Videos as Space-Time Region Graphs文章解读
Videos as Space-Time Region Graphs(Wang的工作)[1]主要的创新是为视频构建了一个graph structure,并利用图卷积网络来处理视频问题。采用的图卷积层公式都是基于Z=AXW,该公式是由kipf在Semi-Supervised Classification with Graph Convolutional Networks[2上提出的,也是首次提出GCN的概念。
笔者本科毕业设计的主要思路也是如此,只是网络结构较简单,构建的graph structure也较简单,本文首先对笔者的工作进行介绍,而后,对Wang的工作进行介绍。
一、笔者的工作
笔者的工作,网络结构是以few-shot learning with graph neural networks(Garcia 的工作)[3]为基础。但区别在于Garcia 的工作是解决Node(节点)的分类问题,而笔者的工作解决的是graph(图)的分类问题。有兴趣的读者可以对这篇文章进行深入解读。
笔者的网络结构如下:
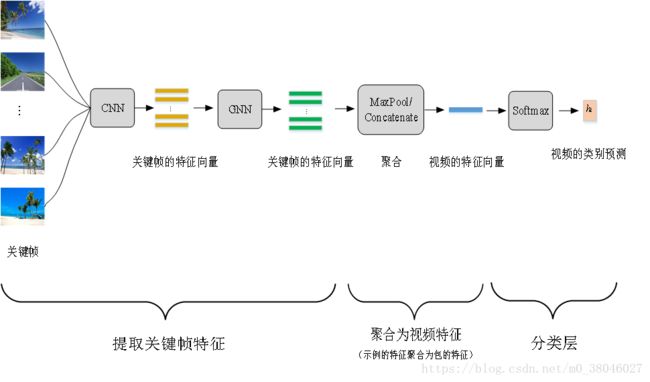
图1
笔者采用的是两个行为识别的数据集,UCF101数据集和HMDB51数据集,这两个数据集的时长都较短,2-10s的居多,实验过程中,以5fps进行取关键帧。只取其连续的N帧(16帧)组成的clip来代表视频。
1、每个关键帧输入2D CNN中,提取关键帧的appearence feature(外观特征),如图1中的黄色横条,一个横条代表一个关键帧的特征向量(维度为F)。
2、将N个关键帧特征向量送入GNN网络中,使得经过GNN更新后的关键帧特征能够带有关键帧之间结构化的相关关系,GNN网络如图2

图2
GNN网络由3个子块组成,子块完成的功能如下:
(1)构建邻接矩阵A:计算任意两个Node(node_i ,node_j)之间差值的绝对值,并输入一个多层感知机中,得到一个标量,该标量值即为这两个Node之间的边的权重大小,在邻接矩阵的(i,j)位置上填充权重值。共有N个Node,因此构建的邻接矩阵为N*N,为对称矩阵。构建了一个undirected graph(无向图)。
(2)将邻接矩阵A与N 个Node的特征向量组成的矩阵X(N,F)输入图卷积层,图卷积层的计算公式Z=AXW,得到更新的Node特征向量矩阵Z,即对关键帧的特征向量进行了更新。
经过3个子块之后,得到更新的Node特征向量(维度为C,数据集的类别数),融合了关键帧之间的依赖关系。
3、上一步骤得到了关键帧的特征,但是目标是为了得到视频的特征,因此要将关键帧的特征聚合为视频的特征,这里采用了两种方法,
一种是对N个关键帧得特征向量组成的矩阵(N,C)进行最大池化,得到1*C的视频的特征向量。
另外一种是先将(N,C)的矩阵转成(1,N*C),再经过两层全连接层得到(1,C)的视频的特征向量。
4、将特征向量送入softmax分类层,得到视频的类别预测。
二、Wang的工作
与笔者工作不同的是Wang通过RPN(region propoasl network)对视频的关键帧提取object proposal。将这些object proposals作为node 建立graph structure关系。
Wang的工作用到的是Charades数据集和Something-Something数据集,Charades数据集的视频平均时长为30s ,Something-Something数据集视频的时长为3s-6s。帧采样率为6fps,实验中以32帧组成一个clip代表视频。
主要结构如图3
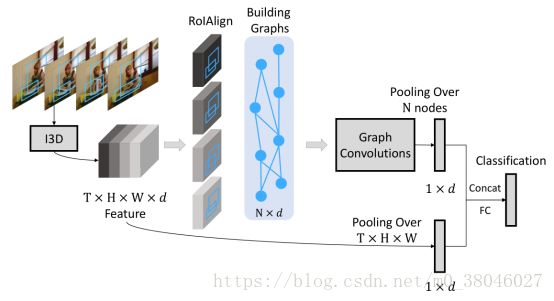
图3
1、首先利用I3D提取视频的特征,最后一个卷积层的输出的视频特征是T×H×W×d
2、采用RPN提取object proposal (类别不可知)。为了能在I3D的最后卷积层上提取object features。首先将16个输入RGB帧(对32个输入帧进行采样,每两个帧取一个帧)上的object proposal 映射到16个输出特征帧上。而后,将视频特征和映射之后的object proposal 应用RoIAlign,来提取object proposal 的特征。
3、构建graph structure,主要是构建边的关系,Wang提出了两种graph structure,Similarity Graph 与Spatial-Temporal Graph.
