【UI自动化-2】UI自动化元素定位专题
前言
UI自动化的学习,个人认为应该分五步走:环境搭建、元素定位、特殊场景处理、框架设计与搭建、测试平台开发。第一步的环境搭建其实没什么难度,都是固定的套路。今天就来到了第二步的元素定位,可以说元素定位是整个UI自动化的基本功。
我查阅了大量的资料,在动手实践的基础上,整理总结了此文。
常用定位方式
众所周知,Selenium提供了8种定位方式:
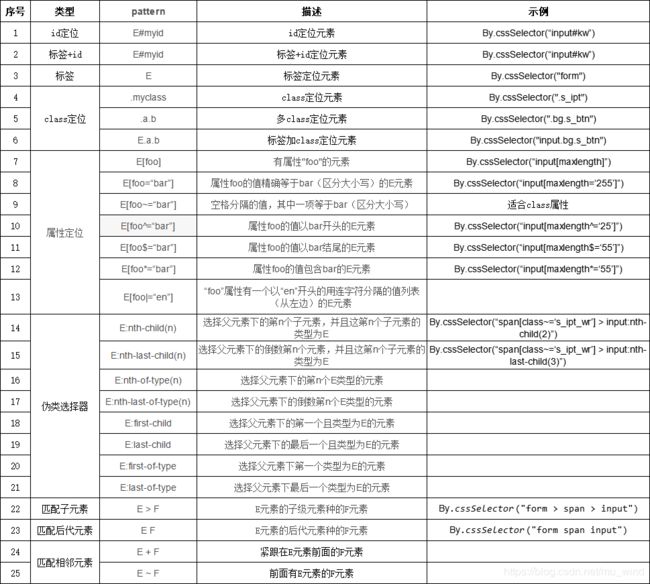
- id:根据id定位,是最常用的定位方式,因为id具有唯一性,定位准确快捷
- name:通过元素的【名称】属性定位,name会存在不唯一的情况
- className:class 属性定义了元素的类名
- tagName:通过标签命定位,一般不建议使用
- linkText:专用于定位超链接元素(即a标签),需要完全匹配超链接的内容
- partialLinkText:同样用于定位超链接元素,但可以模糊匹配超链接的内容
- xpath:根据元素路径进行定位,分为绝对路径和相对路径
- cssSelector:selenium官方推荐的元素定位方式,比xpath效率更高,但需要掌握一些css基础
下面以百度搜索框为例,进行定位方式的实践练习
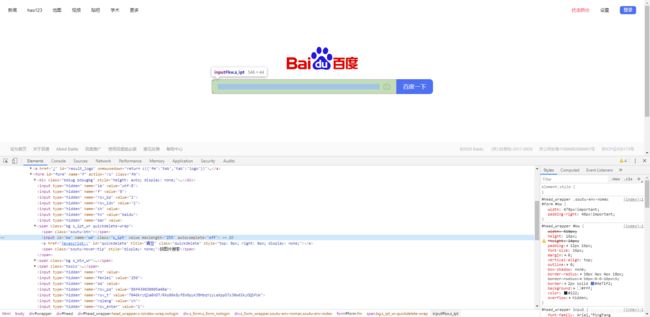
在Java中,selenium封装了获取元素的两个函数,区别在于前者会获得一个元素,后者获取一系列(1个或多个)元素的集合:
// 获取某个元素
WebElement findElement(By var1);
// 获取元素的集合
List<WebElement> findElements(By var1);
1 id定位
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
public class ElementTest {
public static void main(String[] args) {
// 指定浏览器驱动的路径
String driverPath = "E:/source/driver/chromedriver_80_2.exe";
System.setProperty("webdriver.chrome.driver", driverPath);
// 创建一个chrome driver
WebDriver driver = new ChromeDriver();
// 访问百度
driver.get("https://www.baidu.com");
// id定位元素
try {
driver.findElement(By.id("kw")).sendKeys("测试");
Thread.sleep(5000);
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
}
}
2 name定位
根据元素的name标签定位元素,name属性的值是可重复的。
元素定位之外的相同代码省略,下同。
// name定位元素
try {
driver.findElement(By.name("wd")).sendKeys("测试");
Thread.sleep(5000);
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
3 className
很多人可能对前端的class这个概念缺乏了解,这里简单描述一下。class属性一般是对元素进行样式描述,它有两种定义方式:
- 定义在HTML文件的【head】标签的【style】标签内
- 定义在专门的css文件中,用【link】标签对该css文件进行引用
一个元素可以引用多个class,一个class也可以被多个元素引用,见下面示例代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试页面</title>
<link rel="stylesheet" href="../../layui/css/layui.css">
<style>
.colkey {
font-size: 15px;
font-weight: 600;
text-align: left;
width: 75px;
padding: 9px 0 9px 10px;
}
.content {
margin: 0 10px 5px 25px
}
</style>
</head>
<body>
<div class="colkey">测试1</div>
<div class="colkey content">测试2</div>
<div class="content">测试3</div>
</body>
</html>
关于class的知识,感兴趣的可以自己去多了解前端相关内容。使用className去定位元素,其实并不是非常好的一种定位方式,原因是一个className可能被多个元素所拥有,难以保证元素定位的唯一性。
// className定位元素
try {
driver.findElement(By.className("s_ipt")).sendKeys("测试");
Thread.sleep(5000);
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
4 tagName定位
所谓tag就是元素的标签,比如head、form、div等等,通过tagName去定位元素更加难以保证定位的唯一性。
在定位百度搜索框这个案例中,有两种思路,具体见代码:
// tagName定位元素
try {
// 思路1:获取所有input标签的元素,再根据索引获取目标元素
driver.findElements(By.tagName("input")).get(7).sendKeys("测试");
// 思路2:先定位到父级元素,再通过tagName定位目标元素
driver.findElement(By.className("s_ipt_wr")).findElement(By.tagName("input")).sendKeys("测试");
Thread.sleep(5000);
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
5 linkText定位
linkText定位专用于超链接元素,即a标签包裹的元素,例如:
<a href="http://www.w3school.com.cn">W3School</a>
上面就是一个典型a标签元素,href指向目标url,"W3School"是该元素的value,我们可以用该内容定位这个a标签元素。
下面以百度搜索csdn并跳转csdn官网为例,演示linkText定位:
// tagName定位元素
try {
driver.findElement(By.id("kw")).sendKeys("csdn");
driver.findElement(By.id("su")).click();
// 隐式等待页面加载完成
driver.manage().timeouts().implicitlyWait(20, TimeUnit.SECONDS);
// 精确匹配
driver.findElement(By.linkText("CSDN博客")).click();
// 模糊匹配
driver.findElement(By.partialLinkText("IT技术社区")).click();
Thread.sleep(5000);
} catch (Exception e) {
e.printStackTrace();
} finally {
driver.quit();
}
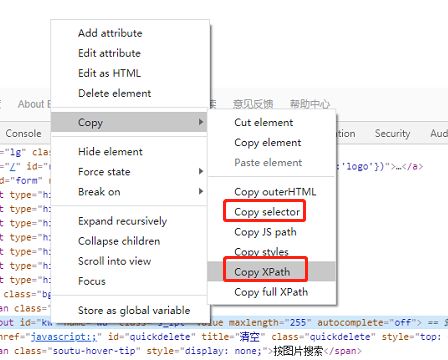
上面的6种定位方式,使用起来很简单,但缺陷在于很多元素用这些方式无法定位,接下来就是两种几乎能定位到所有元素的定位方式:xpath和css selector。这两种方式内容非常多,又比较深奥,如果有人不想努力了,倒是有偷懒方法,在目标元素上右键,Copy selector(获取css selector表达式)和Copy XPaht(获取xpath表达式):
6 xpath定位
所谓xpath,即根据元素的路径进行定位。更多xpath的知识请见:w3school
6.1 路径匹配
xpath定位最常用的就是路径定位了,具体又分为绝对路径和相对路径。
路径匹配有以下几个符号:
- 用
/表示节点路径,如/A/B/C表示节点A的子节点B的子节点C,/表示根节点。 - 用
//表示所有路径以//后指定的子路径结尾的元素,如//D表示所有的D元素;如果是//C/D表示所有父节点为C的D元素。 - 用
*表示路径的通配符,如/A/B/C/*表示A元素下的B元素下的C元素下的所有子元素。
6.1.1 绝对路径
绝对路径也称全路径,是指从根路径出发,逐层定位,例如:
By.xpath("html/body/div/form/span/input")
以上面的百度搜索框为例,绝对路径:
By.xpath("/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input")
绝对路径繁琐冗长,而且极易受前端结构变动影响,所以强烈不推荐使用。
6.1.2 相对路径
即相对于上下文节点的路径,使用双斜杠,例如:
By.xpath("//input//div")
相对路径更加实用,一般我们难以直接定位到一个目标元素时,可以先定位到一个能准确定位到的上级元素,再从此上级元素出发,通过元素之间的层级关系定位到目标元素。
例如,定位百度搜索框(当然百度搜索框本身是能定位到的,这里是为了演示):
By.xpath("//*[@id='form']/span/input")
当一个元素下有多个同类型元素时,仅凭路径匹配就行不通了,又因为对于每一个元素,它的各个子元素都是有序的,所以通过索引就能准确定位到目标元素:
/A/B/C[1]表示A元素下的B元素下的C元素下的第一个子元素。/A/B/C[last()]表示A元素下的B元素下的C元素下最后一个子元素。/A/B/C[position()>2]表示A元素下的B元素下的C元素下的位置号大于2的元素。
例如:
By.xpath("//form[2]")
通过相对路径定位元素,其核心思想在于,当目标元素不能直接定位时,先找到一个能直接定位到的元素,我称之为锚点元素,再通过目标元素与锚点元素之间的位置关系进行定位。
具体又可分为,通过上下级节点(或父子节点)和同级节点(或兄弟节点)两种方式。
示例代码:
<html>
<body>
<div id="parent">
<div id="A"> old brother</div>
<div id="B"> child</div>
<div id="C"> litter brother</div>
</div>
</body>
</html>
以上面代码为例:
1、通过父级节点查找子级节点
By.xpath("//div[@id='parent']/div[2]")
2、通过子级节点查找父级节点
By.xpath("//div[@id='B']/..")
