基于hutool和POI的excel导入工具类
excel导入也可以很简单,利用POI进行导入,以及强大的hutool工具类,再加上对业务的理解,就可以封装成一个超级好用的业务类了。
maven依赖
<dependency>
<groupId>cn.hutoolgroupId>
<artifactId>hutool-allartifactId>
<version>4.0.9version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poi-ooxmlartifactId>
<version>3.17version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poi-ooxml-schemasartifactId>
<version>3.17version>
dependency>这个是模板excel,根据模板的坐标来加载数据excel
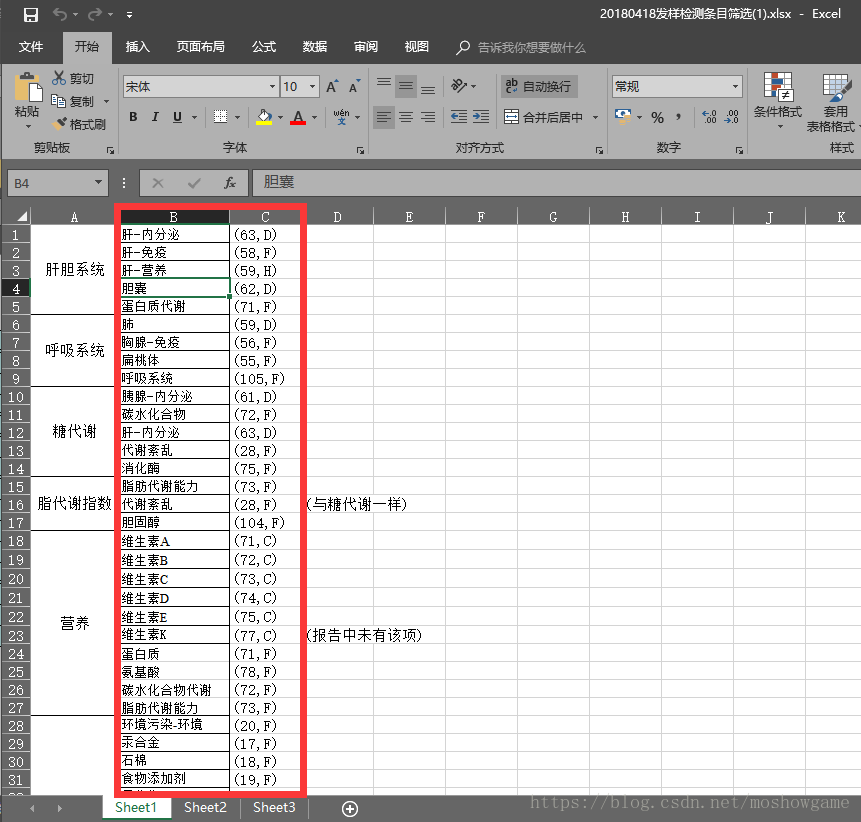
这个是数据excel,理论上是一堆杂乱的看不懂的数据
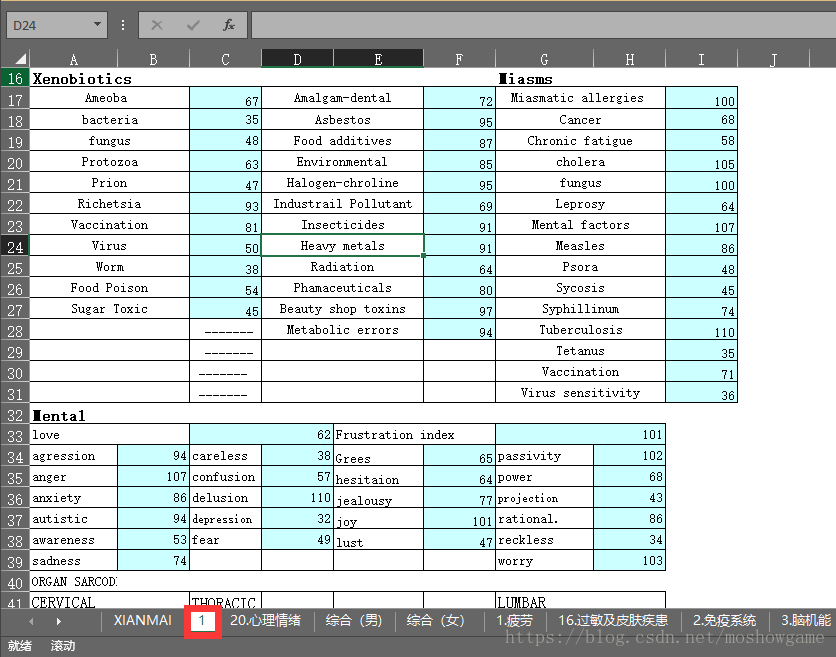
helper类业务封装
package org.microservice.tcbj.yytsg.checksys.util;
import java.util.LinkedHashMap;
import java.util.Map;
import org.apache.commons.lang3.StringUtils;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.CellType;
import com.alibaba.fastjson.JSON;
import cn.hutool.core.io.FileUtil;
import cn.hutool.poi.excel.ExcelReader;
import cn.hutool.poi.excel.ExcelUtil;
/**
* excel业务封装
* @author zhengkai
*/
public class ExcelBizHelper {
public static String abc="#ABCDEFGHIJKLNMOPQRSTUVWXYZ";
public Map readExcel() {
//模板处理 sheetIndex=0代表第一个
ExcelReader readerModel = ExcelUtil.getReader(FileUtil.file("C:\\Users\\Administrator\\Desktop\\体检数据\\20180418发样检测条目筛选.xlsx"),0);
Map excelMapModel=new LinkedHashMap();
addCellToMapPlus(readerModel, excelMapModel, 1, 50, 2);
System.out.println(JSON.toJSONString(excelMapModel));
//数据处理 sheetName页签名称
ExcelReader reader = ExcelUtil.getReader(FileUtil.file("C:\\Users\\Administrator\\Desktop\\体检数据\\匿名.xls"), "1");
Map excelMap=new LinkedHashMap();
//遍历模板excel数据,处理数据excel
for (String modelkey:excelMapModel.keySet()) {
//获取坐标值
String valuePath = excelMapModel.get(modelkey);
if(!StringUtils.isBlank(valuePath)) {
valuePath=valuePath.replace("(","").replace(")", "");
String[] rowcell = valuePath.split(",");
//根据坐标,获取对应的数据excel的值
addCellToMap3(reader, excelMap, modelkey, Integer.valueOf(rowcell[0]) , abc.indexOf(rowcell[1]));
}
}
System.out.println(JSON.toJSONString(excelMap));
return excelMap;
}
/*public static void main(String[] args) {
