一、安装与配置
#将Redis的相关运行文件放到/usr/local/bin/下,这样就可以在任意目录下执行Redis的命令
#启动
redis-server /opt/redis/redis.conf
#命令行客户端
redis-cli -h 127.0.0.1 -p 6379
#停止服务,nosave|save参数表示是否关闭前生成持久化文件
redis-cli shutdown nosave|save

在配置文件redis.conf中,默认的bind 接口是127.0.0.1,也就是本地回环地址。
这样的话,访问redis服务只能通过本机的客户端连接,而无法通过远程连接,
这样可以避免将redis服务暴露于危险的网络环境中,防止一些不安全的人随随便便通过远程
连接到redis服务。如果bind选项为空的话,那会接受所有来自于可用网络接口的连接。
#bind
#bind 127.0.0.1
#protected-mode
protected-mode no
处理异常
Just disable protected mode sending the command 'CONFIG SET protected-mode no' from the loopback interface by connecting to Redis from the same host the server is running, however MAKE SURE Redis is not publicly accessible from internet if you do so. Use CONFIG REWRITE to make this change permanent. 2) Alternatively you can just disable the protected mode by editing the Redis configuration file, and setting the protected mode option to 'no', and then restarting the server.
3) If you started the server manually just for testing, restart it with the '--protected-mode no' option.
4) Setup a bind address or an authentication password. NOTE: You only need to do one of the above things in order for the server to start accepting connections from the outside.
二、理解redis
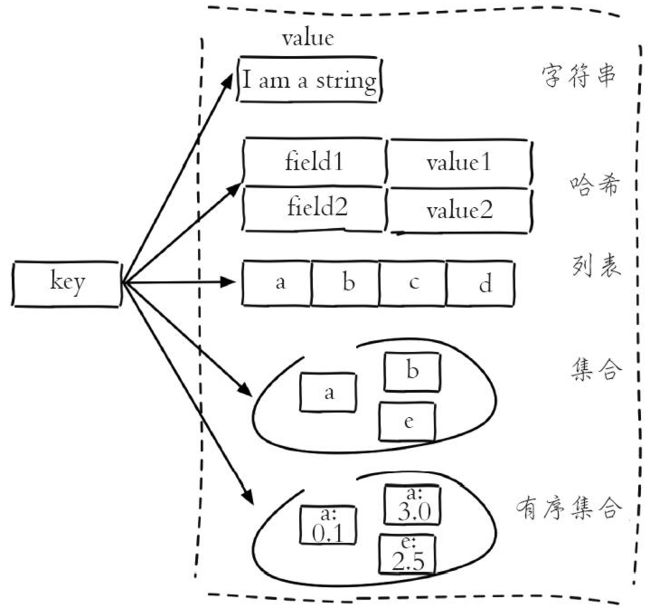
1、redis数据结构
redis数据结构有:string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集合)。
每种数据结构内部都有多种实现编码,这样好处是:
不同使用场景下redis可以采用不同内部实现编码,达到节省内存和提高性能的目的;
另外,对外的数据结构屏蔽了内部编码的不同实现,引入新的内部实现编码不影响开发人员的使用。

redis3.2关于list的内部编码增加了quicklist
127.0.0.1:6379> object encoding mylist
"quicklist"
2、redis架构:内存-单线程-I/O多路复用
reids性能之道:
第一,纯内存访问
第二,非阻塞I/O
第三,单线程避免了线程切换和竞态产生的消耗
注意:如果某个命令执行过长,会造成其他命令的阻塞,对于Redis这种高性能的服务来说是致命的,所以Redis是面向快速执行场景的数据库。
另外,为了性能(对key做hash)和节省空间,redis的key设计尽量简短。
I/O多路复用详解:

blocking I/O:如果当前文件不可读或不可写,整个服务处于阻塞状态,不会对其它的操作作出响应。

I/O 多路复用模型中,最重要的函数调用就是 select,该方法的能够同时监控多个文件描述符的可读可写情况,当其中的某些文件描述符可读或者可写时,select 方法就会返回可读以及可写的文件描述符个数。

