Hadoop学习笔记(四)YARN
YARN产生背景
为什么会产生YRAN?这个与MapReduce1.x的架构有关,正是因为MapReduce1.x存在许多的问题,才会产生 YARN。
MapReduce1.x的架构如下:
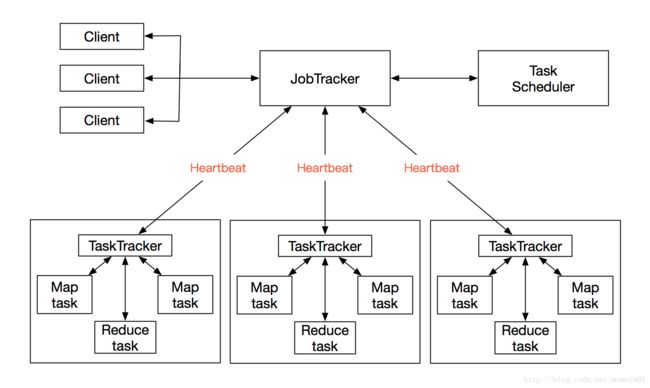
Hadoop1.x时,MapReduce的架构仍然是主从架构。一个JobTracker带多个TaskTracker,主节点为JobTracker,只有一个,从节点为TaskTracker,可以有多个,从节点通过向主节点发送心跳信息(heartbeat)来告诉它自己的运行情况,而主节点则是负责管理调度的工作。
JobTracker(JT):负责资源管理和作业调度。
TaskTracker(TT):定期向JT汇报本节点的健康状况、资源使用情况、作业执行情况。接收来自JT的命令,从而启动任务或杀死任务。
那么这个架构存在什么样的问题呢?
首先是单点故障的问题,所有的从节点(TT)都是跟主节点(JT)直接关联的,如果主节点不小心挂了,那么整个系统就崩溃了,就没有办法运行了。
其次,JT的压力大且不易扩展,他要接收所有从节点(TT)的心跳信息(heartbeat)和客户端的请求,JT承担的职责特别多,随着集群扩展后,那么JT的压力就会越来越大。
最后,最大的问题就是兼容性问题,它不兼容除了MapReduce外的其他框架,比如Spark是不能跑在这个系统上的。
而有了YARN之后,基于YARN之上可以运行很多其他的计算框架,不同计算框架可以共享同一个HDFS集群上数据,享受整体的资源调度。它相当于操作系统,起着调度管理的工作。
YARN概述
关于YARN的概述我们在之前的文章中已经说过了,这里就不多介绍了。
- YARN的全称是Yet Another Resource Negotiatord。
- 通用的资源管理系统,要申请资源统一经过YARN进行申请就行了。
- 为上层应用提供统一的资源管理和调度。
YRAN架构
YARN的架构如下图所示:
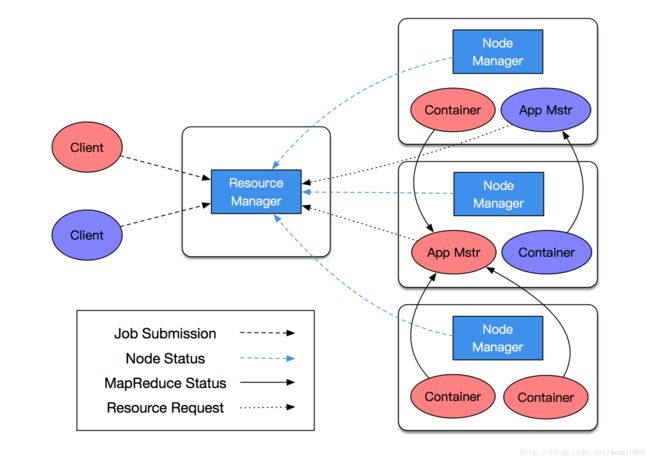
YARN的架构由这几个部分构成:
- ResourceManager(RM):资源管理器
- 整个集群同一时间提供服务的RM只有一个,负责集群资源的统一管理和调度。一般来说RM只有一个,多了的话不好协调容易混乱,但是如果只有一个的话,如果RM出问题了整个系统就崩溃了,所以生产中尽量会再加一个作为备用,这样就算主RM挂了,备用的RM也可以继续工作,但是在同一时间提供服务的只有一个,要么是主RM,要么是备用RM。
- 处理客户端的请求:提交作业、杀死作业。
- 监控NM,一旦某个NM挂了,那么该NM上运行的任务需要告诉AM来如何进行处理。
- NodeManager(NM):节点管理器
- 整个集群中有多个NM,负责自己本身节点资源管理使用。管理自身节点的资源,比如某一时刻还剩多少资源,NM是能知道的。
- 定时向RM汇报本节点的资源使用情况,RM只有知道所有NM上的资源使用情况,才能合理的进行调度。对于一个特定的作业,他才知道该分配到哪个NM上去。
