内存池设计(一)boost内存池
boost内存池
- 0x0 导语
- 0x1 boost::pool
- 0x2 boost::object_pool
- 0x3 boost::singleton_pool
- 0x4 boost::pool_allocator
- 0x5 总结
0x0 导语
最近公司项目中需要用到对象池实现小对象的快速构造和析构,之前项目中使用的是boost::object_pool,但是后面发现boost::object_pool的实现为满足快速连续内存块分配和自动内存回收导致不能很好满足项目效率需求。这是收集对象池相关资料的第一篇,总结boost内存池和对象池。
0x1 boost::pool
关于boost::pool的设计理念和源码分析可以参考博客boost::pool 库速记.
设计理念:
- boost::pool为定长内存池,申请的大块的内存块描述成block,小块内存描述成chunk。
- block逻辑上被划分为3个部分:数据区、指向下个block的指针和下个block长度;
- block通过指针维护成单向block链表,见图1;
- block数据区被划分成next_size个partition_size大小的chunk, 每个chunk的头部存储指向下个chunk的地址,从而形成空闲链表,也就是当chunk空闲时其头部存储下个空闲chunk地址,当分配出去时则完全作为用户数据区,节省了指针的空间,这种设计也造成了一些效率上的问题,见图2。
上面链接的博客boost::pool 库速记对主要的数据结构绘制了非常精美的示意图,链接过来说明下,如果原作者觉得侵权请留言删除。
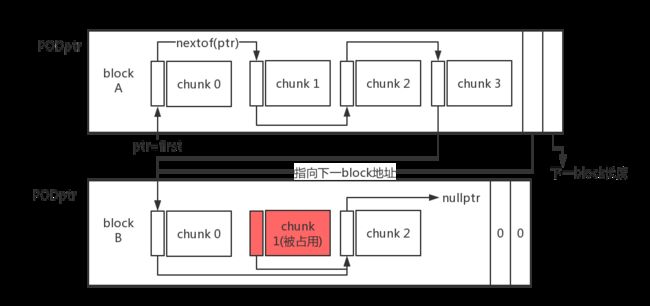
图1 block形成分配内存块单向链表

图2 block数据区内部形成空闲链表
源码部分boost::pool 库速记也进行了详细的解析,下面主要描述我觉得设计上相关的源码部分:
boost::pool在初始化的时候定义了explicit的构造函数,需要传入用户需要的chunk大小nrequested_size、第一次分配block需要的chunk个数nnext_size和后续使用doubling algorithm增长nnext_size时上限nmax_size。实际chunk大小和最小分配空间min_alloc_size、最小对齐空间min_align有关。
// static_lcm是最小公倍数求取器
BOOST_STATIC_CONSTANT(size_type, min_alloc_size =
(::boost::integer::static_lcm::value) );
BOOST_STATIC_CONSTANT(size_type, min_align =
(::boost::integer::static_lcm< ::boost::alignment_of::value, ::boost::alignment_of::value>::value) );
///////////////////////////////////////////////////////////////////
size_type alloc_size() const
{
size_type s = (std::max)(requested_size, min_alloc_size);
size_type rem = s % min_align;
if(rem)
s += min_align - rem;
return s;
}
boost::pool内部保存block链表的头指针details::PODptr
boost::pool比较核心的4个接口为malloc、free、ordered_malloc和ordered_free。
(1)malloc和free: boost::pool是定长内存池,当用户需要申请一个对象空间时调用malloc。malloc首先会检查当前空闲链表中是否有空闲节点,有则将头结点地址分配出去,没有空间节点则调用malloc_need_resize申请新的block, 插入到block链表头,通过将调用simple_segregated_storage::add_block将新block的数据区切分成chunk链表加入到空闲节点链表中, 如图3所示; free则将chunk插入到当前空闲节点链表中, 如图4所示。所以malloc和free函数都是O(1)的复杂度,效率极高,额外的开销是在新申请block的时候需要切分chunk。


///////////////////////////////
void * pool::malloc ()
{
if (!store().empty())
return (store().malloc)();
return malloc_need_resize(); //申请新block并切分chunk
}
///////////////////////////////
void pool::free (void * const chunk)
{
(store().free)(chunk);
}
///////////////////////////////
void * simple_segregated_storage::malloc ()
{
void * const ret = first;
first = nextof(first);
return ret;
}
//////////////////////////////
void simple_segregated_storage::free (void * const chunk)
{
nextof(chunk) = first;
first = chunk;
}
这里有个nextof的函数第一次看的时候没明白过来,以为将void*转成void**后derefrence不还是void*,以为是白费功夫。前面我们说过chunk头部存储下个空闲chunk的首地址,所以传进来的ptr其实是存储地址的空间的首地址,也就是二级指针,所以转成void**后dereference是为了取出存储空间中的地址,也就是下一个chunk的地址,在效果上等价于*(int*)ptr,这里假设地址长度为sizeof(int)。