Reactor 设计模式是事件驱动的,I/O 多路复用模块同时监听多个文件描述FD,当 accept、read、write 、close 文件事件产生时,文件事件处理器就会回调文件描述FD绑定的事件处理器handler。
Reactor设计模式实现了代码的解耦、模块化、提供复用性、控制并发粒度等,在性能上减少每个client创建线程查询select返回,提高性能。

三、数据结构和内部编码
1、字符串String

(1)、set:
ex seconds:为键设置秒级过期时间。
px milliseconds:为键设置毫秒级过期时间。
nx:键必须不存在,才可以设置成功,用于添加。 使用场景有分布式锁。
xx:与nx相反,键必须存在,才可以设置成功,用于更新。
setex和setnx两个命令等同于ex、nx选项
127.0.0.1:6379> set test1 100 ex 300
"ok"
127.0.0.1:6379> set test1 200 nx
"nil"
mset、mget用于批量操作。
(2)、incr key:
incr命令用于对值做自增操作,返回结果分为三种情况:
•值不是整数,返回错误。
•值是整数,返回自增后的结果。
•键不存在,按照值为0自增,返回结果为1。
可用于分布式全局ID,如时间戳+redis自增ID。
redis单线程架构,完全避免使用CAS、同步解决并发问题。
Long id = jedis.incr(key);
if (id > max) {
jedis.set(key, "0");
}
return System.currentTimeMillis() + String.format("%0" + length + "d", id);
其他计数命令
decr key
incrby key increment
decrby key decrement
incrbyfloat key increment
(3)、getset key value命令:设置并返回原值
getset和set一样会设置值,但是不同的是,它同时会返回键原来的值。
(4)、内部编码
•int:8个字节的长整型。
•embstr:小于等于39个字节的字符串。
•raw:大于39个字节的字符串。
(5)
字符串最大大小为512M。
2、哈希hash

set user:1:name tom
set user:1:age 23
set user:1:city beijing
set user:1 serialize(userInfo)
hmset user:1 name tom age 23 city beijing
一般使用哈希存储对象,比使用多个key(占用过多的键,内存占用量较大,同时用户信息内聚性比较差)或者存储对象序列化后字符串要更好(序列化和反序列化有一定的开销,同时每次更新属性都需要把全部数据取出进行反序列化,更新后再序列化到Redis中)
注意:
在使用hgetall时,如果哈希元素个数比较多,会存在阻塞Redis的可能。如果开发人员只需要获取部分field,可以使用hmget,如果一定要获取全部field-value,可以使用hscan命令,该命令会渐进式遍历哈希类型。
//HSCAN 命令用于迭代哈希键中的键值对。
Map data = new HashMap<>();
for(int i=0;i<1000;i++){
data.put("key"+i,String.valueOf(i));
}
jedis.hmset("hash",data);
ScanResult> result;// = jedis.hscan("hash",DATASOURCE_SELECT);
int count = 0;
int cursor = 0;
do {
result = jedis.hscan("hash",cursor);
cursor = Integer.valueOf(result.getStringCursor());
for (Map.Entry map : result.getResult()) {
System.out.println(map.getKey() + ":" + map.getValue());
count++;
}
}
while(cursor!=0);
Redis为解决诸如keys、hgetall、smembers、zrange可能产生的阻塞问题。对应的命令分别是scan、hscan(哈希)、sscan(集合)、zscan(有序集合),它们的用法基本类似。不过如果在scan的过程中如果有键的变化(增加、删除、修改),那么遍历效果可能会碰到如下问题:新增的键可能没有遍历到,遍历出了重复的键等情况。
3、列表list
(1)、命令
list以对列表两端插入(push)和弹出(pop),还可以获取指定范围的元素列表、获取指定索引下标的元素等。列表是一种比较灵活的数据结构,可以充当栈和队列的角色。