3、通过兄弟节点定位
By.xpath("//div[@id='B']/../div[1]")
另外根据兄弟节点的相对位置关系进行定位,其他的常用表达式:
E/following-sibling::F:获取和E元素同级且位于其后的F元素E/following-sibling::F[n]:获取和E元素同级且位于其后的第n个F元素preceding-sibling::F:获取和E元素同级且位于其前的F元素preceding-sibling::F[n]:获取和E元素同级且位于其前的第n个F元素
下面用一个示例进行演示:
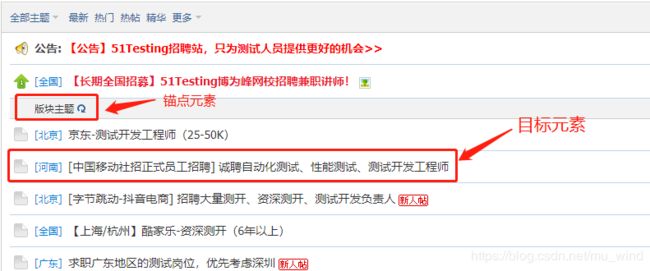
页面代码如下,可以发现目标元素所属的tbody标签只有一个动态id,显然难以直接定位。但在目标元素所在的tbody上面,有一个可以通过id直接定位到的tbody,我称之为锚点元素。锚点元素和目标元素所在tbody在同级,这时候就很适合用兄弟元素的方式去定位。
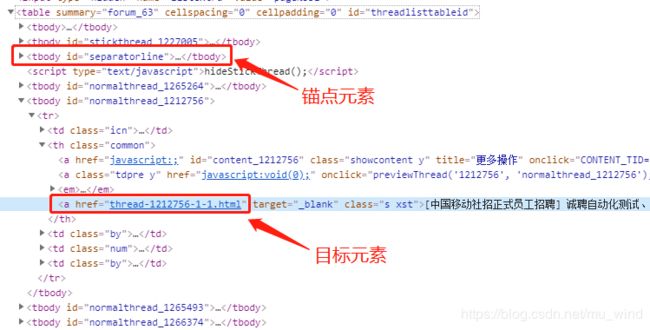
具体代码如下:
By.xpath("//*[@id='separatorline']/following-sibling::tbody[2]/tr/th/a[3]")).click();
6.2 属性匹配
在xpath中可以使用属性和属性的值来定位元素,使用属性定位时要以@开头(下面form仅为示例,也可以为div、input等)
//form[@id]:表示所有具有属性id的form元素。//form[@*]:表示所有具有属性的form元素。//form[not(@*)]:表示所有不具有属性的form元素。//form[@id="myId"]:表示id值为myId的form元素。
另外还有属性模糊匹配方法,功能更加强大:
//form[start-with(@id,'myId')]:表示所有属性id的值以myId开头的form元素。//form[ends-with(@id,'myId')]:表示所有属性id的值以myId结尾的form元素。//input[contains(@id,'myId')]:表示所有属性id的值包含myId的form元素。//a[contains(text(),'贴吧')]:表示超链接元素的文本内容为贴吧的a元素
在实际定位中,常常是上面三种方式结合起来进行定位。
当然,另外还有使用布尔逻辑计算定位,例如:
By.xpath("//div[@id='myId' or @name='myName']")
双条件同时过滤,例如:
By.xpath("//div[@id='myId'][@name='myName'")
7 cssSelector定位
更详细内容请见:W3C
css元素选择器
选择input类型的元素:
By.cssSelector("input")
7.1 css类与id选择器
id选择器以 # 来定义,class类选择器以一个.显示,有以下几种例子:
- 选择
id为myId的元素:By.cssSelector("#myId") - 选择
id为myId的input元素:By.cssSelector("input#myId") - 选择class为a的元素:
By.cssSelector(".a") - 选择class为a、b的元素:
By.cssSelector(".a.b") - 选择class为a的input元素:
By.cssSelector("input.a")
7.2 css属性选择器
- 选择有属性有属性
maxlength的input元素By.cssSelector(“input[maxlength]”) - 属性
maxlength的值精确等于255的input元素(完全相等,区分大小写)By.cssSelector(“input[maxlength=‘255’]”) - 属性
class的值以空格隔开,其中一项等于fm(区分大小写)input元素:By.cssSelector(“input[class~=‘fm’]”) - 属性
class的值以bar开头的div元素By.cssSelector(“div[class^=‘bar’]”) - 属性
class的值以bar结尾的div元素By.cssSelector(“div[class$=‘bar’]”) - 属性
name的值包含myName的form元素By.cssSelector(“form[name*=‘myName’]”) - 属性
class有一个以“soutu”开头的用连字符分隔的值列表(从左边)的span元素:By.cssSelector(“span[class|=‘soutu’]”) - 属性
