Python库的安装详解
安装非标准Python库
Python标准库中,用于网页数据采集的有urllib库,同样,有很多优秀的开源库,像BeautifulSoup库、Requests库等。
接下来就介绍一些开源库的安装方法。
Python库的安装可以通过下载源代码执行安装,也可以通过包管理器pip来安装。
这里主要介绍通过pip包管理器的安装方法。
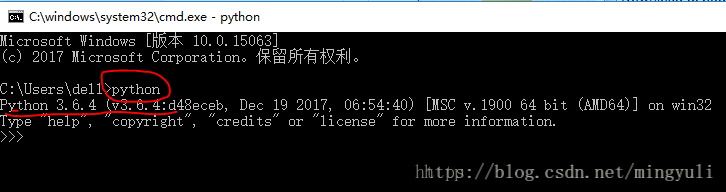
第一步、下面检查python是否安装成功,打开命令行窗口(或者快捷键:Windows 徽标键+R),后输入python进行查询,如显示下图的信息则表示成功了。
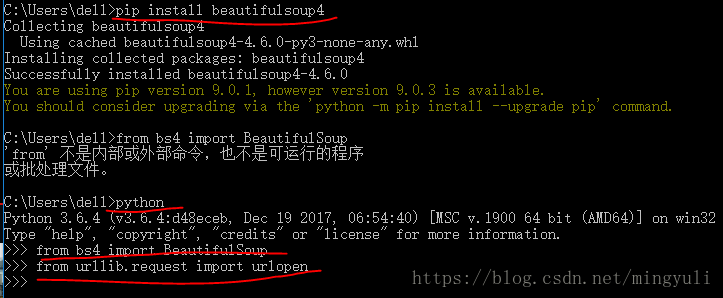
第二步、urllib和BeautifulSoup是否安装成功
urllib和urllib2
python2.x里urllib2库,在python3.x里,urllib2改名为urllib,被分成一些子模块:urllib.request, urllib.parse和urllib.error。尽管函数名称大多数和原来一样,但是在用新的urllib库时需要注意哪些函数被移动到子模块里了。
urllib是python的标准库,包含了从网络请求数据,处理cookie,甚至改变像请求头和用户代理这些元数据的函数。
urlopen用来打开并读取一个从网络获取的远程对象。它可以轻松读取HTML文件、图像文件或其他任何文件流。

1、首先输入python,如下图显示python安装成功。2、在输入pip install beautifulsoup4安装bs4,安装成功后输入from bs4 import BeautifulSoup,如果没有显示任何内容,表示安装成功。3、在输入from urllib.request import urlopen,如果没有显示任何内容,表示安装成功。
注意:以下安装就在window系统中。
第三步、urllib的用法
urllib是python3.x中提供的一系列操作URL的库,他可以轻松模拟用户使用浏览器访问网页
1、使用步骤(1)导入urllib库的request模块from urllib import request
(2)请求URL resp = request.urlopen('http://www.baidu.com')
(3)使用响应对象输出数据 print(resp.read().decode("utf-8"))
又因为浏览器访问服务器时会携带User-Agent信息:使用浏览器的类型,操作系统类型,浏览器版本等,目的是告诉服务器这是一个真正的浏览器,而不是一个爬虫。有一些网站,根据是否携带User-Agent信息判断是否是爬虫,如果检查出将报错。
from urllib import request req = request.Request("http://www.baidu.com") req.add_header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36") resp = request.urlopen(req) print(resp.read().decode("utf-8"))
2、使用post请求:在提交表单数据时。
导入urllib库下面的parse:from urllib import parse
使用urlencode生成post数据:postData = parse.urlencode([(key1,val1),(key2,val2),(keyn,valn)])
使用request.urlopen(req,data=postData.encode('utf-8'))
得到请求状态resp.status
得到服务器的类型:resp.reason
from urllib.request import urlopen from urllib.request import Request from urllib import parse req = Request("http://www.thsrc.com.tw/tw/TimeTable/SearchResult") req.add_header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36") postData = parse.urlencode([ ("StartStation", "2f940836-cedc-41ef-8e28-c2336ac8fe68"), ("EndStation", "977abb69-413a-4ccf-a109-0272c24fd490"), ("SearchDate", "2018/03/27"), ("SearchTime", "22:00"), ("SearchWay", "ArrivalInMandarin")]) resp = urlopen(req, data=postData.encode("utf-8")) print(resp.read().decode("utf-8"))