linsert key before|after pivot value
//列出所有
127.0.0.1:6379> lrange listkey 0 -1
1) "java"
2) "b"
3) "a"
lrem key count valuelrem命令会从列表中找到等于value的元素进行删除,
根据count的不同分为三种情况: •count>0,从左到右,删除最多count个元素。
•count<0,从右到左,删除最多count绝对值个元素。
•count=0,删除所有。
下面操作将从列表左边开始删除4个为a的元素:
127.0.0.1:6379> lrem listkey 4 a
(integer) 4
blpop和brpop是lpop和rpop的阻塞版本,如果timeout=3,那么客户端要等到3秒后返回,如果timeout=0,那么客户端一直阻塞等下去:
127.0.0.1:6379> brpop list:test 3
(nil)
(2)、使用场景
•lpush+lpop=Stack(栈)
•lpush+rpop=Queue(队列)
•lpsh+ltrim=Capped Collection(有限集合)
•lpush+brpop=Message Queue(消息队列,生产者客户端使用lrpush从列表左侧插入元素,多个消费者客户端使用brpop命令阻塞式的“抢”列表尾部的元素,多个客户端保证了消费的负载均衡和高可用性。)
(3)、内部编码
ziplist(压缩列表):当列表的元素个数小于list-max-ziplist-entries配置(默认512个),同时列表中每个元素的值都小于list-max-ziplist-value配置时(默认64字节),Redis会选用ziplist来作为列表的内部实现来减少内存的使用。
linkedlist(链表):当列表类型无法满足ziplist的条件时,Redis会使用linkedlist作为列表的内部实现。
quicklist:简单地说它是以一个ziplist为节点的linkedlist,它结合了ziplist和linkedlist两者的优势。
http://zhangtielei.com/posts/blog-redis-quicklist.html

quicklistLZF结构表示一个被压缩过的ziplist
4、集合(set)
(1)、集合(set)类型也是用来保存多个的字符串元素,但和列表类型不一样的是,集合中不允许有重复元素,并且集合中的元素是无序的,不能通过索引下标获取元素。


获取所有元素smembers key
(2)、内部编码
•intset(整数集合):当集合中的元素都是整数且元素个数小于set-max-intset-entries配置(默认512个)时,Re-dis会选用intset来作为集合的内部实现,从而减少内存的使用。
•hashtable(哈希表):当集合类型无法满足intset的条件时,Redis会使用hashtable作为集合的内部实现。
(3)、使用场景
•sadd=Tagging(标签)
•spop/srandmember=Random item(生成随机数,比如抽奖)
•sadd+sinter=Social Graph(社交需求)
5、有序集合zset
(1)、有序集合保留了集合不能有重复成员的特性,但不同的是,有序集合中的元素可以排序。但是它和列表使用索引下标作为排序依据不同的是,它给每个元素设置一个分数(score)作为排序的依据。


返回指定排名范围的成员
127.0.0.1:6379> zrange user:ranking 0 2 withscores
1) "kris"
2) "1"
3) "frank"
4) "200"
5) "tim"
6) "220"
返回指定分数范围成员个数
127.0.0.1:6379> zrevrangebyscore user:ranking 221 200 withscores
1) "tim"
2) "220"
3) "frank"
4) "200"
(2)、内部编码
ziplist(压缩列表):当有序集合的元素个数小于zset-max-ziplist-entries配置(默认128个),同时每个元素的值都小于zset-max-ziplist-value配置(默认64字节)时,Redis会用ziplist来作为有序集合的内部实现,zi-plist可以有效减少内存的使用。
skiplist(跳跃表):当ziplist条件不满足时,有序集合会使用skiplist作为内部实现,因为此时ziplist的读写效率会下降。
(3)、有序集合比较典型的使用场景就是排行榜系统。
6、其他命令
rename key newkey
//为了防止被强行rename,Redis提供了renamenx命令,确保只有newKey不存在时候才被覆盖,renamex返回0表示newkey存在未完成重命名。
keys \* 输出所有key(注意,keys命令会遍历所有key,算法复杂度O(n),生成环境禁止使用)。
dbsize 获取key的总数(算法复杂度O(1))
exists key检查键是否存在,存在返回1否则返回0
•expire key seconds:键在seconds秒后过期。
•expireat key timestamp:键在秒级时间戳timestamp后过期。
•pexpire key milliseconds:键在milliseconds毫秒后过期。
•pexpireat key milliseconds-timestamp键在毫秒级时间戳timestamp后过期。
对于字符串类型键,执行set命令会去掉过期时间,
127.0.0.1:6379> expire hello 50
(integer) 1
127.0.0.1:6379> ttl hello(integer)
46
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> ttl hello(integer)
-1
flushdb/flushall
命令用于清除数据库,两者的区别的是flushdb只清除当前数据库,flushall会清除所有数据库。
dump+restore命令在Redis实例之间迁移数据
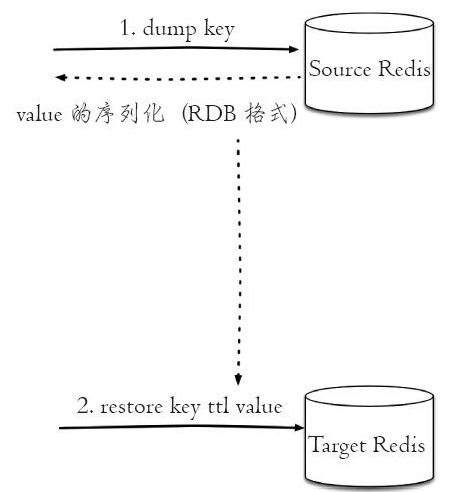
migrate命令在Redis实例之间原子性的迁移数据