- 接受并处理来自RM的各种命令,比如启动Container。NM既然作为主从结构的从节点,那么就应该听老大的话,老大给你分配了任务,让你去执行你就去执行,让你别干了你就别干了。
- 处理来自AM的命令,AM告诉NM需要在节点上启动多少container跑task,NM才能运行。
- 单个节点的资源管理,在跑作业的过程中,对自己节点上资源的使用和剩余多少资源必须要有数。
- ApplicationMaster(AM):应用程序主控程序
- 每个应用程序对应一个,比如一个Spark或者一个MapReduce作业对应一个AM。负责应用程序的管理,为应用程序向RM申请资源,比如需要多少内存和计算量。拿到资源后再分配给内部的task进行处理。
- 需要与NM进行通信,启动或者停止task,task是运行在container里面,AM也是运行在container里面。
- Container:容器
- 封装了CPU、Memory等资源的一个容器,相当于一个任务运行环境的抽象。
- Client:客户端:
- 提交作业、查看作业的运行进度、杀死作业
关于这个架构我是这么理解的,可以将它与企业或者公司的管理进行对比:
Client,很简单自然就是跟公司合作的客户。提交一个作业就相当于客户跟公司一笔生意谈成了,客户提要求,公司负责帮客户去完成项目,只是这里没有金钱交易而已。
RM,相当于公司的管事的boss,权力很大,所有公司的事都要听他的。我们对照则RM的作用一条一条来理解,首先,一个公司同一时间只能有一个拍板的,不能你说你的他说他的,最后整个公司也不知道听谁的,那就彻底乱套了。如果某天老板生病了,那就只能委托一个代理暂时帮他行使管理的责任,这个代理就是备用的RM。其次,老板可以决定项目何时终止,何时开始,这个很好理解。NM相当于公司下面分设的许多部门,AM相当于某个具体项目的负责人,具体的我们待会再说,暂时先这么理解。最后,老板可以随时知道部门的情况,如果某个部门集体度假了,或者出了什么重大事故,那么自然这个部门所牵涉的项目就要被搁置,这时候对于这个项目该怎么处理,是等他们回来再继续,还是直接把项目给其他的部门,这就要问这个项目的负责人了,怎么决断就要听他的意见,毕竟这个项目是他负责的。
NM所在的整个节点,相当于公司的各个部门,唯一的区别就是,在公司中,往往不会设立两个财务部门或三个人力部门,公司的部门往往是唯一的。而YARN 的结构中,每个节点并不具有唯一性,所以我们为了类比方便,可以假设这个公司有3个开发部门,4个测试部门这样。这样RM就可以理解成这个部门的负责人,显然RM对于本部门的情况是十分了解的,包括哪个人今天有没有来上班,部门现在的工作能力如何,是不是有人还处于空闲没事做的状态等等。负责人需要定期向老板递交工作记录(心跳信息)从而让老板知道这个部门的工作能力如何啊等等这些信息,这样下次有新任务的时候,老板就知道能不能分配给这个部门。作为部门负责人,自然得听老板的话,老板给你个任务,让你立马在部门中给我组个小组(container)完成,你就要执行老板的命令。同时对于项目负责人的要求,他也要尽量可能满足,比如项目负责人说我这个项目需要你们部门哪些哪些人帮我去做,那部门负责人就按照他的要求把那些人组成一个小组去执行任务。