static void * & nextof(void * const ptr)
{
return *(static_cast(ptr));
}
(2) malloc和free效率极高,我们平时完全可以使用pool::malloc, 在申请的空间上构造对象,替代new MyData(), 那为什么还需要ordered_malloc()、 ordered_malloc(size_type)、 order_free()和 ordered_free(size_type)这些接口呢?原因在于设计内存池的时候考虑到连续分配多个对象空间(比如int* tmp= new int[100])。
连续分配多个对象空间: 这个需求使得内存池能更加通用,后面介绍的boost::pool_allocator和boost::fast_pool_allocator就说明了这个问题。为了实现连续分配多个对象空间的需求,就需要获取空闲节点链表中连续地址节点,假如空闲节点链表各个节点在地址上是有序的,这样就可以快速知道前后节点空间是不是连续且空闲的,所以ordered_malloc在获取空闲节点时会从first检查空闲链表是否能满足需求,不能满足调用pool::ordered_malloc_need_resize申请新的block块,然后按地址大小将新block插入block链表中,新block切分的chunk链表也按序插入freeNode链表中,如图5所示;ordered_free在归还空间时也会将chunk按序插入freeNode链表中,所以ordered_malloc和ordered_free都是O(N)的复杂度。
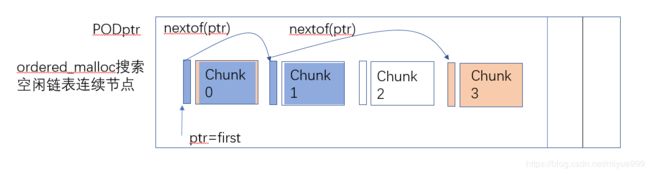
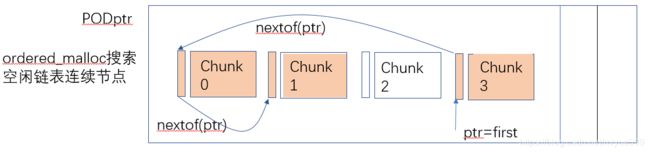
void * pool::ordered_malloc(const size_type n)
{
//获取对齐后的chunk空间大小
const size_type partition_size = alloc_size();
const size_type total_req_size = n * requested_size;
//实际需要分配的chunk个数
const size_type num_chunks = total_req_size / partition_size +
((total_req_size % partition_size) ? true : false);
//检查freeNode节点中是否有连续的n个节点满足需求
void * ret = store().malloc_n(num_chunks, partition_size);
if ((ret != 0) || (n == 0))
return ret;
// freeNode链表没有连续的n个地址相连的节点,则申请新的block
next_size = max (next_size, num_chunks);
size_type POD_size = static_cast(next_size * partition_size +
integer::static_lcm::value + sizeof(size_type));
char * ptr = (UserAllocator::malloc)(POD_size);
if (ptr == 0)
{
if(num_chunks < next_size)
{
// 缩小分配chunk个数重试
next_size >>= 1;
next_size = max BOOST_PREVENT_MACRO_SUBSTITUTION(next_size, num_chunks);
POD_size = static_cast(next_size * partition_size +
integer::static_lcm::value + sizeof(size_type));
ptr = (UserAllocator::malloc)(POD_size);
}
if(ptr == 0)
return 0;
}
const details::PODptr node(ptr, POD_size);
// 这里将需要的num_chunks个chunk块地址划给用户,剩下的按序插入freeNode链表
if (next_size > num_chunks)
store().add_ordered_block(node.begin() + num_chunks * partition_size,
node.element_size() - num_chunks * partition_size, partition_size);
// doubling algorithm,决定下一次分配的chunk个数
if(!max_size)
next_size <<= 1;
else if( next_size*partition_size/requested_size < max_size)
next_size = min BOOST_PREVENT_MACRO_SUBSTITUTION(next_size << 1, max_size*requested_size/ partition_size);
// 将新的block块按序插入block链表
if (!list.valid() || std::greater()(list.begin(), node.begin()))
{
//node直接作为block链表首节点
node.next(list);
list = node;
}
else
{
details::PODptr prev = list;
while (true)
{
// if we're about to hit the end, or if we've found where "node" goes.
