3、并发模型
概述
在实际的并发系统中,根据不同的业务场景一般使用不同的并发处理手段,这些不同的手段我们就称之为并发模型。不同的并发模型采用不同的方式拆分任务,同时这些并发线程间的交互方式也大不相同。本篇我们就介绍常见的几种并发模型:
并发模型
本篇我们主要分以下三个模块展开:
- 并发模型和分布式系统的相似点:
- 常见的三种并发模型
- 哪种并发模型最好
1、并发模型和分布式系统的关系
我们知道在分布式系统中,各个系统之间通过各种方式交互来实现业务目标。其中每个系统我们可以看做是一个单独的进程,那么分布式系统也就可以理解为是 多进程交互。回到我们的并发模型。在并发模型中,一般通过 多线程交互 的方式来达成某种目标。而线程和进程本身就具有很大的相似性,这也是为什么绝大多数并发模型和分布式系统类似的原因。
其次从目的上来说,分布式系统通过 分布 的方式将复杂业务拆开到不同机器上,避免单台机器处理所有类型请求的压力。而并发模型也可以理解为将大任务拆分为小任务,分配到不同的线程中执行,避免单线程压力过大以至阻塞,导致无法正常服务。
最后从缺陷来说,因为分布式系统将应用部署在不同机器,因此很容易面临处理网络失效、远程主机或进程宕掉等额外挑战。而在大型并发模型中,某块CPU、网卡,磁盘的失效也有可能带来同样的影响。
经过上面的介绍,我们会发现并发模型和分布式系统是非常相似的。因此我们在设计并发模型过程中可以借鉴分布式系统的思想,分布式系统也可以从并发模型中获得启发,减少不必要的麻烦。
2、常见的三种并发模型
常见的并发模型有以下三种:
- 并行工作模型
- 流水线模型
- 函数式并行模型
2-1、并行工作模型
并行工作模型的核心思想是:将所有任务分配到不同的线程中,每个线程执行子任务的所有内容。
举个简单的例子:修车厂每天需要修理很多车辆,该工厂将需要修理的车辆按数量分配给所有的工人,每个工人负责从头到尾修理他所分配的车辆。
在这个例子中要修理的车辆即所有任务,工人就类似线程,每个工人从头到尾负责它所分配的车辆就是说每个线程完成分配给它的子任务。
下来我们通过简单代码来模拟该情况:
public class ThreadModel {
static class Car {
private String name;
public Car(String name) {
this.name = name;
}
}
static class currentWoker implements Runnable {
Car car = null;
public currentWoker(Car car) {
this.car = car;
}
@Override
public void run() {
String name = Thread.currentThread().getName();
System.out.println("工人:" + name + "----修理了车辆" + car.name);
}
}
public static void main(String[] args) {
List<Car> carList = new ArrayList<>();
for (int i = 0; i < 10; i++) {
carList.add(new Car("汽车" + i));
}
for (int i = 0; i < 10; i++) {
new Thread(new currentWoker(carList.get(i))).start();
}
}
}
运行结果:

上述代码中没有用到线程池,无法复用线程,因此假设每个工人只会分到一辆车辆。关于线程池的介绍可以 点击这里 查看我之前的博客。
简单来说,并行工作模型就是将相同类型的任务交互给不同的线程来做,这种处理思想有点类似集群:单台机器处理压力过大,将不同请求分配到不同机器的相同应用中来处理。
并行工作模型的优点:容易理解
- 容易理解:该方式简单来说就像企业招人:100件事一个人干太慢了,招100个人每人分配一件来干就快很多。
并行工作模型的缺陷:共享状态复杂,工作次序不确定
-
共享状态复杂:当所有线程需要访问某一块内存资源时,需要保证每个线程的处理对其他线程可见,并且线程间还需要保证不出现 死锁 等线程并发性问题。
就拿上述修车这个案例来说,工人在修车过程中是互不影响的。假设修车完毕后需要上报到总修车数。工人甲看到公司今天总修车数量为5,自己修了3辆车,按理说应该更新总修车数为8。但在工人甲看到的同时,工人乙正在进行上报。此时工人甲看到的总修车数量是不包括工人乙上报内容的,那么等甲上报后就会出现问题了,系统丢失了部分工人乙上报的数据。
