MLAPP————第十一章 混合模型和EM算法
第十一章 混合模型和EM算法
11.1 隐变量模型
在第十章中,我们展示了如何用一个概率图模型去表示一个高维的联合概率分布。基本思想是通过在图中添加两个变量之间的边来建立两个变量之间的依赖关系。
另一种方法假设我们的观察到的变量是相关的,就是假设它们都受到某个隐藏的变量影响。这样的模型我们就叫做潜在变量模型(latent variable models, LVMs),我觉得在这里要说明一下,之前因为也讲到隐变量,隐变量就是我们观测不到的变量,所以我觉得这里用latent这个词非常好,因为这里不仅仅是隐藏的变量,更是我们都不知道存不存在或者我们假想的潜在的变量。正如我们将在本章中看到的,这种模型比没有潜在变量的模型更难拟合。然而,它们可以有显著的优势,主要有两个原因。首先,LVMs的参数通常比直接表示可见空间中的相关性的模型少。如下图所示。如果所有节点(包括H)都是二进制的,所有CPD都是表格的,那么左边的模型有17个自由参数,而右边的模型有59个自由参数。在图中叶子代表了医学症状。根系代表主要原因,如吸烟、饮食和锻炼。隐藏的变量可以表示中介因素,例如心脏病,这些因素可能不是直接可见的。

其次,LVM中的隐藏变量可以作为瓶颈,计算数据的压缩表示。这就形成了无监督学习的基础。就类似于上面这张图,不通过隐变量得不到后面的推理结果。这其实就是形成非监督学习的基础,我们后面将看到。下图说明了一些可用于此目的的通用LVM结构。

(a)是many-to-many (b)是one-to-many (c)是many-to-one (d)是one-to-one
一般来说,会有L个隐变量:![]() ,D个可见变量
,D个可见变量![]() ,一般来说
,一般来说![]() 。如果我们有
。如果我们有![]() ,每个观察都有许多潜在的因素,所以我们有many-to-many映射。如果
,每个观察都有许多潜在的因素,所以我们有many-to-many映射。如果![]() ,我们只有一个潜在变量,在这种情况下,
,我们只有一个潜在变量,在这种情况下,![]() 通常是离散的,我们有one-to-many映射。我们也可以有many-to-one的映射,为每个观察到的变量表示不同的竞争因素或原因。最后,我们可以得到一个one-to-one的映射,它可以表示为
通常是离散的,我们有one-to-many映射。我们也可以有many-to-one的映射,为每个观察到的变量表示不同的竞争因素或原因。最后,我们可以得到一个one-to-one的映射,它可以表示为![]() 。根据似然
。根据似然![]() 和先验
和先验![]() 的形式,我们可以生成各种不同的模型,如下表所示:
的形式,我们可以生成各种不同的模型,如下表所示:

11.2 混合模型
LVM最简单的形式就是![]() ,也就是
,也就是![]() 是有K个状态的离散的隐变量。所以我们假设先验就是
是有K个状态的离散的隐变量。所以我们假设先验就是![]() 。对于似然函数来说,我们使用
。对于似然函数来说,我们使用![]() ,其中
,其中![]() 就是对于观测的第k个基分布(base distribution),这个可以是任何形式的。但是整个模型就是我们所谓的混合模型,因为我们把K个基本分布混合在一起:
就是对于观测的第k个基分布(base distribution),这个可以是任何形式的。但是整个模型就是我们所谓的混合模型,因为我们把K个基本分布混合在一起:

其实上面每个分布的![]() 是不太一样的,这是关于所有的
是不太一样的,这是关于所有的![]() 的一个线性组合,也可以叫做凸组合,其中我们有
的一个线性组合,也可以叫做凸组合,其中我们有![]() 以及
以及![]() 。下面我们举一些具体的例子:
。下面我们举一些具体的例子:
11.2.1 混合高斯模型
使用最广泛的混合模型就是混合高斯模型(mixture of Gaussian MOG),也叫做高斯混合模型(Gaussian mixture model GMM)。在这个模型中,混合分布中的每个基分布都是多元高斯分布,其中均值为![]() ,协方差矩阵为
,协方差矩阵为![]() 。因此模型具有如下的形式:
。因此模型具有如下的形式:

下图显示了二维中3个高斯函数的混合。每一种混合的分量都由一组不同的等高线表示。GMM可以用来近似![]() 上定义的任何密度,只要这个数目够多。
上定义的任何密度,只要这个数目够多。

11.2.2 multinoullis 的混合
我们可以使用混合模型来定义各种数据的密度模型。例如,假设我们的数据是D维的0-1的向量。在这样的情况下,近似的条件分布就是若干个伯努利分布乘起来:

潜变量(latent variables)没有任何意义,我们可以简单地引入潜变量,以使模型更强大。例如,可以证明混合分布的均值和协方差为:

其中![]() ,所以虽然分量分布是可以因式分解的,但联合分布并不是这样。因此,混合分布可以捕获变量之间的相关性,并不是伯努利分布的这样一个简单的乘积。上面的具体证明过程如下:
,所以虽然分量分布是可以因式分解的,但联合分布并不是这样。因此,混合分布可以捕获变量之间的相关性,并不是伯努利分布的这样一个简单的乘积。上面的具体证明过程如下:

11.2.3 对于聚类使用混合模型
对于混合模型来说,有两个主要的应用。第一个就是把他们当成是黑盒的密度模型![]() 。这对于各种任务都很有用,例如数据压缩、离群值检测和生成分类器的创建,在这些任务中,我们通过混合分布对每个类条件密度p(x|y = c)建模。第二,也是更常见的,混合模型的应用是将它们用于聚类。我们将在第25章详细讨论这个主题,但基本思想很简单。我们先去拟合这个混合模型,然后去计算
。这对于各种任务都很有用,例如数据压缩、离群值检测和生成分类器的创建,在这些任务中,我们通过混合分布对每个类条件密度p(x|y = c)建模。第二,也是更常见的,混合模型的应用是将它们用于聚类。我们将在第25章详细讨论这个主题,但基本思想很简单。我们先去拟合这个混合模型,然后去计算![]() ,这个后验概率分布表明了
,这个后验概率分布表明了![]() 这个数据点属于k这个类别的概率。可以按照如下的贝叶斯规则计算:
这个数据点属于k这个类别的概率。可以按照如下的贝叶斯规则计算:
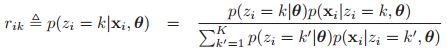
这个过程称为软聚类,与使用生成分类器时执行的计算相同。两种模型的区别只出现在训练时:在混合的情况下,我们从不观察zi,而在生成分类器中,我们观察yi(扮演zi的角色)。
我们可以使用![]() 表示聚类的这样一个不确定性。假设如果这个不确定性是很小的话,那么我们就可以采用硬判决,叫hard clustering,使用MAP估计,即:
表示聚类的这样一个不确定性。假设如果这个不确定性是很小的话,那么我们就可以采用硬判决,叫hard clustering,使用MAP估计,即:
![]()
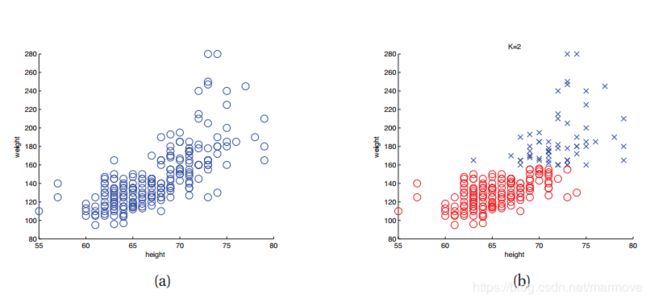
使用GMM进行硬聚类如下图所示,其中我们对一些表示人的身高和体重的数据进行聚类。颜色代表了硬性的分类。请注意,所使用的标签(颜色)的标识是不重要的;我们可以自由地重命名所有集群,而不会影响数据的分区;这叫做标签交换。
作为聚类二进制数据的一个例子,考虑一个MNIST手写数字数据集的二值化版本(只有0-1)如下图,其中我们忽略了类标签(我们最终只是把数据分为10类,并不标注哪一个是9或者0等)。我们可以使用混合的multinoullis模型来拟合它。其中我们的K=10,我们的数据是256的0-1向量,参数![]() 也是256的向量。
也是256的向量。