if (prev.next_ptr() == 0
|| std::greater()(prev.next_ptr(), node.begin()))
break;
prev = prev.next();
}
//新block插入到prev节点后面
node.next(prev.next());
prev.next(node);
}
// and return it.
return node.begin();
}
///////////////////////////////////////////////////////////////
//malloc_n函数为什么不从first开始分配?
template
void * simple_segregated_storage::malloc_n(const size_type n,
const size_type partition_size)
{
if(n == 0)
return 0;
//这里不检查first!=0和start!=0就取下个块的地址会core? bug?
void * start = &first;
void * iter;
do
{
//分配的第一个块从start的下一个块开始
if (nextof(start) == 0)
return 0;
//分配成功则chunk范围为(start, start+n], 失败则start指向最后一个连续块,下一次 从nextof(start) 开始找
iter = try_malloc_n(start, n, partition_size);
} while (iter == 0);
//start之后的块才是第一块
void * const ret = nextof(start);
//从freeNode链表中删除分配出去的n个连续Node
nextof(start) = nextof(iter);
return ret;
}
//这个函数的确是分配从start之后(不包括start)的n个块,所以应该是(start, {retval}]
template
void * simple_segregated_storage::try_malloc_n(
void * & start, size_type n, const size_type partition_size)
{
//调用函数malloc_n需要保证start和iter都不为0
void * iter = nextof(start); //iter指向第一个分配的块,所以不是从start开始的
while (--n != 0)
{
void * next = nextof(iter);
if (next != static_cast(iter) + partition_size)
{
// next为尾节点或者下个块地址上不连续,则start指向最后一个连续地址块
start = iter;
return 0;
}
iter = next;
}
//存在start后存在的n个连续块,返回连续chunk最后一个chunk的地址
return iter;
}
void simple_segregated_storage::ordered_free(void * const chunks, const size_type n)
{
const size_type partition_size = alloc_size();
const size_type total_req_size = n * requested_size;
const size_type num_chunks = total_req_size / partition_size +
((total_req_size % partition_size) ? true : false);
store().ordered_free_n(chunks, num_chunks, partition_size);
}
////////////////////////////////////////////////////////////
void simple_segregated_storage::ordered_free(void * const chunk)
{
// 找到chunk在freeNode链表中的前一个Node, 需要freeNode链表Node在地址上是有序的
void * const loc = find_prev(chunk);
if (loc == 0)
//直接插入freeNode链表头
(free)(chunk);
else
{
//插入到loc之后
nextof(chunk) = nextof(loc);
nextof(loc) = chunk;
}
}
0x2 boost::object_pool
自动回收对象:内存池实现了内存的快速分配,对于对象池而言则需要额外的对象构造和析构,boost::object_pool继承自boost::pool,为了实现自动对象回收调用了ordered_malloc和ordered_free,ordered_malloc大部分情况下可以以O(1)复杂度从freeNode链表头分配空间,但是ordered_free将chunk插入freeNode链表时总是O(N)复杂度,这意味着如果你使用的对象池频繁得交替进行对象的构造和析构,则有可能整体效率会很低下。
element_type * object_pool::malloc ()
{
//! Amortized O(1).
return static_cast(store().ordered_malloc());
}
void object_pool::free (element_type * const chunk)
{
//! Note that the destructor for p is not called. O(N).