在真正开发环境中,共享数据常常集中在业务数据,系统缓存、数据库连接池等模块。
在处理这部分共享数据时,一般需要通过 锁 的方式来确保同时只有一条线程操作该数据。这种方式会导致其他线程处于等待状态,影响线程之间的并发性。同时这种处理方式意味着,每条线程在操作共享数据的时候,都需要同步最新的数据。如果共享数据在数据库中,每次从数据库同步数据是非常影响效率的。
-
工作次序不确定:并行工作模式下,所有的线程抢占CPU资源,并不会按照线程启动的顺序执行,更多时候是一种随机的方式,也就是说线程运行的次序是不确定的。关于这点我们可以看上述代码的运行结果,很明显不是按照线程启动顺序执行的,并且每次运行结果都不相同
2-2、流水线模型
流水线模式的核心思想是:每个线程专注于自己的任务,在它完成任务后交接给下一个线程。线程之间 互不 共享工作状态。
这里依然用修车厂来举例:修车厂有A、B、C,D四个员工,每个员工处理不同的车辆问题。当车辆有问题时,首先A员工处理自己负责的模块,处理完成后B接着处理,依此类推。
在上述例子中:修车这件事就类似大任务,A、B、C,D员工类比四条线程,每种线程有自己负责的任务小模块,并且线程之间顺序执行。
下面我们通过简单代码来模拟流水线模型:
public class ThreadModel2 {
static class A implements Runnable {
CountDownLatch start;
CountDownLatch end;
public A(CountDownLatch start, CountDownLatch end) {
this.start = start;
this.end = end;
}
@Override
public void run() {
try {
start.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第一步修理车门");
end.countDown();
}
}
static class B implements Runnable {
CountDownLatch start;
CountDownLatch end;
public B(CountDownLatch start, CountDownLatch end) {
this.start = start;
this.end = end;
}
@Override
public void run() {
try {
start.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第二步修理车窗");
end.countDown();
}
}
static class C implements Runnable {
CountDownLatch start;
CountDownLatch end;
public C(CountDownLatch start, CountDownLatch end) {
this.start = start;
this.end = end;
}
@Override
public void run() {
try {
start.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第三步修理轮胎");
end.countDown();
}
}
static class D implements Runnable {
CountDownLatch start;
CountDownLatch end;
public D(CountDownLatch start, CountDownLatch end) {
this.start = start;
this.end = end;
}
@Override
public void run() {
try {
start.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第四步修理油门");
end.countDown();
}
}
public static void main(String[] args) {
CountDownLatch sign1 = new CountDownLatch(1);
CountDownLatch sign2 = new CountDownLatch(1);
CountDownLatch sign3 = new CountDownLatch(1);