HyperLogLog
完成数据统计,占用空间很少,不过有80%左右误差。
127.0.0.1:6379> pfadd 2016_03_06:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-4"
(integer) 1
//uuid-90新增
127.0.0.1:6379> pfadd 2016_03_06:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-90"
(integer) 1
127.0.0.1:6379> pfcount 2016_03_06:unique:ids
(integer) 5
7、redis运维命令
(1)、慢查询
redis提供以下两种命令记录慢查询日志。
config set slowlog-log-slower-than 20000
config set slowlog-max-len 1000
config rewrite
slowlog-log-slower-than为预设阀值,它的单位是微秒(1秒=1000毫秒=1000000微秒),默认值是10000,即10毫秒。(如果slowlog-log-slower-than=0会记录所有的命令,slowlog-log-slower-than<0对于任何命令都不会进行记录。)在高并发情况下,建议设置1毫秒
slowlog-max-len慢查询日志最多条数,以列表方式存储内存。线上建议1000以上,并不会占用过多内存。
慢查询只记录命令执行时间,并不包括命令排队和网络传输时间。

#获取慢查询日志,可选n条
slowlog get [n]
#慢查询条数
slowlog len
#重置慢查询
slowlog rset
CacheCloud提供更强大的redis运维功能:http://www.ywnds.com/?p=10610
(2)、redis-cli --bigkeys统计redis数据大小
[root@localhost ~]# redis-cli --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest zset found so far 'myrank' with 3 members
[00.00%] Biggest set found so far 'user:test' with 2 members
[00.00%] Biggest string found so far 'test' with 5 bytes
[00.00%] Biggest hash found so far 'testmap' with 3 fields
[00.00%] Biggest list found so far 'mylist' with 5 items
[00.00%] Biggest set found so far 'myset' with 3 members
-------- summary -------
Sampled 8 keys in the keyspace!
Total key length in bytes is 61 (avg len 7.62)
Biggest string found 'test' has 5 bytes
Biggest list found 'mylist' has 5 items
Biggest set found 'myset' has 3 members
Biggest hash found 'testmap' has 3 fields
Biggest zset found 'myrank' has 3 members
1 strings with 5 bytes (12.50% of keys, avg size 5.00)
1 lists with 5 items (12.50% of keys, avg size 5.00)
4 sets with 7 members (50.00% of keys, avg size 1.75)
1 hashs with 3 fields (12.50% of keys, avg size 3.00)
1 zsets with 3 members (12.50% of keys, avg size 3.00)
(3)、stat
--stat选项可以实时获取Redis的重要统计信息,虽然info命令中的统计信息更全,但是能实时看到一些增量的数据。
[root@localhost ~]# redis-cli --stat
------- data ------ --------------------- load -------------------- - child -
keys mem clients blocked requests connections
8 901.15K 3 0 282 (+0) 18
8 901.15K 3 0 284 (+2) 18
8 901.15K 3 0 286 (+2) 18
8 901.15K 3 0 288 (+2) 18
8 901.15K 3 0 290 (+2) 18
8 901.15K 3 0 291 (+1) 18
8 901.15K 3 0 292 (+1) 18
(4)、info Commandstats
命令平均耗时使用info Commandstats命令获取,包含每个命令调用次数、总耗时、平均耗时,单位为微秒。
127.0.0.1:6379> info Commandstats
# Commandstats
cmdstat_hmset:calls=1,usec=12,usec_per_call=12.00
cmdstat_hincrby:calls=2,usec=30,usec_per_call=15.00
cmdstat_scan:calls=3,usec=46,usec_per_call=15.33
cmdstat_srem:calls=1,usec=16,usec_per_call=16.00
cmdstat_dbsize:calls=4,usec=3,usec_per_call=0.75
cmdstat_publish:calls=5,usec=15,usec_per_call=3.00
cmdstat_llen:calls=4,usec=9,usec_per_call=2.25
cmdstat_lpush:calls=2,usec=25,usec_per_call=12.50
cmdstat_hlen:calls=3,usec=4,usec_per_call=1.33
cmdstat_scard:calls=12,usec=6,usec_per_call=0.50
cmdstat_command:calls=11,usec=71675,usec_per_call=6515.91
cmdstat_hkeys:calls=2,usec=23,usec_per_call=11.50
cmdstat_subscribe:calls=2,usec=7,usec_per_call=3.50
cmdstat_hdel:calls=2,usec=11,usec_per_call=5.50
四、pipeline