AM,项目负责人或团队,一个公司可能有多个项目,自然每个项目需要有一个项目负责人。项目负责人在做项目的时候必定会用到公司中的资源,比如开会需要会议室、打印机啊,那自然得跟老板去申请说,我这个项目需要利用公司的会议室、打印机等等,老板说可以啊没问题,那么他拿到这些资源后就会给每个小组说,我已经帮你们申请到这些东西了,以后你们要用的话就直接可以用了。最后,他可以跟某个部门的负责人说,我需要你们部门的几个人组成一个小组(container)来帮我做这个项目,或者你们部门的这个小组做的不行,我不要他们了。
container就是一个小组,小组内有大家可以共用的一些资源,每个项目分成一个个小的任务也是在各个小组中完成的,每个小组都属于某个部门,一个部门可以有若干个小组。
不知道这样说会不会对理解YARN的架构有所帮助,这只是我在看到这个架构时的一些理解。
YRAN执行流程
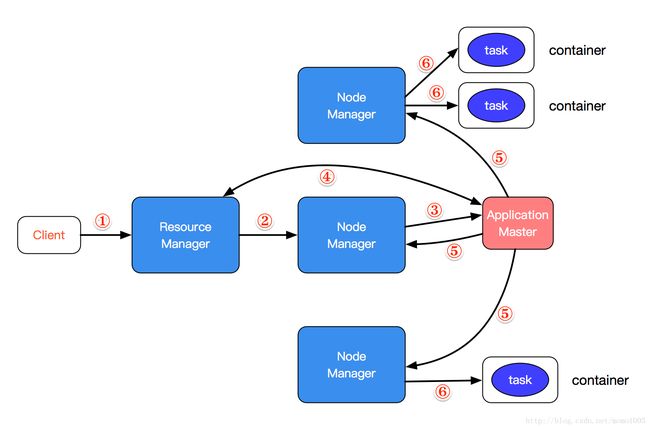
- 客户端提交一个作业请求给RM,可以是MapReduce作业,也可以Spark作业。
- RM会为作业分配第一个container,假设这个container运行在第二个节点上,这样RM就会与对应的NM进行通信,也就是跟第二个节点的NM说,我要在你上面启动一个container。
- NM在接到了RM的指令后,在NM上启动了一个container,而application master就运行在这个container之中。
- AM启动完了之后,会在RM中进行注册,注册了用户就可以通过RM看到作业执行的进度了。并且AM会将需要使用的资源,比如需要多少memory,向RM进行申请,如果申请到资源就美滋滋,接着进行下面的步骤。
- 申请到资源后,AM就在对应的NM上开始启动任务。假设需要在第一个NM启动2个task,在第三个NM上启动1个task,那么把这些通知发送给对应的NM。
- NM在接受到这些通知后,就知道自己需要创建几个task,于是在NM上启动相应的container,并把task放到container中去运行。
其实这个流程并不是很复杂,可以对照着之前举的公司的例子,把相应的角色带入进去理解一下流程。
我们再来思考一个问题,为什么说在1.x版本不能支持其他计算框架的运行,而使用了YARN后就可以了呢?关键在于这个流程是个通用的流程,AM作为应用程序的主控程序,如果我们对于相应的框架都做出对应的AM的实现,也就是说,如果是MapReduce,那么这里的AM就是MapReduce对应的AM,对于spark也是同样的道理。那么在YARN之上就可以运行很多计算框架了。其实可以把YARN的作用理解成可以跑各种计算框架的操作系统,就跟使用Windows操作系统,你就可以在这个操作系统上运行各种软件一样。
更多的信息可以参见hadoop官网上关于YARN架构的文档描述(http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html)。