CountDownLatch sign4 = new CountDownLatch(1);
CountDownLatch sign5 = new CountDownLatch(1);
new Thread(new A(sign1, sign2)).start();
new Thread(new B(sign2, sign3)).start();
new Thread(new C(sign3, sign4)).start();
new Thread(new D(sign4, sign5)).start();
sign1.countDown();
try {
sign5.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("运行结束");
}
}
运行结果:
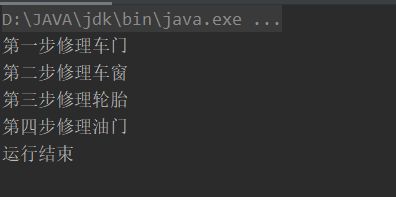
通过运行结果我们可以看出,四个并发线程按顺序依次执行。
在上述代码中,我是通过 CountDownLatch 类实现线程的次序执行,然而在实际编码过程中,也可以通过 回调函数 或是 监听事件 的方式来确保流水线的顺序性。
在实际的应用场景中,并不是只有一条流水线,而是很多组流水线同时进行,也就是说同时有很多线程在同步执行,并且各个流水线之间存在 交叉执行 的可能性。
流水线模型的优点:线程无须共享状态,更好的处理性能,工作次序可控制
-
线程无须共享状态:在流水线模型中,线程之间不会访问相同的内存,因此也不用考虑共享数据问题,也不用每次在操作内存时都进行同步操作。
-
更好的处理性能:因为不存在线程安全性问题,因此在实现业务逻辑是可以选择更高效的数据结构和算法,提高硬件效率。同时因为不存在线程安全性问题,省去了加解锁等操作,提高软件效率。
-
工作次序可控制:在流水线模型中,只有前一个任务完成后才会执行下一个任务,任务之间是有序的,这种业务场景更符合当下很多业务需求。
流水线模型的缺点:开发困难,排查问题困难
-
开发困难:在流水线模型中,线程之间往往处理不同的业务,这也就导致整个业务被拆分并分别实现在不同的JAVA类当中,这种方式无疑会增加开发者的难度。
-
排查问题困难:流水线模式需要首先确定出现问题的模块,然后锁定对应业务类再做排查。而并行模型一般业务处理逻辑都在一起,只需要按照代码顺序向下排查即可。
在并行模式中,为了确保任务的次序执行,有时候会用到 回调函数。当代码中嵌入过多的回调函数时,排查问题是非常困难的:我们无法确定每次回调过程都做了哪些操作,以及无法保证每次回调的数据是否正确。
2-3、函数式并行模型
函数式并发模型的核心思想是:使用函数调用实现程序。
在了解函数式并行模型之前,我们首先了解以下什么叫 函数式编程。
在 JAVA 语言中最常强调的思想就是 面向对象,即世间万物都可以抽象为对象。而函数式编程不是这样的,函数式编程是将万物都抽象为事件和关系。即 A 事物因为某种关系变为 B事物 。我们把这个过程抽象为 ** 函数式**。
函数式并行可以抽象的理解为:函数之间通过发送消息互相调用。如果这些函数可以独立的运行,那就意味着它们可以分散到不同的CPU上执行,也就是说在多处理器上并行的执行函数。
函数式并行模型的优点:线程安全
- 线程安全:函数都是通过拷贝来传递参数的,所以除了接收函数外没有其他实体可以操作数据。
函数式并行模型的缺点:实现困难,场景单一,效率不高
-
实现困难:一般情况下,我们很难确定可以并行的函数调用,也就是说我们很难确定两个函数是否可以在两个不同CPU上并行执行。
-
场景单一:将任务拆分给多个CPU进行函数调用所产生的开销,仅仅在当前任务是程序唯一调用时才有意义。如果当前系统还再并行执行其他任务,那么将单个任务进行拆分是没有意义的。
-
效率不高:跨 CPU 调用函数本身也有很大的开销,如果某个函数调用本身所能产生的效益小于这部分开销,那么还不如使用单线程模型。
3、哪种并发模型最好?
我认为没有最好的并发模型的,只有当前场景下最 合适 的并发模型。选择何种并发模型和你的业务场景息息相关。
- 如果业务比较简单,并且业务量比较大,那么考虑并行工作模型
- 如果业务本身就是独立的,业务之间不存在线程安全问题,那么考虑并行工作模型
- 如果业务本身特别复杂,想要拆分业务并发执行,那么考虑流水线模型
- 如果业务本身有次序,需要按照一定顺序执行,那么考虑流水线模型
- 如果业务经常修改,并行功能模型和流水线模型都可以实现,不过我比较偏向流水线模型,因为流水线模型在新加业务或者删除业务时,只需要添加或删除相应的业务类即可,无须修改代码逻辑。