pipeline批量命令节省网络交互时间,相对原生批量命令(mget等)是原子的,Pipeline是非原子的。 原生批量命令是Redis服务端支持实现的,而Pipeline需要服务端和客户端的共同实现。
Lua脚本:
•Lua脚本在Redis中是原子执行的,执行过程中间不会插入其他命令。
•Lua脚本可以帮助开发和运维人员创造出自己定制的命令,并可以将这些命令常驻在Redis内存中,实现复用的效果。
•Lua脚本可以将多条命令一次性打包,有效地减少网络开销。
Pipeline pi = jedis.pipelined();
//多个操作..
pi.sync();
redis集群下pipeline:
如果集群是由客户端做一致性hash(如shardingJedis),使用pipeline前需要对操作按hash算法做分组。
redisCluster目前不支持pipeline,解决方案参考:http://blog.csdn.net/youaremoon/article/details/51751991。
五、事务
127.0.0.1:6379> multi
OK
127.0.0.1:6379> sadd testTran test1
QUEUED
127.0.0.1:6379> sadd testTran test2
QUEUED
127.0.0.1:6379> exec
1) (integer) 1
2) (integer) 1
127.0.0.1:6379> sismember testTran test1//exec执行之前操作返回0
(integer) 1
redis事务并不支持回滚,同时无法实现命令之间的逻辑关系计算。
redis提供watch命令,如果事务执行中key被改的过,则事务不执行(exec结果为nil)。
#T1:客户端1
127.0.0.1:6379> set key "java"
OK
#T2:客户端1
127.0.0.1:6379> watch key
OK
#T3:客户端1
127.0.0.1:6379> multi
OK
#T4:客户端2
127.0.0.1:6379> append key python
(integer) 11
#T5:客户端1
127.0.0.1:6379> append key jedis
QUEUED
#T6:客户端1
127.0.0.1:6379> exec
(nil)
#T7:客户端1
127.0.0.1:6379> get key
"javapython"
六、发布与订阅

#T1
127.0.0.1:6379> publish channel:test "hello"
#T2
127.0.0.1:6379> subscribe channel:test
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "channel:test"
3) "hello"
#T2取消订阅
127.0.0.1:6379> unsubscribe channel:test
#当前channel:sports频道的订阅数为1:
127.0.0.1:6379> pubsub numsub channel:test
1) "channel:test"
2) (integer) 1
按模式匹配订阅
psubscribe pattern [pattern...]
punsubscribe [pattern [pattern ...]]