Article Analysis(AA): A Simple Framework for Contrastive Learning of Visual Representations
本文为读文章笔记,受所学所知限制,如有出错,恭请指正。
A Simple Framework for Contrastive Learning of Visual Representations
作者: Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton
本文提出一种简洁有效的设计的无监督设计,并且以7%的margin刷新了SOTA。
摘要直译:这篇文章提出了SimCLR, 一种简单的、用于视觉表征对比学习的框架。作者们简化了最近刚提出的对比自监督学习算法,并且不需要特别的架构或者J记忆库。为了探究是什么使得对比预测任务能够学习到游泳的表征,作者们系统地研究了该框架的大部分组件。作者们展示出(1)数据增强的组成在定义高效预测任务中具有关键的作用,(2)在表征和对比损失之间引入了一种可学习的非线性变换,该变换能够实质性地提高学习到的表征的质量,(3)相对于监督学习,对比学习能够从更大的batch size和更多的训练中获益。通过组合以上要点,在ImageNet上,作者们的方法能够大大的超过之前用于自监督和半监督的方法。一个用SimCLR学习的自监督表征的线性分类器能够达到76.5%的top-1精度,这是7%的相对提升,超过之前的SOTA, 且与监督模型ResNet-50的性能无异。仅仅1%的标签量用于微调,就能达到85.8%的top-5精度,以少100倍的标签量超过AlexNet。
核心分析:
对比学习框架,如下图
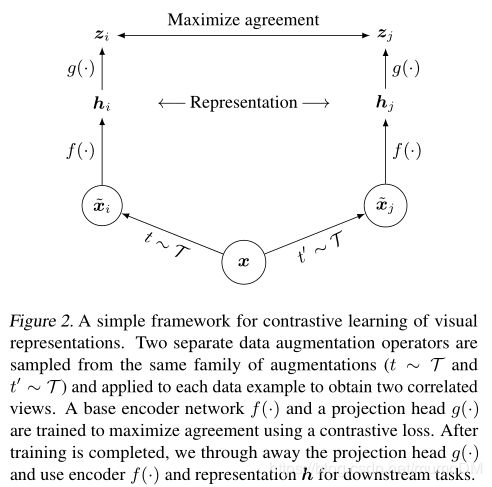
该框架有四个主要模块:
1, 随机数据增强模块,它能够随机地变换任何给定的数据样本,即生成同一样本的两个相关表征, x i ^ \hat{x_i} xi^和 x j ^ \hat{x_j} xj^,也就是一个正样本对,如上图。在文章中,顺序应用了3个简单的增强方式,随机剪裁之后,Resize到同一尺寸,接着是随机颜色扰动,随机高斯模糊。特别的是,随机剪裁和颜色扰动的组合对获得好性能至关重要。
2,用于从增强后的数据样本中提取表征向量的神经网络基础编码器(base encoder) f ( ) f() f()。该框架能够无限制的适用不同的网络框架。文章中,作者们采用简单通用的ResNet来计算 h i h_i hi, 即 h i = f ( x i ^ ) = R e s N e t ( x i ^ ) h_i=f(\hat{x_i})=ResNet(\hat{x_i}) hi=f(xi^)=ResNet(xi^), 其中 h i ∈ R d h_i \in R^d hi∈Rd是均值池化后的输出。
3, 神经网络映射头(projection head) g ( ) g() g(),用来将表征映射到对比损失应用的空间。文章中用一个隐藏层的MLP来计算 z i z_i zi, z i = g ( h i ) = W ( 2 ) σ ( W ( 1 ) h i ) z_i=g(h_i)=W^{(2)}\sigma(W^{(1)}h_i) zi=g(hi)=W(2)σ(W(1)hi),其中 σ \sigma σ是一个ReLU。作者认为在 z i z_i zi上定义对比损失比在 h i h_i hi上更好。
4, 对比损失函数,用于对比预测任务。给定一个包含正样本对 x i ^ \hat{x_i} xi^和 x j ^ \hat{x_j} xj^的数据集 x k ^ {\hat{x_k}} xk^,对比预测任务目标是,给定 x i ^ \hat{x_i} xi^后,在 { x k ^ } k ≠ i \{\hat{x_k}\}_{k \neq i} {xk^}k=i中识别 x j ^ \hat{x_j} xj^。
给定一个minibatch N N N的样本,在该批增强后的样本上定义对比预测任务,则有 2 N 2N 2N个数据点。注意并没有采样负样例。给定一对正样例,同批次中其他 2 ( N − 1 ) 2(N-1) 2(N−1)的增强样例作为负样例。
两个向量 v v v, u u u之间的余弦相似度,即 s i m ( u , v ) = u T v / ∣ ∣ u ∣ ∣ ⋅ ∣ ∣ v ∣ ∣ sim(u, v)=u^{T}v / ||u|| \cdot ||v|| sim(u,v)=uTv/∣∣u∣∣⋅∣∣v∣∣,那么对一对正样本 ( i , j ) (i, j) (i,j)有损失函数
l i , j = − l o g e x p ( s i m ( z i , z j ) / τ ) ∑ k = 1 2 N 1 [ k ≠ i ] e x p ( s i m ( z i , z k ) / τ ) l_{i, j}= - log \frac{exp(sim(z_i, z_j)/\tau)}{\sum^{2N}_{k=1} 1_{[k \neq i]} exp(sim(z_i, z_k)/\tau)} li,j=−log∑k=12N1[k=i]exp(sim(zi,zk)/τ)exp(sim(zi,zj)/τ)
其中 1 [ k ≠ i ] ∈ { 0 , 1 } 1_{[k \neq i]} \in \{0, 1\} 1[k=i]∈{0,1}是指示函数, τ \tau τ是一个温度参数。最终的损失需要计算批次中所有的正样例对,即 ( i , j ) (i, j) (i,j), ( j , i ) (j, i) (j,i)。文章中, 作者们称以上为NT-Xent(the normalized temperature-scaled cross entropy loss)。

以上是文章核心内容的说明。消融实验非常值得看,这里不在列出;放个结果图

其中, ( 1 × , 2 × , 4 × ) (1 \times, 2\times, 4\times) (1×,2×,4×)指的是ResNet-50中3个不同的隐藏层宽度,见文章第六部分第二行。
参考文献:
[1] https://arxiv.org/pdf/2002.05709.pdf 文章源地址。
[2] http://xxx.itp.ac.cn/pdf/2002.05709.pdf 国内镜像地址。