ExcelBizHelper helper=new ExcelBizHelper();
helper.readExcel();
}*/
/**
* 将excel坐标数据添加到map(key,value)
* 例如数据(1,A)='姓名',(1,B)='XXX'
* 只需调用addCellToMap(row=1,cell=1,。。。)
* cell参数,A=1,B=2,C=3以此类推
* 即可获取map('姓名','XXX')
* @author zhengkai
*/
public void addCellToMap(ExcelReader reader,Map map,int row,int cell) {
map.put(getValue(reader.getSheet().getRow(row-1).getCell(cell-1)), getValue(reader.getSheet().getRow(row-1).getCell(cell)));
}
/**
* 将excel坐标数据添加到map(str+key,value)
* 例如数据(1,A)='姓名',(1,B)='XXX'
* 只需调用addCellToMap(str='用户信息',row=1,cell=1,。。。)
* cell参数,A=1,B=2,C=3以此类推
* 即可获取map('用户信息-姓名','XXX')
* @author zhengkai
*/
public void addCellToMap2(ExcelReader reader,Map map,String str,int row,int cell) {
map.put(str+"-"+getValue(reader.getSheet().getRow(row-1).getCell(cell-1)), getValue(reader.getSheet().getRow(row-1).getCell(cell)));
}
/**
* 循环遍历将excel坐标数据添加到map(key,value)
* 例如数据(1,B)='姓名',(1,C)='XXX'
* 例如数据(2,B)='性别',(2,C)='YYY'
* 只需调用addCellToMapPlus(row_start=1,row_end=2,cell=1,。。。)
* cell参数,A=1,B=2,C=3以此类推
* 即可获取map{('姓名','XXX')+map('性别','YYY')
* @author zhengkai
*/
public void addCellToMapPlus(ExcelReader reader,Map map,int row_start,int row_end,int cell) {
for(int r=row_start;r<=row_end;r++) {
addCellToMap(reader, map, r, cell);
}
}
/**
* 循环遍历将excel坐标数据添加到map(str+key,value)
* 例如数据(1,B)='姓名',(1,C)='XXX'
* 例如数据(2,B)='性别',(2,C)='YYY'
* 只需调用addCellToMapPlus2(row_start=1,row_end=2,cell=1,str='用户信息'。。。)
* cell参数,A=1,B=2,C=3以此类推
* 即可获取map{('用户信息-姓名','XXX')+map('用户信息-性别','YYY')
* @author zhengkai
*/
public void addCellToMap2Plus(ExcelReader reader,String str,Map map,int row_start,int row_end,int cell) {
for(int r=row_start;r<=row_end;r++) {
addCellToMap2(reader, map, str, r, cell);
}
}
/**
* 将excel坐标数据添加到map(str+key,value)
* 例如数据(1,B)='XXX'
* 只需调用addCellToMap3(namestr='姓名',row=1,cell=2,。。。)
* cell参数,A=1,B=2,C=3以此类推
* 即可获取map('姓名','XXX')
* @author zhengkai
*/
public void addCellToMap3(ExcelReader reader,Map map,String namestr,int row,int cell) {
map.put(namestr, getValue(reader.getSheet().getRow(row-1).getCell(cell-1)));
