TensorFlow2.1入门学习笔记(10)——使用keras搭建神经网络(Mnist,Fashion)
前面已经使用TensorFlow2的原生代码搭建神经网络,接下来将使用keras搭建神经网络,并改写鸢尾花分类问题的代码,将原本100多行的代码用不到20行代码实现。
用TensorFlow API:tf.keras搭建网络
使用Sequential
六步法:
- import,相关模块
- train, test,指定训练集的输入特征,和训练集的标签
- model = tf.keras.models.Sequential,搭建网络结构,(顺序神经网络)
- model.compile,配置训练方法
- model.fit,执行训练
- model.summary,打印出网络结构和参数统计
model = tf.keras.models.Sequent([网络结构])
描述各层网络:
-
拉直层:tf.keras.layers.Flatten(),将输入特征拉直
-
全连接层:tf.keras.layers.Dense(神经元个数,activation=“激活函数”,kernel_regularizer=哪种正则化)
activation(字符串给出)可选: relu、 softmax、 sigmoid 、 tanh
kernel_regularizer可选: tf.keras.regularizers.l1()、tf.keras.regularizers.l2()
-
卷积层: tf.keras.layers.Conv2D(filters = 卷积核个数, kernel_size = 卷积核尺寸, strides = 卷积步长, padding = " valid" or “same”)
-
LSTM层: tf.keras.layers.LSTM()
model.compile(optimizer = 优化器, loss = 损失函数, metrics = [“准确率”] )
- Optimizer可选:
‘sgd’ or tf.keras.optimizers.SGD (lr=学习率,momentum=动量参数)
‘adagrad’ or tf.keras.optimizers.Adagrad (lr=学习率)
‘adadelta’ or tf.keras.optimizers.Adadelta (lr=学习率)
‘adam’ or tf.keras.optimizers.Adam (lr=学习率, beta_1=0.9, beta_2=0.999) - loss可选:
‘mse’ or tf.keras.losses.MeanSquaredError()
‘sparse_categorical_crossentropy’ or tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False) - Metrics可选:
‘accuracy’ :y_和y都是数值,如y_=[1] y=[1]
‘categorical_accuracy’ :y_和y都是独热码(概率分布),如y_=[0,1,0] y=[0.256,0.695,0.048]
‘sparse_categorical_accuracy’ :y_是数值,y是独热码(概率分布),如y_=[1] y=[0.256,0.695,0.048]
model.fit ()执行训练过程
model.fit (训练集的输入特征, 训练集的标签, batch_size= , epochs= , validation_data=(测试集的输入特征,测试集的标签), validation_split=从训练集划分多少比例给测试集, validation_freq = 多少次epoch测试一次)
model.summary()
打印网络的结构和参数统计
- 例如鸢尾花分类问题

鸢尾花问题使用六步法复现
# 1.import
import tensorflow as tf
from sklearn import datasets
import numpy as np
# train,test
x_train = datasets.load_iris().data
y_train = datasets.load_iris().target
np.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
tf.random.set_seed(116)
# 3.model.Sequential
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(3, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
])
# 4.model.compile
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
# 5.model.fit
model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2, validation_freq=20)
# 6.model.summary
model.summary()
使用class类
六步法:
- import,相关模块
- train, test,指定训练集的输入特征,和训练集的标签
- class MyModel(Model) model=MyModel,(Sequential无法写出带有跳连的非顺序神经网络)
- model.compile,配置训练方法
- model.fit,执行训练
- model.summary,打印出网络结构和参数统计
使用class类封装一个神经网络结构
-
_init_( ) 定义所需网络结构块
-
call( ) 写出前向传播
###############################
class MyModel(Model):
def __init__(self):
super(MyModel, self).__init__()
定义网络结构块
def call(self, x):
调用网络结构块,实现前向传播
return y
model = MyModel()
###############################
class IrisModel(Model):
def __init__(self):
super(IrisModel, self).__init__()
self.d1 = Dense(3)
def call(self, x):
y = self.d1(x)
return y
model = IrisModel()
- 鸢尾花问题使用六步法复现
# 1.import
import tensorflow as tf
from sklearn import datasets
######
from tensorflow.keras.layers import Dense
from tensorflow.keras import Model
######
import numpy as np
# train,test
x_train = datasets.load_iris().data
y_train = datasets.load_iris().target
np.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
tf.random.set_seed(116)
###### 3.class MyModel ######
class IrisModel(Model):
def __init__(self):
super(IrisModel, self).__init__()
self.d1 = Dense(3, activation='sigmoid', kernel_regularizer=tf.keras.regularizers.l2())
def call(self, x):
y = self.d1(x)
return y
model = IrisModel()
# 4.model.compile
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
# 5.model.fit
model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2, validation_freq=20)
# 6.model.summary
model.summary()
打印结果:

MNIST数据集:
介绍
-
Yann LeCun
-
提供 6万张 28*28 像素点的0~9手写数字图片和标签,用于训练。
-
提供 1万张 28*28 像素点的0~9手写数字图片和标签,用于测试。

- 导入MNIST数据集:
mnist = tf.keras.datasets.mnist
(x_train, y_train) , (x_test, y_test) = mnist.load_data()
-
数据处理
作为输入特征,输入神经网络时,将数据拉伸为一维数组:
tf.keras.layers.Flatten( )
[0 0 0 48 238 252 252 …… …… …… 253 186 12 0 0 0 0 0] -
查看数据集
plt.imshow(x_train[0], cmap='gray')#绘制灰度图
plt.show()

print("x_train[0]:\n", x_train[0])

print("y_train[0]:", y_train[0])

# 打印出整个训练集输入特征形状
print("x_train.shape:\n", x_train.shape)
# 打印出整个训练集标签的形状
print("y_train.shape:\n", y_train.shape)
# 打印出整个测试集输入特征的形状
print("x_test.shape:\n", x_test.shape)
# 打印出整个测试集标签的形状
print("y_test.shape:\n", y_test.shape)

使用Sequential实现手写字体识别
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
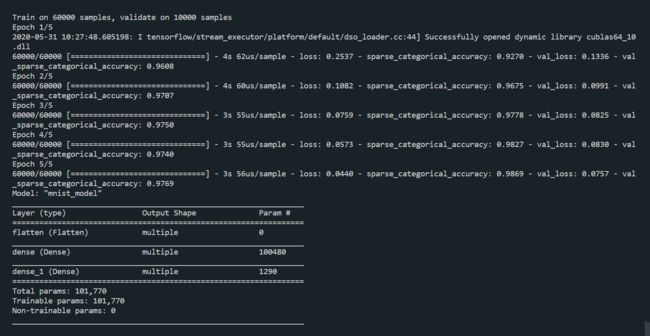
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()

使用class MyModel实现手写字体识别
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras import Model
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class MnistModel(Model):
def __init__(self):
super(MnistModel, self).__init__()
self.flatten = Flatten()
self.d1 = Dense(128, activation='relu')
self.d2 = Dense(10, activation='softmax')
def call(self, x):
x = self.flatten(x)
x = self.d1(x)
y = self.d2(x)
return y
model = MnistModel()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
FASHINO数据集
- 提供 6万张 28*28 像素点的衣裤等图片和标签,用于训练。
- 提供 1万张 28*28 像素点的衣裤等图片和标签,用于测试。

- 导入数据集
fashion = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion.load_data()
使用Sequential实现手写字体识别
import tensorflow as tf
fashion = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion.load_data()
x_train, x_test = x_train/255.0, x_test/255.0
model=tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128,activation="relu"),
tf.keras.layers.Dense(10,activation="softmax")
])
model.compile(optimizer="adam",
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits = False),
metrics = ['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test,y_test), validation_freq=1)
model.summary()

使用class MyModel实现手写字体识别
import tensorflow as tf
from tensorflow.keras.layers import Dense,Flatten
from tensorflow.keras import Model
fashion=tf.keras.datasets.fashion_mnist
(x_train,y_train),(x_test, y_test)=fashion.load_data()
x_train, x_test=x_train/255.0,x_test/255.0
class FashionModel(Model):
def __init__(self):
super(FashionModel, self).__init__()
self.flatten=Flatten()
self.d1=Dense(128,activation="relu")
self.d2=Dense(10,activation="softmax")
def call(self,x):
x=self.flatten(x)
x=self.d1(x)
y=self.d2(x)
return y
model = FashionModel()
model.compile(optimizer="adam",
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=["sparse_categorical_accuracy"])
model.fit(x_train,y_train,batch_size=32,epochs=5,validation_data=(x_test,y_test),validation_freq=1)
model.summary()
