日志数据分析之二,对某网游客访问记录及相关参数进行统计
1、需求分析
日期 uv pv 登录人数 游客人数 平均访问时长 二跳率 独立ip数
如何获取:
登录:userid有值,会员,有账号登录
游客:userid无值,非登录人员(都有身份认证的唯一id)
平均访问时长:在网页停留时间
二跳率:在一次会话中,同一个session点击的页面大于等于2的会话就是二跳(判断同一个session有多条记录的几率是多少)
==>独立ip数:统计ip去重
==>trackU访问渠道:表示你是通过什么方式进入到网站
-1.搜索引擎进入
-2.手输网页
-3.论坛、博客
-4.广告、脚本
作用:可以渠道的来源,加大投放力度,去宣传
2、对数据的处理及分析
2.1、创建一张源表,对所有的源数据进行加载,根据提供的的字段解析及日志格式,对源数据进行建表
create table yhd_source(
id string,
url string,
referer string,
keyword string,
type string,
guid string,
pageId string,
moduleId string,
linkId string,
attachedInfo string,
sessionId string,
trackerU string,
trackerType string,
ip string,
trackerSrc string,
cookie string,
orderCode string,
trackTime string,
endUserId string,
firstLink string,
sessionViewNo string,
productId string,
curMerchantId string,
provinceId string,
cityId string,
fee string,
edmActivity string,
edmEmail string,
edmJobId string,
ieVersion string,
platform string,
internalKeyword string,
resultSum string,
currentPage string,
linkPosition string,
buttonPosition string
)partitioned by (date_now string)
row format delimited fields terminated by "\t";
load data local inpath '/opt/datas/2015082818' into table yhd_source partition(date ='2015082818');
2.2、创建一张数据清洗表,只针对我们的需求索要用到的数据进行数据提取与清洗(会话信息表)
create table session_info(
session_id string ,
guid string ,
trackerU string ,
landing_url string ,
landing_url_ref string ,
user_id string ,
pv string ,
stay_time string ,
min_trackTime string ,
ip string ,
provinceId string
)
partitioned by (date_now string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
==>加载数据: 数据源来自源表
针对每一个会话进行分组group by sessionId
注意:进行分组之后,trackerU,landing_url,landing_url_ref可能会存在多条记录,获取第一条记录
==>创建两张临时表作为中间表
因为同一个session可能存在多个trackerU,landing_url,landing_url_ref
如果只创建一张临时表,对这个表进行select ... group by sessionId
结果会报错,因为一个sessionId只能对应一条数据,但是一个sessionId却有可能有多条
trackerU,landing_url,landing_url_ref数据,所以必须使用两张临时表,最后把数据根据sessionid做join
2.3、先创建一张对sessionid进行分组的表,group表 session_tmp,都是从源表中获取数据
create table session_tmp as
select
sessionId session_id,
max(guid) guid,
max(endUserId) user_id,
count(distinct url) pv,
(unix_timestamp(max(trackTime))-unix_timestamp(min(trackTime))) stay_time,
min(trackTime) min_trackTime,
max(ip) ip,
max(provinceId) provinceId
from yhd_source where date_now = '20150828'
group by sessionId;
==>从源表中获取每一条记录的trackerU,landing_url,landing_url_ref
==>从源表中获取每一条记录的时间
==>然后进行最小的时间与源表的最小时间进行join
2.4、创建第二张临时表,用来和第一张临时表进行join,来提取出每一个sessionid所对应的需要的唯一的值,都是从源表中获取数据
create table track_tmp as
select
sessionId session_id, 唯一sessionid
trackTime trackTime, 最下时间
url landing_url,
trackerU trackerU,
referer landing_url_ref
from yhd_source where date_now='20150828';
2.5、对数据进行join,提取出结果,根据session_info表所需要的字段,对两张临时表进行join提取
insert overwrite table session_info partition(date_now='2015082818')
select
a.session_id,
a.guid,
b.trackerU,
b.landing_url,
b.landing_url_ref,
a.user_id,
a.pv,
a.stay_time,
a.min_trackTime,
a.ip,
a.provinceId
from session_tmp a join track_tmp b
on a.session_id=b.session_id and a.min_trackTime=b.trackTime;
==>此时,所提取的每一条sessionid的数据,应该是合格的,完整的,可以做完全的的做一个日志的相关维度分析
2.6、创建结果表,对相关字段进行数据统计,如下图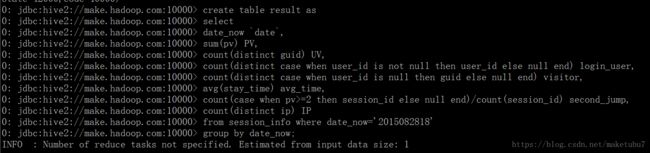
对我们的result的内容进行查询,可以看到我们对游客的人数统计为0,这明显是错误的,不可能一个游客都没有的,userID是存在很多的,一定是哪里出了问题,我们对结果表进行重建,对user_id的统计换一种方式,

2.7、再次创建结果表,可以从图中看出,我们对userID的统计换了一种方式,上面是对内容是否为空进行统计,第二次我们是以 length(userID)的值来进行统计
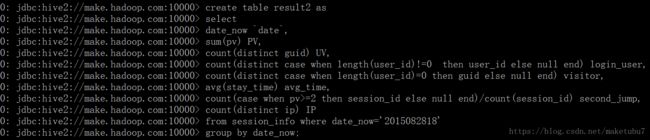
再次对我们的结果进行,查询,我们可以得到一份玩着方的日志分析结果,对应我们的需求
==>日期 uv pv 登录人数 游客人数 平均访问时长 二跳率 独立ip数
得到了一个相对准确的的统计结果,其实大数据多统计出来的数据,你永远不知道他是否精确,你只需要判断,数据是否异常,趋势是怎样的,该向那个方向拓展,就可以了

到这里,一次日志数据的简单分析就完成了,这里我们的数据量是非常小的,后面会遇到几十亿行数据的分析,那个时候,我们应该会用更加高级的方式来进行处理,拭目以待,
日志下载地址:链接: https://pan.baidu.com/s/1o20USOfSYgiaLyoDDkMfLg
密码: cr4q 可以自行测试