store().ordered_free(chunk);
}
为什么实现自动回收对象要调用ordered_malloc和ordered_free?这个和boost::pool维护空闲节点的freeNode链表设计有关。前面介绍过block被切分成chunk, 空闲chunk头存储着下一个空闲chunk的地址,但是已分配的chunk空间就全部作为用户数据区,这意味着已分配的chunk没有额外的索引,所以为了识别chunk A是不是已被分配出去就要检查chunk A在不在freeNode链表中,如果不在的话需要先调用析构函数。如果freeNode链表是无序的就需要遍历整个链表,为了提高效率就需要freeNode链表是地址有序的,这样在2个不连续空闲Node之间的chunk直接调用析构函数即可,这些是用户调用construct但是忘记调用destroy归还的chunk。
template
object_pool::~object_pool()
{
// 空池直接返回
if (!this->list.valid())
return;
details::PODptr iter = this->list;
details::PODptr next = iter;
// Start 'freed_iter' at beginning of free list
void * freed_iter = this->first;
const size_type partition_size = this->alloc_size();
do
{
// increment next
next = next.next();
for (char * i = iter.begin(); i != iter.end(); i += partition_size)
{
// 该chunk如果在freeNode链表中则说明之前析构过,不做处理,freeNode节点移动到下一个
if (i == freed_iter)
{
freed_iter = nextof(freed_iter);
continue;
}
//该chunk不在freeNode节点中则调用析构函数
static_cast(static_cast(i))->~T();
}
//释放整个block的内存
(UserAllocator::free)(iter.begin());
//移动到下个block
iter = next;
} while (iter.valid());
// Make the block list empty so that the inherited destructor doesn't try to
// free it again.
this->list.invalidate();
}
思考
boost::pool在单个对象空间分配设计上没有太大的问题,为了实现连续多个对象空间内存分配实现ordered_malloc和ordered_free也没有什么问题,但是boost::object_pool基于ordered_malloc和ordered_free实现自动内存析构就有问题。为了识别未分配chunk导致每次destroy都要调用O(N)复杂度的ordered_free,还不如在每个chunk中专门预留一个指针的空间,从而可以维护已分配节点链表和空闲节点链表,牺牲少量空间的前提下可以大幅度提升destroy和自动回收对象性能,甚至可以使用额外的容器(std::set、std::vector等)维护已分配chunk索引,实际上后面几篇内存池设计也的确是这样的,并且效率极高,已被用于生产环境验证过。对象池使用boost::object_pool在性能上和预想的出入很大。
0x3 boost::singleton_pool
单例池使用了singleton设计模式,使用锁实现了线程安全,底层为static boost::pool对象。为了实现boost::singleton_pool在main函数调用之前被初始化一次,将boost::singleton_pool::get_pool()函数放在static 对象create_object的构造函数中。
struct object_creator
{
object_creator()
{ // This constructor does nothing more than ensure that instance()
// is called before main() begins, thus creating the static
// T object before multithreading race issues can come up.
singleton_pool::get_pool();
}
inline void do_nothing() const
{ }
};
static object_creator create_object;
另外一个需要注意的点是boost::singleton_pool的模板参数typename Tag,只是为了编译期产生不同的singleton_pool。
0x4 boost::pool_allocator
pool_alloctor是实现可兼容标准容器的内存分配器,其中定义的boost::pool_allocator在分配连续内存块上有优势,调用的是ordered_malloc和ordered_free,可用于std::vector这类容器; boost::fast_pool_allocator在分配单个内存块上有优势,调用的是malloc和free,可用于std::list这类容器。
boost::pool_alloctor底层使用了boost::singleton_pool分配内存,所以是线程安全的内存分配器,如果只在单线程中使用可以定义BOOST_POOL_NO_MT宏取消同步开销,这个在detail/mutex.hpp中可以看到。
#if !defined(BOOST_HAS_THREADS) || defined(BOOST_NO_MT) || defined(BOOST_POOL_NO_MT)
typedef null_mutex default_mutex;
#else
#if defined (BOOST_NO_CXX11_HDR_MUTEX)
typedef boost::mutex default_mutex;
#else
typedef std::mutex default_mutex;
#endif
可以使用boost::pool_allocator和boost::fast_pool_allocator设计自己的对象池,比如在上层使用指针维护已分配块链表和空闲链表,以便实现自动对象回收。
0x5 总结
(后续补充)