Apache Kylin 在中企的使用主要在新数仓系统以及 BI 报表的数据计算工作,带来的变化有:
一方面Kylin帮助我们提升了开发效率,减少了开发人员需要手动编写HQL/SQL 语句去查询维度数据的状况;
另一方面解耦现有系统设计,数据计算层主要包括Spark类的实时计算和HQL的离线计算(Kylin在我司目前还没有接入实时流计算,后期会尝试接入),通过引入Kylin,整个离线计算这一块就可以转到Kylin去处理,灵活度高了很多;
最后,Apache Kylin采用HBase做为结果集的存储,对外提供API,并且支持大部分BI展示工具,目前2.0+版本也提供了基于Spark的计算引擎和雪花模型,可见,在未来Kylin在中企动力的应用场景会越来越丰富。
在Apache Kylin高性能的背后,Cube是至关重要的核心。Cube是所有Dimension 的组合,每一种Dimension 的组合称之为Cuboid,有N个Dimension的Cube就会有2^n个Cuboid。因此,一个优化得当的Cube既能满足高速查询的需要,又可节省集群资源,本文将从Kylin Cube的设计方面带大家了解Cube的优化方案。
为何需要优化Cube?
前面说过,Cube是所有维度的组合,当我们有10个维度时,那么就会预计算2^10 也就是1024个Cuboid,但当我们真正查询的时候,可能只会用到100个Cuboid,如果不对Cube进行优化的话:
1、会使得Build出来的Cube Size 很大,从而占用大量的磁盘空间;
2、Cube Building的时间会很长 ;
3、会占用集群的计算资源 。
因此,如果使用Apache Kylin做数据分析,Cube优化将是我们必做的一项工作。
Cube 维度优化主要方式
· Cube ID 剪枝优化
· 衍生维度优化
· 聚合组优化
· 强制维度
· 层次维度
· 联合维度
· Cube并发粒度优化
以上7种优化方式,都可以认为是对维度的一种剪枝,因为每种优化的最终目的都是为了减少Cuboid的数量,下面我将逐个介绍每个优化项的概念以及使用场景。
Cube ID 剪枝优化
前面说到如果有10个维度,那么就会生成2^10=1024个Cuboid,如果有20个维度那么将会生成2^20=1048576个Cuboid,是指数级增长,kylin.properties中参数 kylin.cube.aggrgroup.max-combination=4096,也就是说当Cuboid数量大于4096时, Cube定义是无法保存的的,会报TooManyCuboidException异常。
1.检查Cuboid数目
执行命令 :
bin/kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader cubeName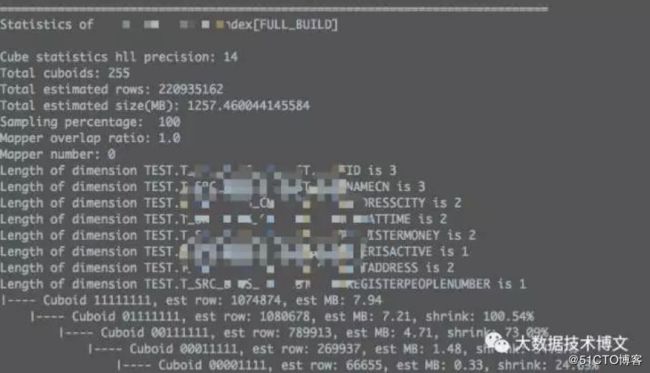
2.检查Cube Size
在kylin web gui 的model界面选择一个READY状态的Cube,将光标移到Cube Size上面,会显示出Cube源数据的大小,以及当前Cube的大小除以源数据大小的比例,如图:

一般,Cube的膨胀率应该在0%-1000%之间,如果Cube的膨胀率超过了1000%,那么就需要查询其中的原因了,导致膨胀率高的原因一般为以下几点:
1)、Cube的维度数量较多,没有进行很好的剪枝;
2)、Cube中存在较高基数的维度,导致这类维度每个Cuboid占用的空间很大,从而造成Cube体积变大;
3)、存在比较占用空间的度量。
对于Cube膨胀率高的情况,需要针对实际的业务需求进行分析,可以考虑通过下面的几种优化方式进行优化:
[Derived Dim]衍生维度优化
衍生维度(Derived Dim):当一个或者多个维度能够从主键中推断出来,那么这些维度列就称之为衍生“Derived” 列。
衍生维度(Derived Dim)优化效果:维度表中的n个维度计算,将Cuboid从2^n 减为2。
使用场景:在星型模型中,有一个用户维度表,表中包含了ID,A,B,C ,其中ID 为PK,在这里通过ID的值就可以确定A,B,C的值,因为A,B,C为ID的Derived。当进行build一个Cube包含A,B,C 的时候,只需要包含ID,并且将A,B,C标记为derived ,这样derived列就不会生成Cuboid 。

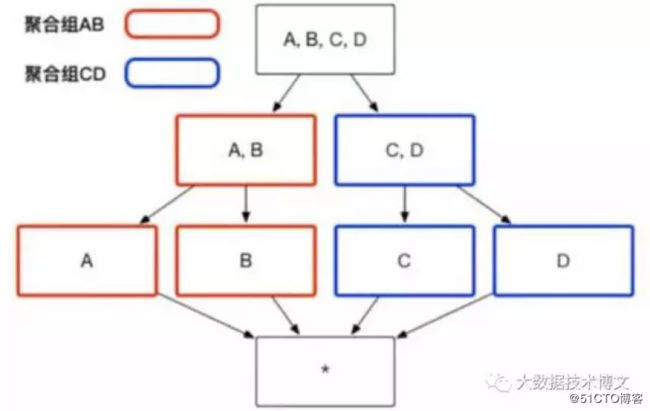
[Aggregation Group]聚合组优化
聚合组(Aggregation Group): 根据业务的维度组合,划分出具有强依赖的组合,这些组合称之为聚合组,在聚合组内,维度之间的组合会预计算,聚合组之间并不交叉预计算,从而减少Cuboid的数量.
聚合组优化效果:如果有4个维度,分别为A,B,C,D,那么就会有16个Cuboid,如果AB和CD分别为聚集组的话,那么Cuboid的数量就缩减为8个。
使用场景:所有维度中,有部分维度之间具有聚合操作的,可以将这些维度放在一个聚合组内。不放在聚合组里面的,就直接进行Base Cube操作。
[Mandatory Dimensions]强制维度
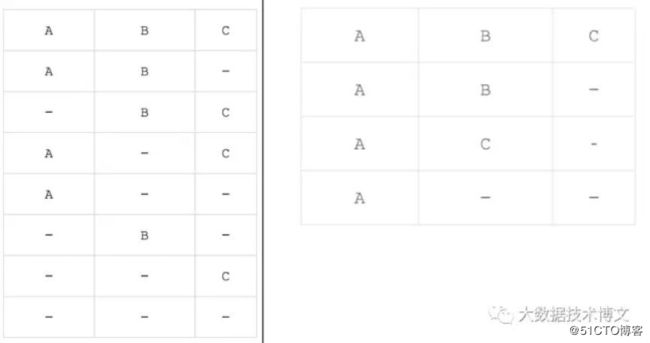
强制维度(Mandatory Dimensions):所有Cubeid中都包含的维度称之为强制维度,不包含强制维度的Cubeid不会计算。
优化效果:只计算包含强制维度的Cubeid,Cubeid的数量会缩减一半。
使用场景:假如有三个维度A,B,C,那么Cuboid就会有8个,分别为ABC,AB,BC,AC,A,B,C,这时将A设置为强制维度,那么就只会计算ABC,AB,AC,A这四个 Cubeid。
[Hierarchy Dimension]层次维度
层次维度(Hierarchy Dim):某些维度之间具有上下层次关联。
优化效果:如果有三个维度A,B,C 设置为层次维度,那么Cuboid数量将由2^3减为3+1。
使用场景:比较适用于进行下钻分析,比如年月日,省市县这种。
[Joint Dimension]联合维度
联合维度(Joint Dimension):固定用来分组的维度查询。
优化效果:将多个维度优化到一个维度。
使用场景:假如有ABC三个维度,但是在查询的时候只会出现Group by A,B,C,而不会出现Group A,Group by B,Group by A、B等等这种情况,那么就可以将A,B,C设置为联合维度。

调整Cube并发粒度
当Segment中某个Cuboid的大小超出一定的阈值时,系统会将该Cuboid的数据分片到多个Hbase Region Server,从而实现Cuboid数据读取的并行化,优化Cube的查询速度。
kylin的默认设置中
kylin.storage.hbase.region-cut-gb=5,
kylin.storage.hbase.min-region-count=1,
kylin.storage.hbase.max-region-count=500
在实际应用中(根据实际数据量调整),可以将
kylin.storage.hbase.min-region-count=2,
kylin.storage.hbase.max-region-count=100,
kylin.storage.hbase.region-cut-gb=1
上面设置为最小为2个分区,每个分区大小为1G,最多设置100个region分区。