机器学习笔记(一) 逻辑斯蒂回归LR
本文是在学习完李航老师的《统计学习方法》后,在网上又学习了几篇关于LR的博客,算是对LR各个基础方面的一个回顾和总结。
一 简述
逻辑斯蒂回归是一种对数线性模型。经典的逻辑斯蒂回归模型(LR)可以用来解决二分类问题,但是它输出的并不是确切类别,而是一个概率。
在分析LR原理之前,先分析一下线性回归。线性回归能将输入数据通过对各个维度的特征分配不同的权重来进行表征,使得所有特征协同作出最后的决策。但是,这种表征方式是对模型的一个拟合结果,不能直接用于分类。
在LR中,将线性回归的结果通过sigmod函数映射到0到1之间,映射的结果刚好可以看做是数据样本点属于某一类的概率,如果结果越接近0或者1,说明分类结果的可信度越高。这样做不仅应用了线性回归的优势来完成分类任务,而且分类的结果是0~1之间的概率,可以据此对数据分类的结果进行打分。对于线性不可分的数据,可以对非线性函数进行线性加权,得到一个不是超平面的分割面。
二 原理
2.1 sigmoid函数
sigmoid函数形式为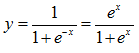 ,分布如下图所示:
,分布如下图所示:

2.2 LR回归模型
二项逻辑斯蒂回归模型由条件概率分布P(Y|X)表示,随机变量X取值为实数,随机变量Y取值为1或0。模型的条件概率分布
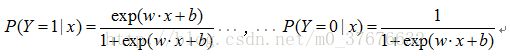
在进行分类时,通过比较上面两式的大小来将输入实例分配到概率值大的那一类。
也就是说,LR将输入实例x的线性回归的加权结果w·x+b通过sigmoid函数映射到0~1之间,加权结果的值越接近正无穷,概率值就越接近1,反之则越接近0。
2.3 多项LR回归模型
LR模型也可以推广到解决多分类问题,模型如下:

2.4 模型参数估计
LR的参数估计使用最大似然估计。LR损失函数为对数损失函数,所以这里最大似然估计可以理解为损失函数为对数损失函数的经验风险最小化。
若假设![]() ,
,
那么似然函数为 ![]()
求解最大似然函数,对上式取对数后求解最大。
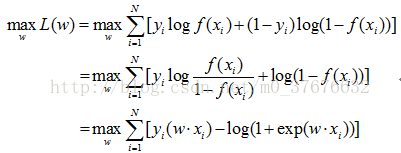
在解这个最优化问题的时候,若是直接求取解析解会使计算非常复杂,通常采用近似方法如梯度上升法和拟牛顿法。其中梯度上升法可能导致计算量太大,于是用随机梯度上升法代替;牛顿法或拟牛顿法一般收敛速度更快。
2.5 损失函数
LR损失函数为对数损失函数。对数损失函数的定义是
![]()
在参数模型估计中的对数似然函数极大化即对应着损失函数极小化。
在Andrew Ng的课程中将损失函数定义为![]() (这里符号取w以保证本文的符号统一)。
(这里符号取w以保证本文的符号统一)。
与2.4部分统一后,LR损失函数可以表示为

使用梯度下降法使损失函数极小化,每一步的迭代公式为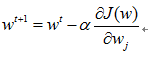
在推导![]() 前,由上文
前,由上文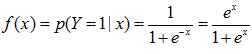 ,
,
需要知道对于siamoid函数有如下求导性质
![]()
那么在权值w的更新过程中,![]() 推导如下:
推导如下:
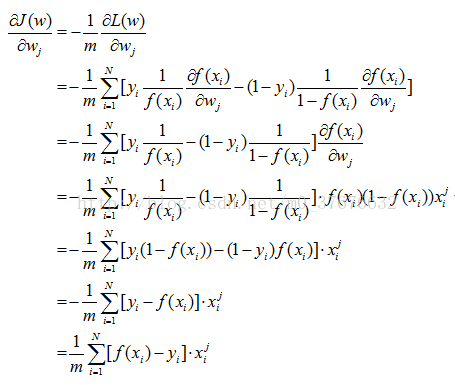
基于此,迭代公式为 
三 LR的应用和优缺点
LR是解决工业规模问题最流行的算法。在工业应用上,如果需要分类的数据拥有很多有意义的特征,每个特征都对最后的分类结果有或多或少的影响,那么最简单最有效的办法就是将这些特征线性加权,一起参与到决策过程中。比如预测广告的点击率,从原始数据集中筛选出符合某种要求的有用的子数据集等等。
优点:1)适合需要得到一个分类概率的场景。2)计算代价不高,容易理解实现。LR在时间和内存需求上相当高效。它可以应用于分布式数据,并且还有在线算法实现,用较少的资源处理大型数据。3)LR对于数据中小噪声的鲁棒性很好,并且不会受到轻微的多重共线性的特别影响。(严重的多重共线性则可以使用逻辑回归结合L2正则化来解决,但是若要得到一个简约模型,L2正则化并不是最好的选择,因为它建立的模型涵盖了全部的特征。)
缺点:1)容易欠拟合,分类精度不高。2)数据特征有缺失或者特征空间很大时表现效果并不好。
四 与其他算法比较
与SVM比较
线性回归做分类因为考虑了所有样本点到分类决策面的距离,所以在两类数据分布不均匀的时候将导致误差非常大;LR和SVM克服了这个缺点,其中LR将所有数据采用sigmod函数进行了非线性映射,使得远离分类决策面的数据作用减弱;SVM直接去掉了远离分类决策面的数据,只考虑支持向量的影响。
但是对于这两种算法来说,在线性分类情况下,如果异常点较多无法剔除的话,LR中每个样本都是有贡献的,最大似然后会自动压制异常的贡献;SVM+软间隔对异常比较敏感,因为其训练只需要支持向量,有效样本本来就不高,一旦被干扰,预测结果难以预料。
参考:
李航《统计学习方法》
http://www.cnblogs.com/zhizhan/p/5007540.html
http://www.jianshu.com/p/95e5faa3f709
http://www.tuicool.com/articles/uiMjyuu