}
/**
* 获取excel的值
* @author zhengkai
*/
public String getValue(Cell c) {
try {
if(CellType.NUMERIC.equals(c.getCellTypeEnum())) {
return c.getNumericCellValue()+"";
}else{
return c.getStringCellValue()+"";
}
} catch (Exception e) {
e.printStackTrace();
}
return "";
}
}
最终效果
原始数据:链接: https://pan.baidu.com/s/1oHx4tIY3jr_cgkiL070Euw 密码: sza3
坐标数据:
{“肝-内分泌”:”(63,D)”,”肝-免疫”:”(58,F)”,”肝-营养”:”(59,H)”,”胆囊”:”(62,D)”,”蛋白质代谢”:”(71,F)”,”肺”:”(59,D)”,”胸腺-免疫”:”(56,F)”,”扁桃体”:”(55,F)”,”呼吸系统”:”(105,F)”,”胰腺-内分泌”:”(61,D)”,”碳水化合物”:”(72,F)”,”代谢紊乱”:”(28,F)”,”消化酶”:”(75,F)”,”脂肪代谢能力”:”(73,F)”,”胆固醇”:”(104,F)”,”维生素A”:”(71,C)”,”维生素B”:”(72,C)”,”维生素C”:”(73,C)”,”维生素D”:”(74,C)”,”维生素E”:”(75,C)”,”维生素K”:”(77,C)”,”蛋白质”:”(71,F)”,”氨基酸”:”(78,F)”,”碳水化合物代谢”:”(72,F)”,”环境污染-环境”:”(20,F)”,”汞合金”:”(17,F)”,”石棉”:”(18,F)”,”食物添加剂”:”(19,F)”,”氯化物”:”(21,F)”,”工业污染”:”(22,F)”,”杀虫剂”:”(23,F)”,”重金属”:”(24,F)”,”放射物-环境”:”(25,F)”,”药物毒素”:”(26,F)”,”美容毒素”:”(27,F)”,”锌(Zn)”:”(113,F)”,”硫(S)”:”(116,F)”,”钠(Na)”:”(117,F)”,”硒 (Se)”:”(119,F)”,”钾 (K)”:”(120,F)”,”磷 ( P)”:”(121,F)”,”镁(Mg)”:”(123,F)”,”锰(Mn)”:”(124,F)”,”铁 (Fe)”:”(126,F)”,”碘(I)”:”(127,F)”,”铬 (Cr)”:”(130,F)”,”钙 (Ca)”:”(133,F)”}- 取值数据:
{“肝-内分泌”:”40.0”,”肝-免疫”:”89.0”,”肝-营养”:”40.0”,”胆囊”:”77.0”,”蛋白质代谢”:”9.0”,”肺”:”40.0”,”胸腺-免疫”:”38.0”,”扁桃体”:”84.0”,”呼吸系统”:”45.0”,”胰腺-内分泌”:”55.0”,”碳水化合物”:”93.0”,”代谢紊乱”:”94.0”,”消化酶”:”18.0”,”脂肪代谢能力”:”87.0”,”胆固醇”:”102.0”,”维生素A”:”122.0”,”维生素B”:”46.0”,”维生素C”:”69.0”,”维生素D”:”104.0”,”维生素E”:”75.0”,”维生素K”:”113.0”,”蛋白质”:”9.0”,”氨基酸”:”57.0”,”碳水化合物代谢”:”93.0”,”环境污染-环境”:”85.0”,”汞合金”:”72.0”,”石棉”:”95.0”,”食物添加剂”:”87.0”,”氯化物”:”95.0”,”工业污染”:”69.0”,”杀虫剂”:”91.0”,”重金属”:”91.0”,”放射物-环境”:”64.0”,”药物毒素”:”80.0”,”美容毒素”:”97.0”,”锌(Zn)”:”48.0”,”硫(S)”:”56.0”,”钠(Na)”:”48.0”,”硒 (Se)”:”64.0”,”钾 (K)”:”104.0”,”磷 ( P)”:”90.0”,”镁(Mg)”:”46.0”,”锰(Mn)”:”48.0”,”铁 (Fe)”:”24.0”,”碘(I)”:”90.0”,”铬 (Cr)”:”48.0”,”钙 (Ca)”:”121.0”}
*。abc那个字母序号获取其实还没怎么完善,excel的序号是从A~Z,AA~ZZ的,等改天有空优化一下这个
*。感谢hutool群的网友反馈,poi-ooxml包已经包含了poi包,不需要引入,已经去除
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poiartifactId>
<version>3.17version>
dependency>