这里从之前聚类的问题看出,我们首先是给出了若干幅手写数字图片,希望系统最终能够使得0-9分为十类,但是从上图我们看出有很多误分类的情况,比如有有两个9被分到了不同的类别中,以及1和0也是一样的情况,所以这个聚类的效果并不是很好。产生这样的误分类的主要原因有如下几种:
该模型非常简单,没有捕捉到数字的相关视觉特征。例如,每个像素都是独立处理的,没有形状或笔触的概念。
因为手写字体有很多的书写习惯,所以可能我们需要更多的类别,K可能要很大,但是很大的K又不能将这些看上去有些区别但是实际是一个数字的字体分到一起,这样就达不到我们的目的,所以其实很难做。(这么看,这个方法做手写识别还是太不靠谱了)
似然函数是非凸的,可能收敛不到全局最优解。
11.2.4 专家的混合(Mixtures of experts)
在后面14.7.3我们将会讲到如何在生成分类器的背景下使用混合模型。但是在这里我们要讲的就是混合模型也可以很好应用到关于分类和回归的判别模型中。例如,我们看下图:

图(a)中,我们可以看到这个数据用三个线性回归函数来拟合更好,而且每一个线性回归函数对应一个输入空间,我们可以假设模型是这样的:
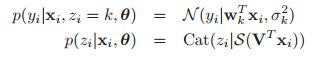
具体的图模型如下:

这个模型就称之为Mixtures of experts(MoE)。其思想是每个子模型都被认为是输入空间某一区域的专家。![]() 被称之为门函数(gating function),决定了我们要去用哪一个领域的专家。在上图的(b)中,我们可以看到门函数的具体的样子,输入小于-0.5就是红色的虚线,大于0.5就是蓝色点虚线,中间则是黑线。(c)则是展示了模型最终的估计,即:
被称之为门函数(gating function),决定了我们要去用哪一个领域的专家。在上图的(b)中,我们可以看到门函数的具体的样子,输入小于-0.5就是红色的虚线,大于0.5就是蓝色点虚线,中间则是黑线。(c)则是展示了模型最终的估计,即:

我们刚刚讲的例子是比较简单的,其实我们的专家可以更加的复杂,我们的门函数也可以改成神经网络中的gate function。甚至我们还可以用多层的混合专家模型,这在后面都会提到。
11.2.4.1 逆问题的应用
关于逆问题,首先我们先举个例子,比如机器手,末端执行器(手)的位置是唯一由电机的关节角决定的,但是如果我们已知末端执行手的位置,其实电机的关节角可以有多种选择。这就是所谓的many-to-one的逆问题,因为你是许多个情况对应一个情况,所以很多时候用mixtures of experts来解决问题。
举一个简单的例子具体如下图:

关于图(a)的逆问题就是图(b),我们可以看到的是,对于一个固定的y可能会有两个x与其对应,所以此时我们就用三条线来拟合,最后估计的结果就是图(c),利用的是书上的11.10公式。但是我觉得这样的估计其实是一个折中的结果,得到的解其实并不是很好的,只是比较折中,不会很差。
11.3 混合模型的参数估计
前面我们可以看到,利用贝叶斯的生成公式,如果我们的参数都已知的话,可以得到隐变量的生成公式:
这个公式我们上面已经提到过,这里在重现一下。在这一小结中,我们将讨论怎么去估计参数。
10.4.2说明了,如果我们有完整的数据(没有丢失的数据以及没有隐变量)以及factored先验,那么关于参数的后验也是factored,所以使得计算会非常简单。很不幸的是,如果我们有隐变量或者有缺失的数据的话,上面的结论就不再正确了。我们先看下图:

在![]() 被观测到的情况下,那么利用贝叶斯球的规则,我们很容易得到
被观测到的情况下,那么利用贝叶斯球的规则,我们很容易得到![]() ,那么关于参数的后验分布也是factored。但是在LVM中,
,那么关于参数的后验分布也是factored。但是在LVM中,![]() 是隐变量,是没有被观测到的,此时参数就不再关于观测是条件独立的,就不能factored,这就导致计算变得复杂很多。这也使MAP和ML估计的计算变得复杂,下面我们将对此进行讨论。
是隐变量,是没有被观测到的,此时参数就不再关于观测是条件独立的,就不能factored,这就导致计算变得复杂很多。这也使MAP和ML估计的计算变得复杂,下面我们将对此进行讨论。
11.3.1 不可识别(unidentifiability)
在LVM模型下进行参数的估计一个主要的问题就是![]() 它是有好几个峰的。那么为什么会这样呢,我们下面考虑GMM模型。如果隐变量都被观测到了,那么我们关于参数的后验就是单峰的:
它是有好几个峰的。那么为什么会这样呢,我们下面考虑GMM模型。如果隐变量都被观测到了,那么我们关于参数的后验就是单峰的:
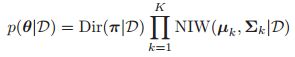
那么我们很容易利用MAP(或者MLE)得到全局的最优解。
但是现在我们考虑我们的隐变量是没有被观测到的,那么对于每一个可能的隐变量的取值形式,我们就会得到一个峰值,那么这样如果我们对于隐变量进行积分的话,就会得到一个多峰的后验分布(这样的多峰的原因就类似于做聚类问题时这个标签顺序置换了)。进一步说明,我们来看一个例子,我们看下图是一个K=2的例子:

在图(b)中,这是一个似然函数的图![]() ,数据的采集是图(a),图(b)中其余的参数我们取得是真实值(
,数据的采集是图(a),图(b)中其余的参数我们取得是真实值(![]() ,当然这里由于这个值是0.5,所以标签的互换就是一样,即
,当然这里由于这个值是0.5,所以标签的互换就是一样,即![]() 估计结果是正的或者反的都可以。),我们可以看到这个似然函数会有两个峰值,其中一个是:
估计结果是正的或者反的都可以。),我们可以看到这个似然函数会有两个峰值,其中一个是:![]() ,另一种情况就是
,另一种情况就是![]()
![]() ,那么我们的参数就不是唯一的,我们的MLE也不是唯一的,(0.2,0.8,-10,10)以及(0.8,0.2,10,-10)都是MLE的结果。那么如果我们的先验没有把这个标签问题给去掉的话,那么我们的后验肯定也不是唯一的,所以后验分布就是多峰的。那么这个峰到底有多少个呢,我们从MLE的情况来看,应该有K!个(每一种排列都是一个),当然如果由于先验,或者是不同的
,那么我们的参数就不是唯一的,我们的MLE也不是唯一的,(0.2,0.8,-10,10)以及(0.8,0.2,10,-10)都是MLE的结果。那么如果我们的先验没有把这个标签问题给去掉的话,那么我们的后验肯定也不是唯一的,所以后验分布就是多峰的。那么这个峰到底有多少个呢,我们从MLE的情况来看,应该有K!个(每一种排列都是一个),当然如果由于先验,或者是不同的![]() 的参数是一样的,那么有些峰可能会合并,但是总的来说是很大的(指数级别的)。(到这里为止,我个人认为,那随便找一个峰都是可以的啊,这时候模型本身其实是已经确定了啊,顺序本身并不重要啊)。
的参数是一样的,那么有些峰可能会合并,但是总的来说是很大的(指数级别的)。(到这里为止,我个人认为,那随便找一个峰都是可以的啊,这时候模型本身其实是已经确定了啊,顺序本身并不重要啊)。
那么在贝叶斯推理里面,这个会导致什么问题呢。比如说我们已经拿到了后验分布了,假设我们从这个分布里面采样一些点![]() ,采样了这些点之后,我们用他们的均值来进行后验的均值即
,采样了这些点之后,我们用他们的均值来进行后验的均值即![]() (在后面的24章,我们将详细的解释这个Monte carlo 方法),如果我们的采样是来自于不同的峰的话,那么这个均值就没有任何的意义。但是注意
(在后面的24章,我们将详细的解释这个Monte carlo 方法),如果我们的采样是来自于不同的峰的话,那么这个均值就没有任何的意义。但是注意![]() 这个式子本身还是有意义的,因为标签的错乱并不会导致数据生成的问题,不同的标签生成出来的数据都是合理的,所以用这个去近似数据的分布还是合理的。
这个式子本身还是有意义的,因为标签的错乱并不会导致数据生成的问题,不同的标签生成出来的数据都是合理的,所以用这个去近似数据的分布还是合理的。
针对这样的不可识别的问题,提出了很多种的方法,这些解决方案取决于模型的细节和使用的推理算法。例如,针对使用MCMC处理混合模型,解决不可识别的方法见(Stephens 2000)。
在本章中使用的方法要简单的多,我们仅仅计算一个局部的峰值,因此我们只是进行一个近似的MAP估计。当然因为它很简单,所以也是目前最常见的方法。至少在样本容量很大的时候,采用这样的一种近似的方法是很合理的(针对MLE,local的其实就是global的,而样本数目很多的时候,MAP近似于MLE)。在分层贝叶斯学习中,分布本身带来的不确定性是很有必要的,使用点估计不是很好。
11.3.2 在非凸问题下计算MAP估计
在前几节中,我们相当直观地讨论了似然函数具有多个峰值,因此很难找到MAP或ML估计。在这一节中,我们将通过更加代数的方法来展示这个结果,从而进一步深入了解这个问题。这一块的展示主要是基于(Rennie 2004)。
我们考虑LVM模型的log似然函数:

不幸的是,最大化这个log似然函数是非常的难的,因为我们的log函数里面还有一个求和(或者积分)。这里只是排除了某些代数的简化方式,但并没有证明这个问题是困难的。
现在我们假设我们的这个联合分布![]() 是在指数家族里面的,这意味着它可以写成如下的形式:
是在指数家族里面的,这意味着它可以写成如下的形式:
![]()
我们遇到的很多的分布比如Gaussian,Dirichlet, multinomial, Gamma, Wishart等都是指数家族的(学生分布是个例外),我们可以证明MVN是在指数家族里面的。进一步,指数家族分布的混合任然是属于指数家族的(在隐变量被观测到的情况下)。

在这样的假设下,我们可以得到完整数据的log似然为:
![]()
我们可以看到左边关于![]() 是线性的,而右边其实是一个凸函数(Boyd and Vandenberghe 2004),所以整个这样一个函数是凹函数,所以这个函数只有一个最大值。
是线性的,而右边其实是一个凸函数(Boyd and Vandenberghe 2004),所以整个这样一个函数是凹函数,所以这个函数只有一个最大值。
现在我们考虑我们这个隐变量没有被观测到的情况,那么这个时候我们的log似然函数具有如下的形式:
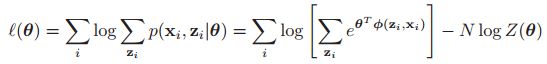
在boyd书中,我们有log-sum-exp是凸函数,我们上面也说了![]() 是凸函数,但是两个凸函数的差并不是凸函数,所以这个函数既不是凸的也不是凹的,所以就会有局部的最优值。
是凸函数,但是两个凸函数的差并不是凸函数,所以这个函数既不是凸的也不是凹的,所以就会有局部的最优值。
关于非凸函数的一个缺点就是我们很难找到它的全局最优点。大部分的优化算法只能够找到这种函数的局部最优点,具体是哪一个取决于初始点的位置。也有一些其他的算法,如模拟退火算法(simulated annealing 24.6.1)或者遗传算法(genetic algorithm),这些算法生称它们往往能够找到全局最优解,但是它们都是建立在一些不切实际的假设下的。在实践中,我们使用local optimizor,当然我们会使用多个随机的初始点来提高我们找到一个不错的局部最优点的概率。当然,仔细的初始化也会有很大帮助。我们举例说明如何在个案的基础上做到这一点。
在这章中我们将讲到EM算法,其实很多利用稀疏性提高性能的算法都是加了一个非凸的惩罚项,然后用EM算法去求解,这就告诉我们不要害怕非凸的函数。
11.4 EM算法
正如我们上面讲到的,在机器学习和统计领域,当我们在complete data的情况下,计算ML或者MAP估计往往是比较容易的(很多情况下都是凸的),但是在有丢失数据或者隐变量的情况下,关于ML和MAP的计算就会变得相当复杂。
其中的一个方法就是利用一般的基于梯度的优化方法去得到负的log似然的(NLL)的一个局部最小值,具体如下:
![]()
但是,我们一般会加一些约束条件,比如我们要求协方差矩阵是正定的,我们的混合权重系数的和是1,这样就变得比较棘手。在这样的情况下,我们使用一个叫做期望最大化(expectation maximization,EM)的更加简单的算法。这是一个简单的迭代算法,对于每一步更新都会有闭式的表达式,更重要的是,这个算法能够自动的满足这些约束。
EM算法基于的一个想法就是在我们的数据被完全观测到的情况下(complete data),没那么ML和MAP估计将会变得简单。所以EM算法包含E step和M step两个部分(迭代的去做)。在Estep下,就是推理哪些没有被看到的值,在Mstep下(这样就会变成了complete data的情况),优化未知的参数。下面的表给出了下面具体要对EM算法的具体介绍:

最后会对EM算法有一个比较理论的讨论。
11.4.1 基本的思想
首先令![]() 是我们观测到的变量,
是我们观测到的变量,![]() 是我们观测不到的隐变量。那我们的目标就是去最大化这个关于观测到的数据的log似然函数:
是我们观测不到的隐变量。那我们的目标就是去最大化这个关于观测到的数据的log似然函数:

之前已经说过,优化这个函数是比较的复杂的,EM算法则用下面的方法解决了这个问题。首先我们定义完整数据的log似然函数,具体如下:

但是由于log不能放到求和函数里面去,所以没有办法计算。所以我们定义了一个叫做期望完全数据的log似然(expected complete data log likelihood):
![]() =
=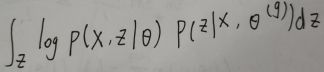 (这里的g就是前面的t-1)
(这里的g就是前面的t-1)
其中t就是当前的迭代次数。Q叫做辅助函数(auxiliary function)。这里的期望是基于观测到的数据![]() 以及上一个时刻的参数下的
以及上一个时刻的参数下的![]() 求期望(把z给积分掉)。在E step里,我们就是要计算
求期望(把z给积分掉)。在E step里,我们就是要计算![]() 。得到这个之后,在M step里,我们就是要计算:
。得到这个之后,在M step里,我们就是要计算:
![]()
上面是计算的是MLE,如果是MAP的话,那么就是计算:
![]()
在MAP中,E step还是保持不变的。
在11.4.7中,我们将会展示,EM算法其实会逐渐的增加log似然函数的值的,如果在EM算法的仿真中,你的log似然函数变小了,那么说明代码肯定出现了问题。
下面我们就具体看看EM算法在一些简单模型中的应用。
11.4.2 EM算法在GMMs中的应用
在这一节中,我们考虑如何将EM算法应用到GMM模型当中去,对于其它的一些混合模型,有时往往只需要做一些简单的改变就行。我们假设模型混合的个数K是知道的。
11.4.2.1 辅助函数
我们的辅助函数,即期望完整数据的log似然为:

公式的第二行,我们可以看到没选中的就是1,所以只保留了zi=k的那一项。这一块的推导整体上并不是针对GMM的,对于其它的混合模型同样是适用的。公式中![]() 表明的是观测的第i个数据属于第k个类别的可靠度。
表明的是观测的第i个数据属于第k个类别的可靠度。
11.4.2.2 E step
E step的具体公式如下,对于所有的混合模型都是一样的:

11.4.2.3 M step
在M step中,我们优化Q中的参数![]() 。对于
。对于![]() ,我们很显然有:
,我们很显然有:

其中![]() 是所有的数据点在k这个类的概率的和(拉格朗日乘数法)。
是所有的数据点在k这个类的概率的和(拉格朗日乘数法)。
以上其实我们推导的都是针对一般的模型,在GMM模型中,我们再M step中需要更新的参数是![]() ,我们可以看到在Q中跟
,我们可以看到在Q中跟![]() 有关的式子就是其右边(我们可以对于每一个k单独优化,这也是我们为什么要把它转化成complete data),所以我们要优化的是:
有关的式子就是其右边(我们可以对于每一个k单独优化,这也是我们为什么要把它转化成complete data),所以我们要优化的是:

我们可以看到这个和MVN其实就是加了一个权重系数。我们最终的估计结果是:
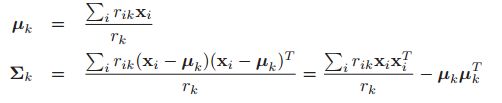
具体推导过程如下:

这些方程很直观:聚类k的均值就是分配给聚类k的所有点的加权平均值,协方差与加权经验散点矩阵成比例。在M step结束了之后,我们将参数更新后再次到E step里面去进行计算。
11.4.2.4 例子
下面给出了关于这个算法的一个具体的例子以及其更新的过程:
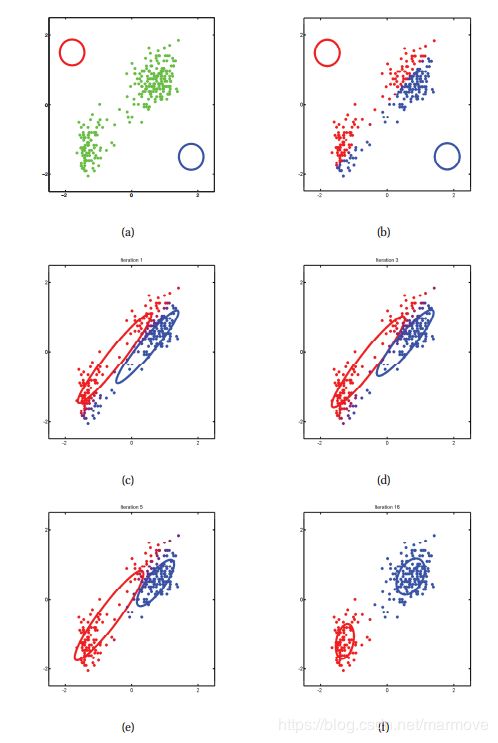
首先,如上图,这个是有两个高斯分布的情况,我们一开始初始化参数为![]()
![]() ,这里我们看到(a)就是一开始的状态,(b)就是进行了E step,每个点的关于z的后验分布出来了,红点,表示其后延分布更倾向于红色的类,相反蓝色的则是表示更加倾向于蓝色的。其颜色的具体的计算是这样的:
,这里我们看到(a)就是一开始的状态,(b)就是进行了E step,每个点的关于z的后验分布出来了,红点,表示其后延分布更倾向于红色的类,相反蓝色的则是表示更加倾向于蓝色的。其颜色的具体的计算是这样的:![]() ,所以歧义点是紫色的(不过我根本看不出来,只看到红蓝色)。(c)就是我们有再去更新参数,如此反复就会得到(f)的最终结果。
,所以歧义点是紫色的(不过我根本看不出来,只看到红蓝色)。(c)就是我们有再去更新参数,如此反复就会得到(f)的最终结果。
11.4.2.5 K-means 算法
关于GMMs里EM算法的一个比较流行的变形就是K-means算法。考虑在一个GMM模型中,我们做出如下的假设:
![]()
![]() ,
,![]() 都是固定已知的,所以我们需要估计的只有
都是固定已知的,所以我们需要估计的只有![]() 这个中心点的位置。
这个中心点的位置。
另外我们再考虑,之前我们计算关于z的后验分布![]() 的时候是利用的是:
的时候是利用的是:
现在我们利用的是delta函数来近似在E step中的这样一个后验分布:![]() ,其中我们有:
,其中我们有:![]() ,我们称这个为hard EM,因为我们这里用了一个硬判决。因为我们这里的所有的协方差矩阵是一样的,所以说
,我们称这个为hard EM,因为我们这里用了一个硬判决。因为我们这里的所有的协方差矩阵是一样的,所以说![]() ,这一点可以根据zi的后验分布计算公式看出来。因此,在每一个E step中,我们必须找到N个数据点到K个簇中心的欧式距离,这需要O(NKD)的时间。但是,可以使用各种技术来加速这一过程,例如应用三角不等式来避免一些冗余的计算。
,这一点可以根据zi的后验分布计算公式看出来。因此,在每一个E step中,我们必须找到N个数据点到K个簇中心的欧式距离,这需要O(NKD)的时间。但是,可以使用各种技术来加速这一过程,例如应用三角不等式来避免一些冗余的计算。
在上面的硬判据,所以在M step中,我们的均值的计算结果是:![]() (就是zi等于k的这些数据的平均),下面我们展示相关的伪代码:
(就是zi等于k的这些数据的平均),下面我们展示相关的伪代码:

11.4.2.6 矢量量化
由于K-means算法在中间使用的硬性的判决,他并不是最大化似然函数,所以其实并不是真正意义上的EM算法,只是一个简单版本的变形。相反,它可以被解释为一种贪婪算法,用于近似地最小化与数据压缩相关的损失函数(下面将具体的进行解释)。
考虑我们需要对一些实值的向量![]() 进行有损的压缩。一个非常简单方法就是我们使用矢量量化的方法。基本的思想就是我们将我们的这些实值的向量都赋予一个离散的标号
进行有损的压缩。一个非常简单方法就是我们使用矢量量化的方法。基本的思想就是我们将我们的这些实值的向量都赋予一个离散的标号![]() ,这对应于一个含有K个值的码书
,这对应于一个含有K个值的码书![]() 。那么我们的编码过程就是利用欧几里得距离最小这个量进行衡量:
。那么我们的编码过程就是利用欧几里得距离最小这个量进行衡量:
![]()
我们可以定义在这个情况下的损失函数(就是编码完之后再译码回来跟真实的值之间的差距):

其中![]() ,其实K-means算法就可以是看做在迭代的做这么一个操作。
,其实K-means算法就可以是看做在迭代的做这么一个操作。
当然,我们也可以做到0失真,只要我们给每一个数据都给一个编码,其实就是把N个数分成N类这种,但是这个编码需要的空间是O(NDC),其实就是没有压缩,这里N就是实数向量的个数,D就是每个向量的长度,C就是每个实数的记录所需要的比特数。但是在实际的数据集中,可能有很多的向量是长得非常接近的,所以其实我们并不需要重复的存储他们很多次,这个时候我们可能用指针来做就会节省很多空间。在这种情况下,其实我们所需要的空间就是![]() ,怎么来思考这个问题呢,首先我们有N个向量,K是没有重复的向量的数目(当然这个K是可以有我们设定的,其实就是前面的有损编码的码书里面的元素个数),那么我们就需要
,怎么来思考这个问题呢,首先我们有N个向量,K是没有重复的向量的数目(当然这个K是可以有我们设定的,其实就是前面的有损编码的码书里面的元素个数),那么我们就需要![]() 个bits对其进行编码,那么我们每一个向量只要对应于一个编码就行,后面就是存储这K个不同的向量所需要的空间。一般来说重复的会很多,就是K很小,那么这个时候前一项就是主导,所以这个空间就是
个bits对其进行编码,那么我们每一个向量只要对应于一个编码就行,后面就是存储这K个不同的向量所需要的空间。一般来说重复的会很多,就是K很小,那么这个时候前一项就是主导,所以这个空间就是![]() ,这要远比
,这要远比![]() 要小。
要小。
关于VQ的一个应用就是在图像压缩的领域。考虑一个有![]() 像素点的图如下:
像素点的图如下:

因为这是一个灰度图,所以D=1,我们用一个byte就是8bits来表示一个点(0-255),那么C=8,所以我们就需要NDC = 512000个bits来描绘这幅图。但是如果对于压缩了的图的话,如果我们设定K=4,那么我们只需要128kb,压缩了大概4倍,当然K越大,压缩率就越低,所以图像可能失真的也越少,相反则压缩率越高,图像也会失真的比较明显。
11.4.2.7 初始化和避免局部最小值
无论是K-means还是EM算法都需要初始化。我们都需要找K个值并作为我们这些聚类点的中心。一种最简单的方法就是我们随机找K个点作为我们这样初始化的中心点。还有另一种方法就是我们迭代的(序贯的)去找初始点。首先我们先找一个初始点,然后我们再找下一个初始点,这个初始点要能够使得整个点之间的距离整体比较的分散。具体如下:

其中我们有 ,这是(Bahmani 2012年的文章中的k-means++算法)。
,这是(Bahmani 2012年的文章中的k-means++算法)。
令人感到惊讶的是,有人证明了在这样的初始化下,失真比最优的情况差最多O(logK)(有理论下界)。
另一个在语音识别领域比较常用的启发式的方法是叫做渐进式增长的GMMs:首先我们基于混合权重对每个类初始化一个得分(score)。在每一轮的训练之后,我们考虑将得分最高的那个类分成两个类,新的中心点事原来中心点加了一些扰动,新的分数是旧的分数的一半。如果一个新集群的得分太小,或者方差太窄,就会删除它。我们继续这样做,直到达到所需的集群数量。
11.4.2.8 MAP估计
MLE估计的话,往往会产生过拟合的问题,我们之前也常常会提到过这个问题。在GMMs中,过拟合的问题是非常严重的,为了简单起见,假设我们的![]() ,然后
,然后![]() 。我们假设我们的数据是如下的样子:
。我们假设我们的数据是如下的样子:

最左边的这个点,可能会被分成一个类别里面去,那么它的似然函数就是 ,也就是说这个似然的结果可以趋向于无穷,只要这个方差足够的小,也就是说这个高斯分布是趋于delta函数的,这就是由于数据量太少导致的过拟合问题。
,也就是说这个似然的结果可以趋向于无穷,只要这个方差足够的小,也就是说这个高斯分布是趋于delta函数的,这就是由于数据量太少导致的过拟合问题。
针对这样的过拟合问题,我们已经不是第一次遇到了,那么解决MLE过拟合的问题,那就是使用先验,做MAP估计。那么我们的辅助函数就是变成了期望完整数据的log似然加上log先验,即:

关于E step是没有任何的改变的,改变的知识M step。
对于混合权重的先验,使用Dirichlet先验是比较自然的,![]() ,因为这个分布是Cat分布的共轭先验,那么它的MAP估计就是:
,因为这个分布是Cat分布的共轭先验,那么它的MAP估计就是:
![]()
如果我们使用的是无信息的先验,那么![]() ,那么这个就是MLE的结果是一样的了。
,那么这个就是MLE的结果是一样的了。
关于类条件参数的先验,那要具体情况具体分析,我们下面讨论的是GMMs的情况。为了简单起见,我们同样使用共轭先验:![]()
我们从4.6.3中可以看出,MAP估计的结果就是(这一点是稍微分析一下就能很容易看出来的):

我们下面就要阐明为什么我们要在GMMs的框架下用MAP估计而不是用ML估计。我们将EM应用于D维的一些合成数据,然后分别使用ML或MAP估计。如果有涉及奇异矩阵的数值问题,我们认为试验是失败的。对于每个维度,我们进行5次随机试验。结果如下图所示,使用N = 100:
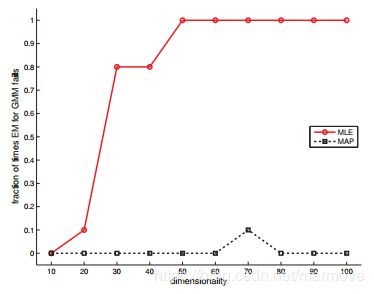
我们发现在MLE中,D稍微增大一点点,就直接崩掉了,但是MAP估计器却从来不会出现这样的问题。在使用MAP估计时,需要指定超参数。在这里我们可以设定![]() ,因为数值仿真问题导致是因为协方差矩阵奇异导致的。在这样的情况下,MAP估计的结果就可以写的更加简答一些:
,因为数值仿真问题导致是因为协方差矩阵奇异导致的。在这样的情况下,MAP估计的结果就可以写的更加简答一些:![]() ,这样看起来就没那么吓人了。
,这样看起来就没那么吓人了。
现在我们考虑怎么去设定![]() ,一个可能的例子就是使用:
,一个可能的例子就是使用:![]() ,其中
,其中![]() 。参数
。参数![]() 控制我们对我们的先验的相信程度。最弱的我们可以使用之前,虽然仍是正确的,是设置,这是一个常见的选择。
控制我们对我们的先验的相信程度。最弱的我们可以使用之前,虽然仍是正确的,是设置,这是一个常见的选择。
11.4.3 EM算法在专家混合模型中的应用
我们可以将EM算法应用到专家混合模型(这里我才对专家混合模型有一些理解,之前我们的混合模型是属于无监督学习的,但是在专家学习中是属于监督学习的例子,我们是要做预测的)当中,在这个模型下,辅助函数具有如下的形式:

其中:

我们可以看到,在E step中,跟标准的混合模型其实是一样的,除了这里我们用![]() 去替换
去替换![]() 。
。
在M step中,我们需要去最大化![]() ,其中的参数包括
,其中的参数包括![]() 。对于回归部分的参数,我们的目标函数可以写为:
。对于回归部分的参数,我们的目标函数可以写为:

对该函数进行MLE计算,我们可以得到:
![]()
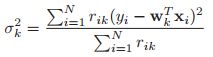
在一般的混合模型的框架中,我们需要估计的是![]() ,但是在专家混合模型中,我们需要进行估计的是
,但是在专家混合模型中,我们需要进行估计的是![]() ,目标函数具有如下的形式:
,目标函数具有如下的形式:
![]()
其中![]() 是根据
是根据![]() 计算出来的。我们可以看到这等价于公式8.34中multinomial logistic回归的对数似然,只不过我们用软的1-of-K编码
计算出来的。我们可以看到这等价于公式8.34中multinomial logistic回归的对数似然,只不过我们用软的1-of-K编码![]() 替换了硬的1-of-C编码
替换了硬的1-of-C编码![]() 。因此,我们可以通过拟合一个软目标估计下的logistic回归模型来估计V。这里我有一些不明白的点需要说明一下,首先对于这个问题,我觉得和式子8.34中的问题是有区别的,对于我们这个问题本身,其实我们就是要算:
。因此,我们可以通过拟合一个软目标估计下的logistic回归模型来估计V。这里我有一些不明白的点需要说明一下,首先对于这个问题,我觉得和式子8.34中的问题是有区别的,对于我们这个问题本身,其实我们就是要算:

这里的求导计算,我觉得是挺难的,不太好计算,书上面说用![]() 替代8.34即
替代8.34即![]() 中的
中的![]() ,但是有一点我想说的是,其实8.34中的
,但是有一点我想说的是,其实8.34中的![]() 对应于我们现在模型中的
对应于我们现在模型中的![]() ,并不是
,并不是![]() ,
,![]() 对应的是先验的信息,
对应的是先验的信息,![]() 其实对应的则是后验的分布,所以在这一点上,直接替换掉的话,我还是有一点点的疑惑。
其实对应的则是后验的分布,所以在这一点上,直接替换掉的话,我还是有一点点的疑惑。
11.4.4 EM算法应用在具有隐变量的DGMs上
基于EM算法在混合专家模型,我们可以将EM算法应用到任何的DGM中计算相应的MLE或者MAP。我们可以用基于梯度的方法,但是利用基于EM的算法会更加的简单。在E step中,我们就是对隐变量进行估计,在M step中,我们则是对complete data进行MLE或者是MAP估计。
为了便于展示,我们假设所有的CPDs都是可以用表格来刻画的(离散情况的)。基于10.4.2,我们知道每一个CPT都可以写成如下的形式:

那么相应的complete data的log似然函数就是:
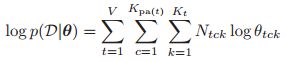
其中V是变量的个数,我们的总的观测数据是N,我们有![]() 时经验的计数在EM的框架中,在E step中就是对complete data(关于隐变量的后验分布)求期望,即:
时经验的计数在EM的框架中,在E step中就是对complete data(关于隐变量的后验分布)求期望,即:
![]()
其中 ,其中
,其中![]() 是第i次观测时观测到的数据。(在这里首先在图模型中不是固定哪一些是隐变量,而是在每一次观测的时候,会有一些数据的丢失,关于上面公式的理解,其实
是第i次观测时观测到的数据。(在这里首先在图模型中不是固定哪一些是隐变量,而是在每一次观测的时候,会有一些数据的丢失,关于上面公式的理解,其实 这一块的左边部分就是那些没有被观测到的变量(至少一个),而这个
这一块的左边部分就是那些没有被观测到的变量(至少一个),而这个![]() 东西,它的期望就是发生这个事情的概率。)
东西,它的期望就是发生这个事情的概率。)
关于![]() 的计算可以利用任意的GM推理算法得到。
的计算可以利用任意的GM推理算法得到。![]() 就是我们期望的充分统计量,也是E step的输出,至此,E step就告一段落了。
就是我们期望的充分统计量,也是E step的输出,至此,E step就告一段落了。
在M step中,我们的结果是:

这个结果可以通过对于期望的完整数据的log似然添加拉格朗日乘数法(即相关的参数和为1),然后去优化相关的参数。在MAP中,我们可能就是要加一个狄里克雷先验,相应的结果就是加入一些伪的计数。
11.4.5 EM算法在学生分布中的应用*
高斯分布的一个问题是它对离群值很敏感,之前我们在2.4.2曾经讨论过这个问题,所以很多时候我们用学生分布,该分布更加的健壮(受到异常值的影响较小)。
不像高斯分布一样,学生t分布关于MLE是没有具体的闭式表达式的,即使在没有丢失数据的情况下,所以我们只能寄希望于迭代的优化算法。那么EM算法是最简单的之一。因为EM算法自动强迫使得![]() 是正数,并且
是正数,并且![]() 是对称正半定的(是因为计算的结果是这样的吧?EM算法本身应该不具有这样的特性吧)。此外,生成的算法具有简单直观的形式,如下所示。
是对称正半定的(是因为计算的结果是这样的吧?EM算法本身应该不具有这样的特性吧)。此外,生成的算法具有简单直观的形式,如下所示。
乍一看,使用EM的原因可能并不明显,因为没有丢失数据。我们的一个关键的想法就是自己引入一个隐变量或者叫做辅助变量来简化算法。
实际上,如果我们进一步的去探索,学生分布其实是无限个高斯分布(不同的方差)的叠加,具体的公式如下:
![]()
关于这一点,我们推导一维比较简单的情况,其实就是习题11.1(然而有个积分我并不会)。

那么我们怎么用EM算法去估计相关的参数呢,在EM模型中,我们把![]() 看多丢失的数据,那么对于完整数据的log似然函数就是:
看多丢失的数据,那么对于完整数据的log似然函数就是:

其中![]() 是之前说过的马氏距离,我们可以把这个似然函数分成两个部分,其中一个部分是只含有
是之前说过的马氏距离,我们可以把这个似然函数分成两个部分,其中一个部分是只含有![]() 的,而另一个则是只含有
的,而另一个则是只含有![]() ,我们将无关的常数项都扔掉了,这并不会影响估计。所以关于完整数据的log似然可以分解成如下的形式。
,我们将无关的常数项都扔掉了,这并不会影响估计。所以关于完整数据的log似然可以分解成如下的形式。

但是最终我们是要对该函数进行隐变量的后验期望计算的。
11.4.5.1 在![]() 已知的时候
已知的时候
首先我们先来推导![]() 已知情况下的结果。在这种情况下,
已知情况下的结果。在这种情况下,![]() 这一项我们就可以忽略不去考虑,所以我们可以看到在
这一项我们就可以忽略不去考虑,所以我们可以看到在![]() 中,只有右边的一项
中,只有右边的一项 包含zi,所以其实我们只要计算在上一轮迭代参数下的
包含zi,所以其实我们只要计算在上一轮迭代参数下的![]() 。
。
我们利用![]() 可以看出这个关于
可以看出这个关于![]() 的分布还是具有Ga分布的形式,这一点,我们前面关于一维的情况的推导可以看出来,所以其实我们有:
的分布还是具有Ga分布的形式,这一点,我们前面关于一维的情况的推导可以看出来,所以其实我们有:
![]()
而我们有又知道,对于Gamma分布![]() ,我们有
,我们有![]() ,所以在E step中,我们有
,所以在E step中,我们有

所以在M step中,求导很容易就可以得到:
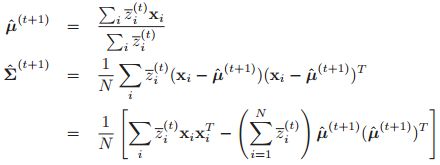
这些结果非常直观:![]() 是测量i的精度,如果量
是测量i的精度,如果量![]() 很小,那么在估计均值和协方差时,相应的数据点会被向下加权。这就是学生为什么对异常值有有较好的rubust。
很小,那么在估计均值和协方差时,相应的数据点会被向下加权。这就是学生为什么对异常值有有较好的rubust。
11.4.5.2 在![]() 未知的时候
未知的时候
在这样的情况下,同样我们是需要去计算![]() 关于
关于![]() 后验分布的期望,这个包括了
后验分布的期望,这个包括了![]() ,比上面要复杂很多。有人证明了如果
,比上面要复杂很多。有人证明了如果![]() ,那么它的log的期望就是
,那么它的log的期望就是![]() ,其中
,其中![]() 称作双伽玛函数。因此根据书中的公式11.69,我们就有(其实就是把具体的参数带进去):
称作双伽玛函数。因此根据书中的公式11.69,我们就有(其实就是把具体的参数带进去):
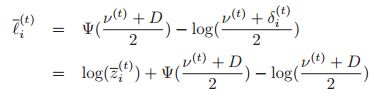
再把这个带入到公式11.68中,结合前面的计算结果,我们可以得到:
![]()
对于该式子求梯度,可以得到:
![]()
这个在![]() 上只有唯一的解。
上只有唯一的解。
在M step,有时我们其实并不需要计算出具体的闭式表达式,我们可以利用基于梯度的优化方法进行求解,这就是我们所知道的广义的EM算法(Generalized EM algorithm)。即使在M step参数的提升只有一点点,但是算法依然会收敛到局部的最优解。
11.4.5.3 混合的学生分布
混合的学生分布,我觉得就是在加入控制是哪一个学生分布的隐变量,也就是说针对这个公式
![]()
右边的部分要进一步展开成![]() 以及
以及![]() ,对所有的隐变量求期望,由于这一块是独立的,所以计算其实都是分开算(两种隐变量同样如此)。具体的思路我觉得就是这个。
,对所有的隐变量求期望,由于这一块是独立的,所以计算其实都是分开算(两种隐变量同样如此)。具体的思路我觉得就是这个。
书后面举了一个关于银行的一个具体的例子,结果就是混合高斯的效果没有混合学生分布的好,至于为什么,还是那句话,异常点太多了,高斯的就不稳健了。
11.4.6 EM算法应用在probit regression*(我感觉这里书上写的有问题,这里的推导我没有做)
在9.4.2,我们提出了一个叫做probit regression的模型,这个模型与logistic regression其实是差不多的,只不过这里用的是高斯的分布的cdf而不是logistic函数。我们用隐变量对该模型进行了解释,其中在dRUM模型下,我们有![]() ,其中
,其中![]() 是隐变量(这里联系到前面关于probit regression隐变量模型的解释,我们知道两个高斯分布作差还是高斯分布,但是为什么它把方差写成了1,因为这里其实方差取任何的值只是一个尺度的问题,相应的w也会相应的尺度变化,所以把方差写成任何数对模型本身是没有任何影响的,所以这里就写成了1)。下面我们就讲如何将EM算法应用到该模型当中去。(虽然在之前我们已经讲了如何用基于梯度的方法来做,但是EM算法本身具有一些优越性,它可以泛化到一些其它的模型当中去。)
是隐变量(这里联系到前面关于probit regression隐变量模型的解释,我们知道两个高斯分布作差还是高斯分布,但是为什么它把方差写成了1,因为这里其实方差取任何的值只是一个尺度的问题,相应的w也会相应的尺度变化,所以把方差写成任何数对模型本身是没有任何影响的,所以这里就写成了1)。下面我们就讲如何将EM算法应用到该模型当中去。(虽然在之前我们已经讲了如何用基于梯度的方法来做,但是EM算法本身具有一些优越性,它可以泛化到一些其它的模型当中去。)
书中在这块关于EM算法的理解,我个人觉得很奇怪,下面我是根据我自己的理解来写的,如有错误希望指出:
首先在这里EM算法中,complete data应该是{y,x,z},然后要去估计的变量即w,这里我们的w的先验是假设为![]() 。所以我们的完整data的似然函数应该是:p(y,x,z|w) =
。所以我们的完整data的似然函数应该是:p(y,x,z|w) = ![]() =
=![]() +const。
+const。
那么在E step,我们有:
![]() (这个地方应该是正比于吧,要不然都不是一个真正的概率密度函数)
(这个地方应该是正比于吧,要不然都不是一个真正的概率密度函数)
那么关于似然函数我们需要求关于![]() 的期望,这里的具体计算我先放一放,后面有空我再来认真思考,这里的思路就是对于
的期望,这里的具体计算我先放一放,后面有空我再来认真思考,这里的思路就是对于![]() 求积分,书上只是对zi求期望了,但是我从式子上看出,不仅要对zi求期望,还需要对zi*zj求期望,对于zi求期望的具体的结果是:
求积分,书上只是对zi求期望了,但是我从式子上看出,不仅要对zi求期望,还需要对zi*zj求期望,对于zi求期望的具体的结果是:

期望求完之后会有一个结果(只与w有关,其余都是已知的量),这样就进入了M step,由于我们这里关于参数w是有先验信息的,所以结果要加上![]() ,这样进行MAP估计得到w^(t+1),由于这里我的思路和书上的完全不同,所以结果应该是不一样的,这里没有算出来。这样整个EM过程就结束了。
,这样进行MAP估计得到w^(t+1),由于这里我的思路和书上的完全不同,所以结果应该是不一样的,这里没有算出来。这样整个EM过程就结束了。
如下图所示:
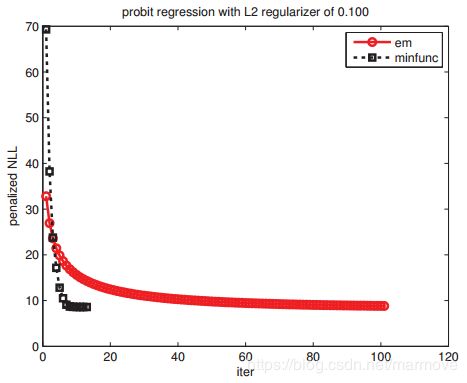
EM算法要比基于梯度的算法慢很多。因为在EM算法中对于信息的挖掘不够充分,在E step中,我们只是知道![]() 是正的或者是负的。加一个正则项可能会提高收敛的速度,当然还会有一些其他的方法提高收敛的速度。
是正的或者是负的。加一个正则项可能会提高收敛的速度,当然还会有一些其他的方法提高收敛的速度。
11.4.7 EM算法的理论基础*
在这一节中,我们表明了EM算法会单调的增加观测的数据的log似然函数,直到收敛到一个局部的最大值(也可能是鞍点)。我们的推导也将作为EM的各种一般化算法的基础,我们将在后面讨论。
11.4.7.1 期望完整数据的log似然是一个下界
我们考虑我们的隐变量的分布是![]() ,那么观测到的数据的log似然函数就是:
,那么观测到的数据的log似然函数就是:

因为log函数是凹的,利用jensen不等式,我们有如下的下界:

我们将这个下界记作如下的形式:
![]()
其中![]() 是
是![]() 的熵。
的熵。
我们上面的推导对于任何的![]() 都是成立了,那么为什么在EM算法中我们令
都是成立了,那么为什么在EM算法中我们令![]()
![]() ,下面就告诉你原因。对于每一个数据i,我们有:
,下面就告诉你原因。对于每一个数据i,我们有:
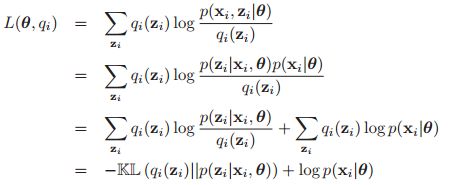
我们可以看到这个式子,最大值就是![]() ,而直觉上我们要找一个下界,肯定是希望这个下界越大越好,说明这个下界更紧。基于这样的原则,我们只有KL距离为0,所以
,而直觉上我们要找一个下界,肯定是希望这个下界越大越好,说明这个下界更紧。基于这样的原则,我们只有KL距离为0,所以![]()
![]() 。当然其实这里我们的
。当然其实这里我们的![]() 是未知的,所以说我们只能用上一个时刻M step估计除了的参数作为替代,所以
是未知的,所以说我们只能用上一个时刻M step估计除了的参数作为替代,所以![]() 。
。
把这个放到下界的公式里,我们就可以得到:
![]()
我们可以看到式子的左边这一项其实就死期望完整数据的log似然函数,而右边这一项其实与参数![]() 是没有任何的关系的,所以说在M step中,我们其实就是要计算:
是没有任何的关系的,所以说在M step中,我们其实就是要计算:
![]()
那么我们之前说了这么多其实就是解释了我们为什么EM算法要这么干,下面我们要说的一点是我们这个下界在每一迭代计算完,还是一个非常紧的下确界。由于在E step中选择了![]() ,所KL距离是0,那么我们就有
,所KL距离是0,那么我们就有![]() (这一步肯定是没有问题的),因此我们有:
(这一步肯定是没有问题的),因此我们有:
![]()
所以我们可以看到,我们这个下界其实是非常的紧的。

我们根据上面这个图可以看出,整个的跟新过程是这样的:
首先最外围的是似然函数,比较的复杂,我们先取一个初始点![]() ,在这一点做一个似然函数的下界,就是
,在这一点做一个似然函数的下界,就是![]() (这个下界在
(这个下界在![]() 这个点与
这个点与![]() 重合的),然后更新
重合的),然后更新![]() ,然后再在
,然后再在![]() 这个点上做似然函数的下界,重复操作,最后收敛到一个local最优点。
这个点上做似然函数的下界,重复操作,最后收敛到一个local最优点。
11.4.7.2 EM算法是单调的增加观测的数据的log似然的
经过我们上面的推导,这个结果其实已经比较明显了,我们有:
![]()
其中最左边的不等式是由于![]() 是
是![]() 的下界。第二个不等式是因为
的下界。第二个不等式是因为![]() ,最后一个等式之前也已经说过,所以整个过程显示一定是逐渐的增加的。
,最后一个等式之前也已经说过,所以整个过程显示一定是逐渐的增加的。
11.4.8 在线的EM算法
当我们处理的数据量很大的时候,或者是一些数据流的时候,能够进行在线学习的话就变得很重要,之前我们在8.5中已经讨论过了。目前主要的在线EM算法有两个。第一个就是incremental EM,这个方法就是优化![]() ,这个需要比较大的存储空间,因为每一次的期望充分统计量都要存储。还有一个方法叫做stepwise EM,这个只需要常数的空间就行,具体还是看后面的详细介绍(前面这一块我们根本不太懂,有点瞎写了。)
,这个需要比较大的存储空间,因为每一次的期望充分统计量都要存储。还有一个方法叫做stepwise EM,这个只需要常数的空间就行,具体还是看后面的详细介绍(前面这一块我们根本不太懂,有点瞎写了。)
11.4.8.1 批量EM的回顾
在解释在线的EM的时候,我们先在一个比较抽象的背景下去解释批量EM算法。对于一个单独的数据情况,令![]() 是充分统计量的向量。(例如对于一个multinoullis分布,那么我们的充分统计量就是就是两块,一个就是对于
是充分统计量的向量。(例如对于一个multinoullis分布,那么我们的充分统计量就是就是两块,一个就是对于![]() 中,每一个类别的数目,记作
中,每一个类别的数目,记作![]() ,还有一个就是隐变量的状态是j,观测到的x的值是v的数目,记作
,还有一个就是隐变量的状态是j,观测到的x的值是v的数目,记作![]() )。我们令
)。我们令![]() ,我们称之为第i个数据块的期望充分统计量(expected sufficient statistics, ESS),并且有
,我们称之为第i个数据块的期望充分统计量(expected sufficient statistics, ESS),并且有![]() 。根据
。根据![]() ,那么我们就可以在M step中进行ML或者MAP对参数进行估计。具体的伪代码如下:
,那么我们就可以在M step中进行ML或者MAP对参数进行估计。具体的伪代码如下:

11.4.8.2 Incremental EM
在incremental EM算法中,我们并不是对整体的数据进行处理,而是同时改变![]() 以及
以及![]() 进行更新。具体的伪代码如下:
进行更新。具体的伪代码如下:

这个可以看做最大化下界![]() (这里的Q其实就是相当于
(这里的Q其实就是相当于![]() ),通过先优化
),通过先优化![]() ,然后优化
,然后优化![]() ,然后去优化
,然后去优化![]() ,然后优化
,然后优化![]() (每一次去优化都是基于其它的
(每一次去优化都是基于其它的![]() 不变,某个
不变,某个![]() 发生了更新了,每一次更新进来一个新的
发生了更新了,每一次更新进来一个新的![]() ,就会把旧的那个给删掉),如此反复的去优化,直到收敛。可以用如下的图形象的表示:
,就会把旧的那个给删掉),如此反复的去优化,直到收敛。可以用如下的图形象的表示:

