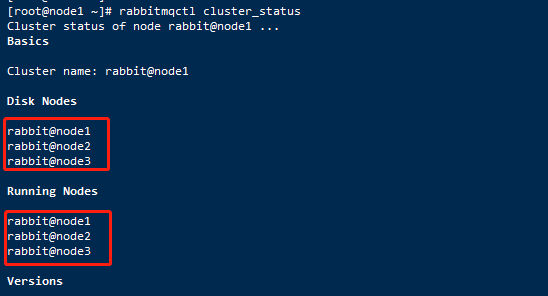
10、至此,由3个节点组成的集群创建完毕。现在我们还可以停止集群中的某个节点,例如停止node1,在node1节点上执行下面命令:
rabbitmqctl stop

然后在node2或node3节点上查看集群状态:
rabbitmqctl cluster_status

然后下面命令再次启动node1,此时node1将会从停止时标记的对等节点同步集群数据信息,如果对等节点不可用,则node1将启动失败,后面会提到如何解决无法启动的情况。
rabbitmq-server -detached
11、将某个节点重置后,该节点将忘记集群,等同退出集群,例如在node3节点上执行:
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
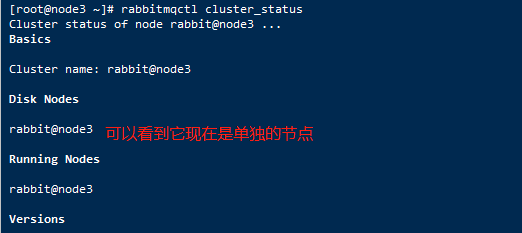
同时查看原理集群信息如下:

12、如果某个节点宕机无法访问,那么我们可以从其它可用的集群节点上剔除该不可用的宕机节点,例如我们模拟把node1节点停掉,然后在node2节点上剔除node1节点,命令如下:
# node1节点执行
rabbitmqctl stop
# node2节点执行
rabbitmqctl forget_cluster_node rabbit@node1
现在在node2节点查看集群状态信息如下:
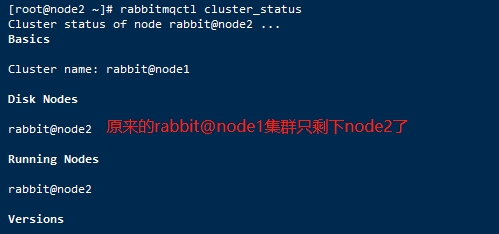
注意,现在node2仍然保留原来集群最终的状态,如果要完全解散集群,应该继续将node2进行重置,重置rabbitmq节点将删除其所有数据。
另外,如果此时再次启动node1,会收到以下报错信息:
Node rabbit@node1 thinks it's clustered with node rabbit@node2, but rabbit@node2 disagrees
原因是node1停止时将node2标记为下次启动时的对等节点,但是node2已经将node1从集群剔除出去,此时node1启动请求从node2同步数据时被拒绝,解决这个问题的办法是当node1在启动尝试10次请求连接node2的时间窗口内快速执行重置命令将node1进行重置,完整命令如下:
rabbitmq-server -detached
# 执行完上面命令后快速执行重置命令,注意一定要快
rabbitmqctl reset
如果前面希望时间窗口加长,可以通过修改rabbitmq配置文件下面两个配置项:
#等待60秒而不是30
mnesia_table_loading_retry_timeout = 60000
#重试15次而不是10
mnesia_table_loading_retry_limit = 15
默认配置文件位置,新安装的服务器不存在该文件需要手工创建:
$RABBITMQ_HOME/etc/rabbitmq/rabbitmq/rabbitmq-env.conf
13、我们可以通过下面命令修改节点的类型为磁盘或RAM:
# 修改为磁盘类型
rabbitmqctl stop_app
rabbitmqctl change_cluster_node_type disc
rabbitmqctl start_app
# 修改为内存类型
rabbitmqctl stop_app
rabbitmqctl change_cluster_node_type ram
rabbitmqctl start_app
# 或者直接在加入集群时指定节点以什么类型加入
rabbitmqctl join_cluster --ram rabbit@node1
集群核心原理
1、通过前面的方式创建集群后,集群所有节点的数据或状态信息互相同步复制,除了消息队列外,消息队列默认情况下只保存在一个节点上,客户端如果访问到其它节点上时,其它节点会路由到对应的队列主节点上。也就是说集群并没有实现队列的高可用,如果队列所在节点挂了,那么宕机节点上的所有队列将不可用,如果要实现队列高可用,后面会单独介绍一种叫队列镜像的方式来实现。
2、Admin管理插件会将集群所有节点信息汇总一并展示到前端页面。
3、集群节点数量强烈建议为奇数,例如:1、3、5、7。
4、集群中节点可以时磁盘类型,也可以是RAM内存类型,RAM类型目的是为了提升吞吐量,由于RAM类型节点所有数据在启动时从其它磁盘(只会选择磁盘类型节点)节点同步,所以一个集群必须至少有一个磁盘类型节点,通常建议是把全部节点都配置为磁盘节点。
5、集群节点在停止时会选择并标识一个可用的对等磁盘类型节点,作用是在下次启动时从这个标识的对等节点同步数据。如果启动时这个对等节点不可用(默认是尝试连接10次,每次超时30s),则该启动失败。但是如果停止时没有可用的对等节点,比如最后停止的节点,那么这个节点在下次启动时将不会连接对等节点来同步数据,而是直接启动,其它节点能够再次加入它。
6、当某个节点被重置后,或修改hostname后,再次重启将无法识别原理的集群,而是以单节点方式启动。
镜像队列
概念原理部分:
前面搭建的集群除了队列数据外其它数据例如交换和绑定都是在所有节点进行复制,通过镜像队列可以弥补队列高可用的问题,镜像队列思想是将队列配置为一主多从,每个队列都有一个主节点,多个镜像节点,所有操作都是先在主节点上进行,然后复制到镜像节点,这样可以保证消息的FIFO顺序。镜像队列不会同步被主节点队列确认的消息。实际上镜像队列只实现高可用,而没有实现负载均衡的效果。如果主服务器发生故障,则将最早的镜像提升为主节点。rabbitmq通过策略policy的方式来配置镜像队列,policy按名称正则表达式方式进行队列的匹配,下面是一个例子:
rabbitmqctl set_policy ha-hello "^hello\." \
'{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
set_policy:表示创建policy
ha-hello:表示policy名称
^hello\.:表示该policy匹配名称以hello开头的队列
ha-mode:指定镜像队列复制因子模式,后面通过表格来说明
ha-params: 配套ha-mode可选参数
ha-sync-mode:同步模式。
ha-mode |
ha-params |
描述 |
exactly |
数量 |
指定镜像队列副本数量,具体数量由ha-params指定 |
all |
空 |
队列镜像到集群所有节点,可以配合仲裁节点一起使用。 |
nodes |
节点名称 |
队列镜像到指定的集群节点名称。 |
任何时候都可以修改policy,当policy发生变化时,它将努力将其现有镜像保留到与新策略相适应的程度。rabbitmq镜像队列复制数量最佳多少比较合适,官方给出是经验是3个节点2个,5个节点3个。除了可以配置镜像节点数量策略外,还可以配置主节点位置策略,队列主节点位置策略是通过创建队列时指定x-queue-master-locator策略属性来配置,可配置下面3种策略:
策略属性值 |
描述 |
min-masters |
选择托管最少主节点数量的节点作为当前队列的主节点 |
client-local |
选择客户端连接到的节点作为当前队列的主节点 |
random |
随机选择一个节点作为当前队列的主节点 |
实战部分:
1、查看前面搭建的集群状态:

2、通过下面java客户端代码创建3个测试队列:
pom.xml坐标:
com.rabbitmq
amqp-client
4.11.3
Main方法测试代码如下:
public class Main {
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
//这里先访问其中一个节点,后续通过软负载均衡器nginx进行rabbitmq集群服务的负载均衡
factory.setHost("10.68.212.101");
//rabbitmqctl add_user lazy 111111
//rabbitmqctl set_user_tags lazy administrator
//rabbitmqctl set_permissions -p / lazy ".*" ".*" ".*"
factory.setUsername("lazy");
factory.setPassword("111111");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("hello1-queue", true, false,false, null);
channel.queueDeclare("hello2-queue", true, false, false, null);
channel.queueDeclare("hello3-queue", true, false, false, null);
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
}
}
3、登录集群任何一个节点可以查看队列列表:

4、两种方式可以查看队列镜像信息:
# 通过CLI命令行(第一种)
rabbitmqctl list_queues name policy pid slave_pids
# 者在所有节点执行下面命令开启admin管理插件(第二种)
rabbitmq-plugins enable rabbitmq_management
然后在任何一个节点访问,后续会搭建nginx进行软负载:
http://10.68.212.101:15672/
登录账号和密码为:lazy / 111111
第一种方式截图:
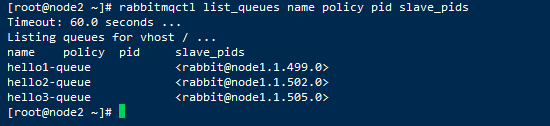
第二种方式截图:

5、分别创建3个policy:
# 将hello1-开头的所有队列镜像模式设置为exactly
rabbitmqctl set_policy --vhost / --apply-to queues ha-exactly-demo "^hello1-*" \
'{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
# 将hello2-开头的所有队列镜像模式设置为all
rabbitmqctl set_policy --vhost / --apply-to queues ha-all-demo "^hello2-*" \
'{"ha-mode":"all"}'
# 将hello3-开头的所有队列镜像模式设置为nodes,节点为node2,node3
rabbitmqctl set_policy --vhost / --apply-to queues ha-nodes-demo "^hello3-*" \
'{"ha-mode":"nodes","ha-params":["rabbit@node2", "rabbit@node3"]}'
6、查看policy生效情况:
# 通过CLI命令行(第一种)查看:

# 通过管理页面(第二种)查看:

深度解答镜像问题:
1、如果修改某个队列的策略导致新的策略的节点不包含任何原理策略的节点,例如原来策略是node1,node2,新的策略节点配置为node3,node4,这种情况下数据如何迁移?
答:这种情况会新的策略会包含node3,node4节点以及原来策略的主节点例如node1,然后node3,node4会从原来策略的主节点node1同步消息数据,直到同步完成才将node1剔除。
2、当rabbitmq连接关闭时排他队列将被删除,请问排他队列可以做镜像吗?
答:排他队列永远不会被镜像。
3、如果rabbitmq镜像队列主节点发生故障,如何提升镜像节点?
答:会将运行时间最长的镜像节点提升为主节点。但是默认情况下
4、如果rabbitmq镜像队列主节点发生故障,会丢失哪些情况的数据吗?
答:镜像节点默认只会同步镜像节点第一次或重新加入(置空历史消息数据)做为主节点那一刻时间之后的主节点新的消息,不会同步加入主节点之前的消息。
从消费端来分析:如果过程中主节点发生故障,然后提升该镜像节点为主节点,那么可能会丢失镜像节点加入之前的历史消息数据(如果消费速度很慢没有被消费完的话,但是可以通过配置为不自动提升非全量同步的镜像节点为主节点,然后通过手动同步全量数量后来弥补这个问题,注意同步过程会使所有其它队列阻塞)。然后重新排队当前镜像节点尚未收到消费者确认的那部分消息发送给消费者,所以消费者必须做好幂等性处理(因为可能会重复),所以消费端可能会丢失数据,也可能会重复收到消息。
从发送端来分析:如果发送者配置为自动确认模式,如果恰好当发送消息到主节点的同时主节点挂断,那么消息可能会丢失。但是发送者如果配置为手工确认模式,那么主节点会保证所有镜像节点都接受到该消息,才会向发布者确认并定期被落盘,所以,如果主节点挂断,那么发送者可以正确知道消息确认情况,所以发送者只要配置确认机制,基本消息不会丢失。否则,会发生丢失的可能。
5、镜像节点如何手工同步主队列节点的全量消息数据?
答:可以通过下面命令手工不同历史消息数据:
rabbitmqctl sync_queue your_queue_name
6、如何配置为不自动提升非全量同步的镜像节点?
答:从rabbitmq3.7.5版本开始,可以通过配置队列声明属性:ha-promote-on-failure值为:when-synced来确保不自动提升非全量同步的镜像来防止历史数据的丢失,默认值为:always表示总是自动提升非全量同步镜像节点。当值配置为:when-synced时,发送者必须使用手动确认模式才能完全确保消息整体不丢失,否则when-synced配置就是毫无意义的。
7、如何查看队列节点同步情况?
答:可以通过下面命令查看:
rabbitmqctl list_queues name slave_pids synchronised_slave_pids
8、如何配置镜像节点为总是默认全量同步主队列所有历史数据?
答:可以通过配置队列声明属性:ha-sync-mode值为:manual表示历史全量数据需要手动同步,值为:automatic表示自动同步历史全量数据。
9、手动关闭rabbitmq节点,会提升镜像队列吗?
答:默认情况下,rabbitmq显示停止或操作系统关闭时,不会提升镜像队列为主队列的,此时整个队列为关闭状态。但是如果由于节点崩溃例如内存溢出,磁盘爆满或者网络中断、剔除集群等原因时,才会提升镜像队列为主队列。
通过Nginx实现集群节点负载均衡:
1、安装nginx,这里挑选node1节点来安装nginx:
cd /opt/tarball
wget http://nginx.org/download/nginx-1.16.1.tar.gz
tar -xvf nginx-1.16.1.tar.gz -C /opt/src/
cd /opt/src/nginx-1.16.1/
./configure --with-stream
make
make install
2、配置nginx环境变量:
vi /etc/profile
source /etc/profile

3、启动nginx:
nginx
4、配置nginx负载均衡和代理转发:
vi /usr/local/nginx/conf/nginx.conf
关键配置内容如下:
stream {
upstream rabbitmq_server {
server node1:5672;
server node2:5672;
server node3:5672;
}
server {
listen 18080;
proxy_connect_timeout 5s;
proxy_timeout 5s;
proxy_pass rabbitmq_server;
}
}
http {
upstream rabbitmq_admin {
server node1:15672;
server node2:15672;
server node3:15672;
}
server {
listen 18081;
server_name rabbitmq_admin;
location / {
proxy_pass http://rabbitmq_admin;
}
}
}
5、修改node1防火墙端口策略:
firewall-cmd --zone=public --add-port=18080/tcp --permanent
firewall-cmd --zone=public --add-port=18081/tcp --permanent
firewall-cmd --reload
6、浏览器访问nginx负载均衡admin地址:
http://10.68.212.101:18081/

7、java客户端代码修改为如下连接地址:
public class Main {
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
//访问nginx地址
factory.setHost("10.68.212.101");
factory.setPort(18080);
//rabbitmqctl add_user lazy 111111
//rabbitmqctl set_user_tags lazy administrator
//rabbitmqctl set_permissions -p / lazy ".*" ".*" ".*"
factory.setUsername("lazy");
factory.setPassword("111111");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("hello1-queue", true, false,false, null);
channel.queueDeclare("hello2-queue", true, false, false, null);
channel.queueDeclare("hello3-queue", true, false, false, null);
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
}
}
至此,rabbitmq集群搭建讲解完毕。
---------------------- 正文结束 ------------------------
长按扫码关注微信公众号

Java软件编程之家