Python3实现简单的selenium自动化测试
本文参考OSChina的博主‘磁针石’的《使用Python学习selenium测试工具》,该文章中有些代码执行起来有些问题,在这篇文章中已经调通。另外,本文只是简单整理了下python实现selenium的一个简单流程,要了解更多selenium相关可以参考‘磁针石’的那篇文章。
前置环境
- 该环境的配置参见另一篇文章:《eclipse安装pydev》
- 本篇文章涉及的源码:>>本文源码<<
- 《unittest文档》
- 《selenium-python文档》
- chrome driver版本
- chrome driver下载
1. 安装selenium
- 《python selenium环境搭建笔记》
2. 先来一个简单的搜索功能练练手
- Demo 1
# searchtests.py
#!/user/bin/env python
#encoding: utf-8
import unittest
from selenium import webdriver
class SearchTests(unittest.TestCase):
def setUp(self):
#create a new Firefox session
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(30)
self.driver.maximize_window()
# navigate to the application home Page
self.driver.get("http://www.jd.com/")
def test_search_by_category(self):
#keywords
self.search_field = self.driver.find_element_by_id("key")
self.search_field.clear()
self.search_field.send_keys("phones")
#go search
self.search_btn = self.driver.find_element_by_xpath("//button[@clstag='h|keycount|2015|03c']")
self.search_btn.click()
#获取页面所有商品的 标签ַ
products = self.driver.find_elements_by_xpath("//div[@class='p-img']/a")
self.assertGreater(len(products), 3, "more than 3~~")
def test_search_by_name(self):
#输入搜索关键字
self.search_field = self.driver.find_element_by_id("key")
self.search_field.clear()
self.search_field.send_keys("phones")
#go search
self.search_btn = self.driver.find_element_by_xpath("//button[@clstag='h|keycount|2015|03c']")
self.search_btn.click()
products = self.driver.find_elements_by_xpath("//div[@class='p-img']/a")
self.assertGreater(len(products), 4, "more than 4~~")
def tearDown(self):
# close
self.driver.quit()
if __name__ == '__main__':
unittest.main(verbosity=2)
- Demo 2
# searchtests.py
#!/user/bin/env python
#encoding: utf-8
import unittest
from selenium import webdriver
class SearchTests(unittest.TestCase):
@classmethod
def setUpClass(cls):
# 基于类的setUp()和tearDown()方法
# 这里的‘@classmethod’支持在一个类中只进行一次初始化和清理
cls.driver = webdriver.Firefox()
cls.driver.implicitly_wait(30)
cls.driver.maximize_window()
# navigate to the application home page
cls.driver.get("http://www.jd.com/")
def test_search_by_category(self):
# get the search textbox
self.search_field = self.driver.find_element_by_id("key")
self.search_field.clear()
self.search_field.send_keys("phones")
#submit
self.search_btn = self.driver.find_element_by_xpath("//button[@clstag='h|keycount|2015|03c']")
self.search_btn.click()
# get all the anchor elements which have product names displayed
# currently on result page using find_elements_by_xpath method
products = self.driver.find_elements_by_xpath("//div[@class='p-img']/a")
self.assertGreater(len(products), 3, "more than 3~~")
def test_search_by_name(self):
# get the search textbox
self.search_field = self.driver.find_element_by_id("key")
self.search_field.clear()
self.search_field.send_keys("android")
#submit
self.search_btn = self.driver.find_element_by_xpath("//button[@clstag='shangpin|keycount|toplist1|b03']")
self.search_btn.click()
# get all the anchor elements which have product names displayed
# currently on result page using find_elements_by_xpath method
products = self.driver.find_elements_by_xpath("//div[@class='p-img']/a")
self.assertGreater(len(products), 4, "more than 4~~")
@classmethod
def tearDownClass(cls):
# close the browser window
cls.driver.quit()
if __name__ == '__main__':
unittest.main(verbosity=2)
- Demo 1和Demo 2对比,可以发现,Demo 2不需要每次都初始化浏览器
- 另外一点,需要学习find_element_by_xpath的规则以及web的DOM结构
3. 另一个测试用例
# homepagetests.py
#!/user/bin/env python
#encoding: utf-8
import unittest
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.by import By
#from __builtin__ import classmethod
class HomePageTest(unittest.TestCase):
@classmethod
def setUpClass(cls):
# create a new Firefox session """
cls.driver = webdriver.Firefox()
cls.driver.implicitly_wait(30)
cls.driver.maximize_window()
# navigate to the application home page """
cls.driver.get('http://www.jd.com/')
def test_search_field(self):
# check search field exists on Home page
self.assertTrue(self.is_element_present(By.ID, 'key'))
# def test_language_option(self):
# # check language options dropdown on Home page
# self.assertTrue(self.is_element_present(By.ID, 'select-language'))
#
# def test_shopping_cart_empty_message(self):
# # check content of My Shopping Cart block on Home page
# shopping_cart_icon = self.driver.find_element_by_css_selector('div.header-minicart span.icon')
# shopping_cart_icon.click()
#
# shopping_cart_status = self.driver.find_element_by_css_selector('p.empty').text
# self.assertEqual('You have no items in your shopping cart.',
# shopping_cart_status)
#
# close_button = self.driver.find_element_by_css_selector('div.minicart-wrapper a.close')
# close_button.click()
@classmethod
def tearDownClass(cls):
# close the browser window
cls.driver.quit()
def is_element_present(self, how, what):
"""
Utility method to check presence of an element on page
:params how: By locator type
:params what: locator value
"""
try:
self.driver.find_element(by=how, value=what)
except NoSuchElementException:
return False
return True
if __name__ == '__main__':
unittest.main(verbosity=2)
4. 组合测试
# smoketests.py
#!/user/bin/env python
#encoding: utf-8
import unittest
from searchtests import SearchTests
from homepagetests import HomePageTest
# get all tests from SearchProductTest and HomePageTest class
search_tests = unittest.TestLoader().loadTestsFromTestCase(SearchTests)
home_page_tests = unittest.TestLoader().loadTestsFromTestCase(HomePageTest)
# create a test suite combining search_test and home_page_test
smoke_tests = unittest.TestSuite([home_page_tests, search_tests])
# run the suite
unittest.TextTestRunner(verbosity=2).run(smoke_tests)
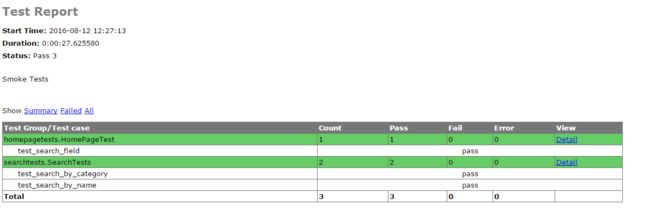
5. 输出测试报告
- 这里需要引入HTMLTestRunner.py文件
- 下载地址:HTMLTestRunner.py
- 这个文件用python2写的,有很多地方会有编译错误,具体怎么修改,>>戳这里<<
- 修改后的HTMLTestRunner.py参考前面给的源码
# smoketests_with_html_report.py
#!/user/bin/env python
#encoding: utf-8
import unittest
import HTMLTestRunner
import os
from searchtests import SearchTests
from homepagetests import HomePageTest
# get the directory path to output report file
result_dir = os.getcwd()
# get all tests from SearchProductTest and HomePageTest class
search_tests = unittest.TestLoader().loadTestsFromTestCase(SearchTests)
home_page_tests = unittest.TestLoader().loadTestsFromTestCase(HomePageTest)
# create a test suite combining search_test and home_page_test
smoke_tests = unittest.TestSuite([home_page_tests, search_tests])
# open the report file
outfile = open(result_dir + '\SmokeTestReport.html', 'w')
# configure HTMLTestRunner options
runner = HTMLTestRunner.HTMLTestRunner(stream=outfile,
title='Test Report',
description='Smoke Tests')
# run the suite using HTMLTestRunner
runner.run(smoke_tests)
- 测试结果