Feature Pyramid Networks for Object Detection
《Feature Pyramid Networks for Object Detection》发表在2017年CVPR上。
本文提出一种Feature Pyramid Networks(FPN)网络结构,能够在不影响速度的前提下融合多层特征,使每个level的特征都具有丰富的语义信息,提高CNN网络特征提取能力。理论上,FPN在CNN方法中是一个通用的方法。
1. 网络结构
在卷积神经网络中,前几层的特征图分辨率高,但是含有的语义信息少。高层的特征图则恰恰相反。
在目标检测任务中,由于目标大小的不一致,图像(特征)金字塔是一个很有效的手段。
A. Featurized image pyramid

通过调整输入图像的大小构建图像金字塔,从而构建特征金字塔。
将原图按比例进行缩放,输入到CNN网络中,从而提取的特征大小也不同。
该法虽然达到了检测不同大小目标的目的,但是需要多次地调整输入图像的大小,所以速度十分慢。
B. Single feature map

为了更快地进行检测,有一些方法只采用了单层的特征图进行检测。
但该法显然对小目标的检测十分不利。
C. Pyramidal feature hierarchy
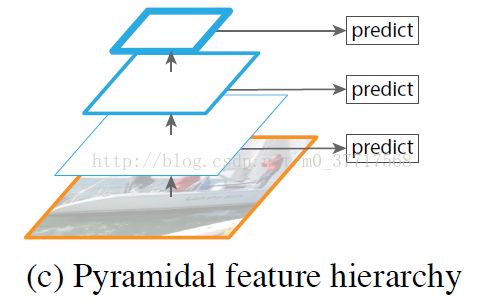
在B的基础上,除了只利用语义信息最丰富的最后一层特征图,也可以使用其他层的特征图分别进行检测。
但不同深度引起了语义鸿沟问题,前几层的特征图分辨率高,但是语义信息少,对目标的表示不利。
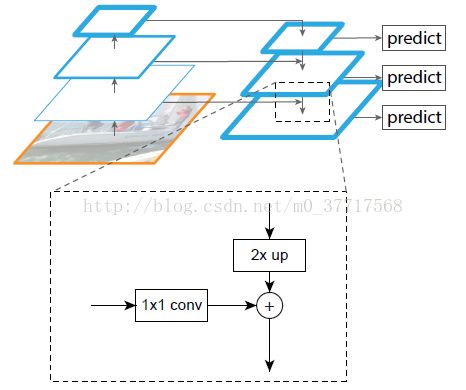
D. Feature Pyramid Network(FPN)

为了取得较好地检测效果,这篇论文希望能够在利用到更多层特征图的同时,使每一层特征金字塔都能具有丰富的语义信息。
所以提出FPN结构,使用自上而下的路径,横向连接低分辨率、语义信息丰富的高层特征和高分辨率、语义信息较少的低层特征
2. Feature Pyramid Network(FPN)
自下而上的路径
在网络结构中,有一些卷积层输出的特征图大小是一样的。本文中将这些层称为一个stage。
对于每一个stage,只定义其中最后一层卷积层作为特征金字塔的一层。
原因很简单,stage中的最后一层含有的语义信息肯定是最多的。
特征金字塔的每层间缩放步长为2。
例如,对残差网络ResNets,忽略conv1,定义残差块conv2~conv5的最后一层为{C2,C3,C4,C5}。与输入图像相比,它们的步长分别为{4,8,16,32}。
自上而下的路径以及横向连接
从最高层开始,特征图经过2倍的上采样,与前一层空间大小相同的特征图进行横向连接,即特征图上对应位置元素相加。如此迭代直到产生最精细的特征图。
简单起见,上采样使用最近邻上采样。
金字塔不同层采用共享的分类器和回归器,通道数需保持一致。因此每次迭代前一层的特征图需要经过1*1卷积。文中规定通道数d=256,因为不存在非线性,所以影响很小。
开始迭代时,在C5后添加一个1*1卷积层,产生最小分辨率的特征图。
同时,为每一个融合的特征图添加一个3*3的卷积层,以减低上采样的混叠效应。
最后,对应于原来的{C2,C3,C4,C5},产生的特征金字塔为{P2,P3,P4,P5}。其大小分别保持不变(保留位置信息)。
3.应用
A. FPN for RPN
RPN在特征图上产生9种anchor进行目标的检测。
FPN产生的每层特征图后面,紧跟一个3*3的卷积层和两个1*1的卷积层(简称为一个head)。
因为金字塔具有尺度信息了,所有在某个特定的金字塔层上不需要多种anchor。
这里,作者为金字塔的每层设置了单一尺度的anchor。
对P5进行步长为2的上采样,记为P6。在{P2,P3,P4,P5,P6}融合的特征图上,分别设置大小为{32^2,64^2,128^2,256^2,512^2}的anchor。同时为了满足形状需求,设置三种纵横比{1:2,1:1,2:1}。所以金字塔的每一层具有15种anchor。
训练时,positive和negative的设定与RPN相同:和任意groundTruth的IoU大于0.7视为positive;和所有groundTruth的IoU小于0.3视为negative。
B. FPN for Fast R-CNN
Fast R-CNN中有将RoI映射到特征图上的过程。
在FPN中,这个过程演变成需要确定将RoI映射到金字塔的不同层的融合特征图上。
作者的想法是:如果RoI的大小比较小,就映射到相对靠前的特征图上,反之映射到相对靠后的特征图上。
作者提到,先认为FPN的特征图是由图像金字塔生成的。然后使用图像金字塔的方法。
假设RoI在输入图像上宽和高分别为w、h,
映射到Pk层的参数k由以下公式决定:

其中224是ImageNet预训练的标准输入图像大小。Faster R-CNN提取C4的特征图,因此设置k0=4。预防产生小数进行取整操作。
将Fast R-CNN中的分类器和回归器简称为一个head。所有head参数共享。
因为conv5作为了金字塔的一层,所以RoI pooling提取7*7的特征之后,添加两个1024-d的全连接层,再跟着head。