type等于hidden且属性name等于ch且属性class为bg的input元素By.cssSelector("input[type='hidden'][name='ch'].bg")
7.3 css子元素选择器
何为子元素?以下面代码中的form元素为基准,span元素和a元素是它的子元素,但input元素不是。
代码示例2:
子元素的标志符号是>,下面是几个示例。
form元素的子元素中的span元素:By.cssSelector("form#myForm > span")- 属性
id为form的form元素的子元素span元素的子元素input元素(实现百度搜索框定位):By.cssSelector("form#form > span > input")
7.4 css后代元素定位
后代元素与子元素的区别是,A元素的子元素的子元素,也是A的后代元素。同样以前文代码2中的form元素为基准,span元素、a元素和input元素都是它的后代元素。
后代元素的标志符号是空格,例如同样定位百度搜索框,用后代元素方式:
By.cssSelector("form#form input[name='wd']")
7.5 css相邻兄弟选择器
相邻兄弟选择器(Adjacent sibling selector)可选择紧接在另一元素后的元素,且二者有相同父元素。例如,属性id为myId的form元素的后代div元素的span子元素的相邻的第一个弟弟元素input:
By.cssSelector("form#myId div>span+input")
7.6 css伪类选择器
这种选择器,要求目标元素必须有父级元素,且符合位置匹配条件,具体如下:
- E:nth-child(n)和E:nth-last-child(n):两者的区别是前者正序计数,后者倒序计数。其次,这两个选择器定位的元素要求必须在某个父级标签内,且其父级标签内对应索引n的元素的类型必须为E,否则匹配失败。以百度搜索框代码为例,span:nth-child(7)这样是匹配失败的,因为form元素内第7个子元素是input类型元素,不是span类型。
- E:nth-of-type(n)和E:nth-last-of-type(n):两者也是正序和倒序的区别。E:nth-of-type(n)与E:nth-child(n)的区别在于,前者匹配第n个E元素,后者匹配到第n个元素并判断是否是E元素,不是则匹配失败。
几个示例如下:
- 属性
class为s_ipt_wr的span元素的第2个子元素,且其类型为input的元素(位置和类型不对应则匹配失败):By.cssSelector(“span[class~=‘s_ipt_wr’] > input:nth-child(2)”) - 属性
class为s_ipt_wr的span元素的倒数第3个子元素,且其类型为input的元素(位置和类型不对应则匹配失败)By.cssSelector(“span[class~=‘s_ipt_wr’] > input:nth-last-child(3)”) - 属性
class为s_ipt_wr的span元素的第2个input元素(该input元素在所有子元素排第几无所谓):By.cssSelector(“span[class~=‘s_ipt_wr’] > input:nth-of-type(2)”) - 属性
class为s_ipt_wr的span元素的倒数第3个input元素(该input元素在所有子元素排第几无所谓):By.cssSelector(“span[class~=‘s_ipt_wr’] > input:nth-of-type(3)”) - 属性
class为s_ipt_wr的span元素的子元素中排在第一且为input类型的元素:By.cssSelector(“span[class~=‘s_ipt_wr’] > input:first-child”) - 属性
class为s_ipt_wr的span元素的子元素中排在最后一个且为input类型的元素:By.cssSelector(“span[class~=‘s_ipt_wr’] > input:last-child”) - 属性
class为s_ipt_wr的span元素的第一个input类型的元素(该input元素在所有子元素排第几无所谓):By.cssSelector(“span[class~=‘s_ipt_wr’] > input:first-of-type”) - 属性
class为s_ipt_wr的span元素的最后一个input类型的元素(该input元素在所有子元素排第几无所谓):By.cssSelector(“span[class~=‘s_ipt_wr’] > input:last-of-type”)
基本上常用的css selector定位方式都在下表中了: