结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程
1.什么叫中断上下文?
硬件通过触发信号,导致内核调用中断处理程序,进入内核空间。这个过程中,硬件的 一些变量和参数也要传递给内核,内核通过这些参数进行中断处理。所谓的“ 中断上下文”,其实也可以看作就是硬件传递过来的这些参数和内核需要保存的一些其他环境。
在发生中断时,内核就在被中断进程的上下文中,在内核态下执行中断服务例程。但同时会保留所有需要用到的资源,以便中继服务结束时能恢复被中断进程 的执行。
2.中断的具体过程
首先说明中断处理程序与中断服务例程的关系:
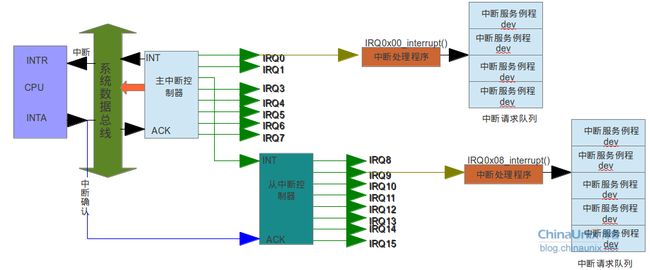
当一个中断发生时,内核应该有相应的处理方法,这个方法就是中断处理程序,一个中断处理程序对应一个中断号。中断处理程序是管理硬件的驱动程序的一部分,如果设备需要中断,相应的设备驱动程序就需注册中断处理程序。注册方式:使用request_irq()函数。
而一条中断线对应一个一个中断处理程序,而多个设备可能共享一条中断线,那么如何让中断处理程序为不同的设备提供不同的处理方法。这就引出了中断服务例程。一个中断处理程序对应若干个中断服务例程。
中断处理程序就相当于某个中断向量的总的处理程序,比如IRQ0x09_interrupt()是中断号为9的总处理程序,假如这个9号中断由5个设备共享,那么这5个设备都分别有其对应的中断服务例程。也就是说当有多个设备需要共享某个中断线时,中断处理程序必须要调用ISR,此时会调用handle_IRQ_event()
整个中断的总体流程为:首先是硬件通过中断控制器发出中断信号,中断信号对应中断向量,然后利用中断向量在IDT中找到对应中断门,在中断门中得到段选择符从而可以从GDT中找到中断服务例程的段基址。之后在栈中保存eflags、cs和eip的内容,就要选择对应的中断服务例程来完成中断所需要的服务。其中所有的中断都需要在中断服务真正开始之前执行SAVE_ALL保存上下文环境。
3.分析fork与execve的中断上下文切换
fork系统调⽤创建了⼀个⼦进程,⼦进程复制了父进程中所有的进程信息,包括内核堆栈、进程描述符等,⼦进程作为⼀个独⽴的进程也会被调度。
fork系统调用进入内核态,通过do_fork来完成,_do_dork具体代码:
1 // kernel/fork.c 2 3 long _do_fork(struct kernel_clone_args *args) 4 { 5 u64 clone_flags = args->flags; 6 struct completion vfork; 7 struct pid *pid; 8 struct task_struct *p; 9 int trace = 0; 10 long nr; 11 12 /* 13 * Determine whether and which event to report to ptracer. When 14 * called from kernel_thread or CLONE_UNTRACED is explicitly 15 * requested, no event is reported; otherwise, report if the event 16 * for the type of forking is enabled. 17 */ 18 if (!(clone_flags & CLONE_UNTRACED)) { 19 if (clone_flags & CLONE_VFORK) 20 trace = PTRACE_EVENT_VFORK; 21 else if (args->exit_signal != SIGCHLD) 22 trace = PTRACE_EVENT_CLONE; 23 else 24 trace = PTRACE_EVENT_FORK; 25 26 if (likely(!ptrace_event_enabled(current, trace))) 27 trace = 0; 28 } 29 30 p = copy_process(NULL, trace, NUMA_NO_NODE, args);//复制进程描述符和执⾏时所需的其他数据结构31 add_latent_entropy(); 32 33 if (IS_ERR(p)) 34 return PTR_ERR(p); 35 36 /* 37 * Do this prior waking up the new thread - the thread pointer 38 * might get invalid after that point, if the thread exits quickly. 39 */ 40 trace_sched_process_fork(current, p); 41 42 pid = get_task_pid(p, PIDTYPE_PID); 43 nr = pid_vnr(pid); 44 45 if (clone_flags & CLONE_PARENT_SETTID) 46 put_user(nr, args->parent_tid); 47 48 if (clone_flags & CLONE_VFORK) { 49 p->vfork_done = &vfork; 50 init_completion(&vfork); 51 get_task_struct(p); 52 } 53 54 wake_up_new_task(p);//将⼦进程添加到就绪队列 55 56 /* forking complete and child started to run, tell ptracer */ 57 if (unlikely(trace)) 58 ptrace_event_pid(trace, pid); 59 60 if (clone_flags & CLONE_VFORK) { 61 if (!wait_for_vfork_done(p, &vfork)) 62 ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid); 63 } 64 65 put_pid(pid); 66 return nr;//返回⼦进程pid(⽗进程中fork返回值为⼦进程的pid) 67 }
_do_fork主要调用了两个关键函数:copy_process和wake_up_new_task。
copy_process:克隆一个当前进程的副本并为之分配id。
execve() 系统调用通常与 fork() 系统调用配合使用。从一个进程中启动另一个程序时,通常是先 fork() 一个子进程,然后在子进程中使用 execve() 变身为运行指定程序的进程。 例如,当用户在 Shell 下输入一条命令启动指定程序时,Shell 就是先 fork() 了自身进程,然后在子进程中使用 execve() 来运行指定的程序。
execve也比较特殊。当前的可执行程序在执行,执行到execve系统调用时陷入内核态,在内核里面用do_execve加载可执行文件,把当前进程的可执行程序给覆盖掉。当execve系统调用返回时,返回的已经不是原来的那个可执行程序了,而是新的可执行程序。
execve系统调用时通过通过调⽤do_execve来具体执⾏加载可执⾏⽂件的⼯作:
1 //filename为可执行文件的名字 2 int do_execve(struct filename *filename, 3 const char __user *const __user *__argv, 4 const char __user *const __user *__envp) 5 { 6 struct user_arg_ptr argv = { .ptr.native = __argv }; 7 struct user_arg_ptr envp = { .ptr.native = __envp }; 8 return do_execveat_common(AT_FDCWD, filename, argv, envp, 0); 9 }
其又调用了do_execveat_common
1 static int do_execveat_common(int fd, struct filename *filename, 2 struct user_arg_ptr argv, 3 struct user_arg_ptr envp, 4 int flags) 5 { 6 return __do_execve_file(fd, filename, argv, envp, flags, NULL); 7 }
1 /* 2 * sys_execve() executes a new program. 3 */ 4 static int do_execveat_common(int fd, struct filename *filename, 5 struct user_arg_ptr argv, 6 struct user_arg_ptr envp, 7 int flags) 8 { 9 char *pathbuf = NULL; 10 struct linux_binprm *bprm; /* 这个结构当然是非常重要的,下文,列出了这个结构体以便查询各个成员变量的意义 */ 11 struct file *file; 12 struct files_struct *displaced; 13 int retval; 14 15 if (IS_ERR(filename)) 16 return PTR_ERR(filename); 17 18 /* 19 * We move the actual failure in case of RLIMIT_NPROC excess from 20 * set*uid() to execve() because too many poorly written programs 21 * don't check setuid() return code. Here we additionally recheck 22 * whether NPROC limit is still exceeded. 23 */ 24 if ((current->flags & PF_NPROC_EXCEEDED) && 25 atomic_read(¤t_user()->processes) > rlimit(RLIMIT_NPROC)) { 26 retval = -EAGAIN; 27 goto out_ret; 28 } 29 30 /* We're below the limit (still or again), so we don't want to make 31 * further execve() calls fail. */ 32 current->flags &= ~PF_NPROC_EXCEEDED; 33 34 // 1. 调用unshare_files()为进程复制一份文件表; 35 retval = unshare_files(&displaced); 36 if (retval) 37 goto out_ret; 38 39 retval = -ENOMEM; 40 41 // 2、调用kzalloc()在堆上分配一份structlinux_binprm结构体; 42 bprm = kzalloc(sizeof(*bprm), GFP_KERNEL); 43 if (!bprm) 44 goto out_files; 45 46 retval = prepare_bprm_creds(bprm); 47 if (retval) 48 goto out_free; 49 50 check_unsafe_exec(bprm); 51 current->in_execve = 1; 52 53 // 3、调用open_exec()查找并打开二进制文件; 54 file = do_open_execat(fd, filename, flags); 55 retval = PTR_ERR(file); 56 if (IS_ERR(file)) 57 goto out_unmark; 58 59 // 4、调用sched_exec()找到最小负载的CPU,用来执行该二进制文件; 60 sched_exec(); 61 62 // 5、根据获取的信息,填充structlinux_binprm结构体中的file、filename、interp成员; 63 bprm->file = file; 64 if (fd == AT_FDCWD || filename->name[0] == '/') { 65 bprm->filename = filename->name; 66 } else { 67 if (filename->name[0] == '\0') 68 pathbuf = kasprintf(GFP_TEMPORARY, "/dev/fd/%d", fd); 69 else 70 pathbuf = kasprintf(GFP_TEMPORARY, "/dev/fd/%d/%s", 71 fd, filename->name); 72 if (!pathbuf) { 73 retval = -ENOMEM; 74 goto out_unmark; 75 } 76 /* 77 * Record that a name derived from an O_CLOEXEC fd will be 78 * inaccessible after exec. Relies on having exclusive access to 79 * current->files (due to unshare_files above). 80 */ 81 if (close_on_exec(fd, rcu_dereference_raw(current->files->fdt))) 82 bprm->interp_flags |= BINPRM_FLAGS_PATH_INACCESSIBLE; 83 bprm->filename = pathbuf; 84 } 85 bprm->interp = bprm->filename; 86 87 // 6、调用bprm_mm_init()创建进程的内存地址空间,并调用init_new_context()检查当前进程是否使用自定义的局部描述符表;如果是,那么分配和准备一个新的LDT; 88 retval = bprm_mm_init(bprm); 89 if (retval) 90 goto out_unmark; 91 92 // 7、填充structlinux_binprm结构体中的命令行参数argv,环境变量envp 93 bprm->argc = count(argv, MAX_ARG_STRINGS); 94 if ((retval = bprm->argc) < 0) 95 goto out; 96 97 bprm->envc = count(envp, MAX_ARG_STRINGS); 98 if ((retval = bprm->envc) < 0) 99 goto out; 100 101 // 8、调用prepare_binprm()检查该二进制文件的可执行权限;最后,kernel_read()读取二进制文件的头128字节(这些字节用于识别二进制文件的格式及其他信息,后续会使用到); 102 retval = prepare_binprm(bprm); 103 if (retval < 0) 104 goto out; 105 106 // 9、调用copy_strings_kernel()从内核空间获取二进制文件的路径名称; 107 retval = copy_strings_kernel(1, &bprm->filename, bprm); 108 if (retval < 0) 109 goto out; 110 111 bprm->exec = bprm->p; 112 113 // 10.1、调用copy_string()从用户空间拷贝环境变量 114 retval = copy_strings(bprm->envc, envp, bprm); 115 if (retval < 0) 116 goto out; 117 118 // 10.2、调用copy_string()从用户空间拷贝命令行参数; 119 retval = copy_strings(bprm->argc, argv, bprm); 120 if (retval < 0) 121 goto out; 122 /* 123 至此,二进制文件已经被打开,struct linux_binprm结构体中也记录了重要信息; 124 125 下面需要识别该二进制文件的格式并最终运行该文件 126 */ 127 retval = exec_binprm(bprm); 128 if (retval < 0) 129 goto out; 130 131 /* execve succeeded */ 132 current->fs->in_exec = 0; 133 current->in_execve = 0; 134 acct_update_integrals(current); 135 task_numa_free(current); 136 free_bprm(bprm); 137 kfree(pathbuf); 138 putname(filename); 139 if (displaced) 140 put_files_struct(displaced); 141 return retval; 142 143 out: 144 if (bprm->mm) { 145 acct_arg_size(bprm, 0); 146 mmput(bprm->mm); 147 } 148 149 out_unmark: 150 current->fs->in_exec = 0; 151 current->in_execve = 0; 152 153 out_free: 154 free_bprm(bprm); 155 kfree(pathbuf); 156 157 out_files: 158 if (displaced) 159 reset_files_struct(displaced); 160 out_ret: 161 putname(filename); 162 return retval; 163 }
fork()系统调用一次调用,两次返回,如果返回是0,则是子进程,如果返回值>0,则是父进程(返回值是子进程的pid),这是众为周知的。
区别于普通系统调用,fork子进程的内核堆栈多了个fork⼦进程的进程上下⽂的数据结构:


5.以系统调用作为中断,分析Linux系统的一般执行过程
(1)正在运⾏的⽤户态进程X。
(2)发⽣中断(包括异常、系统调⽤等),CPU完成以下动作。
save cs:eip/ss:esp/eflflags:当前CPU上下⽂压⼊进程X的内核堆栈。
load cs:eip(entry of a specifific ISR) and ss:esp(point to kernel stack):加载当前进程内核堆栈相关信息,跳转到中断处理程序,即中断执⾏路径的起点。
(3)SAVE_ALL,保存现场,此时完成了中断上下⽂切换,即从进程X的⽤户态到进程X的内核态。
(4)中断处理过程中或中断返回前调⽤了schedule函数,其中的switch_to做了关键的进程上下⽂切换。将当前进程X的内核堆栈切换到进程调度算法选出来的next进程
(本例假定为进程Y)的内核堆栈,并完成了进程上下⽂所需的EIP等寄存器状态切换。详细过程⻅前述内容。
(5)标号1,即前述3.18.6内核的swtich_to代码第50⾏“”1:\t“ ”(地址为switch_to中的“$1f”),之后开始运⾏进程Y(这⾥进程Y曾经通过以上步骤被切换出去,因此可以
从标号1继续执⾏)。
(6)restore_all,恢复现场,与(3)中保存现场相对应。注意这⾥是进程Y的中断处理过程中,⽽(3)中保存现场是在进程X的中断处理过程中,因为内核堆栈从进程X
切换到进程Y了。
(7)iret - pop cs:eip/ss:esp/eflflags,从Y进程的内核堆栈中弹出(2)中硬件完成的压栈内容。此时完成了中断上下⽂的切换,即从进程Y的内核态返回到进程Y的⽤户
态。
(8)继续运⾏⽤户态进程Y。