(1)Similarity Graph 是为任意两个object之间构建相似度。object_i与object_j之间的相似度计算公式为![]()
![]()
这个图,不仅学习不同帧相同object之间的关系,也学习不同object之间的关系。邻接矩阵Gsim的第(I,j)个元素为:![]()
,这里的N是从clip中提取的所有object数量,因此构成了一个N个Node的Graph.
虽然Similarity Graph可以为任意两个Object建立长期的依赖关系,但是却没有为两个object建立相对空间关系,也没有建立状态改变的顺序关系。
(2)因此Spatial-Temporal Graph是为时间或者空间上相互接近的2个obejct建立关系。
Spatial-Temporal Graph由两个图构成,forward graph 和 backward graph(前向图和后向图)。
forward graph:计算第t帧的object proposal与第t+1帧的所有object proposal之间的Intersection over Unions(IoUs)值,定义第t帧第i个object proposal与第t+1帧第j个object proposal 之间的IoU值用符号表示为ɑij,若其值大于1,则建立一个directed edge i->j ,值为ɑij。邻接矩阵的第(i,j)个元素为:![]()
backward graph:若第t帧第i个object proposal与第t+1帧第j个object proposal 之间存在重叠。则构建一个i<-j的边。边的值用IoU计算。Gback的邻接矩阵值也是根据IoU的值。
对于此部分的具体实现笔者还未清楚
4、计算图卷积![]() 将三个graph结合来更新节点的特征,但是经过试验,相对于单个Similarity Graph,性能更差,因为Similarity Graph包含可学习参数,可以进行反向传播,而另外两个graph不需要学习,这样的结合使得优化过程困难。因此,后期使用两个分支,一个GCN采用Similarity Graph ,另一个GCN采用Spatial-Temporal Graph。最后再将GCN的输出进行融合。
将三个graph结合来更新节点的特征,但是经过试验,相对于单个Similarity Graph,性能更差,因为Similarity Graph包含可学习参数,可以进行反向传播,而另外两个graph不需要学习,这样的结合使得优化过程困难。因此,后期使用两个分支,一个GCN采用Similarity Graph ,另一个GCN采用Spatial-Temporal Graph。最后再将GCN的输出进行融合。
5、得到GCN的输出,更新了object proposal 的特征向量,N个object proposal 的特征向量组成的矩阵为(N,d),经过平均池化得到(1,d)的特征向量。
其次,I3D最后卷积层得到的特征(T,H,W,d),经过平均池化后得到(1,d)的特征向量。
将两个(1,d)的特征向量进行concatenated得到(1,2d)的特征向量,再经过全连接层得到视频的分类结果。
Note:这里与笔者的工作相似,得到的是Object的特征,但是目标是要得到视频的特征,因此这里进行的就是特征聚合操作,由Object的特征聚合为视频的特征。
三、分析与比较
笔者的工作将关键帧视为节点,Wang的工作将关键帧中的object 视作节点
笔者构建的graph structure是建立关键帧之间的相关关系,只有一个graph,且是无向图。
Wang构建的graph structure是建立关键帧中的object之间的相关关系,有三个图,包括无向图和有向图。
参考文献:
[1] Wang X.L.,Gupta A. Videos as Space-Time Region Graphs[J].arXiv preprint arXiv:180601810, 2018.
[2] Kipf T.N., Welling M. Semi-Supervised Classification with Graph Convolutional Networks[C]. International Conference on Learning Representations, 2016.
[3] Garcia V., Bruna J. Few-Shot Learning with Graph Neural Networks[J]. arXiv preprint arXiv:1711.04043, 2017.