11.4.8.3 stepwise EM
关于stepwise EM算法的伪代码如下:

stepweise的方法相比于Incremental的其实就是它每一次都是比较依赖于新的数据,当然这个依赖性是体现在![]() ,之前讲过一个 Robbins-Monro的一个条件来保证随机梯度下降算法的收敛,在这里我们同样有这样的约束,所以一般情况下,我们设定:
,之前讲过一个 Robbins-Monro的一个条件来保证随机梯度下降算法的收敛,在这里我们同样有这样的约束,所以一般情况下,我们设定:![]() ,其中
,其中![]() 。
。
一些学者做了相关的仿真实验,实验表明stepwise的EM是最快的,然后是incremental的,最后是EM的。stepwise的算法的性能优势会比batch的要好,当然大部分情况下性能相当,incremental的性能最差。当然这只是在他们的实验背景下得出的结论,不过往往在很多场景下都是这样的。
11.4.9 其它的一些EM变形*
EM算法是机器学习领域和统计领域最常用的算法之一,所以这个算法是有很多的变形的,下面我们简单的提几个,可能在之后的一些章节中,我们还会使用到。
Annealed EM
关于这个算法,它的目的其实就是提高EM算法收敛到全局最优解而不是局部最优解的概率,具体可以详细看书上提供的资料。
variational EM
之前我们讲过在EM算法的E step中,我们就是要计算隐变量的后验期望,这样的log似然的近似是紧的,但是实际上我们可能并没有办法进行这样的理论的计算,所以我们就需要用变分的方法对隐变量的后验分布进行近似,使得在计算上是可行的。
Monte Carlo EM
同样是上面的问题,这个算法是使用一些采样的方法去做,这里我先不去了解了,后面学完之后可能才会有一些见解。
Generalized EM
就是在M step中,有时我们不需要去最大化它,只是简单的利用梯度让它的log似然变大一点点就好。
ECM(E) algorithm
这个算法其实就是说在M step中迭代的去进行优化参数,而不是一次性的全部去优化,比如在学生分布的EM算法中进行如下两步的操作:
![]()
![]()
Over-relaxed EM
在这个算法下,我们M step进行的操作是这样![]() ,
,![]() 就是我们通常在M step进行更新的结果。对于较大的
就是我们通常在M step进行更新的结果。对于较大的![]() 会提高收敛的速度,但是太大之后就可能会崩掉。
会提高收敛的速度,但是太大之后就可能会崩掉。![]() 的话就和我们一般的EM算法的M step是一样的。
的话就和我们一般的EM算法的M step是一样的。
最后其实EM算法是一个更大的算法叫做bound optimization或者是MM(minorize-maximize)算法的一个特殊的情况。
11.5 对于隐变量模型的模型选择
在之前的描述中,我们都是假设LVMs中隐变量的数目是知道的,这很重要,因为隐变量的数目控制着模型的复杂度。在混合模型中同时如此,那么怎么选择隐变量的数目呢?下面我们就来讨论一下这个问题。
11.5.1 概率模型的模型选择
在贝叶斯的框架下,我们对模型进行选择一般是计算如下的式子:![]() ,即边缘似然的最大值,这是假设我们没有先验信息情况下,即
,即边缘似然的最大值,这是假设我们没有先验信息情况下,即![]() 。
。
但是关于这个的计算存在两个问题。第一个问题是,计算LVMs的边缘似然是非常困难的,所以实际上我们是有一些简单的方法去近似的,比如说5.3.2.4中就提到了一个叫做贝叶斯信息准则的方法(BIC)。另外,我们也可以使用交叉验证的方法去做,当然这个方法会比较慢。
第二个问题是需要搜索大量潜在的模型。通常的方法是对K的所有候选值进行穷举搜索,然而,有时我们可以将模型设置为其最大尺寸,然后依靠贝叶斯Occam剃刀的能力来消除不需要的一些可能性。后面21.6.1.6将会举一个相关的例子。
另外还有一些基于采样的方法,后面会讲到一些,这里由于还没有理解,就不多叙述了。但是基于采样的方法会比其它的方法要更加的快,基于采样的方法能够更快的判断出一个K是否是性能很差的。
11.5.2 非概率模型的模型选择
那么如果我们使用的是非概率模型呢?比如我们如何对K-means算法进行模型K的选择,由于这并不是概率模型,没有似然函数,所以基于概率模型的方法就不能用。
那么我们一个比较容易想到的方法就是找一个误差函数来替代似然函数,我们定义如下的reconstruction 函数:
![]()
在K-means模型中![]() 以及
以及![]()
![]() ,下图的左边展示了误差函数随着K变化的曲线:
,下图的左边展示了误差函数随着K变化的曲线:

我们注意到误差随模型复杂度的增加而减小,这一点其实也好理解,如果K=N的话,误差就不存在了。但是如果我们使用概率模型的话,例如GMM,即上图的右边,那么我们看到NLL是呈现一个U的状态。
在监督学习中,我们总是可以使用交叉验证在不同复杂性的非概率模型之间进行选择,但在非监督学习中并非如此。虽然这不是一个新颖的观察,但它可能没有得到应有的广泛赞赏(指对概率模型)。事实上,这是支持概率模型的更有说服力的论据之一。
那么交叉验证不起作用,并且假设某人不愿意使用概率模型(出于某种奇怪的原因…),那么如何选择K呢?最常见的方法是绘制训练集上的重建误差与K的关系图,并试图识别曲线上的膝关节或扭结。就是说假设![]() 是真实的类别的数目,当
是真实的类别的数目,当![]() ,曲线下降的速度可能是比较快的,但是呢,随着
,曲线下降的速度可能是比较快的,但是呢,随着![]() 或者更大一点,可能下降的速度会突然有变小。
或者更大一点,可能下降的速度会突然有变小。
这种扭结过程可以通过使用间隙统计量来实现自动化,然而,识别这种扭结可能是困难的,如上图(a)所示,因为损失函数通常是逐渐下降的。在12.3.2.1节中描述了一种不同的扭结发现方法。
11.6 缺失数据(missing data)情况下的模型拟合
理论上在进行参数的估计的时候,我们就是进行最大似然估计就好了(或者MAP),但是在有些情况下,我们的数据会出现问题,我们的数据是有洞的,有一些数据并不能被观测到,或者说观测出来的结果是NaN。我们进行如下的正式定义,如果说在第i个数据中的第j个分量被观测到了,那么我们有![]() ,所以我们的数据就可以分成两块,一块就是观测到的正常数据
,所以我们的数据就可以分成两块,一块就是观测到的正常数据![]() ,另一个呢就是全是NaN的数据
,另一个呢就是全是NaN的数据![]() ,那么我们的目标其实就是:
,那么我们的目标其实就是:![]()
那么在有缺失数据的情况下,我们有:

其中就是第i行,列的话就是取决于![]() ,因此我们的log似然函数具有如下的形式:
,因此我们的log似然函数具有如下的形式:
![]()
其中 (这个是重点),其中我们有
(这个是重点),其中我们有![]() 就是那些没有观测到的量,所以我们就有:
就是那些没有观测到的量,所以我们就有:

不幸的是,这个式子其实是很难计算的,因为log不能放到sum里面去,但是我们可以用EM算法计算其局部最小值。
11.6.1 MVN中有缺失数据的MLE(EM算法计算)
假设我们想要计算一个有缺失数的MVN的MLE,那么我们可以用EM算法计算得到其局部最优解,下面我们将详细叙述。
11.6.1.1 开始
为了开始整个算法(初始化),首先我们先对完整观测的数据进行MLE估计,如果没有一个数据是完整的,那么我们就使用一些特别的方法进行插入一些值,然后进行MLE估计,初始化参数。
11.6.1.2 E step
我们有了参数![]() ,那么在E step中,我们就是要计算期望完整数据的似然函数:
,那么在E step中,我们就是要计算期望完整数据的似然函数:

其中![]()
为了表示的简单,丢掉了![]() ,我们看到,我们最终就是要去计算
,我们看到,我们最终就是要去计算![]() 。
。
为了计算这个,我们使用4.3.1的公式结果,其实就是条件概率分布,这个具体看4.3.1就会懂了,我们这里左边就是丢失的,右边就是观测到的,具体的结果如下:

所以期望的充分统计量就是:![]() ,不失一般性,我们假设没有观测的在观测到的前面。
,不失一般性,我们假设没有观测的在观测到的前面。
那么计算![]() ,我们使用
,我们使用![]() ,所以结果就是:
,所以结果就是:

11.6.1.3 M step
在M step,我们计算![]() ,我们把上面的计算结果带入到Q中,然后MLE结果其实就是:
,我们把上面的计算结果带入到Q中,然后MLE结果其实就是:

因此,我们看到EM并不等于简单地用变量的期望替换变量,并应用标准的MLE公式,那样的后验方差其实是有问题的,将会导致错误的估计。相反,我们必须计算充分统计量的期望,并将其代入通常的MLE方程。该方法应用到MAP估计也是非常简单的。
11.6.1.4 例子
11.6.1.5 拓展到GMM框架中
那也就是多了混合模型权重相关参数,但是由于这一块是独立的,所以其实没什么影响,其实很多时候missing data和混合模型其实都是很容易融合在一起的,因为相关的很多计算是独立的,并没有耦合在一起。